






本文主要介绍了不同公司在实现RAG(检索增强生成)模型时采用的技术方案和优化策略,并对它们的功能模块、召回模块、重排模块、大模型处理、Web服务、切词处理、文件存储等方面进行了比较和总结。
原文链接:https://zhuanlan.zhihu.com/p/704828374
所谓 RAG,简单来说,包含三件事情。
第一,Indexing。即怎么更好地把知识存起来。
第二,Retrieval。即怎么在大量的知识中,找到一小部分有用的,给到模型参考。
第三,Generation。即怎么结合用户的提问和检索到的知识,让模型生成有用的答案。这三个步骤虽然看似简单,但在 RAG 应用从构建到落地实施的整个过程中,涉及较多复杂的工作内容(细节上是魔鬼)。
架构几乎按照这个模块设计,但是各家落地方案各有不同
01

先看一下各家的技术方案
有道的QAnything
亮点在:rerank
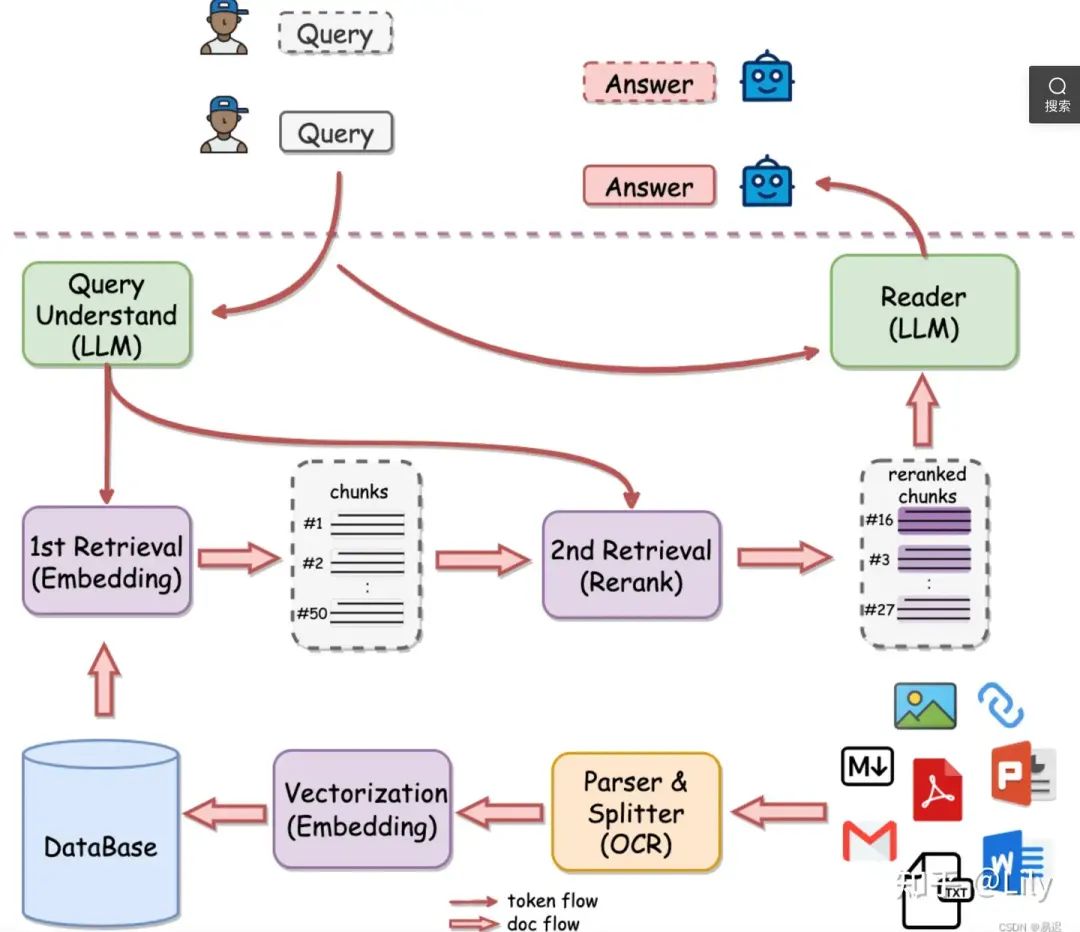
RAGFLow
亮点在:数据处理+index

