






一、背景
当前已经存在非常多的推理框架,比如 vLLM、TRT-LLM、SGlang 以及针对各种特定场景的框架,比如针对 PD 分离的 MoonCake,针对多 LoRA 的 S-LoRA,还有我们刚刚介绍过的针对 Reasoning 场景的 Dynasor。本文中我们介绍来自 MLC-AI 团队的新的 MicroServing 框架。
对应的论文:[2412.12488] A System for Microserving of LLMs [1]
对应的开源代码:GitHub - mlc-ai/mlc-llm: Universal LLM Deployment Engine with ML Compilation [2]
二、摘要
LLM 推理扩展到多 GPU 甚至多节点,也出现了 Prefill-Decoding 分离及 Context 迁移等多种协调模式,对 LLM 推理系统提出了更高的要求。然而,当前多数推理服务提供的都是预设策略的粗粒度 Request 级别 API,限制了协调方式的自定义能力及动态重构能力。
本文中,作者提出 LLM Microserving 框架,是一种多层次的、可编程的推理框架。作者引入了间接而高效的 MicroServing API,支持细粒度的子请求级操作。可编程 Router 将用户请求转换为子请求调度,实现服务模式的动态重构。为了支持多样化的执行模式,作者也构建了统一的 KV Cache 接口,处理各种 KV 计算、传输和重用场景。
评估结果表明,LLM Microserving 框架仅需数行 Python 代码即可重构支持多种分离式编排策略,同时保持 LLM 推理任务的先进性能。此外,基于该框架可以探索新的策略变体,相较于现有策略,最多可减少 47% 的任务完成时间。
三、引言
3.1 一点总结
最近也在思考一个高效、可靠、灵活的 LLM 推理服务系统应该是什么样的,因此简单梳理了涉及的场景、相关的功能、模块等,实际中还需要结合场景和需求做减法,砍掉不必要的部分,其实大部分框架也都在针对其中的一部份。当然,也有很多内容并没有在其中涉及,比如:
-
性能监控,比如 Latency、GPU、内存利用率。
-
弹性伸缩,比如高峰、低谷期的伸缩,动态调整资源。
-
故障修复,大模型推理涉及的资源更多,相应的故障处理也会更加复杂。
-
模块间的交互,通常要考虑怎么更好的将几个模块组织起来,协同工作,比如怎么更好的存储、传输 KV Cache,以供计算。

不管是什么样的 LLM 推理系统,都是为了实现以下几个方面(或之一):
-
最小化成本:平均每个 Token 的成本最低,比如
-
MFU(Model FLOPs Utilization,模型浮点利用率)。
-
最小化时延:每个 Token 都生成的尽可能快,比如
-
