








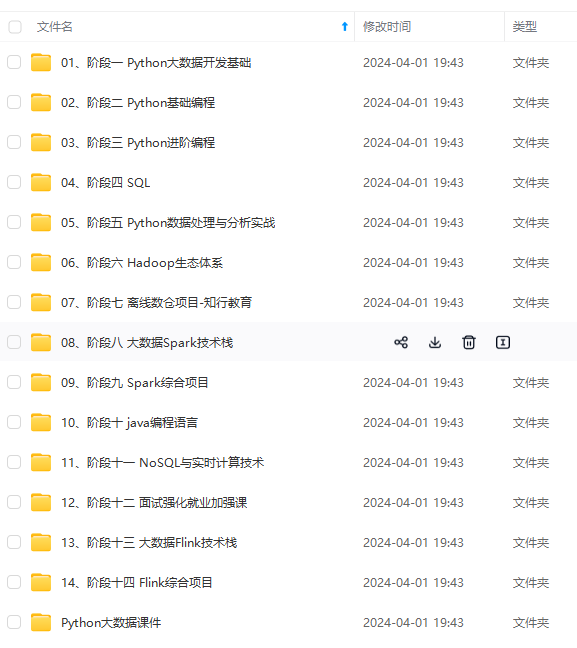
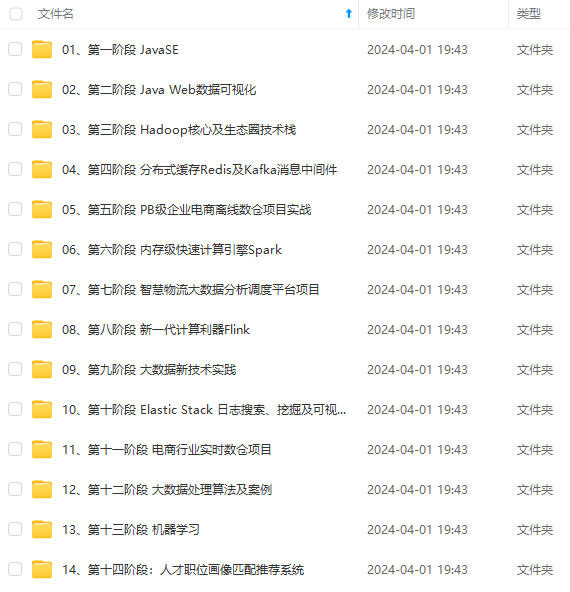
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
print(re.findall("caa[^,a]", "caa^bcabcaabc"))
输出:
['caa^', 'caab']
(2)^
^ 通常用来匹配行首,例如:
print(re.findall("^abca", "abcabcabc"))
输出结果:
['abca']

(3) $
$ 通常用来匹配行尾,例如:
print(re.findall("abc$", "accabcabc"))
输出结果:
['abc']

(4)\
反斜杠后面可以加不同的字符表示不同的特殊含义,常见的有以下3种。
- \d:匹配任何十进制数等价于[0-9]
print(re.findall("c\d\d\da", "abc123abc"))
输出结果为:
['c123a']
\可以转义成普通字符,例如:
print(re.findall("\^abc", "^abc^abc"))
输出结果:
['^abc', '^abc']
- s
匹配任何的空白字符例如:
print(re.findall("\s\s", "a c"))
输出结果:
[' ', ' ']
- \w
匹配任何字母数字和下划线,等价于[a-zA-Z0-9_],例如:
print(re.findall("\w\w\w", "abc12\_"))
输出:
['abc', '12\_']

(5){n}
{n}可以避免重复写,比如前面我们用\w时写了3次\w,而这里我们这需要用用上{n}就可以,n表示匹配的次数,例如:
print(re.findall("\w{2}", "abc12_"))
输出结果:
['ab', 'c1', '2\_']
(6)*
*表示匹配零次或多次(尽可能的多去匹配),例如:
print(re.findall("010-\d\*", "010-123456789"))
输出:
['010-123456789']
**(7) + **
+表示匹配一次或多次,例如
print(re.findall("010-\d+", "010-123456789"))
输出:
['010-123456789']
(8) .
.是个点,这里不是很明显,它用来操作除了换行符以外的任何字符,例如:
print(re.findall(".", "010\n?!"))
输出:
['0', '1', '0', '?', '!']
(9) ?
?表示匹配一次或零次
print(re.findall("010-\d?", "010-123456789"))
输出:
['010-1']
这里要注意一下贪婪模式和非贪婪模式。
贪婪模式:尽可能多的去匹配数据,表现为\d后面加某个元字符,例如\d*:
print(re.findall("010-\d\*", "010-123456789"))
输出:
['010-123456789']
非贪婪模式:尽可能少的去匹配数据,表现为\d后面加?,例如\d?
print(re.findall("010-\d\*?", "010-123456789"))
输出为:
['010-']
(10){m,n}
m,n指的是十进制数,表示最少重复m次,最多重复n次,例如:
print(re.findall("010-\d{3,5}", "010-123456789"))
输出:
['010-12345']
加上?表示尽可能少的去匹配
print(re.findall("010-\d{3,5}?", "010-123456789"))
输出:
['010-123']
{m,n}还有其他的一些灵活的写法,比如:
- {1,} 相当于前面提过的 + 的效果
- {0,1} 相当于前面提过的 ? 的效果
- {0,} 相当于前面提过的 * 的效果

