






一直想试试大模型微调,正巧最近有个WeClone项目很火,即使用自己的聊天数据来微调LLM,也算是我无趣的生活中难得的落地场景了。
GitHub - xming521/WeClone[1]
眼馋了规划了快两个月,今天终于把模型跑出来了,过程中有一些学习和意外收获,以及发现在云端进行训练和推理比预想中要简单和低成本,我实际操作下来我仅仅在下班后花了三个多小时和不到5块,就得到了自己的数字分身。可以说只要拥有大学本科级别的计算机素养,就可以几乎无门槛上手LLM的微调和端侧部署。
话不多说,先看效果(Ollama第一次对话冷启动速度有点慢):
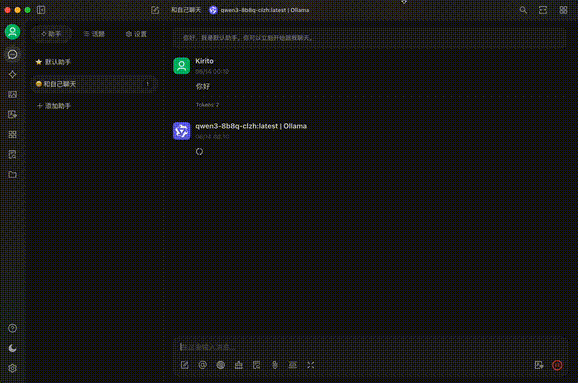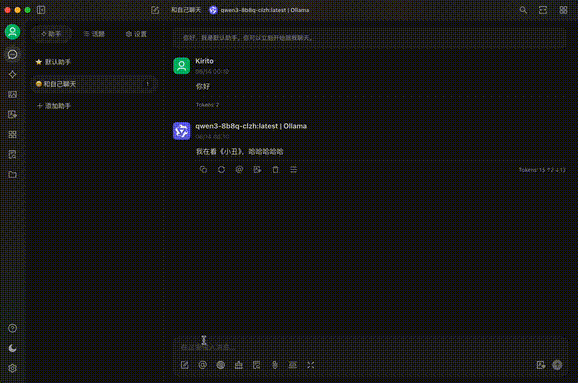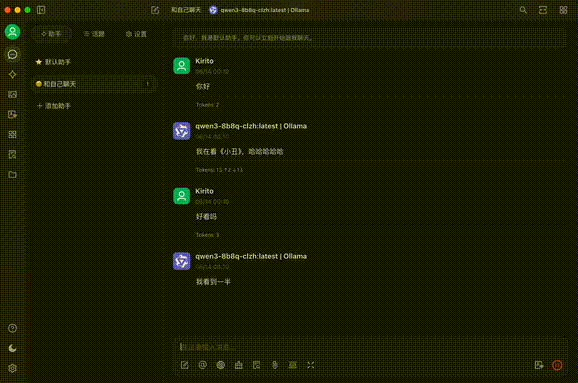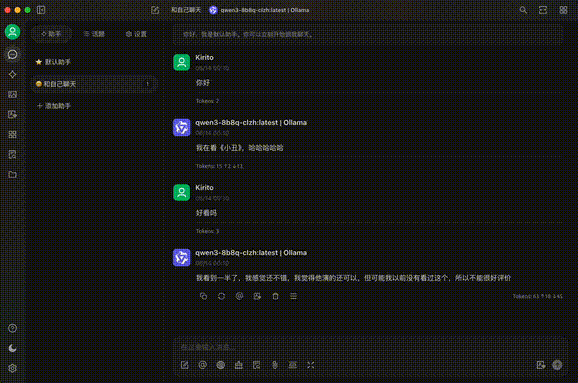
基本概念
在开始动手之前,我们需要先了解一些机器学习和语言模型相关的基础概念,下面是我个人一些简化版的见解,如果大家已有相关基础可以跳过直接看实践部分。
训练模型的本质
现在我们说的模型一般都指神经网络模型,可以通俗地理解为一种通过大量简单线性运算叠加而对目标函数进行拟合的一种「近似函数」,所以也有人把现阶段的人工智能称为「高级统计学」。
总的来说,我们可以把「模型」看作一个「黑盒函数」,它获取一个输入,经过一些内部的运算,得到一个输出。
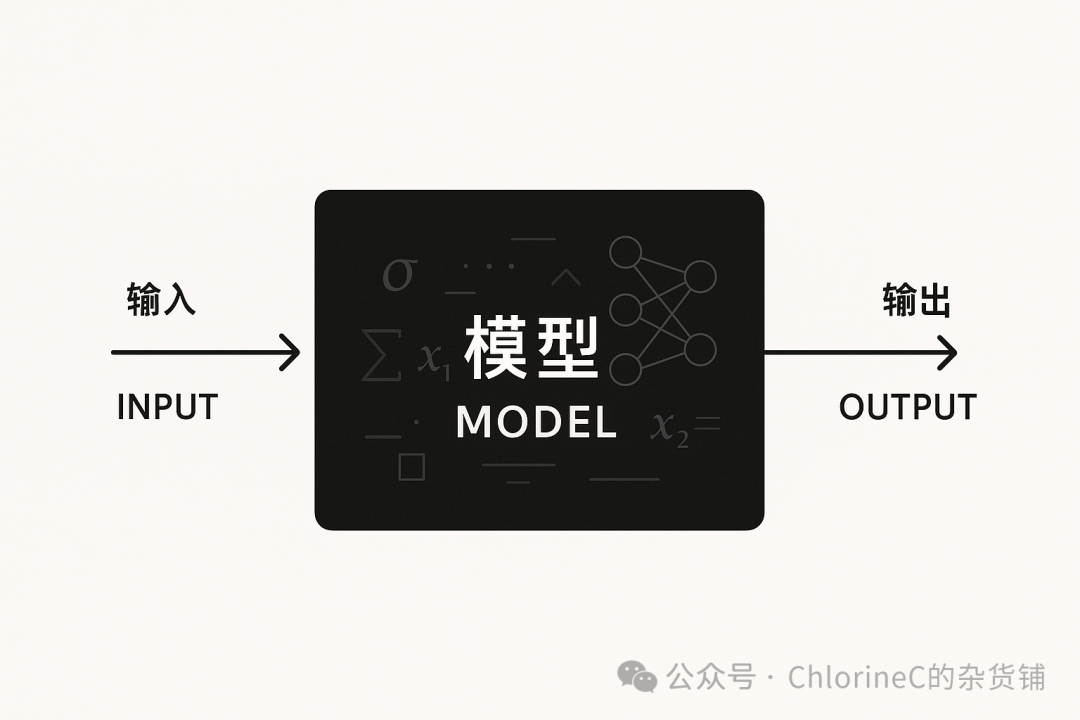