TTFT(Time To First Token,首 Token 时延)。
-
TPOT(Time Per Output Token,每个输出 Token 时间)。
-
TBT(Time Between Token,Token 间间隔)。
-
最佳精度:保证采用的各种优化方案能尽可能高的维持精度,甚至提升精度。
这也就对推理系统提出了几个要求:
-
最大化 Prefix Cache:比如通过排序、路由提升 Prefix Cache 命中,降低 Prefix Cache 淘汰。
-
最小化模型:能用小模型解决的问题尽量使用小模型。
-
最少化 Token:能用更少 Token 解决的问题使用尽可能少的 Token。
-
最大化硬件利用率:算力、存储、通信设备都尽可能利用,相应的也就需要最大化的 Overlap(最常见的就是计算与通信的 Overlap)。
3.2 Anthropic AI Agent 最佳实践
Anthropic 前端时间发布了构建 AI Agent 的最佳实践:Building effective agents \ Anthropic [3],其中提到了一些常见的 Workflow 范式。
3.2.1 Prompt Chaining
Prompt Chaining 将任务分解为一系列的步骤,每一个 LLM 调用都会处理前一个调用的输出。也可以在中间添加检查节点(对应图中 “Gate”),确保流程正确执行或者可以提前结束。

3.2.2 Routing
Routing 会对输入进行分类,并重定向到特定的后续任务,Routing 通常有两种常见的范式:
-
按 Query 意图路由(SambaNova CoE),对应子模型为不同垂类模型,甚至不同的工具。
-
按 Query 难易程度路由(Hybrid LLM,Router LLM),对应子模型往往是不同大小的模型,简单问题到较小模型(如 Claude 3.5 Haiku),较难问题到较大模型(如 Claude 3.5 Sonnet)。
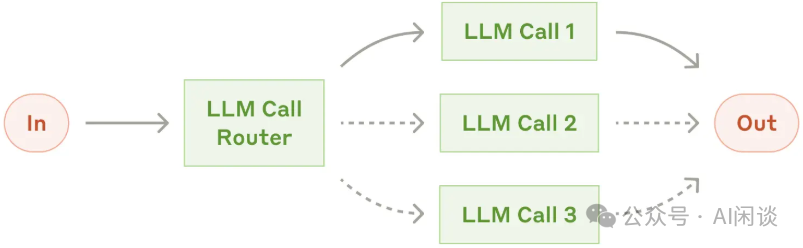
3.2.3 Orchestrator-Worker
在此工作流中,Orchestrator LLM 对任务进行动态分解,并将其委托给多个 Worker LLM,并综合其结果。
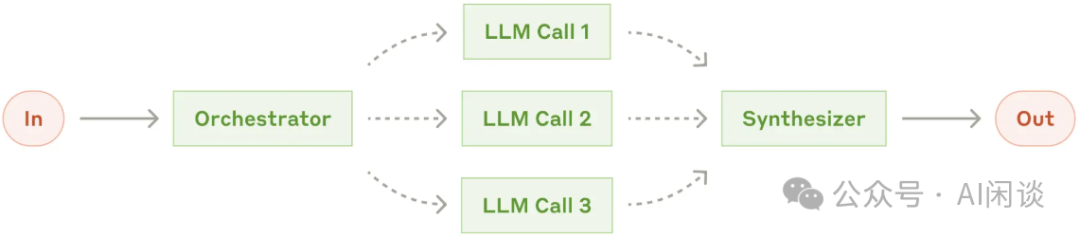
3.3 Reasoning
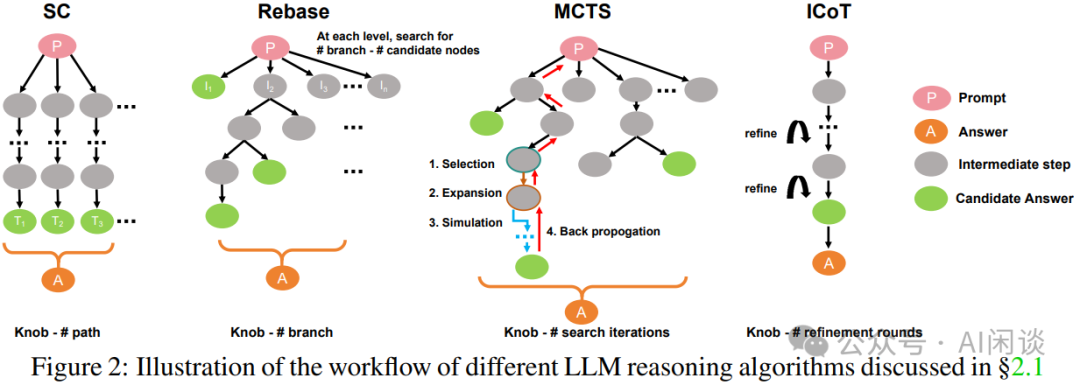
我们在之前的文章中也介绍过 [2412.20993] Efficiently Serving LLM Reasoning Programs with Certaindex [4] 中提到的各种 Reasoning 算法。如下图 Figure 2 所示,作者阐释了 4 种常见的 Reasoning 算法:
