







前言
本文全面回顾了机器学习的发展历史,从早期的基本算法到当代的深度学习模型,再到未来的可解释AI和伦理考虑。文章深入探讨了各个时期的关键技术和理念,揭示了机器学习在不同领域的广泛应用和潜力。最后,总结部分强调了机器学习作为一种思维方式和解决问题的工具,呼吁所有参与者共同探索更智能、更可持续的未来,同时关注其潜在的伦理和社会影响。
1. 引言
机器学习作为人工智能的核心部分,已经成为现代科技发展不可或缺的重要组成。随着大数据的兴起和计算能力的增强,机器学习技术逐渐渗透到我们生活的方方面面。本章节将简要介绍机器学习的基本定义、其重要性以及在各领域的应用场景。
1.1 机器学习的定义
机器学习是一门研究计算机如何利用经验改善性能的科学。它的主要目的是通过从数据中学习模式并作出预测或决策。在技术层面上,机器学习可以分为监督学习、无监督学习、半监督学习和强化学习等。
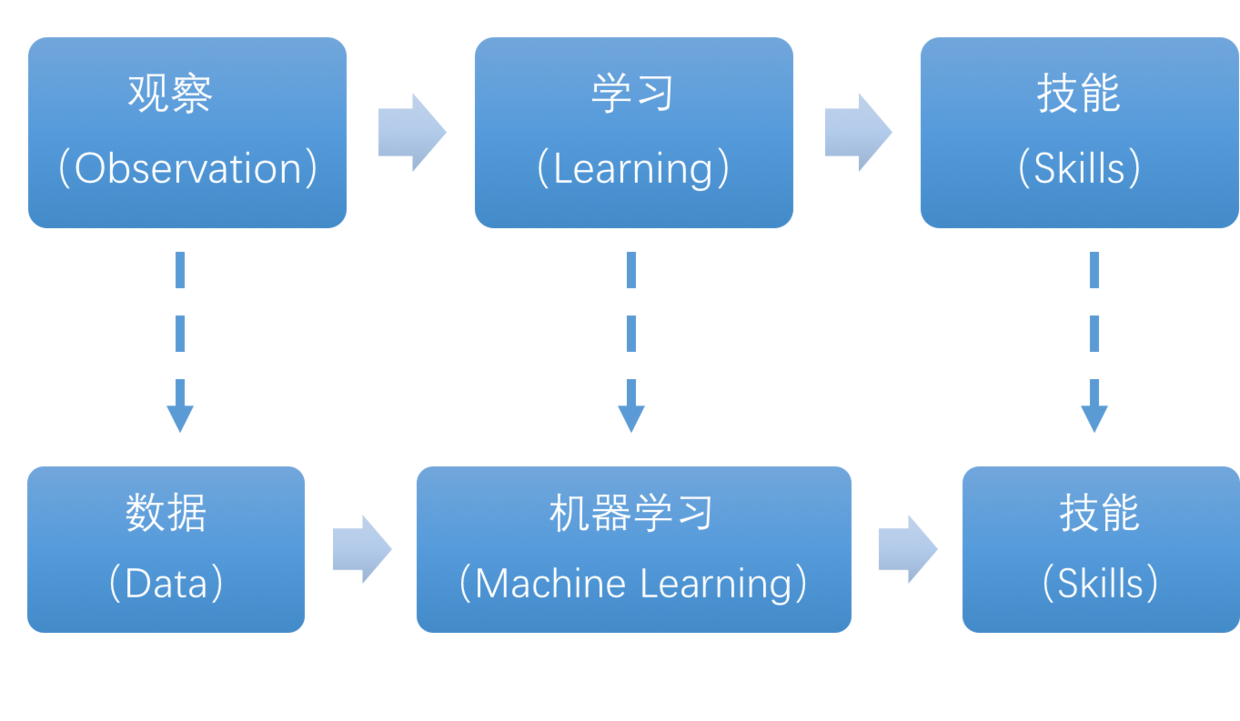
1.2 重要性和应用场景
重要性
机器学习已经变得极其重要,它不仅推动了科学研究的进展,还促进了许多工业领域的创新。通过自动化和智能化的手段,机器学习正在不断改变我们的工作和生活方式。
应用场景

机器学习的应用已经渗透到许多领域,包括但不限于:
- 医疗:通过分析医学图像和临床数据进行疾病诊断。
- 金融:用于风险管理、股票市场分析等。
- 自动驾驶:通过解析来自传感器的数据,使汽车能够自主行驶。
- 娱乐:推荐系统的构建,为用户提供个性化的内容推荐。
2. 机器学习的早期历史