由于我们并不能真的知道「黑盒函数」内进行的每次运算对应的含义(特别是在LLM时代后),所谓「训练模型」也是一个只关注结果的过程,即给定一对输入和预期输出,当模型的实际输出与预期输出越接近,模型就会得到更高的评分,而「训练模型」的过程就是模型通过不断调整自身运算过程(也就是自己的参数)来提高整体评分的过程,这也就是传统的「有监督学习」。
因此模型的训练最关键的因素其实就是数据,毕竟有数据才有训练的方向。
预训练与微调
随着神经网络的不断发展,人们逐渐开始发现每次都要从头开始训练模型实在有点麻烦,就像工厂招工人每次都只能从婴儿开始培养,如果能直接招到义务教育毕业的再培养就简单多了。
其实模型的有些能力本就是通用的,比如对文本的基本识别能力等,这里暂且称之为「泛化智能」,即对通用的事物有一定的感知力,个人印象里预训练模型早年最出名的就是谷歌的BERT了,在GPT3.5出来之前在NLP领域可谓是风头无两,当年还拿BERT微调去做过大创。
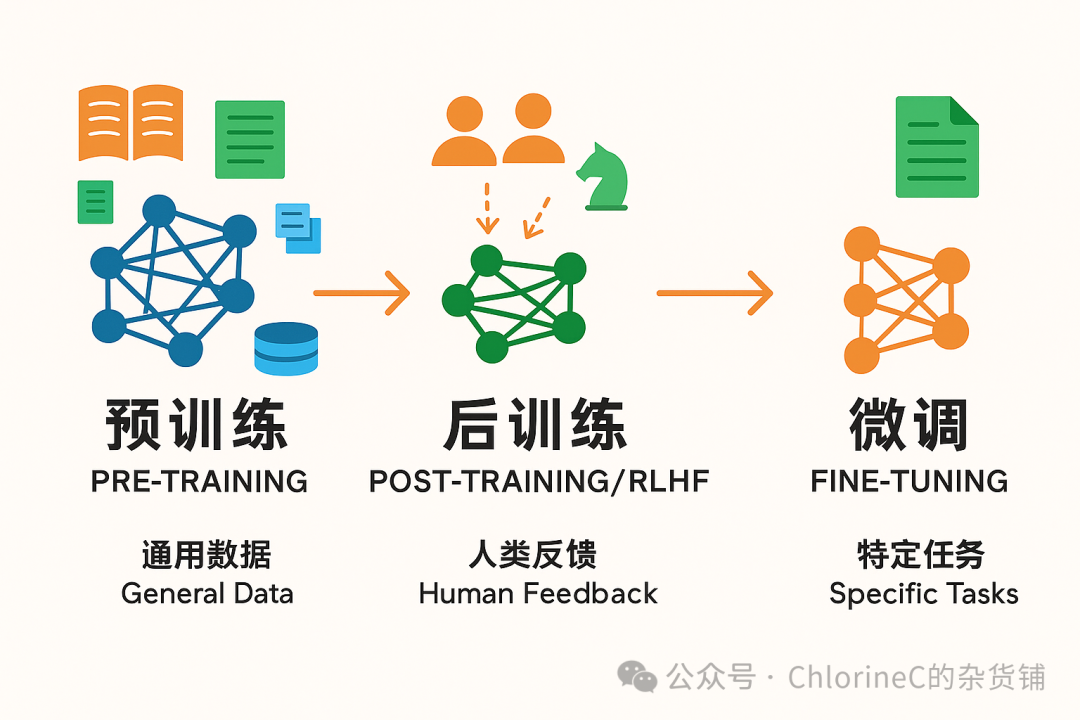
当模型已经拥有一定程度的泛化智能后,我们就需要教会他在特定领域的知识,来优化他做特定任务的表现,具体就是用一些领域特化的数据继续「训练」模型,也就是后训练(post-training)或者微调(fine-tuning)。
后训练和微调的目的都是为了增强模型在某个特定领域或任务的表现,区别点就在于调整规模,微调一般数据集大小和调整范围都远小于后训练,上手门槛也低很多。
LoRA
上面提到,模型的本质就是一堆线性运算的叠加,而模型的参数就是决定这一堆运算具体执行过程的「控制量」,训练模型就是在调整这些参数。

那么,在现阶段大语言模型(如deepseek,Qwen等)已经有足够强的泛化智能的情况下,有没有一种方法可以低成本地优化模型的特化任务的方法(即微调)呢?