-
自一致性(Self-Consistency, SC)。如 Figure 2a,核心是生成多个不同输出,然后对所有答案进行投票表决,选出胜率最高的答案。
-
Rebase 算法。如 Figure 2b,同样是生成多个输出,只不过会分为多步生成,每一步都会使用 Reward 模型进行评分,并基于得分最高的结果继续生成,最后生成具有多个分支的推理树。聚合阶段选择得分最高(Best-of-N)的答案。
-
蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)。如 Figure 2c,通过逐步采样来扩展节点,并构建解决方案树,直至到达包含候选解的叶节点。
-
内化思维链(ICoT)。如 Figure 2d,在训练过程中内化 Reasoning 行为,无需显式的 Reasoning 算法。
四、方案
4.1 概览
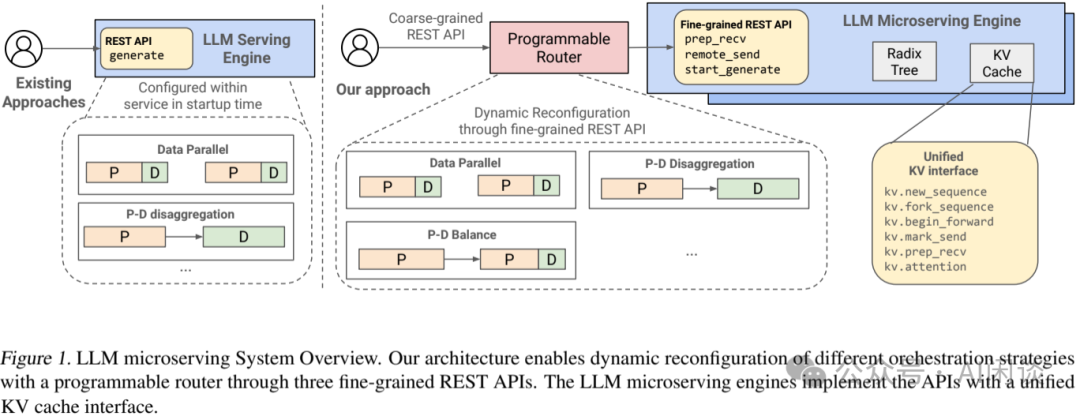
当前推理系统:如下图 Figure 1 左图所示,现有框架通常是封装了一组固定策略,只向用户开放 Request 粒度的 API。因此,重新配置可能需要重启或者中断生成环境,并且用户根据流量动态调度系统的能力比较有限。
本文 MicroServing:如下图 Figure 1 右图所示,通过 3 个关键组件填补了这一空白。其提供了 3 个简单的细粒度 API,允许用户组合表示各种编排模式。
-
控制层:可编程 Router,将 Request 级 API 转换为细粒度 API。可以支持不同的解耦和协调模式,比如数据并行(多实例)、Prefill-Decoding 分离,Context 迁移等,还支持探索新的范式。
-
执行层:为了支持细粒度 API 的多样化语义,LLM MicroServing Engine 需要执行不同的 KV 传输、重用以及计算模式的组合。为此,作者也提出了一个统一的 KV 接口。
4.2 Microserving REST API
作者认为,常见的调度模式可以通过两种基本操作来表达:
-
将部分 KV Cache 从一个 LLM Engine 转移到另一个。被转移的 KV Cache 可能来自 Prefix Cache,也可能是 Prefill 计算。
-
使用 Prompt 的全部或部分 KV Cache 启动 Token 生成。
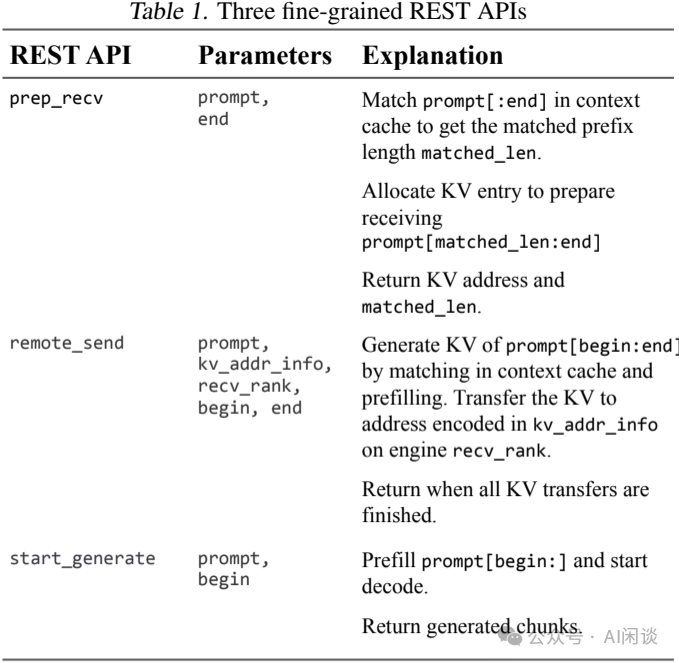
鉴于 KV Cache 转移需要发送和接收方之间的协调,作者引入了 3 个细粒度的 REST API(如下图 Table 1 所示)来执行这些操作。通过 Router 调用这些 API,开发者可以组合多种调度模式:
-
prep_recv:用于检测 KV Cache 中是否存在 prompt[0:end] 的部分,为缺失的子序列分配 KV Cache 空间,并以压缩形式返回地址。
