






ollama 是一个开源的本地大语言模型运行框架,它提供了非常简单便捷的使用形式,让用户可以十分方便的在本地机器上部署和运行大型语言模型,从而实现免费离线的方式使用 LLM 能力,并确保私有数据的隐私和安全性。
1 ollama 安装
ollama 支持多种操作系统,包括 macOS、Windows、Linux 以及通过 Docker 容器运行。其安装、使用及模型下载非常简单,可以简单概括为以下几步:
-
• 下载 ollama 安装程序并安装。
-
• 启动 ollama,执行命令下载和运行模型。如:
ollama run deepseek-r1:1.5b -
• 以命令行交互、API 调用、第三方应用接入等形式使用其服务。
1.1 硬件要求
ollama 本身对硬件要求并不高,主要取决于运行模型的要求。基本建议:
你应该至少有 4 GB 的 RAM 来运行 1.5B 模型,至少有 8 GB 的 RAM 来运行 7B 模型,16 GB 的 RAM 来运行 13B 模型,以及 32 GB 的 RAM 来运行 33B 模型。
假若需要本地私有化部署具有实用性的模型,应至少有独立显卡并有 4G 以上显存。纯 CPU 模式虽然也可以运行,但生成速度很慢,仅适用于本地开发调试体验一下。
本人实测在Mac Studio 2023 版(Apple M2 Max 芯片:12核、32G内存、30核显、1TB SSD)上,运行 deepseek:1.5b 模型响应非常快,可以较为流畅的运行 deepseek-r1:32b 及以下的模型。
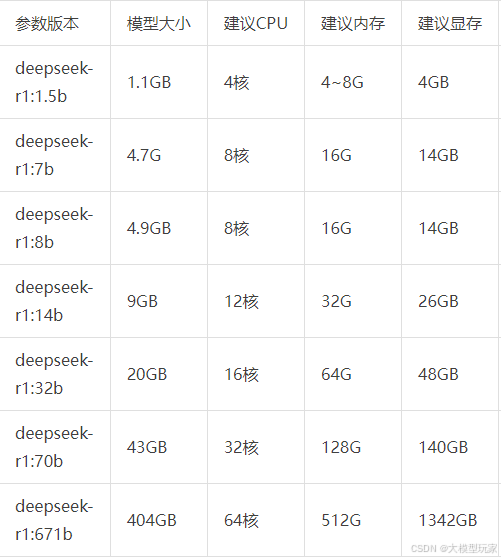
1.2 Windows \ macOS \ Linux 下安装 ollama
Windows 和 macOS 用户可访问如下地址下载安装文件并安装:
-
• 国内中文站下载:http://ollama.org.cn/download/
-
• 官方下载:https://ollama.com/download/
-
• github release 下载:https://github.com/ollama/ollama/releases/
Linux 用户可以执行如下命令一键安装:
curl -fsSL https://ollama.com/install.sh | bash
安装完成后,可以通过执行 ollama --version 命令查看 ollama 版本信息,以验证是否安装成功。
ollama 离线安装:
Windows 和 macOS 下直接复制安装文件到本地本进行安装即可。
Linux 下的离线安装主要步骤参考如下:
mkdir -p /home/ollama cd /home/ollama # 查看服务器 CPU 信息获取其架构,如:x86_64 lscpu # 访问如下地址,下载对应架构的 ollama 安装包 # https://github.com/ollama/ollama/releases/ # - x86_64 CPU 选择下载 ollama-linux-amd64 # - aarch64|arm64 CPU 选择下载 ollama-linux-arm64 # 示例: wget https://github.com/ollama/ollama/releases/download/v0.5.11/ollama-linux-amd64.tgz # 下载 安装脚本,并放到 /home/ollama 目录下 wget https://ollama.com/install.sh # 将 ollama-linux-amd64.tgz 和 install.sh 拷贝到需要安装的机器上,如放到 /home/ollama 目录下 # 然后执行如下命令: tar -zxvf ollama-linux-amd64.tgz chmod +x install.sh # 编辑 install.sh 文件,找到如下内容 curl --fail --show-error --location --progress-bar -o $TEMP_DIR/ollama "https://ollama.com/download/ollama-linux-${ARCH}${VER_PARAM}" # 注释它,并在其下增加如下内容: cp ./ollama-linux-amd64 $TEMP_DIR/ollama # 执行安装脚本 ./install.sh # 模型的离线下载请参考下文模型导入部分
1.3 基于 Docker 安装 ollama
基于 Docker 可以使得 ollama 的安装、更新与启停管理更为便捷。
首先确保已安装了 docker,然后执行如下命令:
# 拉取镜像 docker pull ollama/ollama # 运行容器:CPU 模式 docker run -d -p 11434:11434 -v /data/ollama:/root/.ollama --name ollama ollama/ollama # 运行容器:GPU 模式 docker run --gpus=all -d -p 11434:11434 -v /data/ollama:/root/.ollama --name ollama ollama/ollama # 进入容器 bash 下并下载模型 docker exec -it ollama /bin/bash # 下载一个模型 ollama pull deepseek-r1:8b
也可以基于 docker-compose 进行启停管理。docker-compose.yml 参考:
services: ollama: image:ollama/ollama container_name:ollama restart:unless-stopped ports: -11434:11434 volumes: -/data/ollama:/root/.ollama environment: # 允许局域网跨域形式访问API OLLAMA_HOST=0.0.0.0:11434 OLLAMA_ORIGINS=*
1.4 修改 ollama 模型默认保存位置
ollama 下载的模型默认的存储目录如下:
-
• macOS:
~/.ollama/models -
• Linux:
/usr/share/ollama/.ollama/models -
• Windows:
C:\Users\<username>\.ollama\models
若默认位置存在磁盘空间告急的问题,可以通过设置环境变量 OLLAMA_MODELS 修改模型存储位置。示例:
`# macOS / Linux:写入环境变量配置到 ~/.bashrc 文件中 echo 'export OLLAMA_MODELS=/data/ollama/models' >> ~/.bashrc source ~/.bashrc # Windows:按 `WIN+R` 组合键并输入 cmd 打开命令提示符 # 然后执行如下命令写入到系统环境变量中 setx OLLAMA_MODELS D:\data\ollama\models`
如果已经下载过模型,可以从上述默认位置将 models 目录移动到新的位置。
对于 docker 安装模式,则可以通过挂载卷的方式修改模型存储位置。
1.5 使用:基于 API 形式访问 ollama 服务
ollama 安装完成并正常启动后,可以通过命令行形式运行模型(如:ollama run deepseek-r1:1.5b),并通过命令行交互的方式进行测试。
此外也可以通过访问 http://localhost:11434 以 API 调用的形式调用。示例:
curl http://localhost:11434/api/generate -d '{ "model": "deepseek-r1:8b", "stream": false, "prompt": "你是谁" }'
ollama API 文档参考:
-
• https://ollama.readthedocs.io/api/
-
• https://github.com/ollama/ollama/blob/main/docs/api.md
2 使用 ollama 下载和运行模型
2.1 使用 ollama 命令行下载和运行模型
执行如下命令下载并运行一个模型:
# 基本格式为: ollama run <model_name:size> # 例如下载并运行 deepseek-r1 的 1.5b 模型 # 如果下载模型速度开始较快后面变慢,可以 kill 当前进程并重新执行 ollama run deepseek-r1:1.5b
运行成功则会进入命令行交互模式,可以直接输入问题并获得应答反馈,也可以通过 API 调用方式测试和使用。
从如下地址可搜索 ollama 所有支持的模型:
-
• 中文站:https://ollama.org.cn/search
-
• 官方站:https://ollama.com/search
从 HF 和魔塔社区下载模型
ollama 还支持从 HF 和魔塔社区下载第三方开源模型。基本格式为:
# 从 HF(https://huggingface.co) 下载模型的格式 ollama run hf.co/{username}/{reponame}:latest # 示例: ollama run hf.co/bartowski/Llama-3.2-1B-Instruct-GGUF:Q8_0 # 从魔塔社区(https://modelscope.cn)下载模型的格式 ollama run modelscope.cn/{username}/{model} # 示例: ollama run modelscope.cn/Qwen/Qwen2.5-3B-Instruct-GGUF:Q3_K_M
2.2 使用 ollama create 导入本地模型
通过 ollama run 和 ollama pull 命令均是从官方地址下载模型,可能会遇到下载速度慢、下载失败等问题。
ollama 支持从本地导入模型。我们可以从第三方下载模型文件并使用 ollama create 命令导入到 ollama 中。
