






前言
要想RAG好,embedding和reranker必须给力!目前市面上流行的embedding和reranker使用的都是通用预料训练,并未针对安全这个细分领域定制,所以有必要使用安全领域的预料微调一下!目前所有的预料中,获取成本比较低、并且不需要专门投入人力标注的有两种:
- 网上各种安全论坛的博客、各大热门产品的漏洞说明等
- 用户的点赞反馈数据(chatGPT、copilot等都有该功能)
对于本人而言,用户的点赞反馈数据更容易获取,所以这里使用这类数据,借鉴RLHF-DPO的思路对embedding和reranker模型做微调!训练样本的数据格式如下:
{
"query": "如何使用IDA Pro反汇编一个二进制文件?",
"positive": \[
"使用IDA Pro反汇编一个二进制文件的方法如下:\\n1. 打开IDA Pro并选择“新建”。\\n2. 选择适当的文件格式加载你的二进制文件。\\n3. IDA Pro会自动分析二进制文件并提供反汇编视图。\\n4. 你可以浏览反汇编的代码,以了解二进制文件的功能。\\n5. 使用IDA Pro的交互功能重命名函数、添加注释,以便更容易分析。"
\],
"negative": \[
"使用IDA Pro进行文件反汇编的方法:\\n1. 打开IDA Pro并选择“新建项目”。\\n2. 加载任何类型的文件,IDA Pro会自动将其转换为源代码。\\n3. 你可以直接运行反汇编代码,并通过调试器查看执行结果。\\n4. 如果文件有加密,可以在IDA Pro中直接解密。\\n5. 最后,生成一个全新的二进制文件。",
"使用IDA Pro进行简单的文件修改:\\n1. 打开IDA Pro并载入文件。\\n2. 选择修改的部分并进行编辑。\\n3. 保存修改后的文件。\\n4. 测试修改后的文件是否工作正常。\\n5. 完成所有修改后,生成新的文件。"
\]
}
query是真实的用户咨询,LLM会提供两个答案,用户点赞选择的答案标记为positive,没有被选中的标记为negative!
1、先看embedding。 训练样本的格式是[query、pos、neg],微调的终极目的是让LLM的回答和query匹配,基于这个思路,设计出了Contrastive Learning,也叫Triplet Loss:先把三段文本求embedding,然后让query+pos的相似度最大,query+neg的相似度最小,loss的设计如下:
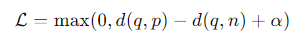
q、p、n分别是三段text的embedding,d 是距离度量(例如欧氏距离或余弦相似度),α 是一个超参数,称为边际(margin)。这个loss函数意义直观,容易理解!具体怎么落地实现了?既然要计算相似度,那就干脆先把query和pos、neg的相似度事先全部先算好,放在矩阵里,便于后续取用。矩阵的每列都是用户每次反馈的数据。矩阵的第一列是query和pos的相似度,其他列是query和neg的相似度,如下:
sim\_matrix = \[\[sim(q1, p1), sim(q1, n11), sim(q, n12), ...\]
\[sim(q2, p2), sim(q2, n21), sim(q, n22), ...\]\]
因为第一列是query和pos的相似度,那么第一列的数值应该尽量大,其他列的数值应该尽量小,这不正好可以使用crossEntropy么?labels向量 = [1,0,0,0…],经过crossEntropy相乘后,loss只剩query—pos的相似度啦!具体落地实现的方式稍微有些变通:
(1)以M3E微调为例,微调实现的代码在这里:https://github.com/wangyuxinwhy/uniem/blob/main/uniem/criteria.py#L62,核心的loss方法如下:
class TripletInBatchNegSoftmaxContrastLoss(ContrastLoss):
def \_\_init\_\_(self, temperature: float = 0.05, add\_swap\_loss: bool = False):
super().\_\_init\_\_(temperature)
self.add\_swap\_loss \= add\_swap\_loss
if self.add\_swap\_loss:
self.\_pair\_contrast\_softmax\_loss \= PairInBatchNegSoftmaxContrastLoss(temperature)
else:
self.\_pair\_contrast\_softmax\_loss \= None
def forward(
self,
text\_embeddings: torch.Tensor,
text\_pos\_embeddings: torch.Tensor,
text\_neg\_embeddings: torch.Tensor,
) \-> torch.Tensor:
# 计算正样本相似度向量
sim\_pos\_vector = torch.cosine\_similarity(text\_embeddings, text\_pos\_embeddings, dim=-1)
# 计算负样本相似度矩阵
sim\_neg\_matrix = torch.cosine\_similarity(
text\_embeddings.unsqueeze(1),
text\_neg\_embeddings.unsqueeze(0),
dim\=-1,
)
# 将正样本相似度和负样本相似度拼接成一个矩阵
sim\_matrix = torch.cat(\[sim\_pos\_vector.unsqueeze(1), sim\_neg\_matrix\], dim=1)
# 温度缩放
sim\_matrix = sim\_matrix / self.temperature
