






一、阻塞IO与非阻塞IO
IO的本质是基于操作系统接口来控制底层的硬件之间数据传输,并且在操作系统中实现了多种不同的IO 方式(模型),比较常见的有下列三种
阻塞型IO模型
非阻塞型IO模型
多路复用IO模型
二、阻塞型IO
当进程发出IO请求后,阻塞进程(让进程进入睡眠状态),资源就绪后唤醒进程继续执行。
注意:一般默认的 IO 操作都是阻塞型 IO
三、非阻塞型IO
当进程发出IO请求后,无论资源是否就绪都会立即返回,相应的模型如下:
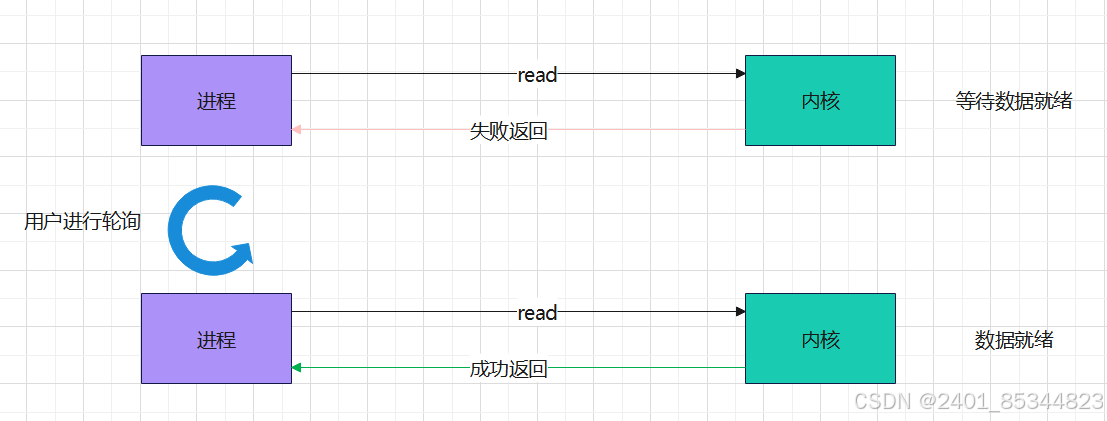
实现非阻塞型IO,需要设置 O_NONBLOCK 标志,设置有两种方式
- 可以通过调用 fcntl 函数来进行设置
- 通过open函数来进行设置,一般在打开文件时就需要设置
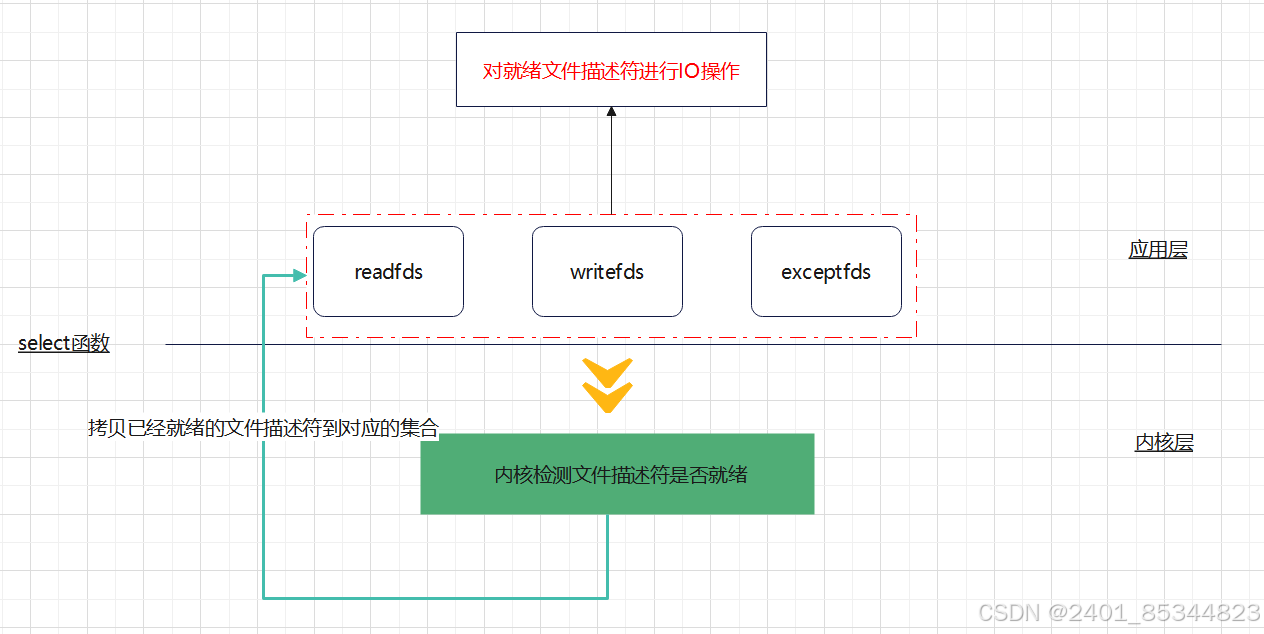
多路复用IO-select
设计思想
- 通过单进程创建一个文件描述符集合,将需要监控的文件描述符添加到这个集合中
