






在日常使用大模型的时候,我们经常遇到一个问题,就是prompt提问、检索增强生成(RAG)提问和微调(Fine-Tuning)场景,当然大模型的本质都是输入-模型推理-输出,三个流程,那么这三个场景具体有什么差异性呢

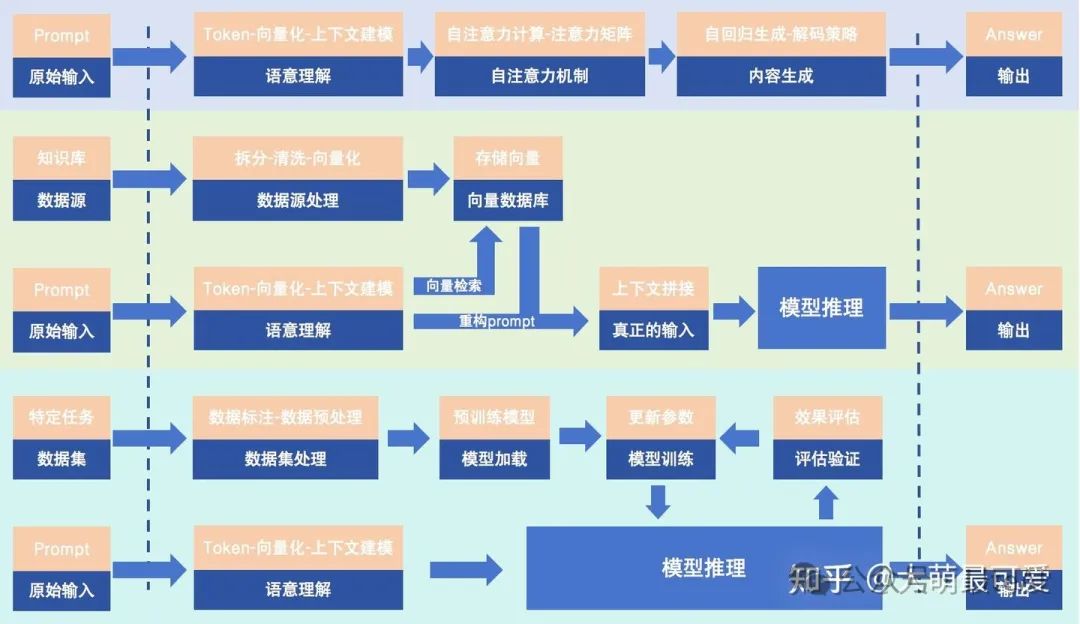
模型推理标准流程
今天我们重点来分析一下这个三种技术在模型内在表现的差异性
为了方便理解,我们可以把GPT在执行任务的时候做一个类比,一个经过了预训练的模型等同于一个理科的毕业生(当然也可能是大博士生,或者院士,我们不钻牛角尖,先用大学生类比),然后我们给大模型指派的任务是写一个贪吃蛇的游戏。

LLM-类比大模型
一、Prompt提示词场景
首选我们先分析讲解大模型的基础用法,prompt提示词(未使用RAG技术、未经过预训练):这个过程就相当于我们有个一任务,这个大学生具备相应的基础知识(比如C语言),然后这个大学生(大模型)就会基于自己的现有能力去编写这个贪吃蛇,最终他会给我们一个编写好的贪吃蛇游戏。

Prompt类比
那么提示词是什么呢(1)我们可以提示他的身份:如他是一个计算机专业的学生(2)这个事的背景:为了实现休息娱乐(3)详细的要求:比如使用电脑、使用手机、多少行代码(4)最终目标:参照上述要求描写
那么,这个具体的工作流程是什么,以前的文章有讲过,这里为了方便理解,再简单梳理一下
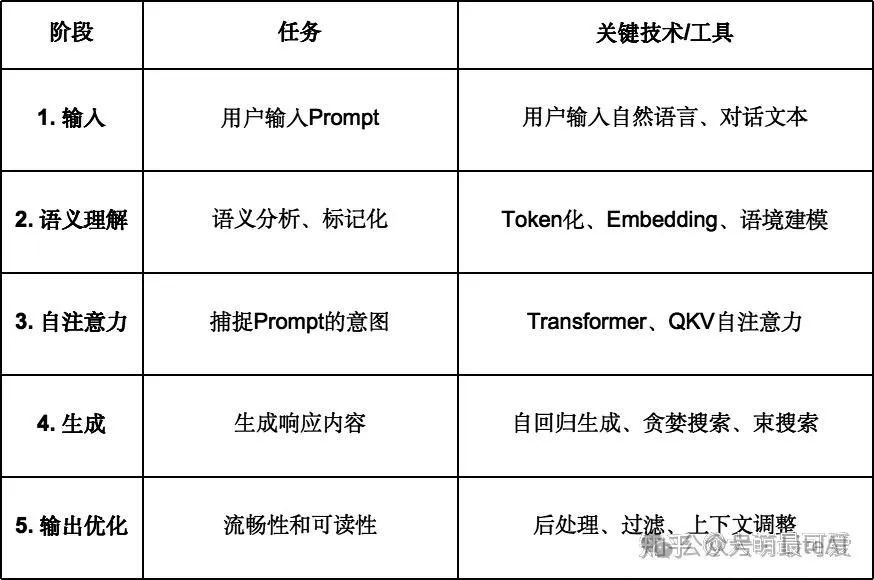
Prompt流程
1️⃣ 输入提示 (Prompt Input)
这是整个过程的第一步,用户通过自然语言的方式直接输入一段文本指令(例如问题、命令或任务描述),这段文本就是prompt。
1、用户输入示例:
“解释什么是大语言模型(LLM)。”
“为我写一首关于春天的诗。”
“将下面的句子翻译成法语:你好,今天过得怎么样?”
“用5句话总结这段文章的内容。”
目标:告诉模型你想要什么。
2、输入格式:可以是自然语言的单一指令,也可以是多轮对话中的输入。
典型提示设计:
任务指令型: “解释一下…”、“生成一段…”、“告诉我…”
角色指定型: “假设你是一名科学家,解释…”
多轮对话型: 通过对话的上下文中生成输出。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[优快云大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