-
remote_send:将 prompt[begin:end] 的 KV 发送到 Engine 接收端。若该子序列部分已经存在 KV Cache 中,则直接传输到接收方;对于其余部分,先通过 Prefill 计算生成新的 KV,再发送给接收方。
-
start_generate:准备对 prompt[begin:] 启动 Prefill 和 Decoding。
👉[优快云大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

4.3 Programmable Router
借助细粒度 REST API 可实现对 Engine 操作的精细控制,调度模式间的重新配置仅发生在 Router 端,无需 Engine 重新配置。
4.3.1 示例 1 - 数据并行
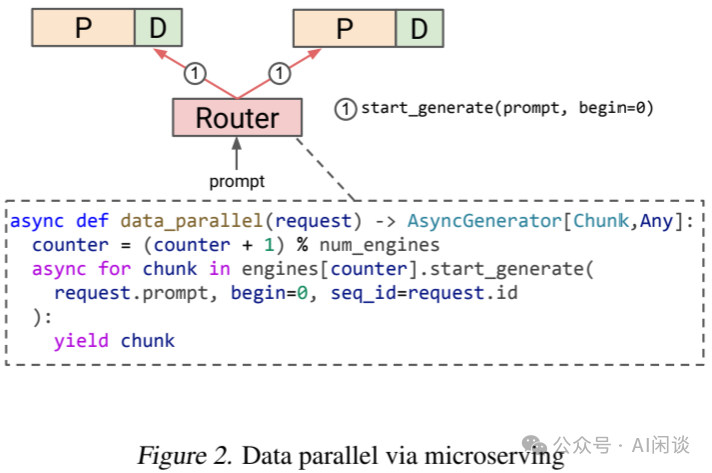
如下图 Figure 2 所示为一个数据并行(多实例)的实现,也就是将 Request 以轮询方式分配给 Engine 的策略。由于各 Engine(实例)间无需通信(PS:也就降低了 Prefill Cache 共享的机会),因此只用一个 Counter 来统计 Request 数,并轮询调用(start_generate)各个 Engine 即可。
4.3.2 示例 2 - Prefill-Decoding 分离
PD 分离的核心观点在于:Prefill 和 Decoding 共置可能导致强烈的相互干扰,此外两阶段的资源分配、并行性也有所不同,不必耦合。通过 PD 分离能够实现更低的延迟、更优的资源管理及更高的可扩展性。不过,调度策略在实施上面临两大挑战:
-
如何高效地将 KV Cache 从 Prefill Engine 转移至 Decoding Engine。
-
如何协调两个 Engine 以最小化 CPU 运行时开销。
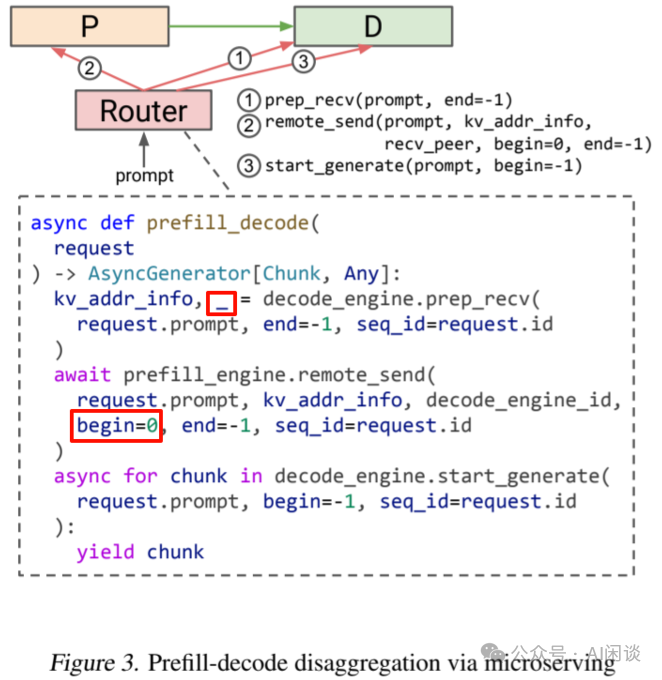
如下图 Figure 3 所示为一个相应的 PD 分离实现示例:
-
Router 首先调 Decoding Engine 的 prep_recv 函数,指示 Decoding Engine 为 request.prompt[:-1] 的 KV Cache 预留空间,并返回相应的地址信息。
-
Router 随后调用 Prefill Engine 的 remote_send 函数,参数 begin=0 与 end=-1 指示 Prefill Engine 执行 Prefill 计算,为 request.prompt[:-1] 生成 KV Cache,并将其发送到 Decoding Engine 的相应位置。
-