# 生成标签,目的是让loss选择第一列的数值
labels = torch.zeros(sim\_matrix.size(0), dtype=torch.long, device=sim\_matrix.device)
# 计算交叉熵损失
loss = torch.nn.CrossEntropyLoss()(sim\_matrix, labels)
# 如果有附加交换损失,则加上
if self.\_pair\_contrast\_softmax\_loss:
loss += self.\_pair\_contrast\_softmax\_loss(text\_pos\_embeddings, text\_embeddings)
return loss
uniem封装后,使用也很简单,几行代码就搞定了:
from datasets import load\_dataset
from uniem.finetuner import FineTuner
dataset \= load\_dataset('/data/security\_zh', 'STS-B')
# 指定训练的模型为 m3e-small
finetuner = FineTuner.from\_pretrained('moka-ai/m3e-large', dataset=dataset)
finetuner.run(epochs\=1)
 M3E微调后的效果好不好,测评的方式有多种:
M3E微调后的效果好不好,测评的方式有多种:
- 模型本身的指标:https://github.com/wangyuxinwhy/uniem/tree/main/mteb-zh 用文本分类、聚类、retrieve、rerank等方式
- RAG的指标:https://www.cnblogs.com/theseventhson/p/18261594 context recall、context Precision
- 用户实际使用评价,核心还是triplet的点赞数据是不是够多
(2)同理,beg的baai_general_embedding微调的方法详见:https://github.com/FlagOpen/FlagEmbedding/blob/master/examples/finetune/README.md ;数据集格式如下,都是一样的:
{"query": str, "pos": List\[str\], "neg":List\[str\]}
重写getitem函数,
def \_\_getitem\_\_(self, item) -> Tuple\[str, List\[str\]\]:
query \= self.dataset\[item\]\['query'\]
if self.args.query\_instruction\_for\_retrieval is not None:
query \= self.args.query\_instruction\_for\_retrieval + query
passages \= \[\]
assert isinstance(self.dataset\[item\]\['pos'\], list)
pos \= random.choice(self.dataset\[item\]\['pos'\])
passages.append(pos)
if len(self.dataset\[item\]\['neg'\]) < self.args.train\_group\_size - 1:
num \= math.ceil((self.args.train\_group\_size - 1) / len(self.dataset\[item\]\['neg'\]))
negs \= random.sample(self.dataset\[item\]\['neg'\] \* num, self.args.train\_group\_size - 1)
else:
negs \= random.sample(self.dataset\[item\]\['neg'\], self.args.train\_group\_size - 1)
passages.extend(negs)
if self.args.passage\_instruction\_for\_retrieval is not None:
passages \= \[self.args.passage\_instruction\_for\_retrieval+p for p in passages\]
return query, passages
把原本的数据换个格式:
(
"query:如何使用IDA Pro反汇编一个二进制文件?",
\[
"passage:使用IDA Pro反汇编一个二进制文件的方法如下:\\n1. 打开IDA Pro并选择“新建”。\\n2. 选择适当的文件格式加载你的二进制文件。\\n3. IDA Pro会自动分析二进制文件并提供反汇编视图。\\n4. 你可以浏览反汇编的代码,以了解二进制文件的功能。\\n5. 使用IDA Pro的交互功能重命名函数、添加注释,以便更容易分析。",
"passage:使用IDA Pro进行文件反汇编的方法:\\n1. 打开IDA Pro并选择“新建项目”。\\n2. 加载任何类型的文件,IDA Pro会自动将其转换为源代码。\\n3. 你可以直接运行反汇编代码,并通过调试器查看执行结果。\\n4. 如果文件有加密,可以在IDA Pro中直接解密。\\n5. 最后,生成一个全新的二进制文件。",
"passage:IDA Pro是一款功能强大的反汇编工具,用户可以通过它轻松分析二进制文件。"
\]
)
微调核心过程:
def encode(self, features):
if features is None:
return None
psg\_out \= self.model(\*\*features, return\_dict=True)
p\_reps \= self.sentence\_embedding(psg\_out.last\_hidden\_state, features\['attention\_mask'\])