2️⃣ 语义理解 (Semantic Understanding)
模型对输入的prompt进行语义分析和嵌入表示,将自然语言转换成可以被神经网络理解的向量表示。
1、语义理解过程:
Token化:将输入的prompt拆分成更小的子单元(token),这些token是自然语言的最小表示单位。
例如,“什么是大语言模型” 可能被拆分为:[“什么”, “是”, “大”, “语言”, “模型”]
嵌入表示:将token映射到高维向量空间,模型会通过嵌入矩阵将这些token转换为向量表示。
每个单词的表示类似于一个向量 (如 [0.23, -0.11, 0.56, …]),这些向量会传递给Transformer编码器。
上下文建模:如果是多轮对话,模型会结合对话的上下文信息(过去几轮的对话)进行处理,以确保生成的响应与对话的整体语境一致。
2、关键技术:
Tokenization(标记化)
Embedding(词向量)
Contextual Modeling(上下文建模)
示例:Prompt为“解释什么是大语言模型”。
· Token化:[“解释”, “什么”, “是”, “大”, “语言”, “模型”]
· 嵌入:每个词的向量化表示被传递给模型。
· 上下文建模:如果这是一场对话,模型会结合之前的对话内容。
3️⃣ 自注意力机制 (Self-Attention Mechanism)
Transformer架构的核心是自注意力机制,它可以让模型在全局范围内关注输入的所有单词,从而理解prompt的语义和意图。
1、自注意力流程:
自注意力计算:对于每一个输入的token(如“语言”),它会与所有其他token(如“解释”、“大”等)进行交互,计算每个单词与其余单词的“重要性权重”。
注意力矩阵:通过“查询-键-值”机制(Q-K-V机制)计算出注意力分数,权重越高的token,模型会赋予更高的关注权重。
多头注意力:模型通过多个“头”来捕捉不同类型的语义关系,例如句子的语法关系、任务意图等。
2、关键技术:
Q-K-V Attention(查询-键-值机制)
Multi-Head Attention(多头注意力)
Positional Encoding(位置编码,表示单词的位置信息)
示例:
对于prompt“解释什么是大语言模型”,
· 模型会将“解释”作为核心关注词,与“什么”、“是”、“语言模型”建立强连接,确保生成的答案是与“解释”有关的。
