



通义千问Qwen2.5-Omni-7B正式开源。
作为通义系列模型中首个端到端全模态大模型,可同时处理文本、图像、音频和视频等多种输入,并实时生成文本与自然语音合成输出。
在权威的多模态融合任务OmniBench等测评中,Qwen2.5-Omni刷新业界纪录,全维度远超Google的Gemini-1.5-Pro等同类模型。
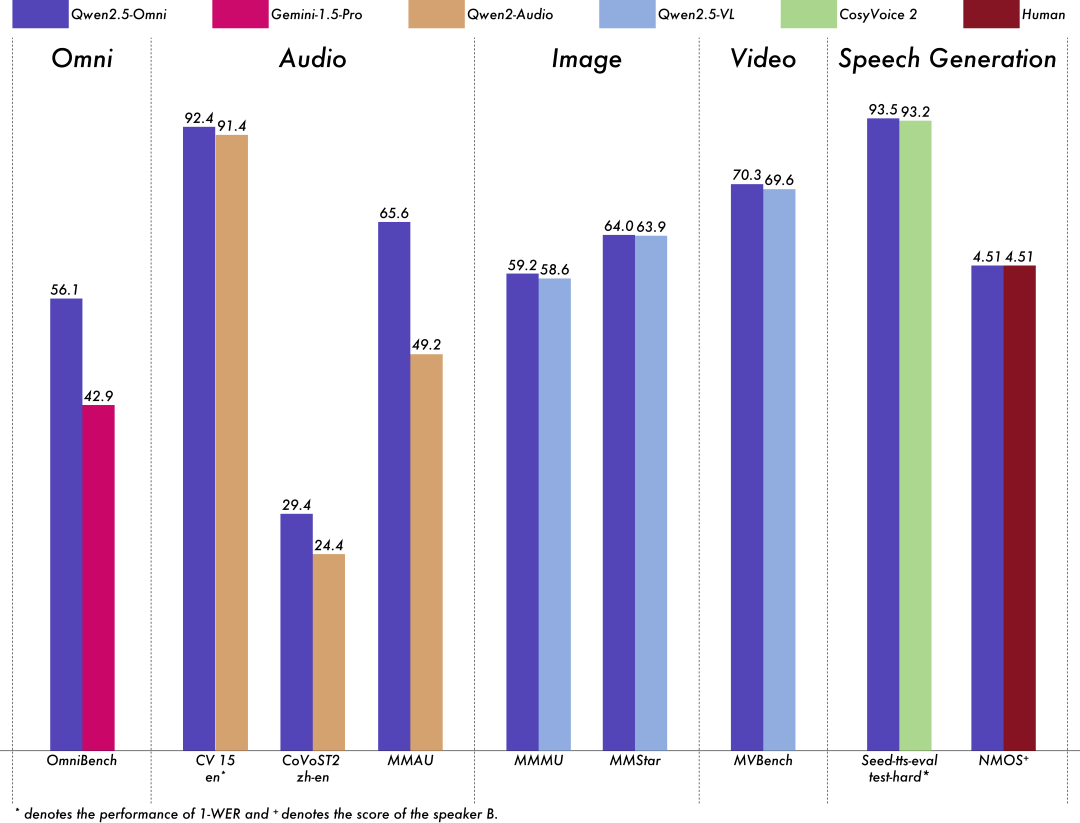
Qwen2.5-Omni以接近人类的多感官方式「立体」认知世界并与之实时交互,还能通过音视频识别情绪,在复杂任务中进行更智能、更自然的反馈与决策。目前,开发者和企业可免费下载商用Qwen2.5-Omni,手机等终端智能硬件也可轻松部署运行。
Qwen2.5-Omni采用了通义团队全新首创的Thinker-Talker双核架构、Position Embedding (位置嵌入)融合音视频技术、位置编码算法TMRoPE(Time-aligned Multimodal RoPE)。双核架构Thinker-Talker让Qwen2.5-Omni拥有了人类的“大脑”和“发声器”,形成了端到端的统一模型架构,实现了实时语义理解与语音生成的高效协同。具体而言,Qwen2.5-Omni支持文本、图像、音频和视频等多种输入形式,可同时感知所有模态输入,并以流式处理方式实时生成文本与自然语音响应。

得益于上述突破性创新技术,Qwen2.5-Omni在一系列同等规模的单模态模型权威基准测试中,展现出了全球最强的全模态优异性能,其在语音理解、图片理解、视频理解、语音生成等领域的测评分数,均领先于专门的Audio或VL模型,且语音生成测评分数(4.51)达到了与人类持平的能力。
相较于动辄数千亿参数的闭源大模型,Qwen2.5-Omni以7B的小尺寸让全模态大模型在产业上的广泛应用成为可能。即便在手机上,也能轻松部署和应用Qwen2.5-Omni模型。当前,Qwen2.5-Omni已在魔搭社区和Hugging Face 同步开源,用户也可在Qwen Chat上直接体验。
从2023年起,通义团队就陆续开发了覆盖0.5B、1.5B、3B、7B、14B、32B、72B、110B等参数的200多款「全尺寸」大模型,囊括文本生成模型、视觉理解/生成模型、语音理解/生成模型、文生图及视频模型等「全模态」,真正实现了让普通用户和企业都用得上、用得起AI大模型。截至目前,海内外AI开源社区中千问Qwen的衍生模型数量突破10万,是公认的全球第一开源模型。
Qwen Chat免费体验:
https://chat.qwenlm.ai
百炼平台模型调用:
https://help.aliyun.com/zh/model-studio/user-guide/qwen-omni
**Demo体验:
**
https://modelscope.cn/studios/Qwen/Qwen2.5-Omni-Demo
开源地址:
https://huggingface.co/Qwen/Qwen2.5-Omni-7B
https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
https://github.com/QwenLM/Qwen2.5-Omni
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
大模型就业发展前景
根据脉脉发布的《2024年度人才迁徙报告》显示,AI相关岗位的需求在2024年就已经十分强劲,TOP20热招岗位中,有5个与AI相关。
 字节、阿里等多个头部公司AI人才紧缺,包括算法工程师、人工智能工程师、推荐算法、大模型算法以及自然语言处理等。
字节、阿里等多个头部公司AI人才紧缺,包括算法工程师、人工智能工程师、推荐算法、大模型算法以及自然语言处理等。

除了上述技术岗外,AI也催生除了一系列高薪非技术类岗位,如AI产品经理、产品主管等,平均月薪也达到了5-6万左右。
AI正在改变各行各业,行动力强的人,早已吃到了第一波红利。
最后
大模型很多技术干货,都可以共享给你们,如果你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 1373
1373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