机器学习的早期历史反映了人类对自动化和智能计算的初步探索。在这个时期,许多基本的算法和理论框架得以提出,为后续的研究奠定了坚实的基础。
2.1 初期理论与算法
在20世纪50年代至70年代,机器学习的早期阶段,许多核心的理论和算法得以形成。
感知机
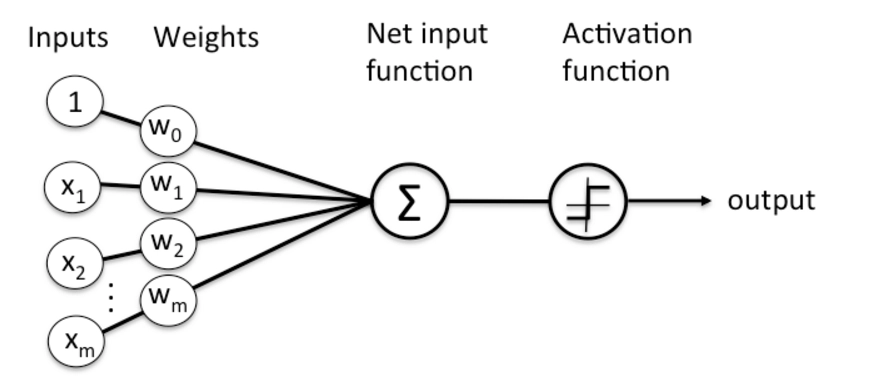
感知机是一种简单的人工神经网络,由Frank Rosenblatt于1957年提出。它是二分类线性分类器的基础,并开启了神经网络的研究。
# 感知机算法示例
def perceptron(training_data, iterations):
weights = [0] * len(training_data[0][0])
for _ in range(iterations):
for inputs, label in training_data:
prediction = int(dot_product(inputs, weights) > 0)
update = label - prediction
weights = [w + update * x for w, x in zip(weights, inputs)]
return weights
# 输出: 最终学习到的权重
2.1 初期理论与算法
决策树
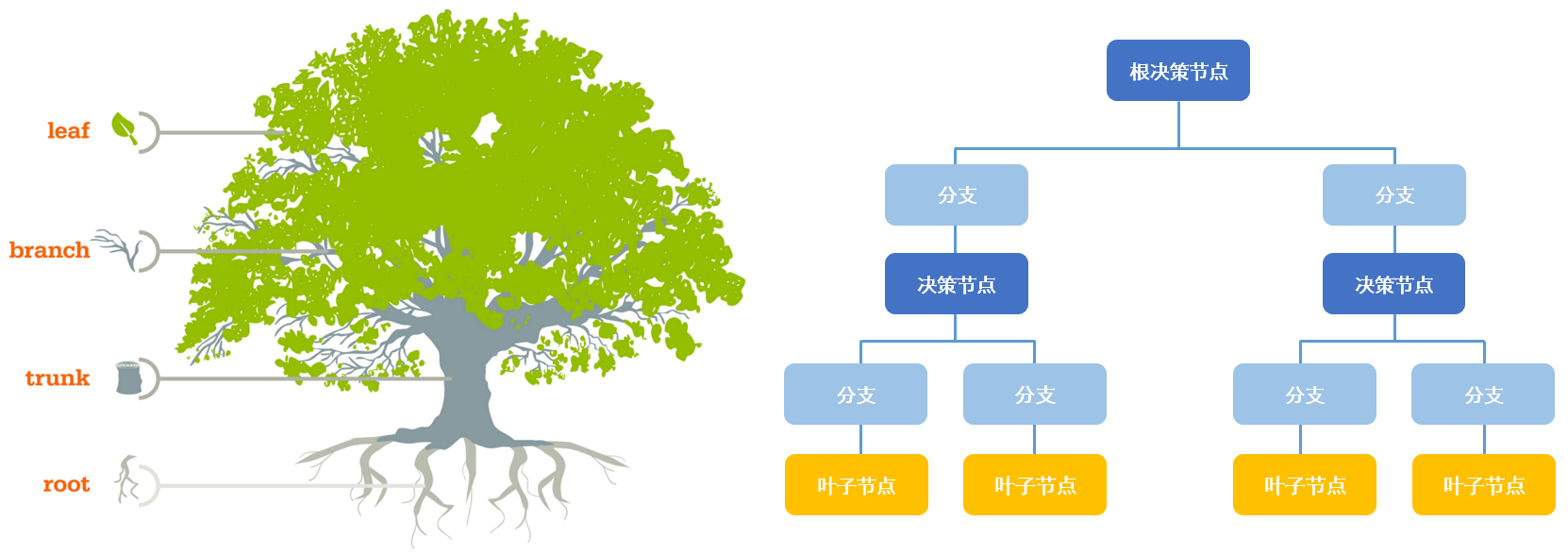
决策树的构建可以使用许多现成的库,如Scikit-learn。
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
# 加载数据
iris = load_iris()