有的兄弟,有的。LoRA(Low-Rank Adaptation,低秩自适应)正是你所需要的。
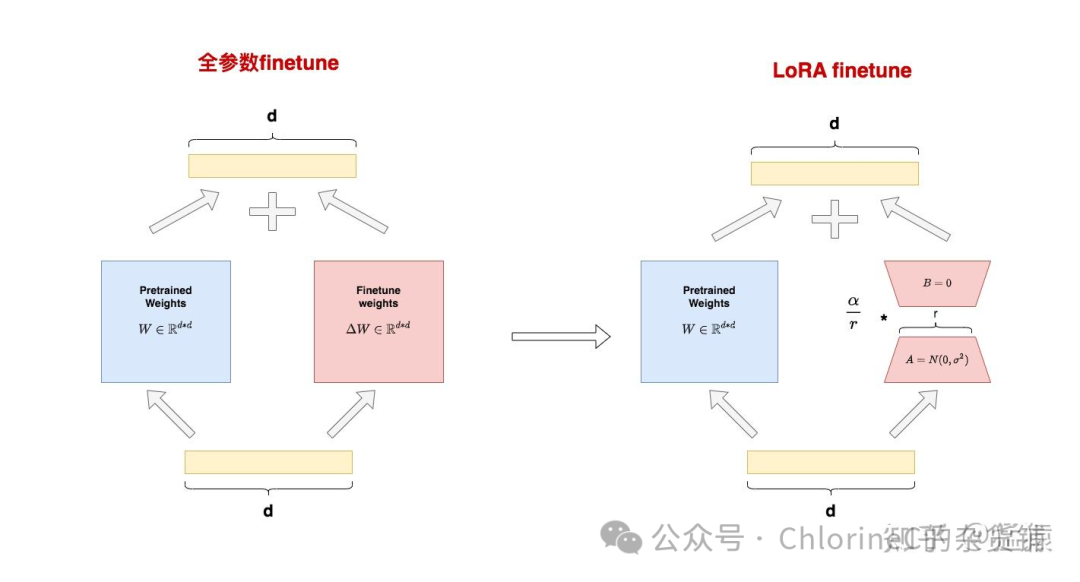
首先我们先把模型这一堆参数看作是一个矩阵,现在的LLM参数量一般都比较大,小一点的也有40~70亿(如qwen和llama的小模型),大一点的一般300亿以上(如deepseek),而这些参数我们就可以看作是「智能」本身。
我们要做的就是不动这些已有的参数确保原有的智能不会被我们弄坏,并在此基础上做一些小手脚,增加一些我们可以调整的参数,来达到微调的效果。
LoRA原理(可跳)
那LoRA是怎么做到的呢?这里涉及到一些简单的数学原理知识,但并不影响后续理解。
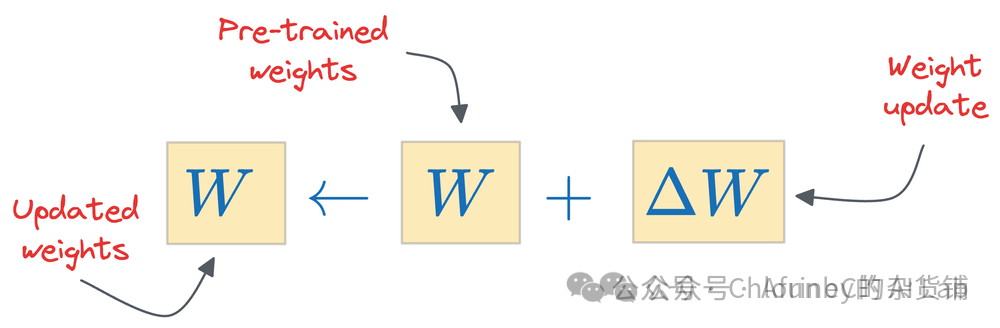
微调本质上是在新数据集上更新模型权重,整个微调过程中模型权重变化可以近似看作下面的公式:
接着我们再继续往推理阶段走,经过简单的线性代数规则变化,我们可以得到一个新的公式:
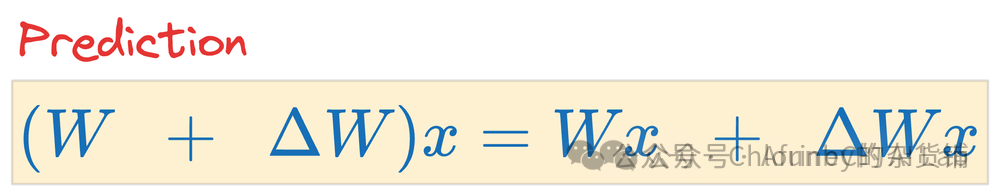
没错,我们其实可以在「锁住」原有权重的基础上,在旁边新开一个一样大的矩阵,就可以只调整新矩阵的参数,最后进行合并,也能达到预期的效果。
但是呢,现在模型的参数量太大了,如果要新建一个一样大的矩阵无异于从头训练,那我还不如直接调原模型呢,所以我们还要进一步简化。
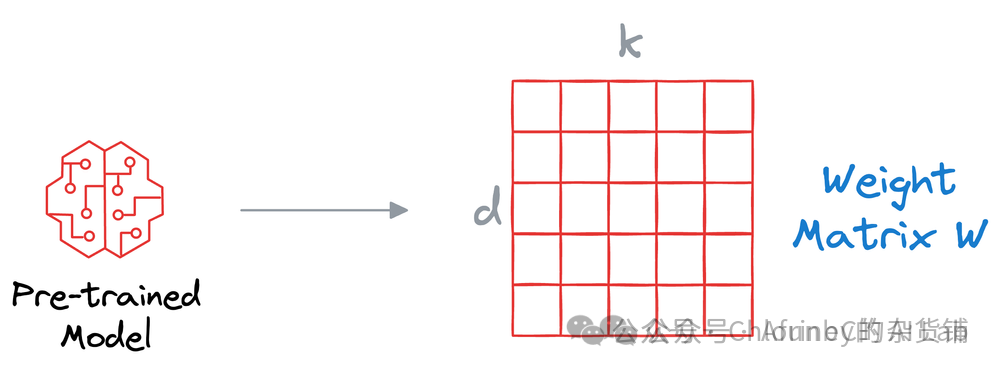
假如我们原模型的参数矩阵是 dxk,那么我们要得到一个相同大小的矩阵,除了直接创建,我们还可以通过简单的线性运算,让两个 dxr 和 rxk的矩阵相乘得到。
这里拆出来的两个小矩阵,就是我们LoRA中所提到的「低秩矩阵」了。
矩阵的秩(rank)是矩阵中线性无关的行或列的最大数量,从意义上来看就是「衡量数据独立信息量」,而当一个矩阵中线性无关的行或列数远小于行或列总数时,这个矩阵就是一个低秩矩阵,代表该矩阵的独立信息密度低。而当所有行或列都能用一行或一列线性表示出来的时候,那这个矩阵的秩r=1,是最低的情况。
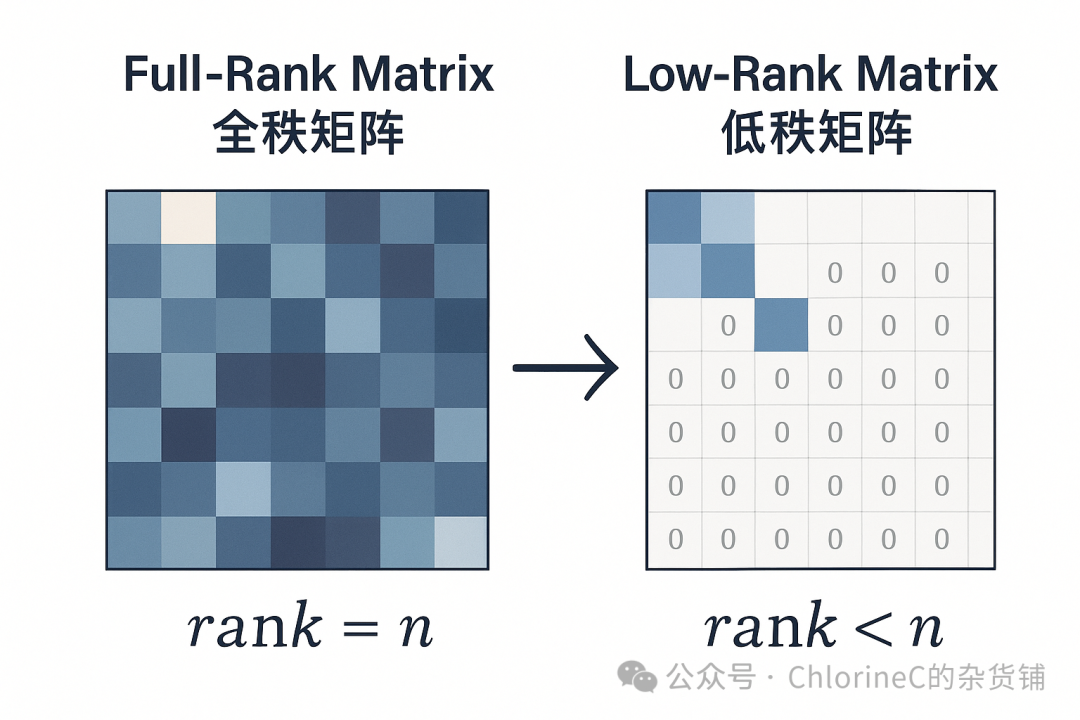
这里的r是我们能控制的量,r越小参数越少,成本越低;r越大参数越多,上限越高,一般由任务复杂度和设备性能综合决定。
模型微调与端侧部署实践
在开始启动前,你需要具备至少以下条件:
-
一台Windows电脑(或运行在虚拟机上的Windows)用于WX数据导出
-
大学本科级别的计算机基础素养,包括基础的PyTorch机器学习训练经验、Linux远程开发经验和科学上网能力
由于WeClone项目已经帮我们预先配置好了大部分超参数和数据管线(pipeline),这里我们几乎不需要关心框架底层的运行逻辑,整个逻辑显得异常轻松。
这里我们使用我心目中的国产开源大模型一哥Qwen的最新Qwen3系列模型,参数量为8b,为大部分中高性能GPU(特别是我的M3Pro+36G内存Mac)能轻松本地跑的理想参数量,显存要求一般在16G左右。
下面是我让Perplexity整理的不同参数规模模型在INT8量化精度下的显存和算力要求表,右侧有推荐设备,大家可以根据下表和自己的设备性能选择自己合适的参数规模。
| 参数数目) | 模型大小(GB,INT8) | 估计显存需求(GB,含20%冗余) | 推荐NVIDIA显卡(显存) | 推荐Mac设备(统一内存) | 备注 |
|
1B(10亿) |
1 GB |
1.2 GB |
