






SD 安装与部署
SD的安装和使用可以在本地电脑进行,也可以通过云端来实现。两种方式各有其优缺点:
-
本地安装:对电脑硬件有一定要求,尤其是显卡、内存、硬盘和CPU。显卡是最关键的,推荐使用Nvidia的独立显卡,至少10系列,想要更好的体验可以选择40系列,显存至少4GB,建议8GB以上。内存至少8GB,硬盘最好是固态硬盘,能加快数据读取速度。支持的操作系统包括Windows 10/11、macOS(仅限搭载Apple Silicon的Mac,Intel芯片的Mac无法使用Radeon显卡)、以及Linux系统。不过,macOS系统上可用的插件可能较少,功能上可能不如Windows和Linux系统全面。
-
云端安装:对本地电脑的硬件要求较低,因为计算和存储主要在云端进行,但需要支付给云服务商一定的使用费用。
如果本地电脑不满足上述硬件要求,可以考虑使用云端虚拟主机服务。对于那些既没有独立显卡也无法使用云服务的情况,可以通过调整软件设置,使用CPU进行渲染。虽然这种方式兼容性好,但渲染速度较慢,且内存需求至少为16GB。此外,还有一些第三方平台提供有限的免费体验,例如LibLib,每天可以免费生成100张图片。