智谱AI
亮点在文档解析、切片、query改写及recall模型的微调

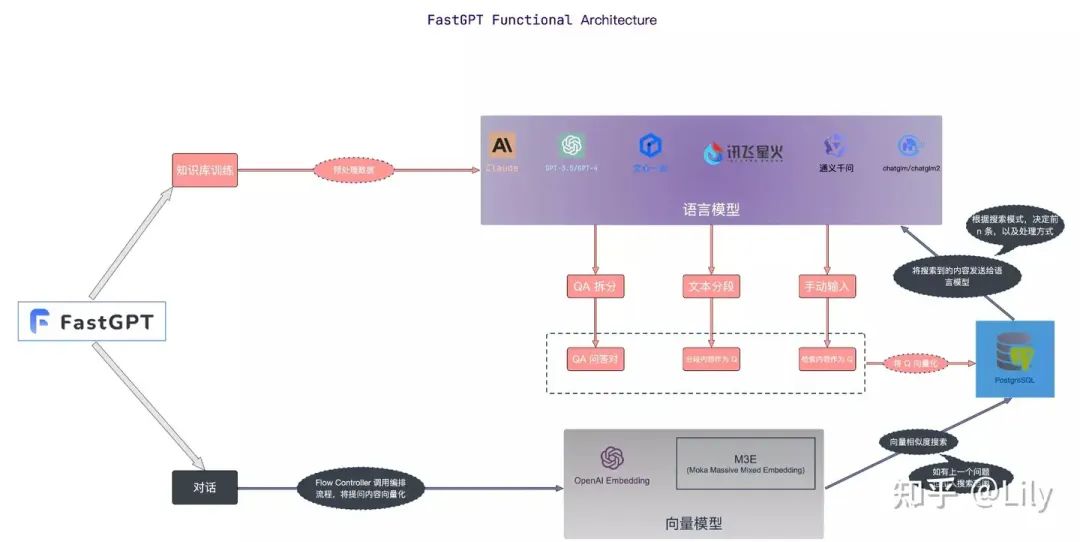
FastGPT
优点:灵活性更高
02

下面分别按照模块比较各框架的区别
| 功能模块 | QAnything | RAGFLow | 智谱AI | FastGPT |
|---|---|---|---|---|
| 知识处理模块 | pdf文件解析是抑郁PyMUPDF实现的,目前效率最高的,解析文档的文字采用的是PyMuPDF的get_text.不区分文字文档,还是图像文档(图像文档的若没有文字会报错) | OCR, Document Layout Analyze 等,这些在常规的 RAG 中可能会作为一个不起眼的 Unstructured Loader 包含进去,可以猜到 RagFlow 的一个核心能力在于文件的解析环节 | ||
| 召回模块 | 向量库采用milvus的混合检索(BM25+向量检索),不设置阈值,返回topk(100) | 向量数据库使用的是 ElasticSearch。混合检索,实现的是文本检索 + 向量检索, | ||
| 没有指定具体的向量模型,但是使用huqie作为文本检索的分词器 | 语义检索 | |||
| 语义检索模式通过先进的向量模型技术,将知识库中的数据集转换成高维向量空间中的点。在这个空间中,每个文档或数据项都被表示为一个向量,这些向量能够捕捉到数据的语义信息。当用户提出查询时,系统同样将问题转化为向量,并在向量空间中与知识库中的向量进行相似度计算,以找到最相关的结果。 |
优势:能够理解并捕捉查询的深层含义,提供更加精准的搜索结果。
应用场景:适用于需要深度语义理解和复杂查询处理的情况,如学术研究、技术问题解答等。
技术实现:利用如text-embedding-ada-002等模型,对文本数据进行embedding,实现高效的语义匹配。
全文检索
全文检索模式侧重于对文档的全文内容进行索引,允许用户通过输入关键词来检索文档。这种模式通过分析文档中的每个词项,并建立一个包含所有文档的索引数据库,使用户可以通过任何一个词或短语快速找到相关的文档。
优势:检索速度快,能够对大量文档进行广泛的搜索,方便用户快速定位到包含特定词汇的文档。
应用场景:适用于需要对文档库进行全面搜索的场景,如新闻报道、在线图书馆等。
技术实现:采用倒排索引技术,通过关键词快速定位到文档,同时结合诸如TF-IDF等算法优化搜索结果的相关性。
混合检索
混合检索模式结合了语义检索的深度理解和全文检索的快速响应,旨在提供既精准又全面的搜索体验。在这种模式下,系统不仅会进行关键词匹配,还会结合语义相似度计算,以确保搜索结果的相关性和准确性。
优势:兼顾了全文检索的速度和语义检索的深度,提供了一个平衡的搜索解决方案,提高了用户满意度。
应用场景:适合于需要综合考虑检索速度和结果质量的场景,如在线客服、内容推荐系统等。
技术实现:通过结合倒排索引和向量空间模型,实现对用户查询的全面理解和快速响应。例如,可以先通过全文检索快速筛选出候选集,再通过语义检索从候选集中找出最相关的结果。
向量模型采用:BGE-M3