· 自注意力机制的作用是捕捉prompt的意图和句子中的关键部分。
4️⃣ 生成阶段 (Generation Phase)
基于自回归生成的过程,意味着模型在生成每一个输出单词时,依赖之前的生成输出。
1、生成过程
自回归生成:对于第一个token(如"大"),它只依赖于输入的prompt;但对于第二个token(如"语言"),它依赖于“prompt+第一个token”。
逐步生成:模型一个一个地生成新token,直到满足结束条件(如生成结束符[EOS])或达到最大输出长度。
解码策略:在生成token时,模型会根据概率从可能的token中选择最有可能的那个。
贪婪解码:总是选择概率最高的token(可能会丢失多样性)
束搜索(Beam Search):考虑多个最优路径,生成更多样化的响应
随机采样:从概率分布中随机抽取下一个单词,避免固定化生成的输出
2、关键技术
Greedy Search(贪婪搜索)
Beam Search(束搜索)
Temperature(温度控制,调整采样的多样性)
示例:
Prompt为“解释什么是大语言模型”
1. 模型生成“一个大语言模型是…”
2. 模型生成“一个大语言模型是一种AI架构…”
3. 模型生成“一个大语言模型是一种通过大规模数据训练的语言模型…”
5️⃣输出优化 (Output Optimization)
输出的最后阶段,模型可能会使用后处理技术来确保输出的流畅性、可读性和语法正确性。
1、优化过程
去除无效标记:例如去掉特殊符号(如[UNK]、[PAD]等特殊符号)。
多轮对话的响应调整:如果是多轮对话,可能会对生成的响应进行情境调整,以确保响应的连贯性。
后处理和过滤:某些实现中会对生成的内容进行敏感词过滤,尤其是在对话机器人中。
2、关键技术
- Post-processing(后处理过滤)
Dialog Context Adjustment(对话上下文调整)
二、RAG场景
RAG是(Retrieval-Augmented Generation)检索增强生成的缩写,RAG是一种增强生成的机制,通过检索外部信息来补充生成内容,进而提高模型的准确性和相关性。它将检索模块与生成模块结合,首先检索相关信息,再根据检索到的内容生成响应。
我们还拿刚刚的大学生编写贪吃蛇游戏来举例子,这个时候呢,还是刚刚的那个大学生,还是编写贪吃蛇游戏,还是一样的提示词;但是当使用了RAG的模型,这个时候发生了哪些变化呢?