RTX 3050 (8GB), RTX 3060 (12GB) |
MacBook Air M2 (8-16GB) |
轻量级模型,适合入门级显卡和普通Mac |
|
4B |
4 GB |
4.8 GB |
RTX 3060 (12GB), RTX 4060 Ti (16GB) |
Mac Studio M1 Max (32GB) |
中小规模模型,适合中端显卡和高配Mac |
|
8B |
8 GB |
9.6 GB |
RTX 3070 (8-16GB), RTX 4070 (12GB) |
Mac Studio M1 Ultra (64GB) |
需要至少12GB显存,Mac需高统一内存配置 |
|
13B |
13 GB |
15.6 GB |
RTX 4080 (16GB), RTX 4090 (24GB) |
Mac Pro M2 Ultra (192GB) |
大模型,显存需求较高,RTX 4080起步,Mac需超大统一内存 |
|
70B |
70 GB |
84 GB |
NVIDIA RTX 6000 Ada (48GB+多卡) |
Mac多机分布式(理论) |
超大模型,单卡难以满足,需多卡或专业服务器 |
训练数据集和环境准备
WX数据导出
这里我们使用WeClone项目官方推荐的 来获取微信导出的聊天数据,具体操作涉及到敏感信息这里就不展开描述,详情可以到项目的推荐博客中了解。
需要注意的是,该导出应用目前仅支持Windows上微信4.0以下版本,务必注意版本正确。
针对手机用户,可以在「设置-通用-聊天记录迁移与备份-迁移-迁移到电脑」选项中,将聊天记录迁移到电脑,若全部聊天记录传输过长,可以只迁移指定的聊天记录并选择只迁移文字,因为导出也只能单条导出,且本教程不涉及多模态数据微调。
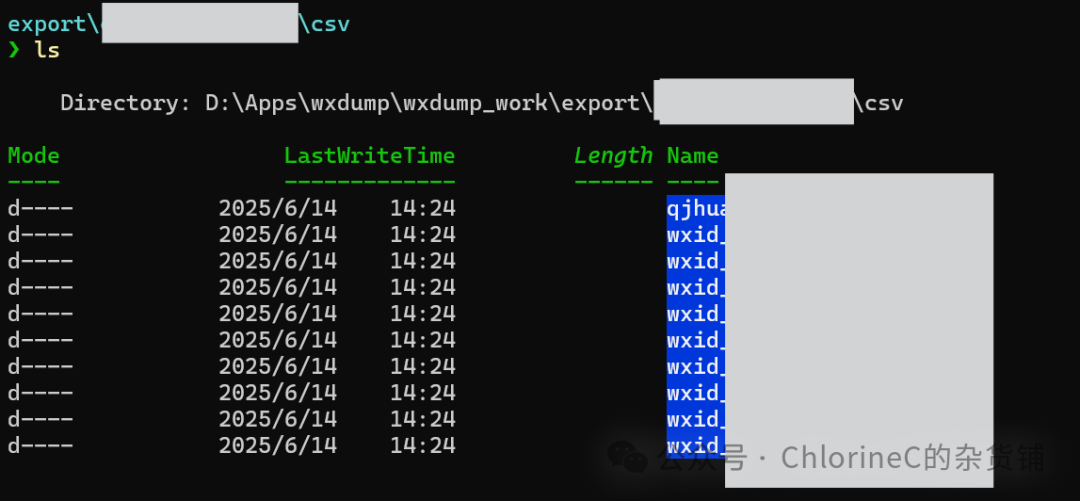
导出完成后,你会获得一个下面格式的目录,csv目录下存放着每个聊天对应的WXID,其中存放着分片的CSV目录,我们可以将这个目录整个打包成zip以便后续使用。
开发环境准备
本文编写时间为2025年6月14日,操作时请注意时效性
这里我重点参考了项目原作者的博客,有相关基础的推荐大家直接阅读原文
接下来是我个人的步骤简化版:
-
选择一个云算力平台,这里我用的是作者推荐的 https://www.autodl.com/home[2]
-
注册账号并租借一个服务器,这里我训练的是7~8B参数的小型模型,推荐选择4090即可,配置截图如下,供大家参考
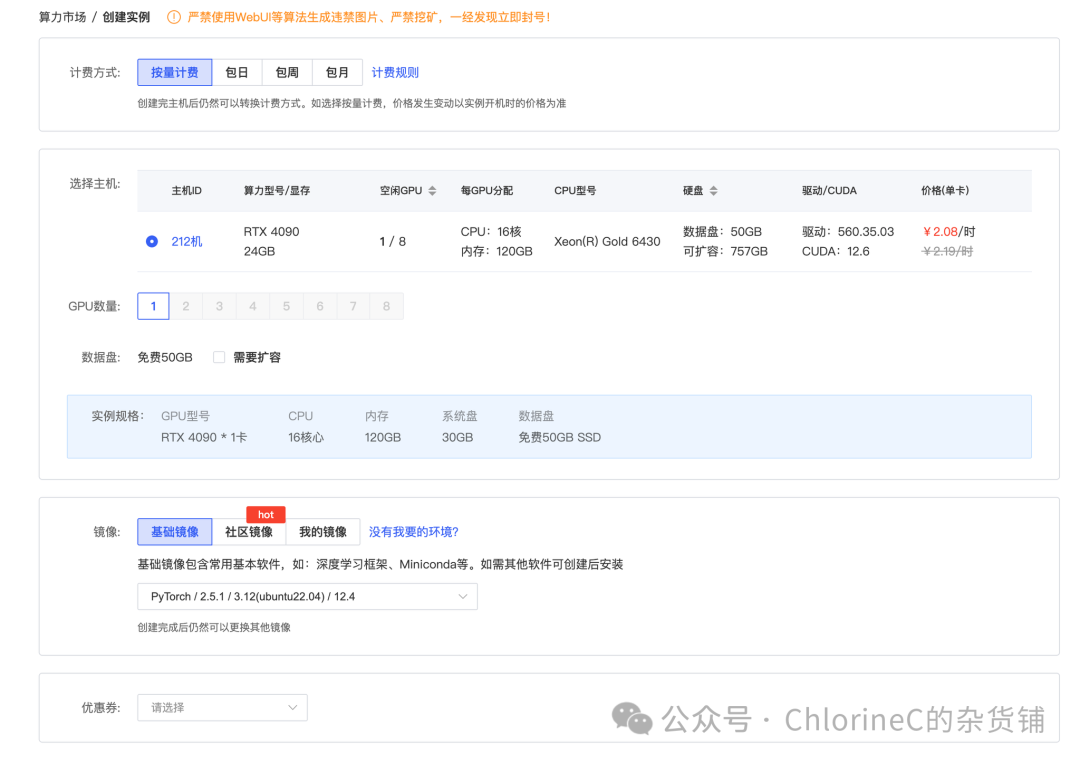
-
初始化项目,参考原博客,命令如下
# 初始化系统环境与相关依赖
apt-get update && apt-get install git
source /etc/network_turbo # 启用学术加速
pip install uv
# 搭建开发环境,就不一一展开说了
cd /root/autodl-tmp
git clone https://github.com/xming521/WeClone.git
cd WeClone
uv venv .venv --python=3.10 # 你可以指定已安装的 Python 3.10+ 版本
source .venv/bin/activate
uv pip install --group main -e . # 安装项目依赖