例如,假若我们下载了 deepseek-r1:8b 模型文件,并保存在 /data/ollama/gguf/deepseek-r1-8b.gguf,则可执行如下命令进行导入:
cd /data/ollama/gguf echo "From ./deepeek-r1-8b.gguf" > modelfile-deepseek-r1-8b ollama create deepseek-r1:8b -f modelfile-deepseek-r1-8b # 查看模型信息 ollama list ollama show deepseek-r1:8b # 运行模型(以命令行交互模式使用) ollama run deepseek-r1:8b
相关文档参考:
-
• https://ollama.readthedocs.io/import/
-
• https://ollama.readthedocs.io/modelfile/
3 ollama 常用命令参考
ollama 提供了丰富的命令行工具,方便用户对模型进行管理。
-
•
ollama --help:查看帮助信息。 -
•
ollama serve:启动 ollama 服务。 -
•
ollama create <model-name> [-f Modelfile]:根据一个 Modelfile 文件导入模型。 -
•
ollama show <model-name:[size]>:显示某个模型的详细信息。 -
•
ollama run <model-name:[size]>:运行一个模型。若模型不存在会先拉取它。 -
•
ollama stop <model-name:[size]>:停止一个正在运行的模型。 -
•
ollama pull <model-name:[size]>:拉取指定的模型。 -
•
ollama push <model-name>:将一个模型推送到远程模型仓库。 -
•
ollama list:列出所有模型。 -
•
ollama ps:列出所有正在运行的模型。 -
•
ollama cp <source-model-name> <new-model-name>:复制一个模型。 -
•
ollama rm <model-name:[size]>:删除一个模型。
4 ollama 安装使用常见问题及解决
4.1 ollama 模型下载慢:离线下载与安装模型
通过 ollama 官方命令拉取模型,可能会遇到网速慢、下载时间过长等问题。
4.1.1 开始快后来慢:间隔性重启下载
由于模型文件较大,下载过程中可能会遇到开始网速还可以,后面变慢的情况。许多网友反馈退出然后重试则速度就可以上来了,所以可以尝试通过每隔一段时间退出并重新执行的方式以保持较快的下载速率。
以下是基于该逻辑实现的下载脚本,注意将其中的 deepseek-r1:7b 替换为你希望下载的模型版本。
Windows 下在 powershell 中执行:
while ($true) { $modelExists = ollama list | Select-String "deepseek-r1:7b" if ($modelExists) { Write-Host "模型已下载完成!" break } Write-Host "开始下载模型..." $process = Start-Process -FilePath "ollama" -ArgumentList "run", "deepseek-r1:7b" -PassThru -NoNewWindow # 等待60秒 Start-Sleep -Seconds 60 try { Stop-Process -Id $process.Id -Force -ErrorAction Stop Write-Host "已中断本次下载,准备重新尝试..." } catch { Write-Host "error" } }
macOS / Linux 下在终端中执行:
#!/bin/bash whiletrue; do # 检查模型是否已下载完成 modelExists=$(ollama list | grep "deepseek-r1:7b") if [ -n "$modelExists" ]; then echo"模型已下载完成!" break fi # 启动ollama进程并记录 echo"开始下载模型..." ollama run deepseek-r1:7b & # 在后台启动进程 processId=$! # 获取最近启动的后台进程的PID # 等待60秒 sleep 60 # 尝试终止进程 ifkill -0 $processId 2>/dev/null; then kill -9 $processId# 强制终止进程 echo"已中断本次下载,准备重新尝试..." else echo"进程已结束,无需中断" fi done
4.1.2 通过网盘等第三方离线下载并导入 ollama 模型
可以通过国内的第三方离线下载模型文件,再导入到 ollama 中。详细参考 2.2 章节。
deepseek-r1 相关模型夸克网盘下载:
链接:https://pan.quark.cn/s/7fa235cc64ef 提取码:wasX