本地安装与部署
目前普遍采用的 SD UI 是 Github 上的 Python 项目,在使用时需要对项目项目在不同的电脑和系统上编译源码,这需要使用者拥有一定的程序开发经验,所以这里我们直接使用 B 站秋叶大佬的整合包,直接安装使用。
1**.软件下载(文末获取籽料哦~)
2**.软件安装**
- 下载后,解压文件,首先安装运行依赖。
- 解压 sd-webui-v4.2
在刚刚解压的文件夹内找到启动器,双击后可以启动。
软件启动后,点击右下角的 “一键启动” 。
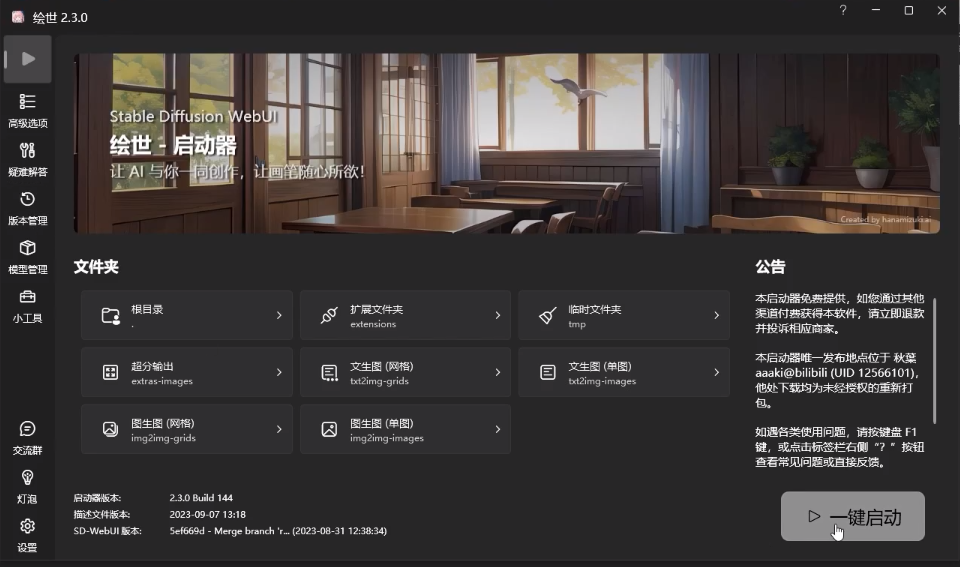
点击后会跳出如下界面,等待加载一段时间后,会自动跳转到网页操作页面。
云端安装与部署
云端服务厂商比较多,如果只是平时使用,不作为生成工具建议直接使用 第三方免费体验的功能。我这里免费体验使用的是 LibLib, 每天可以免费生成300张图片。
认识模型和插件
在使用 SD 中,我们需要了解大模型,LORA,另外还有 VAE ,hypernetworks(超网络模型),Embedding(嵌入式模型)等的一些常见基础知识。