别通过向量检索、文本检索召回数据,并采用RFF算法排序; | 采用文章结构切片以及 small to big 的索引策略可以很好地解决。针对后者,则需要对 Embedding 模型进行微调。我们有四种不同的构造数据的方案,在实践中都有不错的表现:
Query vs Original:简单高效,数据结构是直接使用用户 query 召回知识库片段;
Query vs Query:便于维护,即使用用户的 query 召回 query,冷启动的时候可以利用模型自动化从对应的知识片段中抽取 query;
Query vs Summary:使用 query 召回知识片段的摘要,构建摘要和知识片段之间的映射关系;
F-Answer vs Original:根据用户 query 生成 fake answer 去召回知识片段。
微调 Embedding 模型 |
| 重排模块 | 精准排序采用自己的rerank模型,但是阈值设置在0.35 | 重排是基于文本匹配得分 + 向量匹配得分混合进行排序,默认文本匹配的权重为 0.3, 向量匹配的权重为 0.7 | 支持重排,动态设置
合并 embedding 和 fulltext 的结果,并根据 id 去重;
对qa字符串拼接,并删除空格、标点符号,对字符串进行hash编码并去重;
如果配置了 rerank 模型,那调用模型进行重排序,并在 score 中新增 rerank 的得分;没有则不会增加 rerank的得分; |
|
| 大模型的处理 | 所有数据组织在一起的prompt(做了最大token的优化处理) | 大模型可用的 token 数量进行过滤 |
| 模型微调上,采用分阶段微调,即首先用开源通用问答数据进行微调,然后用垂域问答数据微调,最后用人工标注的高质量问答数据进行微调。 |
| web服务 | 使用sanic实现web服务 | Web 服务是基于 Flask |
|
|
| 切词处理 | 自定义的ChineseTextSplitter完成 | huqie |
|
|
| 文件存储 |
| 文件存储使用的是 MinIO |
|
|
| 亮点 | 与常规的RAG比较,在rerank环节做了精细化调整 | 解析过程写的也很复杂,无怪乎处理速度有点慢。不过预期处理效果相对其他 RAG 项目也会好一些。从实际前端的展示的 Demo 来看,RAGFlow 可以将解析后的文本块与原始文档中的原始位置关联起来,这个效果还是比较惊艳的,目前看起来只有 RagFlow 实现了类似的效果。 | FastGPT 提供了三种检索模式,覆盖了 RAG 中的主流实现。
对重复的数据去重并使用最高得分;计算 rrfScore 并以其为依据排序; |
|
03

总结
1、Qanything rerank模块设计的最好
2、RAGFlow 文档处理最好
3、FastGPT 模块动态配置多
4、智谱RAG,在领域数据上微调训练最好
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[优快云大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 378
378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}