if self.normlized:
p\_reps \= torch.nn.functional.normalize(p\_reps, dim=-1)
return p\_reps.contiguous()
def compute\_similarity(self, q\_reps, p\_reps):
if len(p\_reps.size()) == 2:
return torch.matmul(q\_reps, p\_reps.transpose(0, 1))
return torch.matmul(q\_reps, p\_reps.transpose(-2, -1))#矩阵相乘,本质还是内积
def forward(self, query: Dict\[str, Tensor\] = None, passage: Dict\[str, Tensor\] = None, teacher\_score: Tensor = None):
q\_reps \= self.encode(query)
p\_reps \= self.encode(passage)
if self.training:
if self.negatives\_cross\_device and self.use\_inbatch\_neg:
q\_reps \= self.\_dist\_gather\_tensor(q\_reps)
p\_reps \= self.\_dist\_gather\_tensor(p\_reps)
group\_size \= p\_reps.size(0) // q\_reps.size(0)
if self.use\_inbatch\_neg:
scores \= self.compute\_similarity(q\_reps, p\_reps) / self.temperature # B B\*G
scores = scores.view(q\_reps.size(0), -1)
target \= torch.arange(scores.size(0), device=scores.device, dtype=torch.long)
target \= target \* group\_size
loss \= self.compute\_loss(scores, target)
else:
scores \= self.compute\_similarity(q\_reps\[:, None, :,\], p\_reps.view(q\_reps.size(0), group\_size, -1)).squeeze(1) / self.temperature # B G
scores \= scores.view(q\_reps.size(0), -1)
target \= torch.zeros(scores.size(0), device=scores.device, dtype=torch.long)
loss \= self.compute\_loss(scores, target)
else:
scores \= self.compute\_similarity(q\_reps, p\_reps)
loss \= None
return EncoderOutput(
loss\=loss,
scores\=scores,
q\_reps\=q\_reps,
p\_reps\=p\_reps,
)
def compute\_loss(self, scores, target):
return self.cross\_entropy(scores, target)
def \_dist\_gather\_tensor(self, t: Optional\[torch.Tensor\]):
if t is None:
return None
t \= t.contiguous()
all\_tensors \= \[torch.empty\_like(t) for \_ in range(self.world\_size)\]
dist.all\_gather(all\_tensors, t)
all\_tensors\[self.process\_rank\] \= t
all\_tensors \= torch.cat(all\_tensors, dim=0)
return all\_tensors
模型用的还是双塔结构 BiEncoderModel,**先用矩阵相乘的形式得到query和passage中每条text的相似度,然后构造target向量,通过crossEntropy选择passage中的pos回答,这个落地实现的核心思路和M3E完全一样啊!**微调的接口已经封装好了,直接调用:
torchrun \\
\> -m FlagEmbedding.baai\_general\_embedding.finetune.run \\
\> --output\_dir /root/huggingface/bge\_finetune \\
\> --model\_name\_or\_path /root/huggingface/bge-large-zh-v1.5 \\
\> --train\_data /root/huggingface/data/user\_feedback \\
\> --learning\_rate 1e-5 \\
\> --num\_train\_epochs 5 \\
\> --dataloader\_drop\_last True \\
\> --normlized True \\
\> --temperature 0.02 \\
\> --query\_max\_len 64 \\
\> --passage\_max\_len 256 \\
\> --train\_group\_size 2 \\
\> --negatives\_cross\_device \\
\> --logging\_steps 10 \\
\> --save\_steps 1000
运行完毕:

微调数据量有限的情况下,epoch越多,loss越小!