# 检查cuda
python -c "import torch; print('CUDA是否可用:', torch.cuda.is_available()); print('CUDA版本:', torch.version.cuda); print('PyTorch版本:', torch.__version__)"
-
下载原模型,这里使用Qwen3-8B,这里开始下载了我们就可以新起一个shell session并行开始下一步了
# 复制配置文件模板
cp settings.template.jsonc settings.jsonc
# 下载模型,如果使用Qwen系列的话推荐使用ModelScope,国内源速度更快
# https://modelscope.cn/models/Qwen/Qwen3-8B
uv pip install modelscope
modelscope download --model Qwen/Qwen3-8B --local_dir ./Qwen3-8B
-
将上一步打包好的
csv.zip通过云端的Jupyter Notebook或SCP/FTP等工具上传到/root/autodl-tmp/WeClone/dataset/中并解压,最后得到如WeClone/dataset/csv/张三/聊天记录.csv结构的目录 -
在WeClone目录下,执行数据清洗命令
weclone-cli make-dataset #在WeClone根目录下执行该命令
数据集格式概述
既然要训练聊天语言模型,那自然要让数据集遵循一定的格式,让他看起来像「打了标的数据」,至少要划分哪些是用户输入,哪些是模型输出。
但由于大模型早期的分裂发展,目前暂时没有一个统一的数据集标准。不过,只要能正确区分用户和模型消息,就可以正常进行训练,所以我们只需要找到一个数据结构来描述角色区分,剩下的就交给分词器(tokenizer)就好。
更多信息可参考hugging-face这篇博客
https://github.com/huggingface/blog/blob/main/zh/chat-templates.md
具体到本项目的话,由于我们采用了LLamaFactory作为训练框架,数据集结构为默认的ShareGPT格式,最终输出的数据集存放在 WeClone/dataset/csv_result/sft/sft_my.json中。
数据格式如下图所示,其中User为其他用户输入,Assistant则为本人输出:
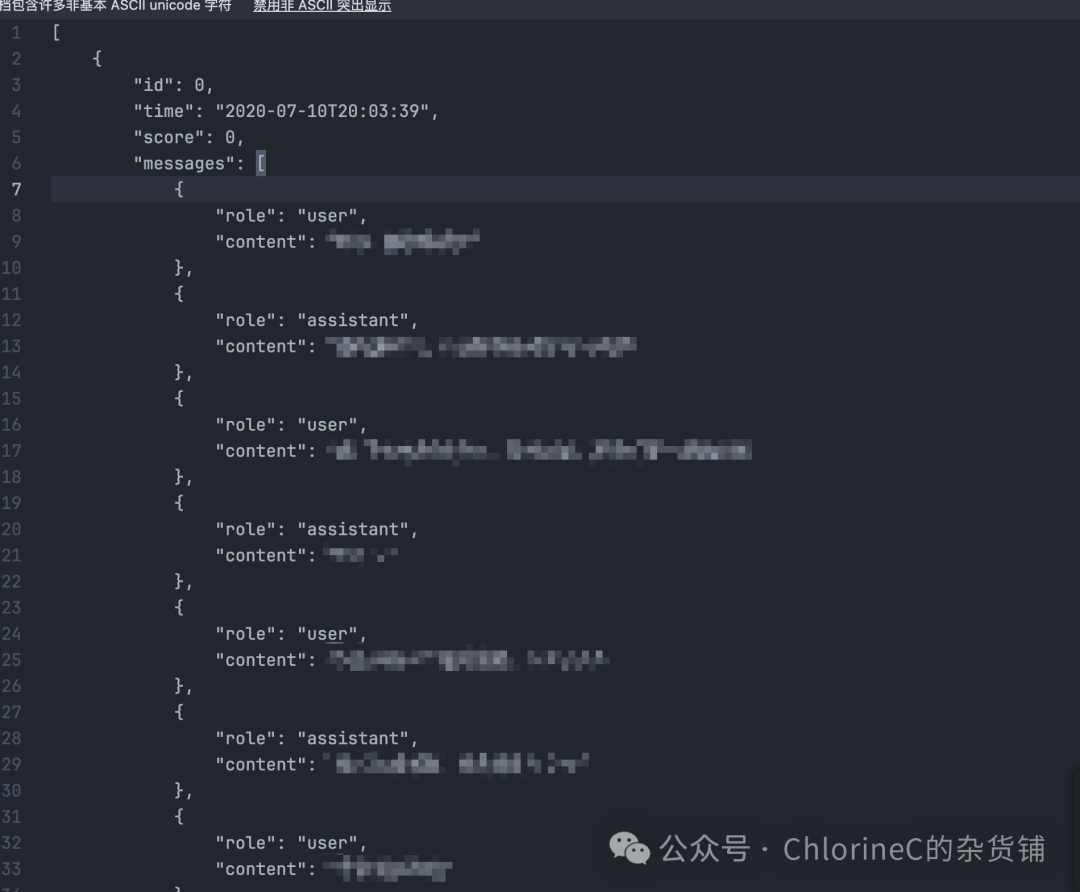
开始训练
训练效率优化
这里我使用几个常用的工具来优化训练过程的效率,大家可以针对自己的硬件性能情况做权衡,训练过程越节省,微调效果可能会受到更大影响。
-
flash-attn:把大块的注意力计算拆成很多小块,边算边用显存里最快的缓存存数据,避免一次性把所有数据都放进显存,减少了数据来回搬运的时间和空间浪费。这样做不仅让计算变得更快,还省了很多显存,特别适合处理很长的文本或大模型。简单来说,就是“分块计算+聪明用缓存+少存中间结果”,让注意力机制又快又省内存,训练和推理速度能提升几倍
-
qlora:简单来说,QLoRA就是“先量化再微调”,将原来的FP16先量化为INT8,然后低秩矩阵就可以用INT8精度创建了,用更少的资源实现了大模型的高效适应和训练
-
unsloth:通过用 OpenAI 的 Triton 语言手写底层 GPU 内核和手动实现反向传播,显著减少显存占用(约70%)并提升训练速度(约2倍),且不损失模型准确度。它支持4bit量化微调,兼容多种主流模型和硬件,使得在普通GPU上也能快速、高效地完成大模型微调,极大简化了训练流程并节省了资源