Router 最后调用 Decoding Engine 的 start_generate 函数,启动相应的 Decoding 过程。
4.3.3 示例 3 - Context 感知的 Prefill-Decoding 分离
相当于对 PD 分离进行扩展,以考虑每个 LLM Engine 上的 KV Cache。与上述的 PD 分离类似,主要区别在于匹配长度(match_len)不一定为 0。
如下图 Figure 4 所示,关键 API 的调用差异如下:
-
prep_recv:会额外返回 match_len 参数。
-
remote_send:会传入 match_len 参数,这可能涉及对 KV Cache 的直接传输或/和未匹配部分进行 Prefill 计算。
-
start_generate:保持不变。

4.3.4 示例 4 - Context Cache 迁移
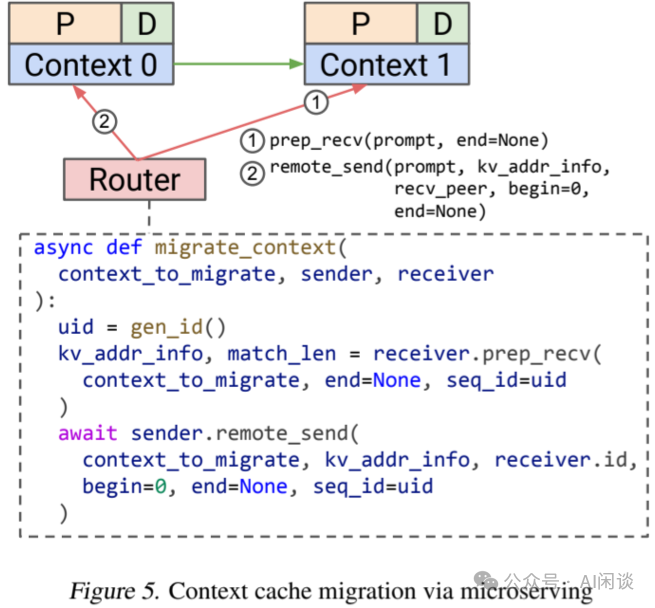
在多实例推理场景中,通常可以将一类场景发送到某个特定实例以增加 Prefix Cache 命中率,比如历史类问题到实例 A,科学类问题到实例 B。然而,这些请求往往很难均衡,比如科学类请求多于历史类,那么对于部分请求就需要将其 KV Cache 从实例 A 迁移到实例 B(PS:前提是迁移成本小于重计算成本)。
如下图 Figure 5 所示,在接收端调用 prep_recv 并在发送端调用 remote_send,即可轻松完成 Context 的转移。值得注意的是,Router 除了要维护 LLM Engine 的 Radix Tree 外,还需要额外维护一个,以便决定将 Request 调度至哪个 Engine 以及何时触发 Context 切换。
4.4 探索均衡的 PD 分离
PD 分离系统中经常被问到的一个问题是:P 和 D 的比例是多少,比如很多人问为什么 DeepSeek V3 中 P 和 D 的比例为 1:10。其实不同的 Workload 分布往往需要不同的比例,甚至可能需要动态负载,比如 Kimi 的常见场景是超长输入、短输出(论文问答),就往往需要更多的 P。
这里作者介绍了一种新的策略,其动态地将部分 Prefill 计算迁移到 Decoding Engine 中,迁移的 Prefill 计算可以与 Decoding 计算融合,以提高整体吞吐量,作者称为 Balanced PD 分离。如下图 Figure 6 所示,其通过几行代码即可以实现:
-
Router 根据监控的 P/D 分布决定在 Prefill 实例上计算子序列 prompt[😒]。
-
当 Prefill Engine 计算完后 Decoding Engine 已经拥有 prompt[😒] 的 KV,因此可以使用 Decoding Engine 计算剩下的 Prefill 部分 prompt[s:],接着开始执行 Decoding。
