



前言
ComfyUI 是一个基于节点流程式的stable diffusion AI 绘图工具WebUI, 通过将stable diffusion的流程拆分成节点,实现了更加精准的工作流定制和完善的可复现性。
ComfyUI因为内部生成流程做了优化,生成图片时的速度相较于WebUI有10%~25%的提升(根据不同显卡提升幅度不同),生成大图片的时候不会爆显存,只是图片太大时,会因为切块运算的导致图片碎裂。
一、下载安装
所有的AI设计工具,模型和插件,都已经整理好了,👇获取~

下载release包并解压
二、配置模型
将checkpoint模型放入ComfyUI\models\checkpoints目录
ComfyUI与WebUI之间共享模型
在ComfyUI目录中将extra_model_paths.yaml.example文件复制一份,重命名为将extra_model_paths.yaml
修改a111的base_path路径为WebUI路径
三、启动
运行run_nvidia_gpu.bat启动ComfyUI
四、更新
如果后面需要更新ComfyUI,可以直接使用update_comfyui.bat,就不需要重新下载和配置了
五、使用

鼠标右键呼出节点目录,可以直接在目录中选择节点。

鼠标双击呼出节点搜索窗口,知道节点名称的话,直接搜索比较快。

连接好节点网络,通过点击面板右侧的工具栏中的 Queue Prompt,就能开始图片生成了。

通过使用鼠标点击拖动节点上的输出输入点,即可创建连线。

一般的的节点网络包括:
- 输入阶段:模型输入,图片输入等。负责载入模型和图片。
- Clip阶段:clip跳过,clip编码器,lora,controlnet都在这个阶段。
- Unet阶段:ksampler节点,负责在潜空间生成图片。参数和webui中的生成参数基本上相同。
- Vae解码阶段:将生成的图片从潜空间转换成RGB色彩空间。Vae解码节点可以链接不同的VAE来得到不同的解码结果。
- 保存和后处理阶段:预览,保存,后处理
六、节点说明
1、Load Checkpoint(加载大模型节点)
加载大模型节点可以根据提供的配置文件加载扩散模型。

输入:
- ckpt_name:要加载的模型名称
输出:
- MODEL:用于去噪潜在变量的模型,连接到kSampler采样器,在采样器中完成反向扩散过程
- CLIP:用于编码文本提示的CLIP模型
- VAE:用于将图像编码和解码到潜在空间的VAE模型,在文生图中,连接到VAE解码器,将图像从潜在空间转换为像素空间
2、CLIP Text Encode (Prompt)(CLIP 文本编码 (Prompt) 节点)

CLIP 文本编码 (Prompt) 节点可以使用 CLIP 模型将文本提示编码成嵌入,这个嵌入可以用来指导扩散模型生成特定的图片。
CLIP 文本编码 (Prompt) 节点的 CONDITIONING 输出连接到 kSampler 采样器的输入正向提示和负向提示

3、Empty Latent Image(空潜在图像节点)

空潜在图像(Empty Latent Image)节点可以用来创建一组新的空白潜在图像。这些潜在图像可以被例如在txt2img工作流中通过采样器节点进行噪声处理和去噪后使用。
输入(inputs)包括潜在图像的像素宽度(width)和像素高度(height),以及潜在图像的数量(batch_size)。输出(outputs)则是空白的潜在图像(LATENT)。
4、KSampler(采样器)

KSampler 是 Stable Diffusion 中图像生成的核心。采样器将随机图像降噪为与提示匹配的图像。
- seed:随机种子值控制潜在图像的初始噪声,从而控制最终图像的合成。
- control_after_generation:种子如何变化。它可以是获取随机值(randomize)、加 1(increment)、减 1(decrement)或保持不变(fixed),如果想保持生成图片的一致性,那么就选择固定。
- steps:采样步长数。数值越高,失真就越少,一般设置20-30左右。
- cfg:重绘幅度和提示词相关性,值越高,提示词的相关性越高。如果太高,会失真。
- sampler_name:在这里,您可以设置采样算法。
- scheduler:控制每个步骤中噪音水平的变化方式。
- denoise:降噪过程应消除多少初始噪音。1 表示全部。
5、Upscale Latent(放大潜在图像节点)
放大潜在图像节点可以用来调整潜在图像的大小。

