






前言
不得不说,Qwen真的是太卷了,目前看来其基座能力已经稳居开源大哥大的宝座,并且与大多数闭源比也丝毫不逊色,估计很多公司的基座团队已经在被 judge 训基座的意义了。
Qwen的开源架势一如既往的凶猛,这更让我坚定的认为基座战争结束了,接下来是应用百花齐放的时候了,大家这时候更应该专注于 SFT 和 RLHF了。
模型架构
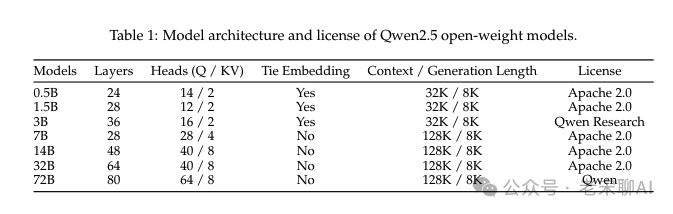
架构与Qwen2 保持一致:
-
注意力机制:GQA
-
激活函数:SwiGLU
-
位置编码:ROPE
-
注意力机制中的 QKV bias
-
归一化:RMSNorm
Pretrain
预训练数据
-
更好的数据过滤:采用Qwen2-instruct 模型作为数据质量过滤器,进行更加细致多维度的评估,从而在多种语言中更有效的保留高质量训练数据并过滤掉低质量样本。
-
更好的数学和代码数据:整合了Qwen2.5-Math 和 Qwen2.5-Coder 的训练数据,这种数据整合策略非常有效。
-
更好的合成数据:在数学,代码,知识领域,利用了Qwen2-72B-Instruct 和 Qwen2-Math-72B-Instruct 生成高质量的合成数据,然后使用奖励模型和专门的Qwen2-Math-RM-72B模型进行严格过滤。
-
更好的数据混合:采用Qwen2-Instrct对不同领域的内容进行分类和平衡。有以下发现:
-
电子商务,社交媒体,娱乐等领域在网络规模数据中占比过高,往往包含重复,模板化或机器生成的内容。 对这批数据进行下采样。
-
技术,科学,学术研究等虽然包括更高质量的信息,但代表性不足。对这批数据进行上采样。
-
训练数据的总规模扩展到18T tokens
长上下文预训练
-
两阶段预训练:初始预训练长度4096,然后是扩展阶段处理更长上下文(32768)
-
采用ABF技术将 ROPE 从10000 增加到 1000000
-
对于Qwen2.5-Turbo,四阶段渐进式上下文扩展策略:32768->65536->131072->262144,rope基频 10000000。
-
每个阶段采用 40%当前最大长度序列和60%较短的序列。
-
增强模型推理阶段处理更长序列的能力:YARN,DCA。通过这两个手段可以实现序列长度四倍的扩增。并且这些方法既能提高长文本的处理能力,还能保持在短文本上的表现。
Post-Pretrain
SFT
构建了超过一百万SFT数据集,并针对关键领域进行数据合成增强。训练参数:训练长度 32768,epoch=2, lr从7*10-6缩减到 7 * 10-7。weight decay=0.1, grad clip= 1.0
-
Long Sequence Generation:采用 back-translation 来从长文本数据中生成query,然后施加长度约束,最后再用Qwen2过滤掉低质量的配对数据。
-
Mathematics:引入 Qwen2.5-Math 中的COT数据。为保证高质量,采用 rejection sampling + reward model 以及带注释的答案进行指导,逐步生成推理过程。
-
Coding:引入 Qwen2.5-Coder 中的数据。
-
Instruction-following:为确保高质量的指令遵循数据,我们实施了严格的基于代码的验证框架。在这种方法中,大语言模型生成指令及其相应的验证代码,以及用于交叉验证的全面单元测试。
-
Structured Data Understanding(结构化数据):开发了一个全面的结构化理解数据集,涵盖传统任务(如表格问答、事实验证、错误纠正和结构理解)以及涉及结构化和半结构化数据的复杂任务。
-
Logical Reasoning(逻辑推理):为增强模型的逻辑推理能力,我们引入了涵盖各个领域的 70,000 个新查询,包括选择题、判断题和开放式问题。模型经过训练,能够系统地处理问题,采用演绎推理、归纳概括、类比推理、因果推理和统计推理等一系列推理方法。
-