- 由内核负责监控文件描述符是否可以进行读写,一旦可以读写,则通知相应的进程进行相应的I/O操作
实现方式
select多路复用I/O在实现时主要是以调用 select 函数来实现
多路复用IO-poll
多路复用poll的方式与select多路复用原理类似,但有很多地方不同,下面是具体的对比
- 在应用层是以结构体struct pollfd数组的形式来进行管理文件描述符,在内核中基于链表对数组进 行扩展;select方式以集合的形式管理文件描述符且最大支持1024个文件描述
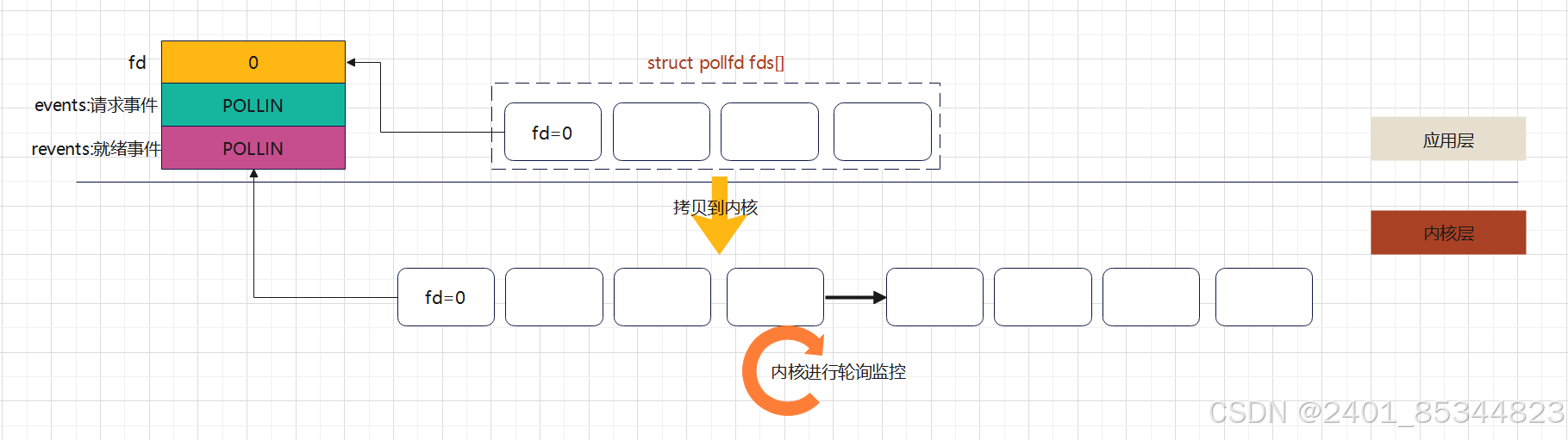
- poll将请求与就绪事件通过结构体进行分开
- select将请求与就绪文件描述符存储在同一个集合中,导致每次都需要进行重新赋值才能进行下一 次的监控
- 在内核中仍然使用的是轮询的方式,与 select 相同,当文件描述符越来越多时,则会影响效率
多路复用IO-epoll
poll相对于select与poll有较大的不同,主要是针对前面两种多路复用 IO 接口的不足
select/poll的不足:
- select 方案使用数组存储文件描述符,最大支持1024个
- select 每次调用都需要将文件描述符集合拷贝到内核中,非常消耗资源
- poll 方案解决文件描述符存储数量限制问题,但其他问题没有得到解决
- select / poll 底层使用轮询的方式检测文件描述符是否就绪,文件描述符越多,则效率越低
epoll优点:
- epoll底层使用红黑树,没有文件描述符数量的限制,并且可以动态增加与删除节点,不用重复拷贝
- epoll底层使用callback机制,没有采用遍历所有描述符的方式,效率较高
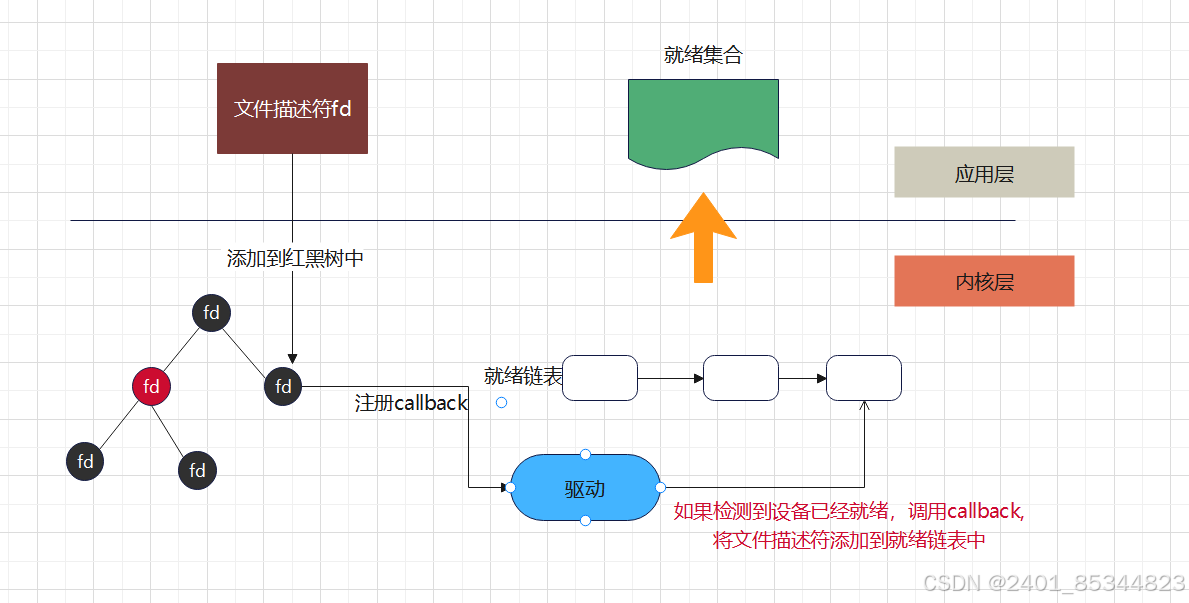
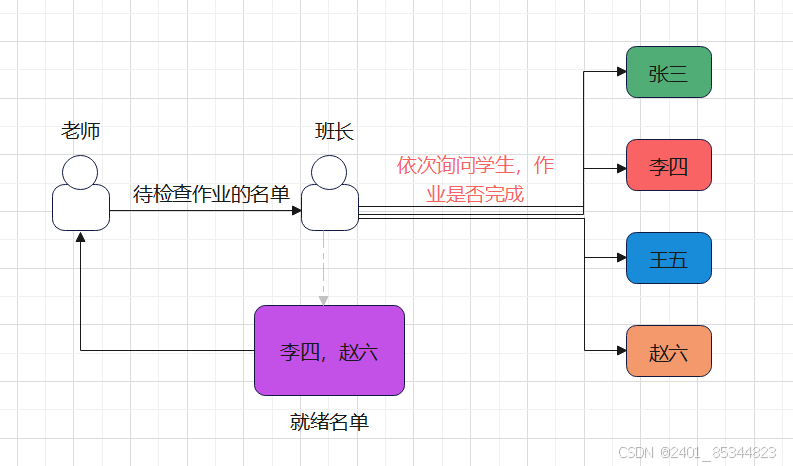
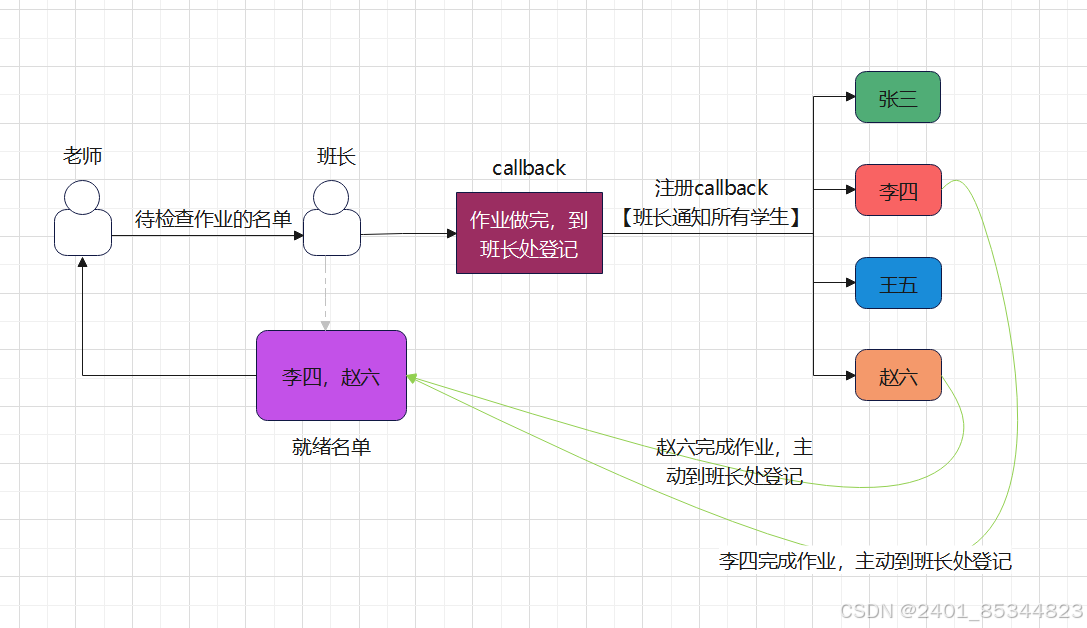
方案图解
select与poll方案
epoll方案


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