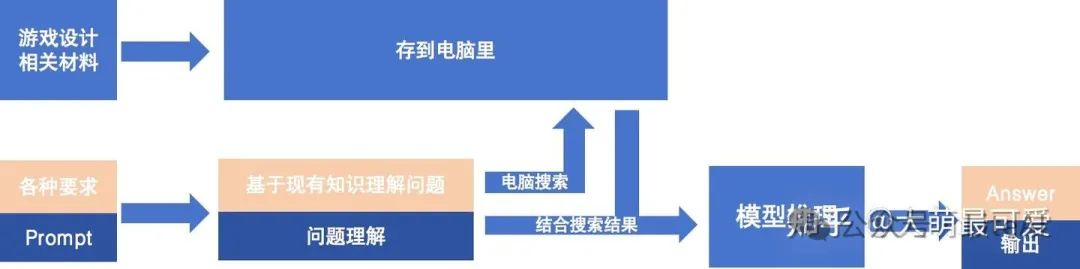
RAG类比流程
就是这个大学生现在手里有好多公司类似的游戏设计说明、游戏编写规范、贪吃狗、贪吃猫类似的游戏代码;在接到任务前,大学生把这些东西都存在了他的电脑里形成了一个游戏编写外挂知识库(不一定是答案,但是可以作为参考,可以更新),当他需要编写代码的时候,他结合要设计的贪吃蛇游戏,搜索他电脑里的游戏编写外挂支持库,最终来编写我们这个游戏。
所以这个过程有两个重要的事:首选,他的有这个和任务相关的外挂知识库,然后,在工作的时候,他会使用这个外挂的知识库来工作。但是,值得注意是,这个所有的过程,这个大学生的自身游戏业的能力并未发生本质的变化,也就是说他其实没有真正掌握编写游戏代码这个流程,他只是在“照葫芦画瓢”。整体流程如下:
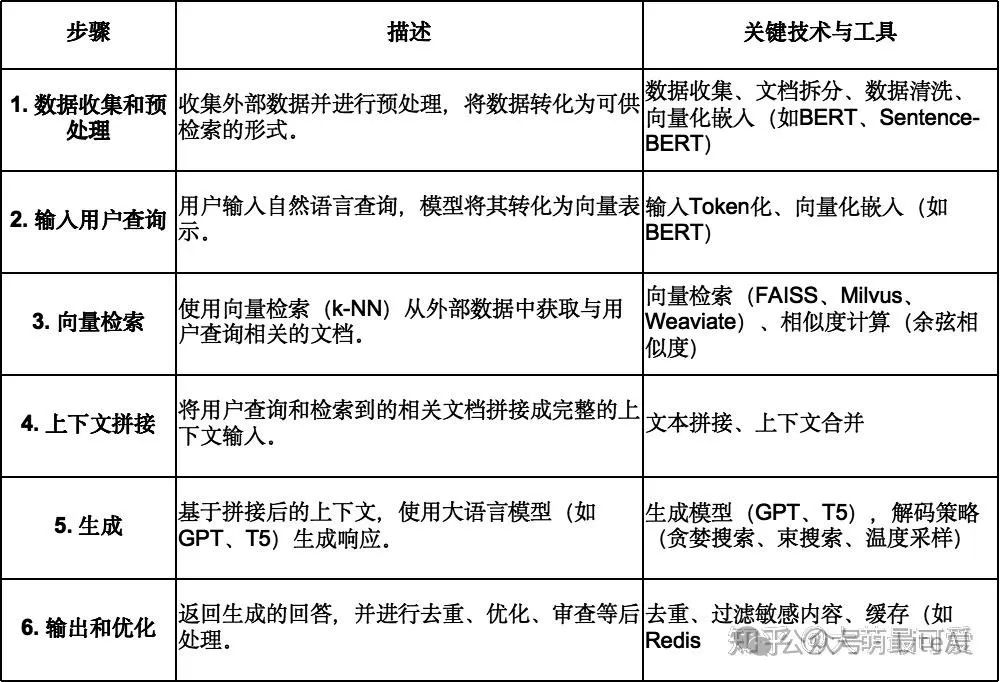
RAG流程
1️⃣ 数据的收集和预处理
在RAG中,外部数据(如文档、网页、API返回的实时信息)通常存储在一个可供检索的文档库或知识库中。
1、数据来源
企业内部的文档库(如产品手册、内部文档、法律条款、FAQ等)
互联网数据(如API数据、网页爬取的数据、行业报告等)
数据库(如MySQL、Elasticsearch、MongoDB等)
2、数据预处理
拆分文档:将长文档拆分成段落、句子或块(chunk),每一段块作为检索的最小单位。
数据清洗:去除无效信息,如HTML标签、乱码字符、表情符号等。
向量化嵌入:通过嵌入模型(如BERT Embedding、Sentence-BERT、OpenAI Embeddings等)将每个文本块转化为高维向量,便于后续的向量搜索。
3、工具
向量库:FAISS、Milvus、Weaviate、Pinecone
嵌入生成器:OpenAI Embedding、Sentence-BERT、DPR
示例: 如果我们有一个法律文档,内容长达20页,则可以将其拆分为每页的段落。
每一段文本(chunk)通过BERT向量化,其向量表示会被存储在Milvus数据库中,后续在回答法律问题时可以动态关联检索到这些段落。
2️⃣ 输入用户查询(Query Input)
用户向RAG系统输入一个自然语言的查询,这段输入通常是一个简单的问题、请求或命令。
1、输入示例:
“我如何退还不满意的商品?”