模型
**- 大模型
**Checkpoint 是 SD 的核心,是最基本的必备模型,体积较大,也被称为大模型。越大的模型代表融合的元素越多,表现的效果细节越丰富。不同的大模型使用不同的图片训练而成,对应不同的风格,相当于最底层的引擎。我们在模型网站筛选 Checkpoint 就是筛选大模型。
大模型后缀分两种,ckpt 和 safetensor 。
一般 ckpt 融合的数据多一点,safetensor 融合的数据少一点,模型侧重不同,各有优略,不代表好坏。
模型存放位置:\models\Stable-diffusion
本地和云端部署模型在 SD 存放位置都是一样的。
- Lora
为某一风格特色的细分,是特征模型,体积较小,使用大模型后需要加一些独特的风格,就可以找这种风格的 Lora,或者自己训练。
多个 Lora 模型混合使用可以起到叠加效果,譬如一个控制面部的 Lora 配合一个控制画风的 Lora 就可以生成具有特定画风的特定人物。因此可以使用多个专注于不同方面优化的Lora,分别调整权重,结合出自己想要实现的效果。
lora的后缀:safetensors。
模型存放位置:\models\Lora
本地和云端部署模型在 SD 存放位置都是一样的。
**- VAE
**VAE 模型类似滤镜 + 模型微调,对画面进行调色与微调,一般需要搭配相应的模型一起使用。(如果图片比较灰,颜色不太靓丽,就可能是没加载对应的 VAE)
模型存放位置:\models\VAE
本地和云端部署模型在 SD 存放位置都是一样的。
- Textual inversion(Embedding)
关键词预设模型,即关键词打包,即等于预设好一个关键词打包,进而来指代特定的对象/风格。比如在描述一个叫 Jam 的人物的关键词时可以把描述词打包成 Jam。
模型存放位置:\models\Embedding
本地和云端部署模型在 SD 存放位置都是一样的。
- hypernetworks(超网络模型)
Hypernetwork 是一个比 Lora 更早的模型微调技术,现在使用的人数越来越少。
模型存放位置:\models\hypernetworks
本地和云端部署模型在 SD 存放位置都是一样的。
模型下载
模型下载模型下载的渠道很多,一种是网站下载,一个是本地部署的启动器内下载。
