





网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
需要注意的是,现实世界中的数据往往是结构化数据和非结构化数据的混合,因此在数据处理和分析时,需要综合考虑两种类型的数据。
三、Hadoop生态圈
Hadoop 是一个能够对大量数据进行分布式处理的软件框架。具有可靠、高效、可伸缩的特点。Hadoop 的核心是 HDFS 和 Mapreduce,HDFS 还包括 YARN。
1、HDFS(hadoop分布式文件)是hadoop体系中数据存储管理的基础。他是一个高度容错的系统,能检测和应对硬件故障。系统)
2、mapreduce(分布式计算框架)mapreduce是一种计算模型,用于处理大数据量的计算。其中map对应数据集上的独立元素进行指定的操作,生成键-值对形式中间,reduce则对中间结果中相同的键的所有值进行规约,以得到最终结果。
3、 hive(基于hadoop的数据仓库)由Facebook开源,最初用于解决海量结构化的日志数据统计问题。hive定于了一种类似sql的查询语言(hql)将sql转化为mapreduce任务在hadoop上执行。
4、hbase(分布式列存数据库)
hbase是一个针对结构化数据的可伸缩,高可靠,高性能,分布式和面向列的动态模式数据库。和传统关系型数据库不同,hbase采用了bigtable的数据模型:增强了稀疏排序映射表(key/value)。其中,键由行关键字,列关键字和时间戳构成,hbase提供了对大规模数据的随机,实时读写访问,同时,hbase中保存的数据可以使用mapreduce来处理,它将数据存储和并行计算完美结合在一起。
5、zookeeper(分布式协作服务)解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
6、sqoop(数据同步工具)sqoop是sql-to-hadoop的缩写,主要用于传统数据库和hadoop之间传输数据。数据的导入和导出本质上是mapreduce程序,充分利用了MR的并行化和容错性。
7、pig(基于hadoop的数据流系统)定义了一种数据流语言-pig latin,将脚本转换为mapreduce任务在hadoop上执行。通常用于离线分析。
8、mahout(数据挖掘算法库)mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。mahout现在已经包含了聚类,分类,推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法是,mahout还包含了数据的输入/输出工具,与其他存储系统(如数据库,mongoDB或Cassandra)集成等数据挖掘支持架构。
9、flume(日志收集工具)cloudera开源的日志收集系统,具有分布式,高可靠,高容错,易于定制和扩展的特点。他将数据从产生,传输,处理并写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在flume中定制数据发送方,从而支持收集各种不同协议数据。