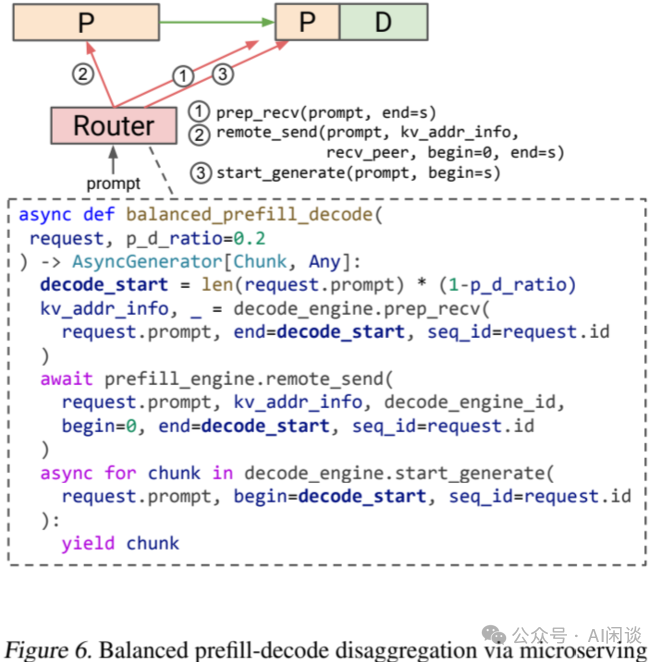
4.5 统一 KV Cache 接口
如下图 Figure 7 所示,作者展示了 LLM Engine 如何借助统一的 KV Cache 接口实现并执行上述 3 个细粒度 API:
-
在 declaration 阶段,KV Cache 提供两个主要的 API,用于声明待执行操作的必要信息。
-
begin_forward 用于声明待处理的 Attention 操作,并要求 KV Cache 一次性为所有 Attention 层规划元数据和 Kernel 操作。
-
mark_send 则声明待处理的 Attention 操作将触发一次向远程的 KV 传输。
-
在模型 Forward 的计算阶段,利用 QKV 数据调用 Attention 计算。此时,KV Cache 利用已经准备好的元数据执行 Attention 计算,这些元数据向 KV Cache 通报了未完成的 KV 传输任务及利用共同前缀的机会。
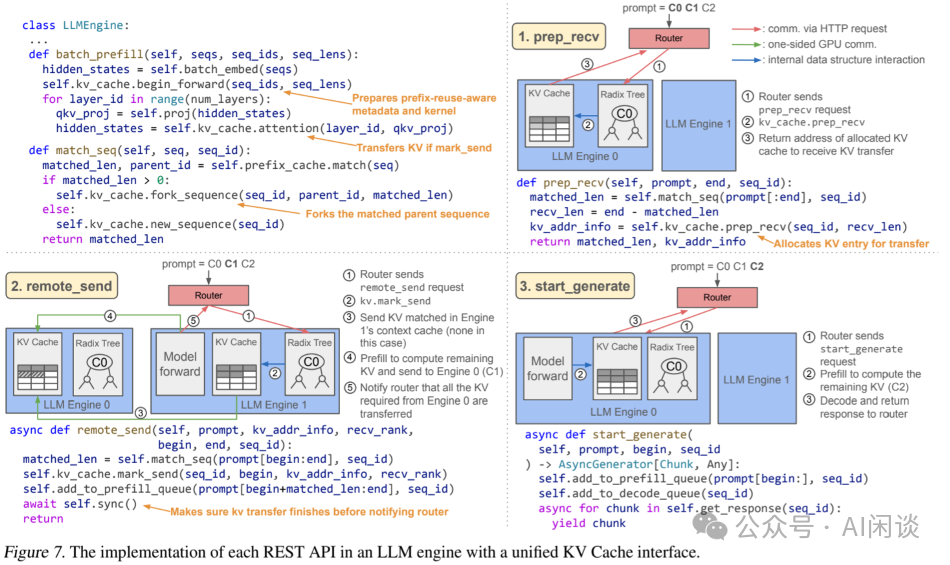
统一 KV Cache 接口里面的具体接口如下图 Table 2 所示:

4.6 KV Cache 和分布式 Context Cache
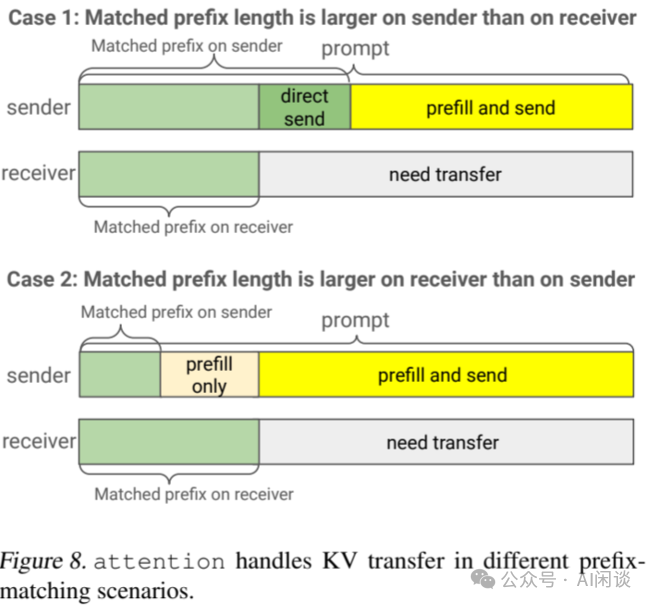
为实现 REST API 所承诺的 Prefix 匹配功能,LLM Engine 需维护一个 Context Cache。尽管现有框架中有部分将这一功能集成于 KV Cache 内部,但作者的设计中将 Context Cache 管理与 KV Cache 解耦。这一设计使得 Engine 本地的淘汰策略与 Router 的全局淘汰策略得以共存,后者可根据其全局知识指示 Engine “固定”某些重要前缀。
如下图 Figure 8 所示,作者通过两个案例探讨了不同 Prefix 匹配场景下的 KV Cache 传输问题:
-
案例一:发送方匹配 Prefix 长度大于接收方。在此情境下,仅由发送方匹配的片段(深绿色部分)可直接发送至接收方,而双方引擎均未匹配的片段则需 Prefill 后再传输(黄色部分)。
-
案例二:接收方匹配 Prefix 长度大于发送方。此情况下,并非所有需传输的 KV 片段均存在于发送方的 Context 缓存中。为计算该片段,发送方应 Prefill 所有未缓存的片段,并仅传输接收方所需部分。
4.7 End-to-end Implementation