Cross-Lingual Transfer(跨语言迁移):使用翻译模型将高资源语言的指令翻译成各种低资源语言,从而生成相应的响应候选。为确保这些响应的准确性和一致性,我们评估每个多语言响应与其原始对应响应之间的语义对齐。
-
Robust System Instruction(系统提示):构建了数百个通用系统提示,以提高后训练中系统提示的多样性,确保系统提示与对话之间的一致性。
-
Response Filtering(Response 过滤):采用多种自动打标系统,只有被所有评分系统认为完美无缺的响应才会被保留。
RLHF
采用两阶段的 RLHF:
Offline RL:该阶段专注于 RM Model 难以评估的领域如推理,数学,编码,指令遵循等领域。在该阶段,我们将通过我们质量检查的Response当做正例,没有通过的Response 当做负例。为了进一步提高训练的可靠性和准确性,同时使用人工和自动审查流。最终构建了15w个训练对的数据集。
Online RL:主要利用RM Model 检测 Response 质量差别,通过制定了一套标准来定义数据:
-
Truthfulness(真实性):响应必须基于事实准确性,忠实地反映提供的上下文和指令。模型应避免生成虚假或无根据的信息。
-
Helpfulness(有用性):模型的输出应该真正有用,有效地解决用户的查询,同时提供积极、引人入胜、有教育意义和相关的内容。它应该精确地遵循给定的指令并为用户提供价值。
-
Conciseness(简洁性):响应应该简洁明了,避免不必要的冗长。目标是以清晰高效的方式传达信息,而不会用过多细节淹没用户。
-
Relevance(相关性):响应的所有部分都应与用户的查询、对话历史和助手的上下文直接相关。模型应调整其输出以确保与用户的需求和期望完美匹配。
-
Harmlessness(无害性):模型必须优先考虑用户安全,避免任何可能导致非法、不道德或有害行为的内容。它应始终促进道德行为和负责任的沟通。
-
Debiasing(无偏性):模型应产生无偏见的响应,包括但不限于性别、种族、国籍和政治方面的偏见。它应平等公正地对待所有主题,遵循广泛接受的道德和伦理标准。
Reward Model:Prompt 来自两个不同数据集:开源数据和高复杂度的专有数据集,Response 是Qwen 模型的 checkpoint 生成的。在迭代实验中发现,当前的Reward Model 评估benchmark并不能准确预测通过其指导训练下的RL Model 的性能。换句话说,在 RM benchmark 上分数高并不一定表明经过其训练得到的 RL Model 的效果好。
几个需要注意的点:
-
Offline RL 中采用 DPO 来训练;Online RL 中采用 GRPO 来训练。
-
Reward Model 的 query set 与 RL 使用的一样
-
Online RL 中优先处理 Response 分数差较高的 query,以确保有效的学习。
-
每个 query 采样 8 个 Response。
长上下文
-
SFT阶段:采用两阶段训练,第一阶段仅仅使用短文本微调,每个指令最多包含32768个token;第二阶段结合短文本(最长32768)和长文本(最长262144)。这种方法有效增强模型在长上下文任务重的指令遵循能力,同时保持其在短任务上的表现。
-
RL阶段:仅专注于短指令。主要由于:1. RL训练对长上下文计算上非常昂贵;2.缺乏为长上下文任务提供合适 RM 信号的 RM model。3. 仅对短指令RL仍然能够显著增强在长上下文任务上的表现。
最后
大模型的发展实在太迅速了,刷paper都跟不上趟了,大家且行且珍惜啊。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

👉[优快云大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈

















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