“请解释合同中的‘不可抗力’是什么意思?”
“2024年最新的财务报告中的营收是多少?”
2、输入的处理
Token化:将输入的问题拆分成token。
向量化表示:使用与文档预处理中相同的嵌入模型,将用户的查询向量化,形成一个与知识库中的文档向量同空间的嵌入向量。
示例: 用户输入:“什么是不可抗力?”
· 嵌入模型(如BERT)将其转化为一个嵌入向量 v = [0.15, -0.28, 0.39, …]
· 该向量将与外部文档的向量进行相似度比较,找出最匹配的内容。
3️⃣ 向量检索(Vector Search)
在这一步,用户输入的查询向量会与外部数据的向量在向量空间中进行相似度检索,从而动态获取相关的外部信息。
1、技术原理
使用最近邻搜索(k-NN)在存储的向量数据库中搜索与查询向量最接近的Top-K个文档。
相似度计算:通常采用**余弦相似度(cosine similarity)**来衡量查询向量和文档向量的距离。
2、工具链
向量库:FAISS、Milvus、Weaviate、Pinecone、Elasticsearch
检索算法:k-NN(K-Nearest Neighbor)、HNSW(Hierarchical Navigable Small World)
示例: 用户输入的查询“什么是不可抗力?”,在Milvus数据库中搜索,找到前3个最相关的段落:
· 段落1:不可抗力是指当事人无法预见的自然灾害……
· 段落2:合同中关于不可抗力的定义为……
· 段落3:根据《合同法》,不可抗力的后果…
4️⃣ 上下文拼接(Context Concatenation)
将用户的原始查询和从外部数据中检索到的文档拼接为一个完整的上下文,供语言模型(如GPT、T5)生成输出。
1、拼接方法
将用户的查询和外部的文档按对话的格式拼接,并构造成一段输入上下文。
拼接示例:
用户问题:什么是不可抗力?
相关文档1:不可抗力是指当事人无法预见的自然灾害……
相关文档2:根据《合同法》,不可抗力的后果……
2、拼接策略
限制最大输入长度:确保拼接后的上下文不超过LLM的最大token数(如4096或8192)。
优先使用最相关的文档:如果超过最大输入长度,可以只拼接Top-K的文档。
5️⃣ 生成(Language Model Generation)
这一步是由大语言模型(如GPT、T5)根据用户的查询和上下文信息生成回答。
· 输入:包含了用户的查询+外部数据文档的拼接上下文。
1、生成机制
自回归生成:模型使用自回归生成机制,基于输入的内容依次生成每个单词。
解码策略:可以选择贪婪搜索、束搜索或温度采样。
示例: 输入拼接:
· 用户问题:什么是不可抗力?