关于常用的元字符以及使用方法就先到这里,我们再来看看正则的其他知识。
(二)正则的使用
1.编译正则
在Python中,re模块可通过compile() 方法来编译正则,re.compile(正则表达式),例如:
s = "010-123456789"
rule = "010-\d\*"
rule_compile = re.compile(rule) #返回一个对象
# print(rule\_compile)
s_compile = rule_compile.findall(s)
print(s_compile) #打印compile()返回的对象是什么
输出结果:
['010-123456789']
2.正则对象的使用方法
正则对象的使用方法不仅仅是通过我们前面所介绍的 findall() 来使用,还可以通过其他的方法进行使用,效果是不一样的,这里我做个简单的总结:
(1)findall()
找到re匹配的所有字符串,返回一个列表
(2)search()
扫描字符串,找到这个re匹配的位置(仅仅是第一个查到的)
(3)match()
决定re是否在字符串刚开始的位置(匹配行首)
就拿上面的 compile()编译正则之后返回的对象来做举例,我们这里不用 findall() ,用 match() 来看一下结果如何:
s = "010-123456789"
rule = "010-\d\*"
rule_compile = re.compile(rule) # 返回一个对象
# print(rule\_compile)
s_compile = rule_compile.match(s)
print(s_compile) # 打印compile()返回的对象是什么
输出:
<re.Match object; span=(0, 13), match='010-123456789'>
可以看出结果是1个match 对象,开始下标位置为0~13,match为 010-123456789 。既然返回的是对象,那么接下来我们来讲讲这个match 对象的一些操作方法。

3.Match object 的操作方法
这里先介绍一下方法,后面我再举例,Match对象常见的使用方法有以下几个:
(1)group()
返回re匹配的字符串
(2)start()
返回匹配开始的位置
(3)end()
返回匹配结束的位置

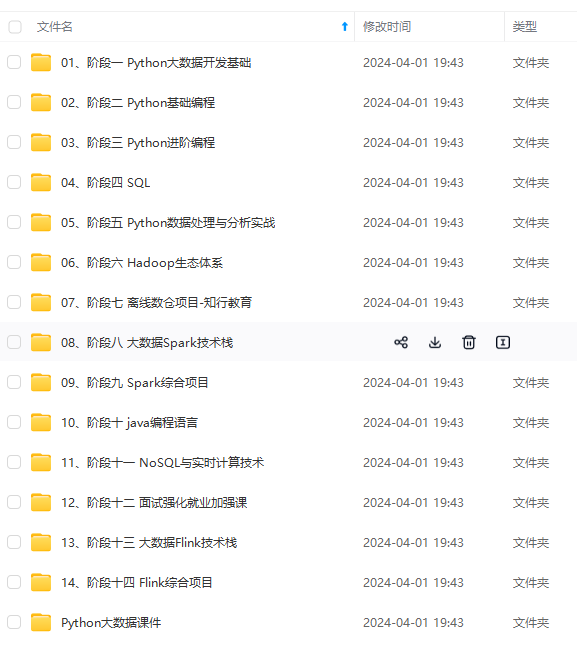
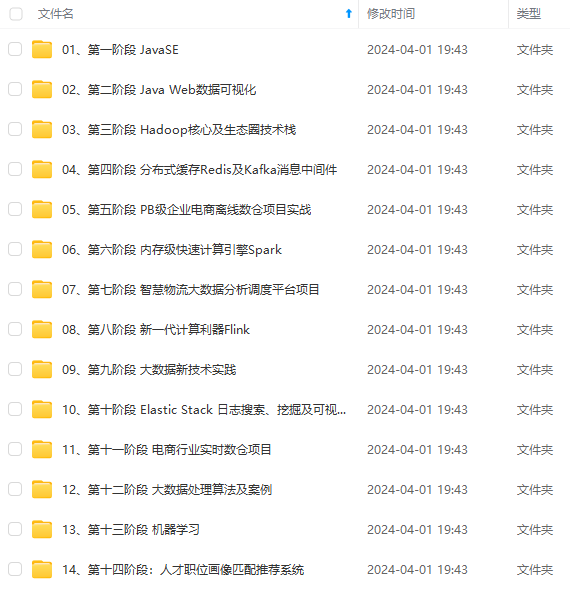
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
ect 的操作方法**
这里先介绍一下方法,后面我再举例,Match对象常见的使用方法有以下几个:
(1)group()
返回re匹配的字符串
(2)start()
返回匹配开始的位置
(3)end()
返回匹配结束的位置
[外链图片转存中…(img-2hsp3XXK-1715683781808)]
[外链图片转存中…(img-Q5dwZ9l4-1715683781808)]
[外链图片转存中…(img-R9UJoLgc-1715683781809)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









