




 本文介绍了如何在Python面试中展现coding能力,包括使用sorted()函数进行复杂列表排序,有效利用数据结构如set、生成器节约内存,以及使用defaultdict和Counter简化字典操作。此外,还提到了Python标准库中的实用功能,如collections模块的defaultdict和Counter。
本文介绍了如何在Python面试中展现coding能力,包括使用sorted()函数进行复杂列表排序,有效利用数据结构如set、生成器节约内存,以及使用defaultdict和Counter简化字典操作。此外,还提到了Python标准库中的实用功能,如collections模块的defaultdict和Counter。
5. 使用sorted()对复杂列表进行排序
大量的编码面试问题需要进行某种排序,并且有多种有效的方法可以进行排序。除非面试官希望你实现自己的排序算法,否则通常最好使用sorted()。你可能已经看到了排序的最简单用法,例如按升序或降序排序数字或字符串列表:
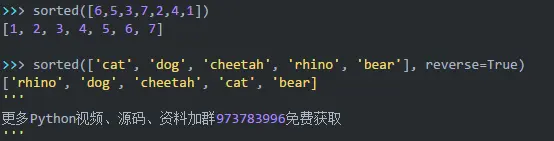
默认情况下,sorted()已按升序对输入进行排序,而reverse关键字参数则按降序排序。
值得了解的是可选关键字key,它允许你在排序之前指定将在每个元素上调用的函数。添加函数允许自定义排序规则,如果要对更复杂的数据类型进行排序,这些规则特别有用:

通过传入一个返回每个元素年龄的lambda函数,可以轻松地按每个字典的单个值对字典列表进行排序。在这种情况下,字典现在按年龄按升序排序。
有效利用数据结构
算法在面试中得到了很多关注,但数据结构可能更为重要。在coding面试环境中,选择正确的数据结构会对性能产生重大影响。除了理论数据结构之外,Python还在其标准数据结构实现中内置了强大而方便的功能。这些数据结构在面试中非常有用,因为它们默认为你提供了许多功能,让你可以将时间集中在问题的其他部分。
1. 使用set存储唯一值
我们通常需要从现有数据集中删除重复元素。新的开发人员有时会在列表应该使用集合时执行此操作,这会强制执行所有元素的唯一性。
假装你有一个名为get_random_word()的函数。它将始终从一小组单词中返回一个随机选择:

你应该重复调用get_random_word()以获取1000个随机单词,然后返回包含每个唯一单词的数据结构。以下是两种常见的次优方法和一种好的方法。
糟糕的方法
get_unique_words()将值存储在列表中,然后将列表转换为集合:
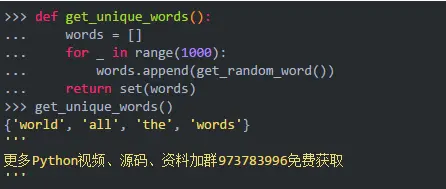
这种方法并不可怕,但它不必要地创建了一个列表,然后将其转换为集合。面试官几乎总是注意到(并询问)这种类型的设计选择。
更糟糕的做法
为避免从列表转换为集合,你现在可以在不使用任何其他数据结构的情况下将值存储在列表中。然后,通过将新值与列表中当前的所有元素进行比较来测试唯一性:
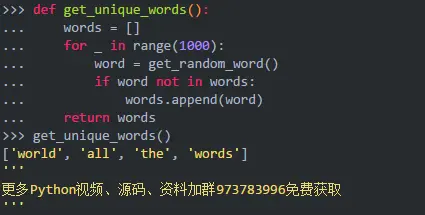
这比第一种方法更糟糕,因为你必须将每个新单词与列表中已有的每个单词进行比较。这意味着随着单词数量的增加,查找次数呈二次方式增长。换句话说,时间复杂度在O(N^2)的量级上增长。
优秀的方法
现在,你完全跳过使用列表,而是从头开始使用一组:
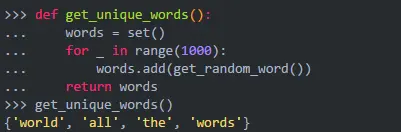
除了从头开始使用集合之外,这可能与其他方法没有太大的不同。如果你考虑.add()中发生了什么,它甚至听起来像第二种方法:得到单词,检查它是否已经在集合中,如果没有,则将其添加到数据结构中。
那么为什么使用与第二种方法不同的集合呢?
**它们是不同的,因为集合存储元素的方式允许接近恒定时间检查值是否在集合中,而不像需要线性时间查找的列表。**查找时间的差异意味着添加到集合的时间复杂度以O(N)的速率增长,这在大多数情况下比第二种方法的O(N^2)好得多。
2. 使用生成器节省内存
前面提到,列表推导是方便的工具,但有时会导致不必要的内存使用。想象一下,你被要求找到前1000个完美正方形的总和,从1开始。你知道列表推导,所以你快速编写一个有效的解决方案:
sum([i*iforiinrange(1,1001)])
333833500
解决方案会列出1到1,000,000之间的每个完美平方,并对值进行求和。你的代码会返回正确的答案,但随后您的面试官会开始增加您需要总和的完美正方形的数量。
起初,你的功能不断弹出正确的答案,但很快就开始放慢速度,直到最后这个过程似乎永远持续下去。这不是你想要在面试中发生的一件事。
这里发生了什么?
它正在列出你要求的每个完美的方块,并将它们全部加起来。具有1000个完美正方形的列表在计算机术语中可能不会很大,但是1亿或10亿是相当多的信息,并且很容易占用计算机的可用内存资源。这就是这里发生的事情。
值得庆幸的是,有一种解决内存问题的快捷方法。你只需用括号替换方括号:
sum((i*iforiinrange(1,1001)))
333833500
换出括号会将列表推导更改为生成器表达式。当你知道要从序列中检索数据,但不需要同时访问所有数据的时候,生成器表达式非常适合。
生成器表达式返回生成器对象,而不是创建列表。该对象知道它在当前状态中的位置(例如,i = 49)并且仅在被要求时计算下一个值。
因此,当sum通过重复调用.__ next __()来迭代生成器对象时,生成器检查i
等于多少,计算i * i,在内部递增i,并将正确的值返回到sum。该设计允许生成器用于大量数据序列,因为一次只有一个元素存在于内存中。
3. 使用.get()和.setdefault()在字典中定义默认值
最常见的编程任务之一涉及添加,修改或检索可能在字典中或可能不在字典中的项。Python字典具有优雅的功能,可以使这些任务简洁明了,但开发人员通常会在不需要时检查值。
想象一下,你有一个名为cowboy的字典,你想得到那个cowboy的名字。一种方法是使用条件显式检查key:
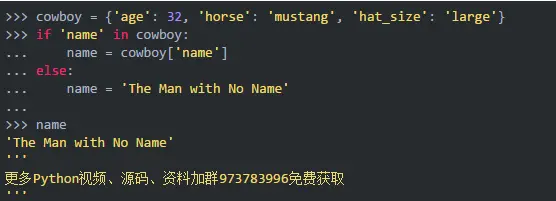
此方法首先检查字典中是否存在name键,如果存在,则返回相应的值。否则,它返回默认值。
虽然清楚地检查key确实有效,但如果使用.get(),它可以很容易地用一行代替:
name=cowboy.get(‘name’,‘The Man with No Name’)
get()执行与第一种方法相同的操作,但现在它们会自动处理。如果key存在,则返回适当的值。否则,将返回默认值。
但是,如果你想在仍然访问name的key时使用默认值更新字典呢? .get()在这里没有真正帮助你,所以你只需要再次显式检查这个值:

检查values并设置默认值是一种有效的方法,并且易于阅读,但Python再次使用.setdefault()提供了更优雅的方法:
name=cowboy.setdefault(‘name’,‘The Man with No Name’)
.setdefault()完成与上面代码片段完全相同的操作。它检查cowboy中是否存在名称,如果是,则返回该值。否则,它将cowboy [‘name’]设置为The Man with No Name并返回新值。
利用Python的标准库
默认情况下,Python提供了许多功能,这些功能只是一个导入语句。它本身就很强大,但知道如何利用标准库可以增强你的编码面试技巧。
从所有可用模块中挑选最有用的部分很困难,因此本节将仅关注其实用功能的一小部分。希望这些对您在编码访谈中有用,并且您希望了解更多有关这些和其他模块的高级功能的信息。
1. 使用collections.defaultdict()处理缺少的字典键
当你为单个键设置默认值时,.get()和.setdefault()可以正常工作,但通常需要为所有可能的未设置键设置默认值,尤其是在面试环境中进行编程时。
假装你有一群学生,你需要记录他们在家庭作业上的成绩。输入值是具有格式(student_name,grade)的元组列表,但是你希望轻松查找单个学生的所有成绩而无需迭代列表。
存储成绩数据的一种方法是使用将学生姓名映射到成绩列表的字典:
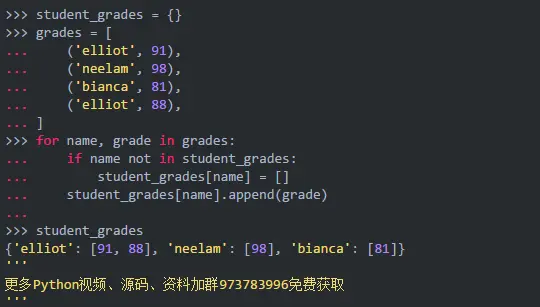
在这种方法中,你迭代学生并检查他们的名字是否已经是字典中的属性。如果没有,则将它们添加到字典中,并将空列表作为默认值。然后将实际成绩附加到该学生的成绩列表中。
但是有一个更简洁的方法,可以使用defaultdict,它扩展了标准的dict功能,允许你设置一个默认值,如果key不存在,它将按默认值操作:

在这种情况下,你将创建一个defaultdict,它使用不带参数的list构造函数作为默认方法。没有参数的list返回一个空列表,因此如果名称不存在则defaultdict调用list(),然后再把学生成绩添加上。如果你想更炫一点,你也可以使用lambda函数作为值来返回任意常量。
利用defaultdict可以使代码更简洁,因为你不必担心key的默认值。相反,你可以在defaultdict里处理它们一次,然后key就终存在了。
2. 使用collections.Counter计算Hashable对象
假如你有一长串没有标点符号或大写字母的单词,你想要计算每个单词出现的次数。
你可以使用字典或defaultdict增加计数,但collections.Counter提供了一种更清晰,更方便的方法。 Counter是dict的子类,它使用0作为任何缺失元素的默认值,并且更容易计算对象的出现次数:
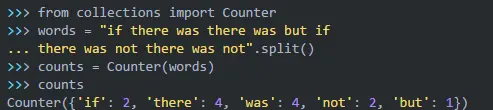
当你将单词列表传递给Counter时,它会存储每个单词以及该单词在列表中出现的次数。
如果你好奇两个最常见的词是什么?只需使用.most_common():
counts.most_common(2)
[(‘there’, 4), (‘was’, 4)]
.most-common()是一个方便的方法,只需按计数返回n个最频繁的输入。
3. 使用字符串常量访问公共字符串组
现在有一个琐事需要判断!‘A’>‘a’是真是假?
这是假的,因为A的ASCII代码是65,但a是97,65不大于97。为什么答案很重要?因为如果你想检查一个字符是否是英语字母表的一部分,一种流行的方法是看它是否在A和Z之间(在ASCII图表上是65和122)。
检查ascii代码是可行的,但是在面试时却很笨拙,很容易弄乱,特别是当你记不清是小写还是大写的ascii字符排在第一位的时候。这时候,使用定义在字符串模块中的常量要容易得多。
你可以使用is_upper(),它返回字符串中的所有字符是否都是大写字母:
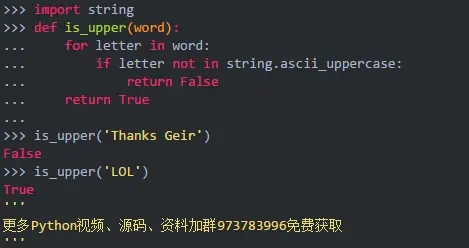
is_upper()迭代word中的字母,并检查字母是否为string.ascii_大写字母的一部分。如果你打印出string.ascii_大写,你会发现它只是一个字符串,该值设置为文本“ABCDEFGHIJKLMNOPQRSTUVWXYZ”。
所有字符串常量都只是经常引用的字符串值的字符串。其中包括以下内容:
string.ascii_letters
string.ascii_uppercase
string.ascii_lowercase
string.digits
string.hexdigits
string.octdigits
string.punctuation
文末有福利领取哦~
👉一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
👉二、Python必备开发工具

👉三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉 四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(文末领读者福利)

👉五、Python练习题
检查学习结果。

👉六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉因篇幅有限,仅展示部分资料,这份完整版的Python全套学习资料已经上传
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
ttps://img-blog.csdnimg.cn/5db8141418d544d3a8e9da4805b1a3f9.png)
👉因篇幅有限,仅展示部分资料,这份完整版的Python全套学习资料已经上传
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

















 310
310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