· 相关文档1:不可抗力是指……
生成的输出:
“不可抗力是指由于不可预测的自然事件或其他不可控的情况,使合同的一方或双方无法履行其义务的情形。根据《合同法》,此类情况可包括地震、洪水、战争等。”
6️⃣ 输出和优化(Post-processing & Response Delivery)
最后,系统将生成的响应返回给用户,在某些场景下,可能需要进一步的优化和过滤。
· 去重和优化:去除不必要的重复信息,确保响应的连贯性。
· 内容审查:如果涉及敏感内容或非法信息,需要对输出进行敏感词过滤。
· 部署:
部署在**API微服务(Flask/FastAPI)**中,供前端调用。
使用缓存(如Redis)保存先前的查询结果,减少检索和生成的响应时间。
三、Fine-Tuning场景
Fine-Tuning是指在预训练大模型的基础上,针对特定任务或领域进行再训练,调整模型的参数,使其在特定任务上表现更好。
我们还拿刚刚的大学生编写贪吃蛇游戏来举例子,这个时候呢,还是刚刚的那个大学生,还是编写贪吃蛇游戏,还是一样的提示词;但是当使用了Fine-Tuning的模型,这个时候发生了哪些变化呢?

Fine-Tuning类比
在接到这个任务以前,有专业的游戏公司开发人员对于这个大学生开展了系统性的培训,把编写游戏程序这个事变成了大学自己的能力,然后这个时候大学生肯定是专业的,他依赖的知识和能力针对游戏设计这个领域进行了专项的培训(并不需要依赖外挂知识库),所以完成这个情况下,完成这个游戏任务的质量是最高的,这个时候,这个大学生已经确实掌握了依据要求编写游戏代码的这个能力。
Fine-Tuning的过程可分为以下6个阶段,每个阶段的目标和关键技术如下:
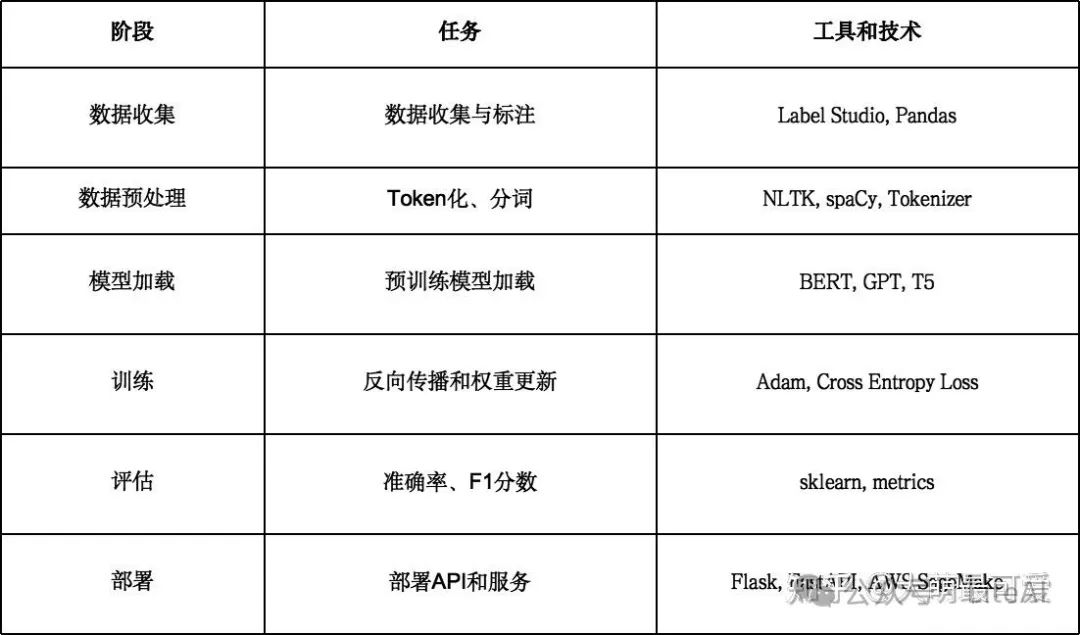
Fine-Tuning流程
1️⃣ 数据收集和数据标注(Data Collection & Annotation)
这是Fine-Tuning的前置准备阶段,主要任务是为Fine-Tuning模型收集和标注高质量的数据集。
· 数据收集:
领域数据:用于特定任务的数据集(例如,客户服务的对话数据、特定领域的问答对话等)。
开源数据集:例如SQuAD、GLUE、CoQA、XSum等任务数据集。
内部数据:对于企业内部的私有数据(如公司知识库、内部文档、FAQ等)。
· 数据标注:
分类任务:将数据标注为特定类别(如情感分析的“正面、负面、中性”标签)。
生成任务:为每个输入的文本(如对话)标注对应的“目标输出”(例如,问题与回答的成对数据)。
特定任务标注:例如,命名实体识别(NER)任务标注“人名、地名、公司名”等。
· 常用工具:
标注平台:Label Studio、Prodigy
数据集平台:Huggingface Datasets、Kaggle Datasets
示例:
· 如果要为“客户服务对话系统”Fine-Tuning一个模型,我们需要收集对话的历史数据,并将每个客户的问题和客服的回答进行“成对标注”,例如:
客户输入:“如何重置密码?”