epoche=30,loss降至0.999

epoche=60,loss降至0.499;

微调完后测评的脚本也是现成的:https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/finetune/eval_msmarco.py 核心思路是对query做encode,然后查找100个最接近的answer,然后计算Recall和MRR;可以直接执行命令:
python -m FlagEmbedding.baai\_general\_embedding.finetune.eval\_msmarco \\
\--encoder /root/huggingface/bge-large-zh-v1.5 \\
\--fp16 \\
\--add\_instruction \\
\--k 100 \\
\--corpus\_data /root/huggingface/data/sec\_corpus.json \\
\--query\_data /root/huggingface/data/sec\_query.json
corpus_data包含了想要检索的内容:
{"content": "为什么要对数据加读锁了而不是互斥锁了?在互斥机制中,读者和写者都需要独立独占互斥量以独占共享资源;而在读写锁机制下,允许同时有多个读者读访问共享资源,只有写者才需要独占资源。相比互斥机制,读写机制由于允许多个读者同时读访问共享资源,进一步提高了多线程的并发度"}
{"content": "从R4+C的地方取4字节数据存入R0,然后把R0存到栈上;接着把R0+4,这里ida已经识别出了是rwlock读写锁,然后就是调用pthread\_rwlock\_rdlock获取读写锁的读锁!这就很关键了"}
{"content": "从ida的trace记录看,前面所有的指令都没有读取栈上保存的url+http头的数据,所以前面肯定还没来得及生成那4个加密字段;**从这里开始用读写锁,结合上面的分析大胆猜测:接下来要开始生成加密字段了**!"}
{"content": "第三个参数我是用frida hook得到的,换了个环境地址肯定也变了,所以这里直接”抄袭“拿过来用肯定报错,这种反调试的方法实在是秒啊!动态调试暂时卡壳"}
{"content": " 之前通过hook registerNative发现:metasec\_ml中的0x1094c被ms.bd.c.h.a方法注册成了native函数,这是metasec\_ml唯一的native函数,肯定很重要,就从这里下手呗!这个函数有5个参数,分别都是啥了?"}
query_data包含了问题和正确答案,如下:
{"query": "frida是什么?", "positive": \["Frida是一款基于python + javascript 的hook框架,适用于android/ios/linux/win/osx等平台。Frida的动态代码执行功能,主要是在它的核心引擎Gum中用C语言来实现的", "只要兼容V8引擎就能正常使用frida"\]}
{"query": "怎么使用IDA?", "positive": \["1、安装IDA 2、用IDA打开二进制文件,可以使用F5将汇编反编译成C语言伪代码 3、可以直接调试伪代码了解二进制代码逻辑"\]}
{"query": "怎么脱壳?", "positive": \["对于一代、二代壳,可以直接使用frida dexdump从内存把正常的dex代码dump到磁盘"\]}
从测评的原理来看,和https://www.cnblogs.com/theseventhson/p/18261594 这里面对整个RAG评测是一样的,所以直接采取RAG的评测方法!
