







嵌入(Embedding)、微调(Fine-tuning)和提示工程(Prompt Engineering) 是AIGC 模型的核心功能,合理运行这些功能,能实现一些复杂和意向不到的应用。
前言
Prompt和Embedding是AIGC模型的核心功能,语言处理应用。例如,它们可以用于聊天机器人、语言翻译、摘要生成、文本分类等。Fine-tuning技术可以用于优化预训练模型,以提高其在特定任务中的性能,例如问答、文本摘要、语言理解等。
一、嵌入(Embedding)
嵌入是浮点数的向量(列表)。两个向量之间的距离衡量它们的相关性。小距离表示高相关性,大距离表示低相关性。
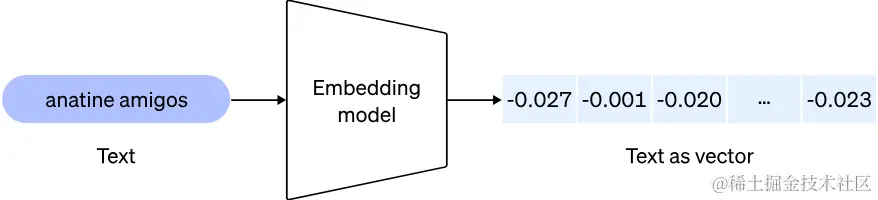
嵌入通常用于:
- Search 搜索(结果按与查询字符串的相关性排序)
- Clustering 聚类(文本字符串按相似性分组)
- Recommendations 推荐(推荐具有相关文本字符串的条目)
- Anomaly detection 异常检测(识别出相关性很小的异常值)
- Diversity measurement 多样性测量(分析相似性分布)
- Classification 分类(其中文本字符串按其最相似的标签分类)
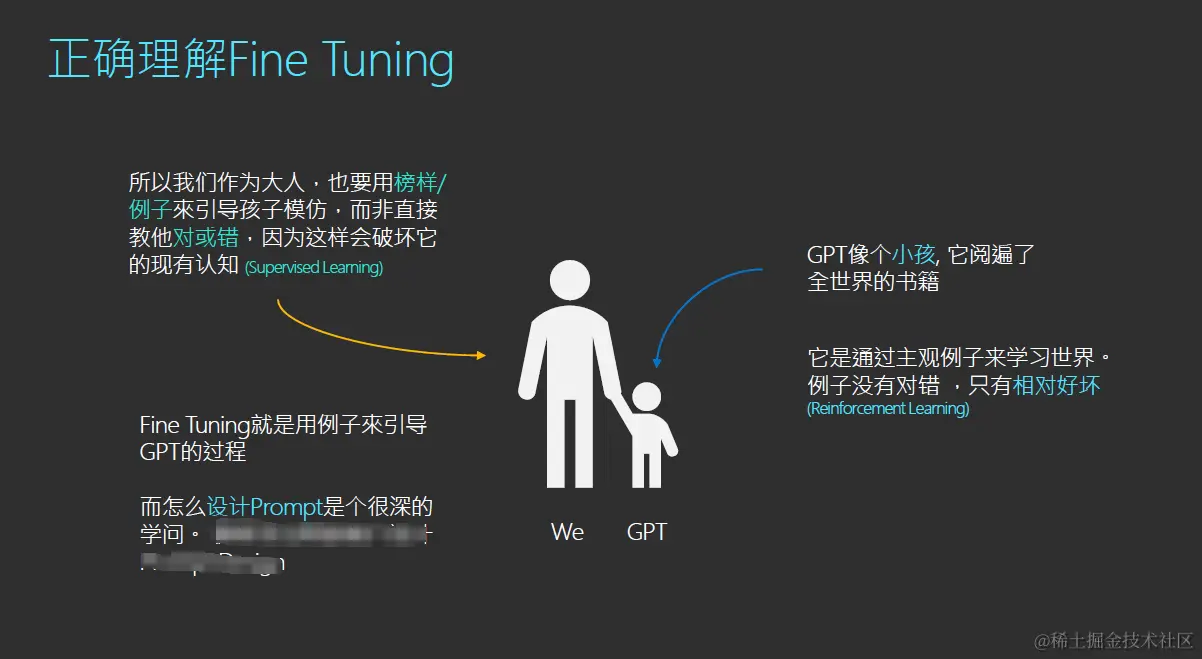
二、微调 (Fine-tuning)
微调通过训练比提示(prompt)中更多的示例来改进小样本学习,让您在大量任务中取得更好的结果。对模型进行微调后,您将不再需要在提示(prompt)中提供示例。这样可以节省成本并实现更低延迟的请求。

三、提示工程(Prompt Engineering)
如果没有良好的提示设计和基础技术,模型很可能产生幻觉或编造答案,其危险在于,模型往往会产生非常有说服力和看似合理的答案,因此必须非常小心地设计安全缓解措施和地面模型的事实答案,所以提示工程应运而生。
提示工程(Prompt Engineering)是一门较新的学科,关注提示词开发和优化,帮助
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2015
2015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