客服回复:"您可以点击登录页面的“忘记密码”按钮来重置密码。
2️⃣ 数据预处理(Data Preprocessing)
在收集到原始数据后,需要对数据进行清洗、分割和格式化,使其适配Fine-Tuning模型的输入格式。
关键任务:
去噪:去除无用的信息,如HTML标签、特殊符号、Emoji表情符等。
分词(Tokenization):将每一段文本划分为token(如“今天/天气/很好”),这通常通过分词器(Tokenizer)来完成。
o 输入格式化:格式化成特定的输入-输出对,例如在“问题-回答”任务中,格式化为:
{
“prompt”: “如何重置密码?”,
“completion”: “您可以点击登录页面的“忘记密码”按钮来重置密码。”
}
常用工具:
· 分词工具:HuggingFace Tokenizer、BERT Tokenizer
· 处理工具:Python的Pandas、NLTK、spaCy、NumPy等
{ “prompt”: “我想取消订单”, “completion”: “您可以登录您的账户,在“我的订单”中选择要取消的订单。” }
3️⃣ 模型加载(Model Loading)
这一步是Fine-Tuning的模型初始化阶段,加载一个预训练的基础模型(如GPT、BERT、T5)并调整其架构以适配任务的输出需求。
· 加载模型:
加载来自HuggingFace、OpenAI等平台的预训练的LLM。
选择模型的架构(如GPT、BERT、T5等)。
· 模型架构的调整:
分类任务:在最后一层(输出层)添加一个Softmax层,以便输出多类别分类结果。
生成任务:如果是生成任务,模型架构保持不变,但可能需要调整最大生成长度和解码策略。
序列标注任务:在模型的每个token上添加一个标签层,使其可以对每个token进行标注。
示例:
· 任务:用BERT进行文本分类。
· 架构调整:BERT的最后一层的输出是一个分类器,输出3个类别:正面、负面、中性。
from transformers import BertForSequenceClassification
# 加载预训练模型(BERT)
model=BertForSequenceClassification.from_pretrained(“bert-base-uncased”, num_labels=3)
4️⃣ 训练(Training)
Fine-Tuning的核心是将预训练模型在新数据上继续训练,并更新模型的参数,这一步骤通常需要大量的算力和内存。
训练步骤:
-
前向传播:将输入传递到模型,生成预测的输出。
-