也可以从 魔塔社区、HuggingFace 等大模型社区搜索并下载 stuff 格式的模型文件。例如:
-
• https://modelscope.cn/models/unsloth/DeepSeek-R1-Distill-Qwen-7B-GGUF/files
-
• https://huggingface.co/unsloth/DeepSeek-R1-GGUF
4.1.3 从国内大模型提供站下载模型
ollama 支持从魔塔社区直接下载模型。其基本格式为:
ollama run modelscope.cn/{model-id}
一个模型仓库可能包含多个模型,可以指定到具体的模型文件名以只下载它。示例:
ollama run modelscope.cn/Qwen/Qwen2.5-3B-Instruct-GGUF # ollama run modelscope.cn/Qwen/Qwen2.5-3B-Instruct-GGUF:qwen2.5-3b-instruct-q3_k_m.gguf
下载 deepseek-r1 模型命令参考:
# deepseek-r1:7b ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-7B-GGUF:DeepSeek-R1-Distill-Qwen-7B-Q4_K_M.gguf # deepseek-r1:14b ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF:Q4_K_M # deepseek-r1:32b ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF:Q4_K_M
此外,也可以从 HF 的国内镜像站(https://hf-mirror.com)查找和拉取模型,方法与上述类似:
# 基本格式 ollama run hf-mirror.com/{username}/{reponame}:{label} # 示例 - 拉取 deepseek-r1:7b ollama run hf-mirror.com/unsloth/DeepSeek-R1-Distill-Qwen-7B-GGUF:Q4_K_M
4.2 ollama 服务设置允许局域网访问
默认情况下 API 服务仅允许本机访问,若需要允许局域网其他设备直接访问,可修改环境变量 OLLAMA_HOST 为 0.0.0.0,并修改 OLLAMA_ORIGINS 为允许的域名或 IP 地址。
环境变量设置示例:
# windows 命令提示符下执行: setx OLLAMA_HOST 0.0.0.0:11434 setx OLLAMA_ORIGINS * # macOS 终端下执行: launchctl setenv OLLAMA_HOST "0.0.0.0:11434" launchctl setenv OLLAMA_ORIGINS "*"
特别注意:
-
• 如果你是在云服务器等拥有公网IP的环境上部署,请谨慎做此设置,否则可能导致 API 服务被恶意调用。
-
• 若需要局域网其他设备访问,请确保防火墙等安全设置允许 11434 端口访问。
-
• 若需要自定义访问端口号,可通过环境变量
OLLAMA_HOST设置,如:OLLAMA_HOST=0.0.0.0:11435。
4.3 为 ollama API 服务访问增加 API KEY 保护
为云服务器部署的服务增加 API KEY 以保护服务
如果你是通过云服务器部署,那么需要特别注意服务安全,避免被互联网工具扫描而泄露,导致资源被第三方利用。
可以通过部署 nginx 并设置代理转发,以增加 API KEY 以保护服务,同时需要屏蔽对 11434 端口的互联网直接访问形式。
nginx 配置:
server { # 用于公网访问的端口 listen 8434; # 域名绑定,若无域名可移除 server_name your_domain.com; location / { # 验证 API KEY。这里的 your_api_key 应随便修改为你希望设置的内容 # 可通过 uuid 生成器工具随机生成一个:https://tool.lzw.me/uuid-generator if ($http_authorization != "Bearer your_api_key") { return 403; } # 代理转发到 ollama 的 11434 端口 proxy_pass http://localhost:11434; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } }
5 集成可视化工具
在部署了 ollama 并拉取了 deepseek 等模型后,即可通过命令行交互和 API 服务方式使用,但使用起来并不方便。
开源社区中有许多大模型相关的可视化工具,如 open-webui、chat-ui、cherry-studio、AnythingLLM 等,可以方便地集成 ollama API 服务,提供图形化界面使用,以实现聊天机器人、问答知识库等多元化应用。在官方文档中列举了大量较为流行的工具应用:https://ollama.readthedocs.io/quickstart/#web