首先我们需要安装上面步骤中需要的依赖项,这里可能遇到一些编译速度相关的问题,可以通过预编译wheel规避:
# 如果遇到flash-attn编译缓慢可以先安装ninja后再使用pep517安装
uv pip install ninja
pip install flash-attn –no-build-isolation –use-pep517
# 安装其他依赖
uv pip install bitsandbytes>=0.39.0 #QLora需要
uv pip install unsloth # unsloth需要
然后配置 settings.jsonc ,主要是修改common_args中量化相关的参数:
{
"version": "0.2.23",
"common_args": {
"model_name_or_path": "./Qwen3-8B",
"adapter_name_or_path": "./model_output", //同时做为train_sft_args的output_dir
"template": "qwen",
"default_system": "请你扮演一名人类,不要说自己是人工智能",
"finetuning_type": "lora",
"trust_remote_code": true,
"quantization_bit": 4, //支持值:2 / 4 / 8,数值越低显存越省,但推理速度和效果可能略有下降。
"quantization_type": "nf4",
"double_quantization": true,
"quantization_method": "bitsandbytes",
"use_unsloth": true,
},
"cli_args": {
"full_log": false
},
"make_dataset_args": {
//数据处理配置
"platform": "wechat",
"include_type": [
"text"
],
"blocked_words": [ // 禁用词
"例如 姓名",
"例如 密码",
"//....."
],
"single_combine_strategy": "time_window", // 单人组成单句策略
"qa_match_strategy": "time_window", // 组成qa策略
"single_combine_time_window": 2, // 单人组成单句时间窗口(分钟),
"qa_match_time_window": 5, // 组成qa时间窗口(分钟),
"combine_msg_max_length": 256, // 组合后消息最大长度 配合cutoff_len 使用
"prompt_with_history": false, // 是否在prompt中包含历史对话
"clean_dataset": {
"enable_clean": false,
"clean_strategy": "llm",
"llm": {
"accept_score": 2, //可以接受的llm打分阈值,1分最差,5分最好,低于此分数的数据不会用于训练
}
},
"online_llm_clear": false,
"base_url": "https://xxx/v1",
"llm_api_key": "xxxxx",
"model_name": "xxx", //建议使用参数较大的模型,例如DeepSeek-V3