作者在现有 MLC-LLM 项目(GitHub - mlc-ai/mlc-llm: Universal LLM Deployment Engine with ML Compilation [2])的基础上实现了 LLM MicroServing Engine 和 KV Cache,该项目总计包含 13,000行 C++ 代码和 6,000 行 Python 代码。得益于 LLM MicroServing 的灵活性,作者在 Router 中仅用 350 行 Python 代码实现了所有策略。
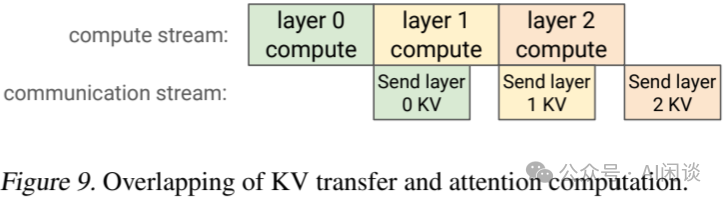
针对 GPU 间的通信,作者采用了 NVSHMEM 库(GitHub - NVIDIA/nv-shmem: Shared memory IPC on BMC [5]),与 NCCL 不同,它支持单边 put 和 get API,即通信仅需一侧的 SM 参与。通过设置计算流与通信流,并在某一层的计算完成后立即发送其 KV 数据,实现了 KV 传输与 Attention 计算的并行处理,如下图 Figure 9 所示。KV 传输是异步进行的,不会影响接收 Engine 正在处理的其他请求。
五、评估
5.1 分离式 LLM 推理评估
作者使用 LLaMA 3.1 8B 模型在 ShareGPT 数据集上评估了不同方案的性能,包含如下几种配置,其中每个 Engine 都在 1 个 NVIDIA A100 SXM 40G GPU:
-
vLLM(0.6.3.post1),作为基线。
-
DP:使用 MicroServing 的多实例方案。
-
1P1D:1 个 Prefill Engine,1 个 Decoding Engine。
-
1P1D-balance:均衡的 PD 分离,1 个 P,1 个 D。
-
1P2D:1 个 Prefill Engine,2 个 Decoding Engine。(PS:这里会额外多使用 1 个 GPU)
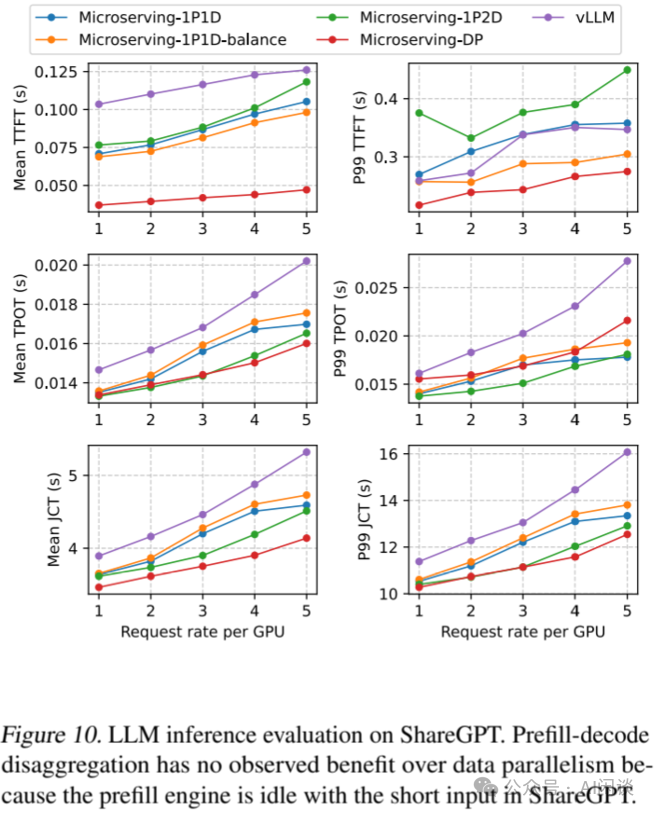
如下图 Figure 10 可以看出,对于 ShareGPT 数据集分布,模型只有 8B,纯 DP 的方案具有很大的优势,并且未观察到 PD 分离的优势,这主要是 ShareGPT 数据集中输入、输出长度在同一量级(平均输入、输出为 200 和 260 左右),Prefill 负载相对较低。当然,1P2D 由于多使用了 1 个 GPU 作为 Decoding Engine,相应的 TPOP(Time Per Output Token)和 JCT(Job Completion Time)也会更低(PS:这也是为什么 PD 分离时通常需要调整 P 和 D 的比例)。
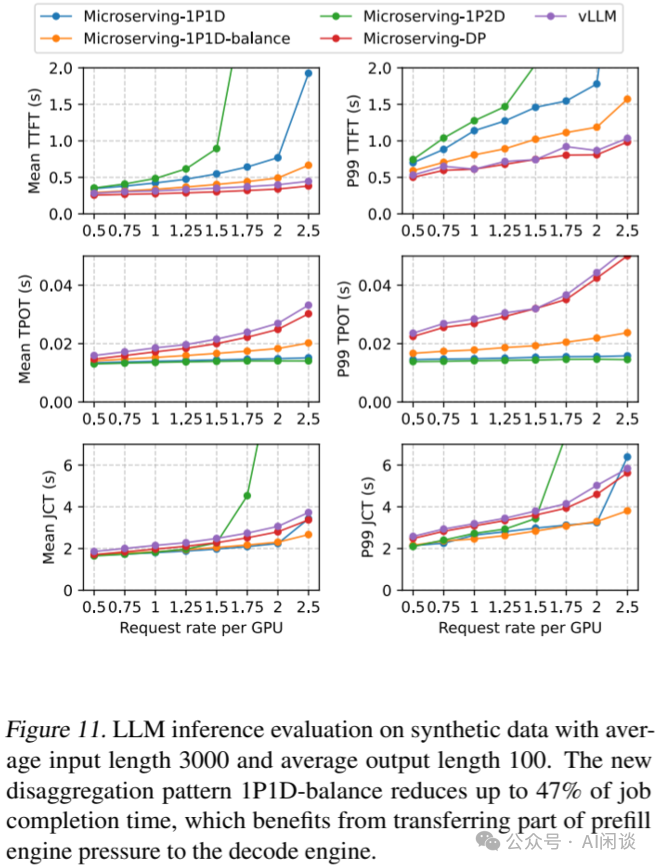
如下图 Figure 11 所示,作者展示了合成数据集(平均输入 3000,平均输出 100)的评估结果,由于输入明显长于输出,PD 分离方案相比纯 DP 并行也就有了一定优势,平均 JCT 最多可以减少 21%,在 P99 JCT 上最多可以减少 47%。