我们后续会选择其中较为典型的工具进行集成和介绍。
5.1 示例:基于 docker 部署 open-webui 并配置集成 ollama 服务
Open WebUI 是一个开源的大语言模型项目,通过部署它可以得到一个纯本地运行的基于浏览器访问的 Web 服务。它提供了可扩展、功能丰富、用户友好的自托管 AI Web 界面,支持各种大型语言模型(LLM)运行器,可以通过配置形式便捷的集成 ollama、OpenAI 等提供的 API。
通过 Open WebUI 可以实现聊天机器人、本地知识库、图像生成等丰富的大模型应用功能。
在开始之前,请确保你的系统已经安装了 docker。
接着拉取大语言模型 deepseek-r1:8b 和用于 RAG 构建本地知识库的嵌入模型 bge-m3:
ollama pull deepseek-r1:8b ollama pull bge-m3
然后新建文件 docker-compose.yml,内容参考:
services: open-webui: image:ghcr.io/open-webui/open-webui:main environment: -OLLAMA_API_BASE_URL=http://ollama:11434/api -HF_ENDPOINT=https://hf-mirror.com -WEBUI_NAME="LZW的LLM服务" # 禁用 OPENAI API 的请求。若你的网络环境无法访问 openai,请务必设置该项为 false # 否则在登录成功时,会因为同时请求了 openai 接口而导致白屏时间过长 -ENABLE_OPENAI_API=false # 设置允许跨域请求服务的域名。* 表示允许所有域名 -CORS_ALLOW_ORIGIN=* # 开启图片生成 -ENABLE_IMAGE_GENERATION=true # 默认模型 -DEFAULT_MODELS=deepseek-r1:8b # RAG 构建本地知识库使用的默认嵌入域名 -RAG_EMBEDDING_MODEL=bge-m3 ports: -8080:8080 volumes: -./open_webui_data:/app/backend/data extra_hosts: # - host.docker.internal:host-gateway
这里需注意 environment 环境变量部分的自定义设置。许多设置也可以通过登录后在 web 界面进行修改。
在该目录下执行该命令以启动服务:docker-compose up -d。成功后即可通过浏览器访问:http://localhost:8080。
服务镜像更新参考:
# 拉取新镜像 docker-compose pull # 重启服务 docker-compose up -d --remove-orphans # 清理镜像 docker image prune
- • open-webui 详细文档参考:https://docs.openwebui.com/getting-started/env-configuration
可选:开启“联网搜索”功能
操作路径:设置 - 联网搜索 - 启用联网搜索
当前已支持接入的联网搜索引擎中,在不需要魔法上网的情况下,有 bing 和 bocha 可以选择接入。基本只需要前往注册并获取 API KEY 回填到这里即可。如果需要保护隐私数据,请不要开启并配置该功能。
- • 博查文档:https://aq6ky2b8nql.feishu.cn/wiki/XgeXwsn7oiDEC0kH6O3cUKtknSR
总结与参考
通过以上内容,我们了解了 ollama 在国内环境下的安装使用方法,并介绍了因为国内网络特色导致安装过程可能会遇到的常见问题及解决办法。希望这些内容对你有所帮助,如果你有任何问题或建议,欢迎在评论区留言交流。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
大模型就业发展前景
根据脉脉发布的《2024年度人才迁徙报告》显示,AI相关岗位的需求在2024年就已经十分强劲,TOP20热招岗位中,有5个与AI相关。
 字节、阿里等多个头部公司AI人才紧缺,包括算法工程师、人工智能工程师、推荐算法、大模型算法以及自然语言处理等。
字节、阿里等多个头部公司AI人才紧缺,包括算法工程师、人工智能工程师、推荐算法、大模型算法以及自然语言处理等。

除了上述技术岗外,AI也催生除了一系列高薪非技术类岗位,如AI产品经理、产品主管等,平均月薪也达到了5-6万左右。
AI正在改变各行各业,行动力强的人,早已吃到了第一波红利。
最后
大模型很多技术干货,都可以共享给你们,如果你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 5405
5405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