10、资源管理器的简单介绍(YARN和mesos)随着互联网的高速发展,基于数据 密集型应用 的计算框架不断出现,从支持离线处理的mapreduce,到支持在线处理的storm,从迭代式计算框架到 流式处理框架s4,…,在大部分互联网公司中,这几种框架可能都会采用,比如对于搜索引擎公司,可能的技术方法如下:网页建索引采用mapreduce框架,自然语言处理/数据挖掘采用spark,对性能要求到的数据挖掘算法用mpi等。公司一般将所有的这些框架部署到一个公共的集群中,让它们共享集群的资源,并对资源进行统一使用,这样便诞生了资源统一管理与调度平台,典型的代表是mesos和yarn。
四、Hadoop HDFS 架构
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。
HDFS的优势:
1.高容错性2.高数据吞吐量3.支持超大文件4.流式数据访问
HDFS的劣势:
1.不适合低延时数据访问
比如毫秒级的来存储数据,这是不行的,它做不到。它适合高吞吐率的场景,就是在某一时间内写入大量的数据。但是它在低延时的情况下是不行的,比如毫秒级以内读取数据,这样它是很难做到的。
2.不适合小文件存储
存储大量小文件(这里的小文件是指小于HDFS系统的Block大小的文件(默认64M))的话,它会占用 NameNode大量的内存来存储文件、目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。
小文件存储的寻道时间会超过读取时间,它违反了HDFS的设计目标。
3.不适合并发写入、文件随机修改
一个文件只能有一个写,不允许多个线程同时写;仅支持数据 append(追加),不支持文件的随机修改。
架构图
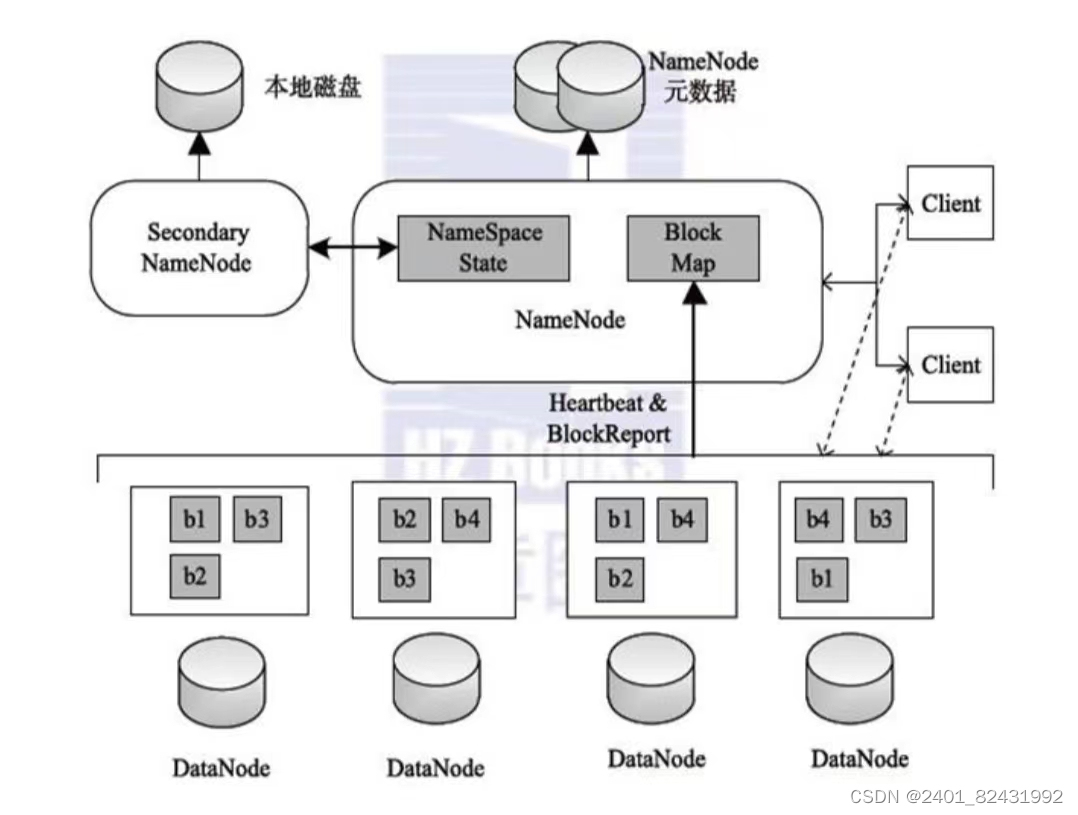
1.Client(客户端)
(1)文件切分,文件上传 HDFS 的时候,Client 将文件切分成一个一个的Block,然后进行存储
(2)与 NameNode 交互,获取文件的位置信息
(3)与 DataNode 交互,读取或者写入数据
(4)Client 提供一些命令来管理 HDFS,比如启动或者关闭HDFS
2.NameNode(master,它是一个主管、管理者)
(1)管理 HDFS 的名称空间
(2)管理数据块(Block)映射信息
(3)配置副本策略
(4)处理客户端读写请求
3.DataNode(slave,NameNode 下达命令,DataNode 执行实际的操作)
(1)存储实际的数据块
(2)执行数据块的读/写操作
4.Secondary NameNode(辅助者,并非 NameNode 的热备)
(1)辅助 NameNode,分担其工作量
(2)定期合并 fsimage和fsedits,并推送给NameNode
(3)在紧急情况下,可辅助恢复 NameNode
五、HDFS读写流程
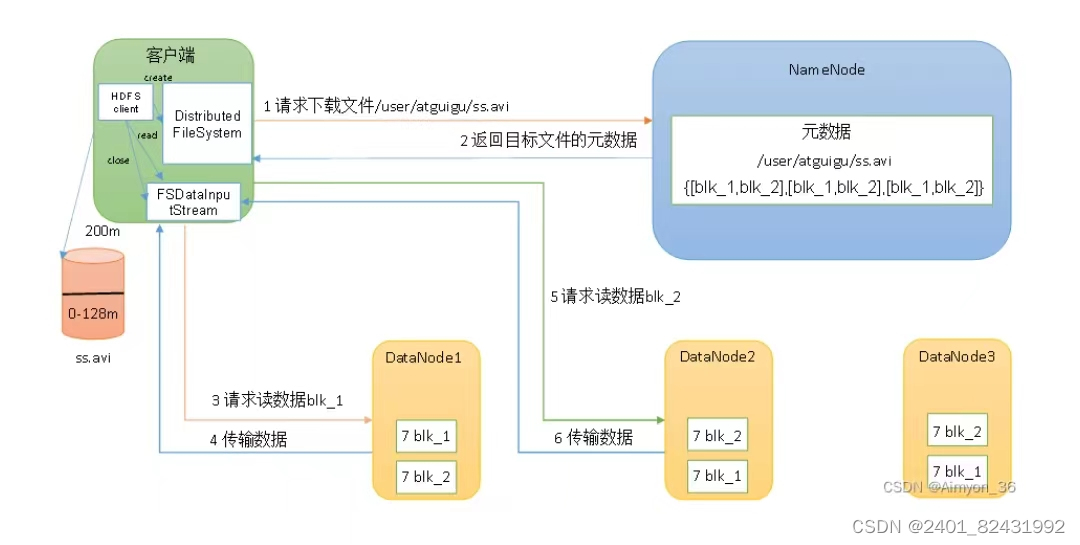
1.客户端向 NameNode 发送读取请求,请求包括要读取的文件名和文件块的起始位置。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