"clean_batch_size": 10,
"vision_api": {
"enable": false, // 设置为 true 来开启此功能
"api_key": "xxx",
"api_url": "https://xxx/v1", // 例如阿里云,或替换为其他兼容OpenAI的API地址
"model_name": "xxx", // 要使用的多模态模型名称,例如qwen-vl-max
"max_workers": 5// 并行调用API的线程数,最多不要超过8
}
},
"train_sft_args": {
//微调配置
"stage": "sft",
"dataset": "chat-sft",
"dataset_dir": "./dataset/res_csv/sft",
"use_fast_tokenizer": true,
"lora_target": "q_proj,v_proj",
"lora_rank": 4,
"lora_dropout": 0.3,
"weight_decay": 0.1,
"overwrite_cache": true,
"per_device_train_batch_size": 8,
"gradient_accumulation_steps": 4,
"lr_scheduler_type": "cosine",
"cutoff_len": 256,
"logging_steps": 10,
"save_steps": 100,
"learning_rate": 1e-4,
"warmup_ratio": 0.1,
"num_train_epochs": 2,
"plot_loss": true,
"fp16": true,
"flash_attn": "fa2",
// "deepspeed": "ds_config.json" //多卡训练
},
"infer_args": {
"repetition_penalty": 1.2,
"temperature": 0.5,
"max_length": 50,
"top_p": 0.65
}
}
开始训练
一切准备就绪后,直接运行一行指令即可开始训练:
weclone-cli train-sft
开始训练后就能看到熟悉的模型训练界面了,我这里跑了40多分钟,这个时间可以不用一直盯着他,不要关闭SSH Shell Session即可,而且云端跑也不会占用本地资源。
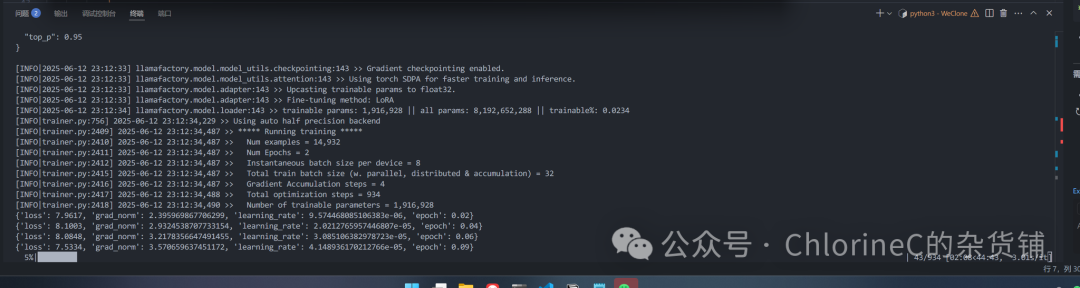
测试模型输出
在开始之前,我们要先删除掉我们在训练过程中在 common_args 中添加的量化参数:
{
"common_args": {
"model_name_or_path": "./Qwen3-8B",
"adapter_name_or_path": "./model_output", //同时做为train_sft_args的output_dir
"template": "qwen",
"default_system": "请你扮演一名人类,不要说自己是人工智能",
"finetuning_type": "lora",
"trust_remote_code": true,
"quantization_bit": 4, //支持值:2 / 4 / 8,数值越低显存越省,但推理速度和效果可能略有下降。
"quantization_type": "nf4",
"double_quantization": true,
"quantization_method": "bitsandbytes",