X, y = iris.data, iris.target
# 创建决策树分类器
clf = DecisionTreeClassifier()
# 训练模型
clf.fit(X, y)
# 预测新数据
prediction = clf.predict([[5.1, 3.5, 1.4, 0.2]])
# 输出: 预测类别
2.2 早期突破
支持向量机
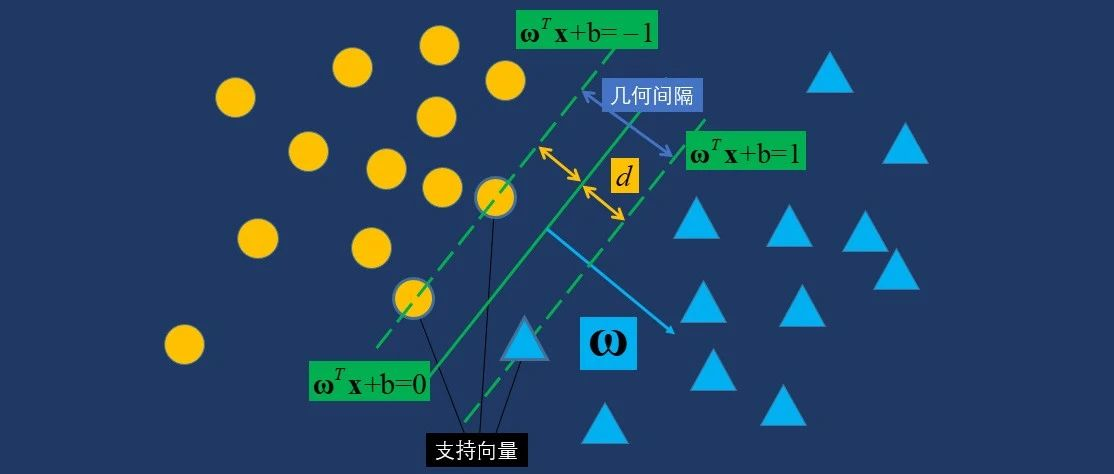
支持向量机的实现也可以使用Scikit-learn库。
from sklearn import svm
# 创建SVM分类器
clf = svm.SVC()
# 训练SVM分类器
clf.fit(X, y)
# 预测新数据
prediction = clf.predict([[5.1, 3.5, 1.4, 0.2]])
# 输出: 预测类别
神经网络初探
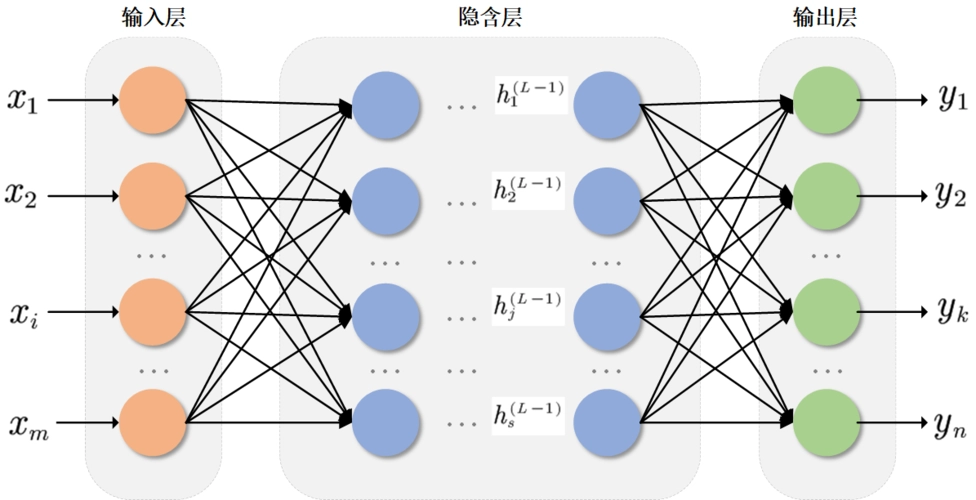
在Python中,可以使用库如TensorFlow或PyTorch来实现神经网络。以下是一个简单的多层感知机(MLP)示例:
import tensorflow as tf
# 定义模型
model = tf.keras.Sequential([
tf.keras.layers.Dense( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2040
2040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









