




至此,我们完成数据的来源分析。
6.蜘蛛来也
完成了数据源分析,我们只需构造数据请求,并进行正确的数据解析,即可拿到我们想要的数据!
6.1.请求导航数据包
修改moment.py定义start_requests方法:
bookid = '12345678' #请填写【出书啦】返回链接中的数字部分
def start_requests(self):
"""
使用get方式请求导航数据包
"""
url = 'http://chushu.la/api/book/chushula-{0}?isAjax=1'.format(self.bookid) #获取目录的url
yield scrapy.Request(url, callback=self.parse)
重载parse方法,解析获取到的导航数据包:
def parse(self, response):
"""
处理获取到的导航数据包
"""
json_body = json.loads(response.body) #加载json数据包
catalogs = json_body['book']['catalogs'] #获取json中的目录数据包
6.2. 发送导航请求,抓取朋友圈数据
根据上面跟踪到发出的http导航请求,要想抓取到朋友圈数据,我们需要根据发出的请求参数构造参数。
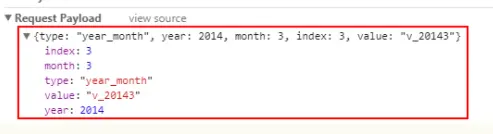
从上图可知,主要包含五个参数:
- type:"year_month"为默认值
- year: 年份
- month: 月份
- index: 第几页
- value : 由年月拼接的字符串
继续修改我们的parse方法,遍历我们第一步抓取到的导航数据包构造请求参数:
def parse(self, response):
"""
处理获取到的导航数据包
"""
json_body = json.loads(response.body) #加载json数据包
catalogs = json_body['book']['catalogs'] #获取json中的目录数据包
url = 'http://chushu.la/api/book/wx/chushula-{0}/pages?isAjax=1'.format(self.bookid) #分页数据url
start_page = int(catalogs[0]['month']) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3002
3002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