"use_unsloth": true,
},
}
然后运行浏览器Web UI Demo,默认运行在http://127.0.0.1:7860[3]上。
weclone-cli webchat-demo
这时如果你使用VSCode的RemoteSSH的话,会自动进行端口映射,其他方式则需要手动进行SSH端口映射,进入WebUI后会显示熟悉的测试界面了。
量化并导出模型
这里我们选择使用 来量化和导出gguf格式的模型,一种可以直接在Ollama上运行的模型格式。
我们打开 WeClone/exported 目录下,可以看见 .safetensors 格式的初始模型参数和一些metadata。
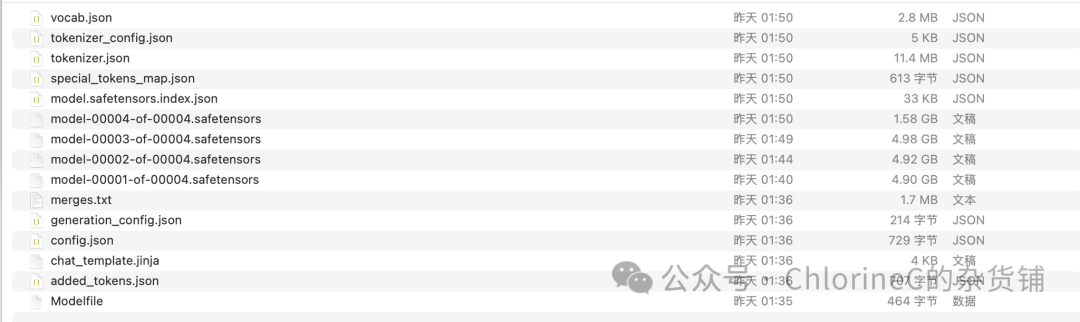
确认无误后,我们先克隆llama.cpp的官方仓库,并遵守编译文档[4]一步步进行安装和导出操作:
# 在WeClone根目录下执行下面的操作
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
# 先编译native部分,这里实测使用CPU_output即可,编译cuda时间巨长
# 这一步大概耗时10min左右
cmake -B build
cmake --build build --config Release
# 编译完成后安装python部分,确保在之前的venv中,而且直接用uv会报错
# 这一步大概耗时5min左右
pip install -r requirements.txt
# 导出gguf,这一步大概耗时10min左右
cd .. # 回到根目录
python llama.cpp/convert_hf_to_gguf.py exported --outtype q8_0 --verbose --outfile ./qwen3-8b-fine-tuned-q8.gguf
端侧部署模型
下载模型权重
最后,我们只需要从云端上把单个gguf文件下载下来即可开始运行了。
这里我们使用了AutoDL平台连接第三方网盘的功能,我使用了阿里云盘,具体可以参考官方文档,个人实测速度还挺快的。
端侧运行
这里我们使用了Ollama在本地部署和运行模型。
首先我们在模型同级别目录创建一个 ModelFile.txt 来给予模型一些初始设置:
FROM qwen3-8b-fine-tuned-q8.gguf
SYSTEM """
请你扮演一名人类,不要说自己是人工智能
"""
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"""
PARAMETER stop "<|im_end|>"
PARAMETER stop "<|endoftext|>"
PARAMETER stop "<|im_start|>"
PARAMETER num_ctx 4096
PARAMETER temperature 0.7
PARAMETER top_p 0.9
PARAMETER num_predict 512
然后执行下面的命令在Ollama中创建对应的模型:
ollama create qwen3-8b8q-fine-tuned -f ModelFile.txt
创建完毕后,就可以在任何喜欢的地方和自己对话啦,你也可以尝试进一步将其部署到自己的聊天机器人上,这就不在本文的讨论范围内了。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