1.网站下载模型网站很多,这里主要介绍 2 个:
国内 - 哩布哩布:https://www.liblib.ai
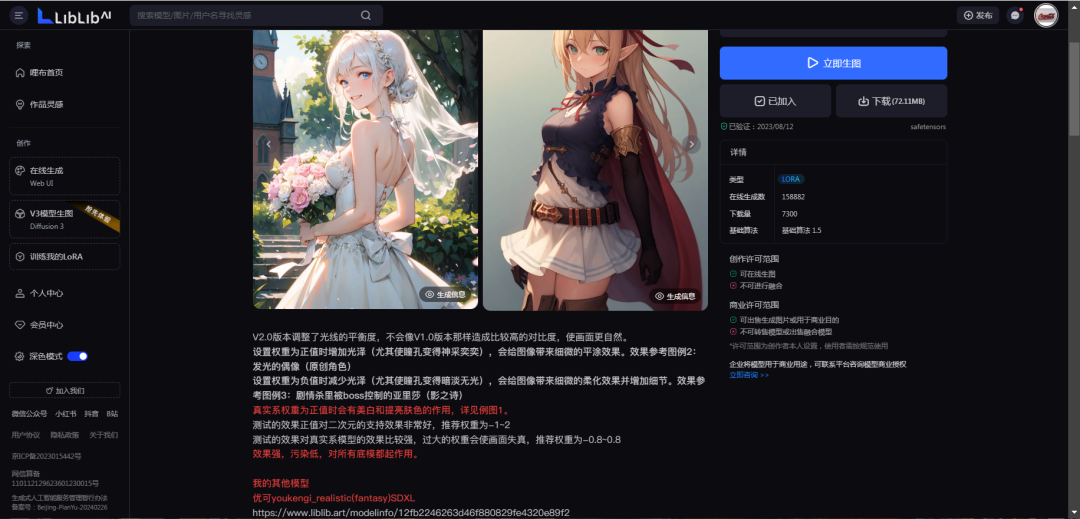
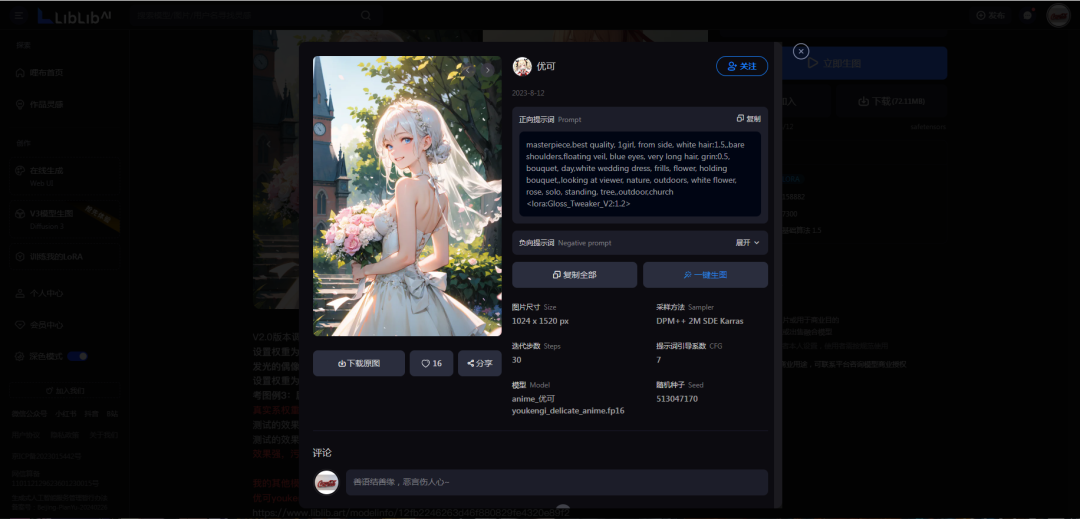
每个模型详细页面也有模型的参数、使用建议和效果图的具体信息,包括正反提示词,使用的什么模型,以及参数细节。
国外 - C站:https://civitai.com
备注:需要魔法访问
2.启动器下载,可以在启动器模型管理选择对应的模型直接下载。
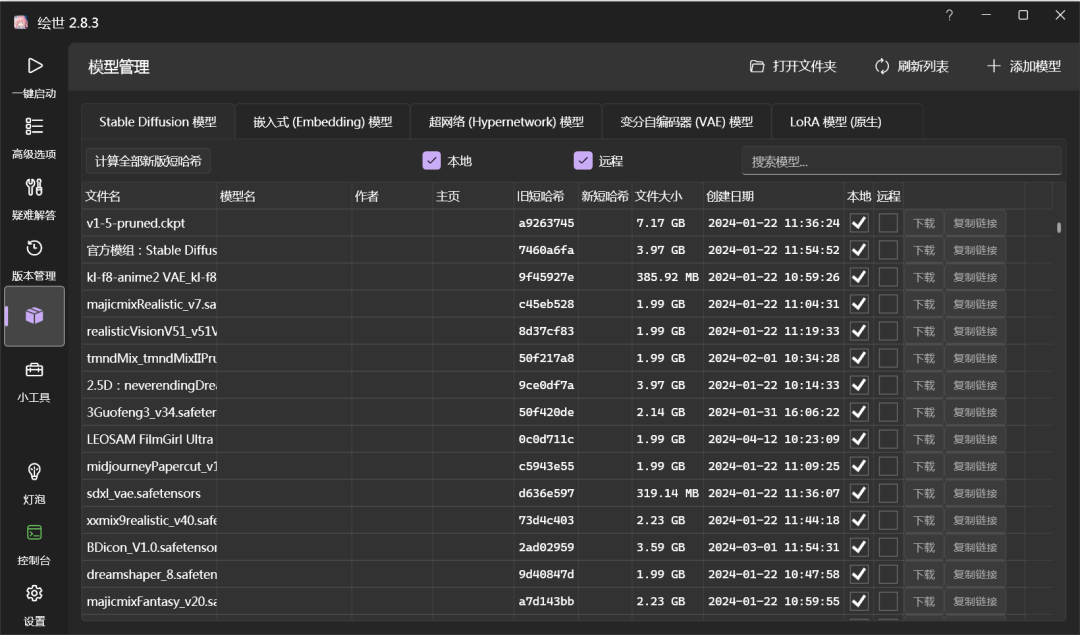
模型切换
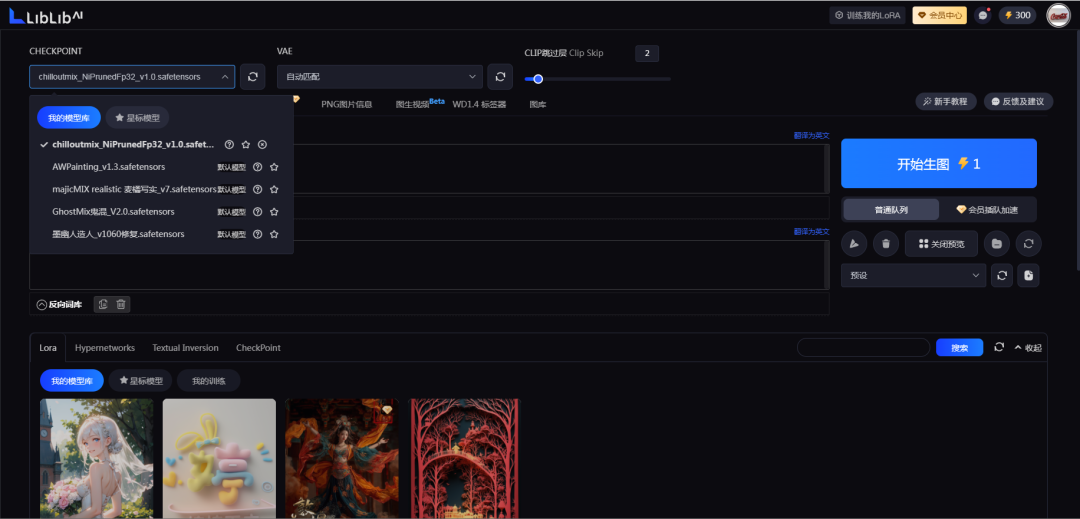
插件安装
众多开发者针对 SD 的应用开发出来的插件,使得 SD 的应用门槛降低,也增加了很多的玩法,插件的应用是 SD 的一大特色。
插件我们一般分为两种,辅助类和控制类。
插件存放位置:\extensions
本地和云端部署插件在 SD 存放位置都是一样的。