损失计算:计算模型的损失函数(Loss),如交叉熵损失(Cross-Entropy Loss)。
-
反向传播:反向传播误差(误差反向传播算法,BP算法),并计算梯度。
-
权重更新:根据**学习率(Learning Rate)**使用优化器(如Adam)更新模型参数。
常用技术:
1. 损失函数:交叉熵(Cross Entropy)、均方误差(MSE)
2. 优化器:Adam、SGD、AdamW
3. 正则化:防止过拟合,如L2正则化和Dropout
示例:
用HuggingFace Trainer在GPT模型上执行Fine-Tuning。
5️⃣ 评估和验证(Evaluation & Validation)
在训练过程中,必须对Fine-Tuning的效果进行评估,以确保模型的准确性、鲁棒性和泛化能力。
· 常见指标:
分类任务:准确率(Accuracy)、F1分数(F1 Score)、精确率(Precision)、召回率(Recall)
生成任务:BLEU分数、ROUGE分数、Perplexity(困惑度)
示例:在评估情感分类模型时,使用F1分数评估模型在验证集上的表现。
6️⃣ 部署和推理(Deployment & Inference)
最后一步是将Fine-Tuned的模型部署为API或微服务,以供前端、客户和企业系统使用。
· 部署方式:
Huggingface Hub:将模型上传到Huggingface平台,API接口即可用。
Web部署:使用Flask、FastAPI提供HTTP接口,供前端调用。
云部署:通过AWS Sagemaker或Google Cloud AI平台部署。
四、总结(省时间)
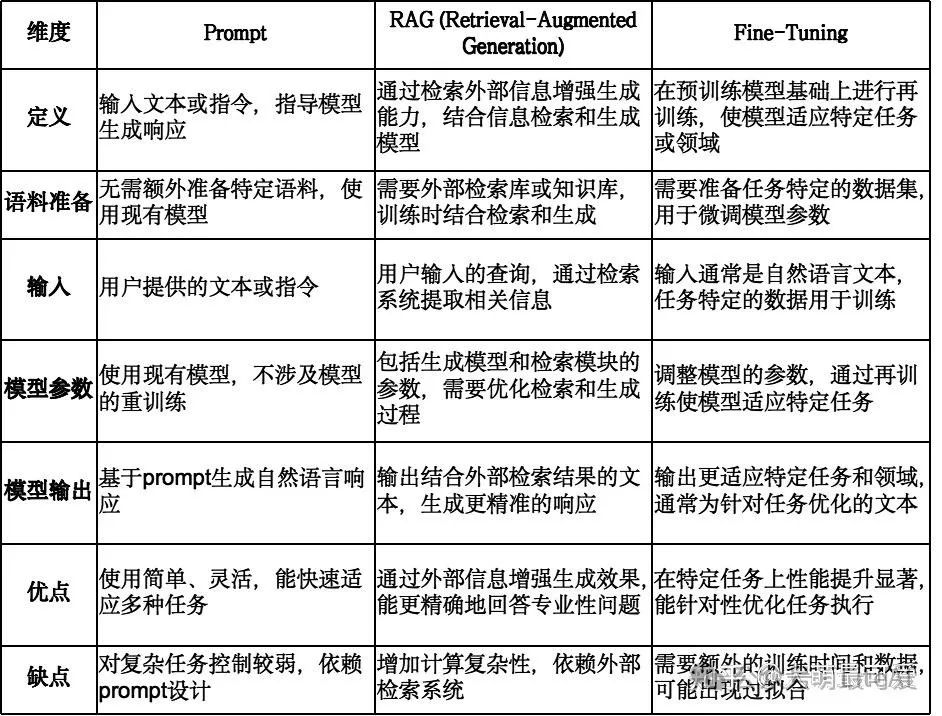
不同维度对比
Prompt RAG Fine-Tuning差异对比
1、Prompt 完成预训练后直接使用,未经过专业的微调,或未有外置数据能力,回答质量高度依赖Prompt水平,模型参数没有变化。
2、RAG完成预训后协同外挂向量数据库使用,回答质量高度依赖Prompt的同时,也依赖外挂数据库质量,实时性较好,模型参数没有变化。
3、模型完成预训练后,经过垂直领域的Fine-Tuning,未有外置数据能力,实时性一般,但是专业能力较好,回答质量高度依赖Prompt的同时,也依赖Fine-Tuning的水平,模型参数发生了变化。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 3903
3903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}