2、reranker微调,这里以beg的reranker为例:https://github.com/FlagOpen/FlagEmbedding/blob/master/examples/reranker/README.md ;训练样本的格式和embedding是一样的,但是也要先对训练样本的格式做转换:
def \_\_getitem\_\_(self, item) -> List\[BatchEncoding\]:
# 获取当前数据项的 query 和正样本
query = self.dataset\[item\]\['query'\]
pos \= random.choice(self.dataset\[item\]\['pos'\])
# 如果负样本数量不足,则重复采样
if len(self.dataset\[item\]\['neg'\]) < self.args.train\_group\_size - 1:
num \= math.ceil((self.args.train\_group\_size - 1) / len(self.dataset\[item\]\['neg'\]))
negs \= random.sample(self.dataset\[item\]\['neg'\] \* num, self.args.train\_group\_size - 1)
else:
# 随机选择 train\_group\_size - 1 个负样本
negs = random.sample(self.dataset\[item\]\['neg'\], self.args.train\_group\_size - 1)
# 初始化批次数据列表
batch\_data = \[\]
# 添加正样本
batch\_data.append(self.create\_one\_example(query, pos))
# 添加负样本
for neg in negs:
batch\_data.append(self.create\_one\_example(query, neg))
return batch\_data # 返回正负样本组合的批次数据
batch_data前面是pos样本,后面接着neg样本,每个batch_data的格式如下:
batch\_data = \[
BatchEncoding({
'input\_ids': \[101, ...\], # pos 编码后的 token ID
'attention\_mask': \[1, 1, ...\] # 注意力掩码
}),
BatchEncoding({
'input\_ids': \[101, ...\], # neg 编码后的 token ID
'attention\_mask': \[1, 1, ...\] # 注意力掩码
}),
BatchEncoding({
'input\_ids': \[101, ...\], # neg 编码后的 token ID
'attention\_mask': \[1, 1, ...\] # 注意力掩码
})
.......
\]
底层本质还是个分类模型,使用的是SequenceClassifierOutput
class CrossEncoder(nn.Module):
def \_\_init\_\_(self, hf\_model: PreTrainedModel, model\_args: ModelArguments, data\_args: DataArguments,
train\_args: TrainingArguments):
super().\_\_init\_\_()
self.hf\_model \= hf\_model
self.model\_args \= model\_args
self.train\_args \= train\_args
self.data\_args \= data\_args
self.config \= self.hf\_model.config
self.cross\_entropy \= nn.CrossEntropyLoss(reduction='mean')
self.register\_buffer(
'target\_label',
torch.zeros(self.train\_args.per\_device\_train\_batch\_size, dtype\=torch.long)
)
def gradient\_checkpointing\_enable(self, \*\*kwargs):
self.hf\_model.gradient\_checkpointing\_enable(\*\*kwargs)
def forward(self, batch):
#选择分类模型
ranker\_out: SequenceClassifierOutput = self.hf\_model(\*\*batch, return\_dict=True)
logits \= ranker\_out.logits
if self.training:
scores \= logits.view(
self.train\_args.per\_device\_train\_batch\_size,
self.data\_args.train\_group\_size
)
#通过target\_label选择pos列用于计算loss的分母
loss = self.cross\_entropy(scores, self.target\_label)
return SequenceClassifierOutput(
loss\=loss,#输入loss反向传播更新参数
\*\*ranker\_out,
)
else:
return ranker\_out
@classmethod
def from\_pretrained(
cls, model\_args: ModelArguments, data\_args: DataArguments, train\_args: TrainingArguments,
\*args, \*\*kwargs
):
hf\_model \= AutoModelForSequenceClassification.from\_pretrained(\*args, \*\*kwargs)
reranker \= cls(hf\_model, model\_args, data\_args, train\_args)
return reranker
def save\_pretrained(self, output\_dir: str):
state\_dict \= self.hf\_model.state\_dict()
state\_dict \= type(state\_dict)(
{k: v.clone().cpu()
for k,
v in state\_dict.items()})
self.hf\_model.save\_pretrained(output\_dir, state\_dict\=state\_dict)
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