5.2 KV 迁移效率评估
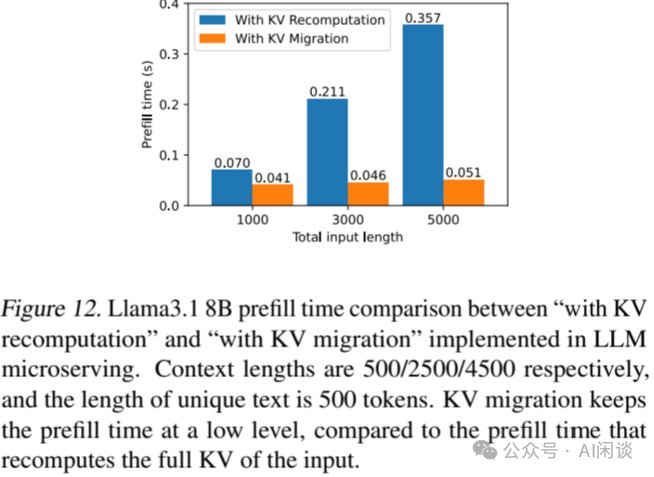
如下图 Figure 12 所示,作者分别评估了 500/2500/4500 的 Context 长度下 KV 迁移的效率。可以看出,LLM MicroServing 利用全局 Context Cache 实现了 KV 迁移的能力,显著减少了 Prefill 计算时间。并且输入越长,Cache 迁移的收益越明显。
为了进一步评估 Prefill 期间的 KV 传输效率,作者评估了相同 Contex Cache 设置下的传输时间。如下图 Table 3 显示了 LLaMA 3.1 8B 中每个模型层的 Prefill 和 KV 传输时间。LLM MicroServing 通过使用 NVSHMEM 库进行 GPU 通信,将 KV 传输与 Prefill 计算重叠。随着总输入长度从 1000 增加到 5000,KV 传输时间重叠率从 15.8% 上升到 55.4%。之所以增加,是因为有效 Prefill 长度保持不变,为 500 个 Token,而传输的 KV 数据的大小呈线性增长。

5.3 PD 均衡比例的影响
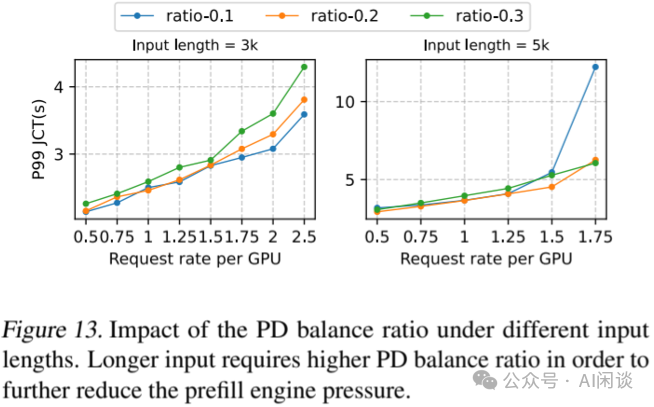
作者进一步研究了不同均衡比例对 Prefill 工作负载从 Prefill Engine 转移到 Decoding Engine 的影响。作者在输入长度为 3000 和 5000 的情况下测试了 0.1、0.2 和 0.3 的均衡比例。结果如下图 Figure 13 所示:
-
对于输入长度为 3000 的情况,0.1 的均衡比相较于更高比值,在 P99 JCT 上提供了高达1.19x 的加速。
-
当输入长度增加到 5000 时,将更多 Prefill Workload 转移到 Decoding Engine 更为有利,尤其是在高请求率的情况下。这是因为高请求率加剧了 Prefill Engine 的压力,导致请求容易在 Prefill Engine 上排队,这种拥塞显著减缓了 TTFT。更高的均衡比有助于更好地缓解拥塞,使系统恢复到 PD 均衡状态。
在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
👉[优快云大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[优快云大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈


















 1356
1356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}