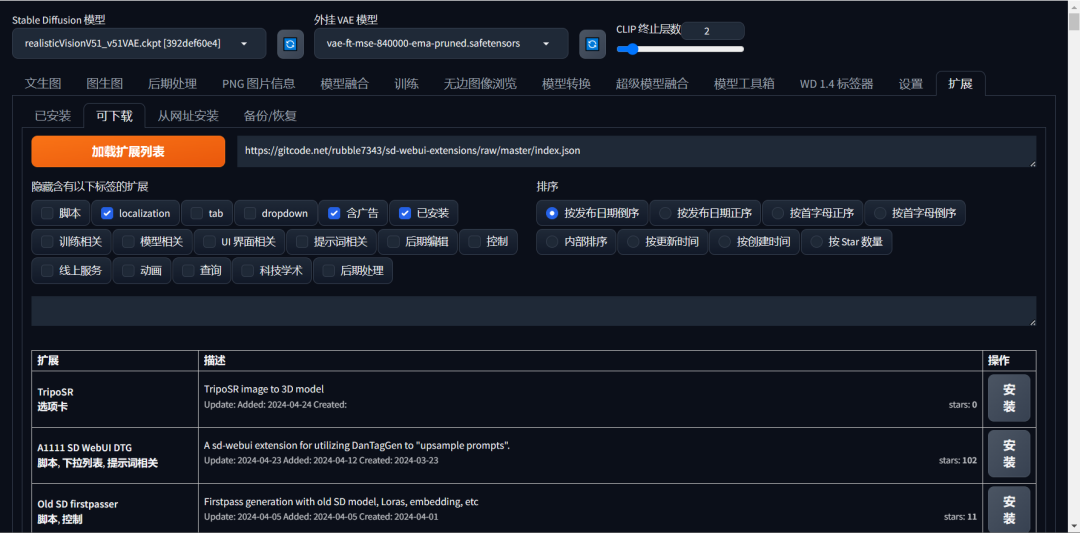
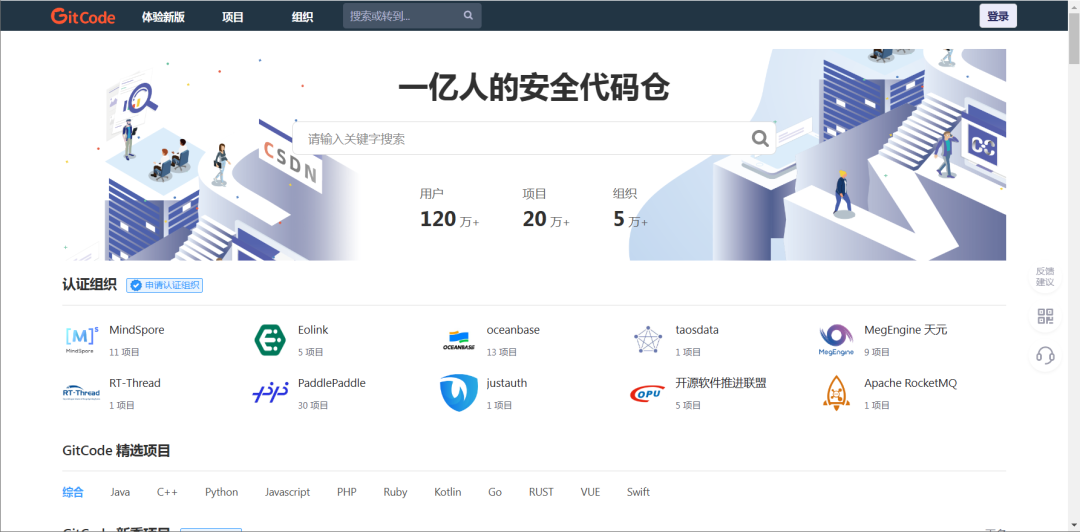
可以从 https://gitcode.net 下载相关的插件。
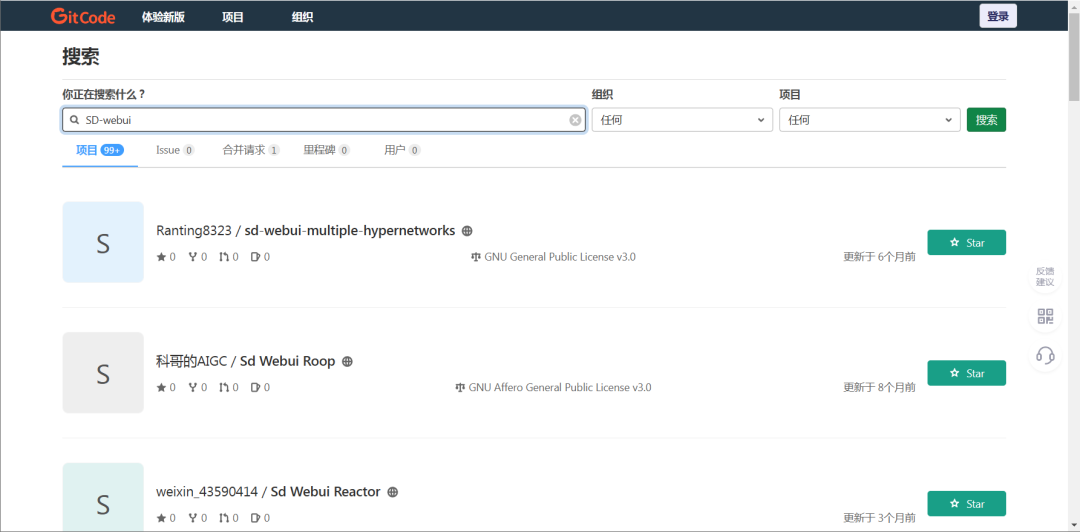
输入 SD-webui 查找对应的插件。
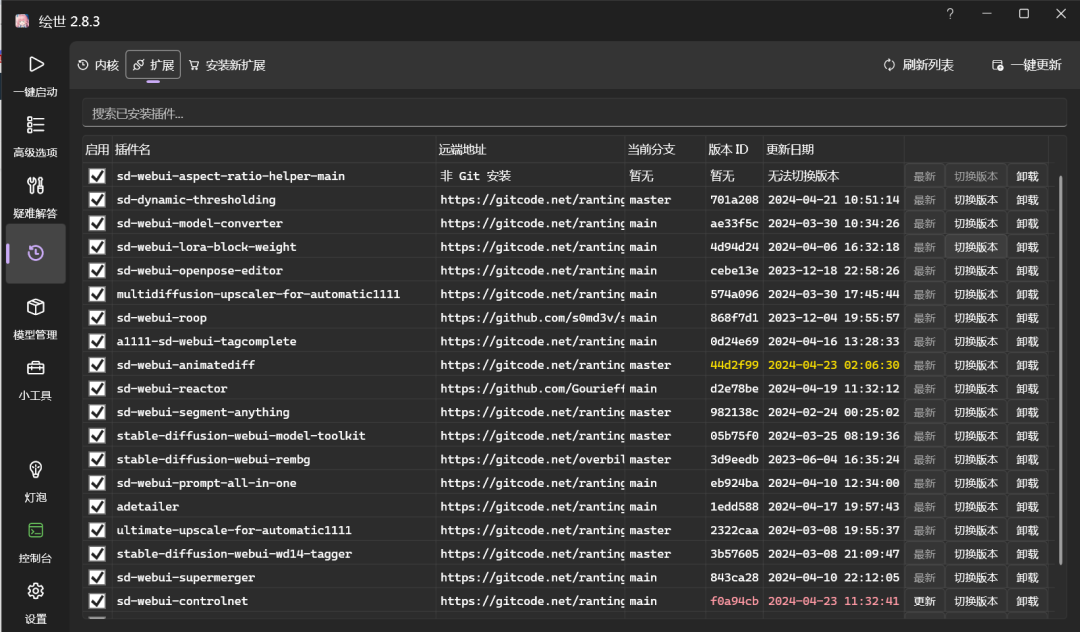
如果需要更新插件,可以在本地启动器中更新对应的插件。
基础使用教程
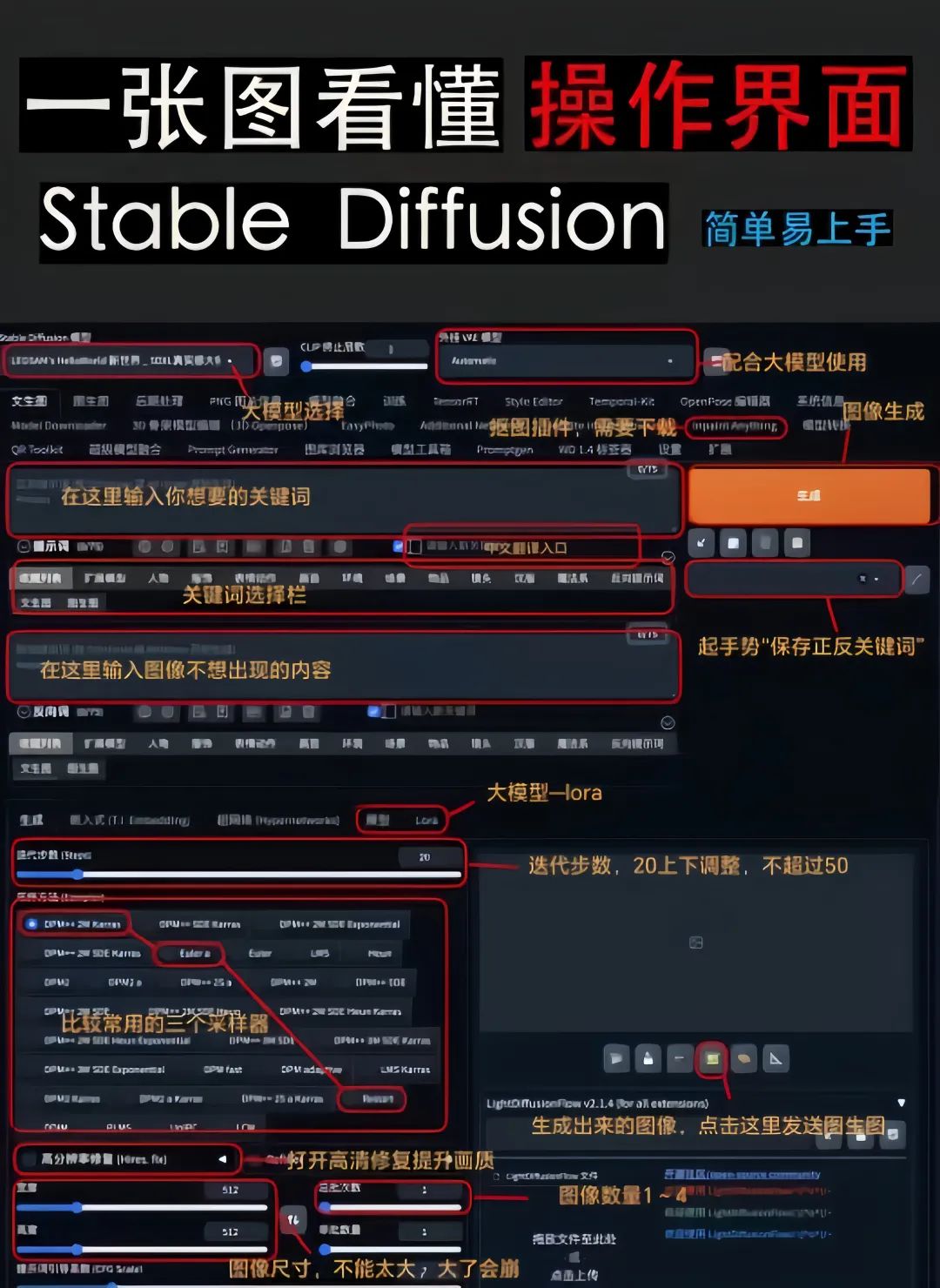
这是不是一下就可以看明白了,接下来我们试试吧~
输入正向提示词和反向提示词
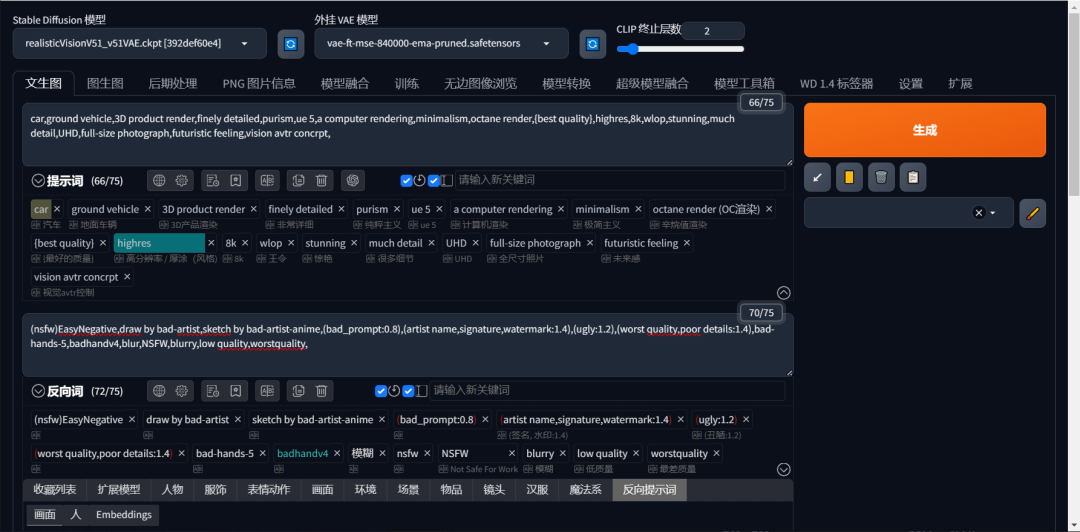
正向词:
car,ground vehicle,3D product render,finely detailed,purism,ue 5,a computer rendering,minimalism,octanerender{bestquality},highres,8k,wlop,stunning,muchdetail,UHD,full-size photograph,futuristic feeling,vision avtr concrpt,
反向词:
(nsfw)EasyNegative,drawbybad-artist,sketchbybad-artist-anime,(bad_prompt:0.8),(artistname,signature,watermark:1.4),(ugly:1.2),(worst quality,poordetails:1.4),bad-hands-5,badhandv4,blur,NSFW,blurry,low quality,worstquality,
点击生成等待一会

生成图片后还可以通过修改提示词和其他参数重新生成想要的图片。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 3108
3108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