输入
- samples:需要被放大的潜在图像
- upscale_method:图像放大方法
- width:目标像素宽度
- height:目标像素高度
- crop:是否通过中心裁剪图片
输出:
- LATENT:调整大小后的潜在图像
6、VAE Decode(VAE解码节点)
VAE解码节点可以用来将潜在空间图像解码回像素空间图像,解码过程使用提供的变分自编码器VAE。

7、Load LoRA(加载LoRA)

Load LoRA 节点可用于加载 LoRA,多个 LoRA可以用串行的方式连接在一起。

输入:
- model:扩散模型。
- clip:CLIP 模型。
- lora_name:LoRA 名称。
- strength_model:修改扩散模型强度。此值可以为负。
- strength_clip:修改 CLIP 模型强度。此值可以为负。
输出:
- MODEL:修改后的扩散模型。
- CLIP:修改后的 CLIP 模型。
8、ControlNet

9、ComfyUI-Florence2反推插件
Florence-2 是一种高级视觉基础模型,它使用基于提示的方法来处理各种视觉和视觉语言任务。Florence-2 可以解释简单的文本提示,以执行字幕、对象检测和分割等任务。
使用ComfyUI Manager安装ComfyUI-Florence2插件

使用Florence2反推提示词

| 模型 | 模型尺寸 | 模型描述 |
|---|---|---|
| Florence-2-base[HF] | 0.23B | 使用 FLD-5B 的预训练模型 |
| Florence-2-large[HF] | 0.77B | 使用 FLD-5B 的预训练模型 |
| Florence-2-base-ft[HF] | 0.23B | 对下游任务的集合进行微调的模型 |
| Florence-2-large-ft[HF] | 0.77B | 对下游任务的集合进行微调的模型 |
这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以点击下方免费领取!
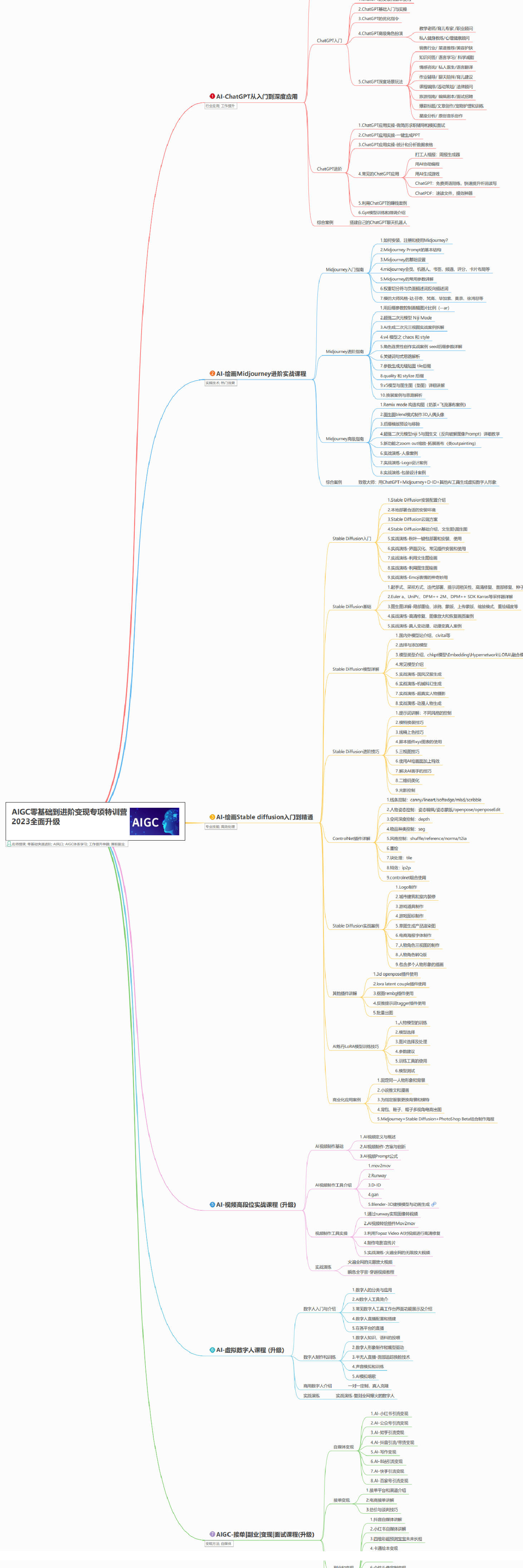
AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!
精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









