







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
在校大学生如果想学习大数据,需要做以下准备:
1)准备一个台式机或笔记本
条件允许的情况下,可以自己买一个台式机或笔记本;

或者去学校机房、图书馆都可以学习(老王当初上大学就是经常去学校机房练习编程)。

2)学习大数据基础编程语言——重点学习
要学习的编程语言为Java或Python,具体喜欢哪一种编程语言,根据自己喜好选择即可。

如果精力和时间允许的情况话,可以再学点Linux命令,为后续学习以及部署大数据服务做准备。

3)编程语言书籍推荐
编程语言方面,可以参考《深入浅出Java》,《深入浅出Python》,这几本都比较适合初学者看。当然最重要的是多跟着书籍做练习,一定要记笔记,把不懂的地方在大数据成长社群进行提问。


4)免费学习网站——保姆级教程
完全免费——建议大家在相对比较系统的网站学习。菜鸟教程 - 学的不仅是技术,更是梦想!
老王建议基础薄弱的同学,优先把上面的内容学好,即使你后续转后端开发或者全栈,都需要这些基础知识做支撑。
5)学习Hadoop家族组件—建议作为了解部分
如果前面的基础编程有一定掌握后,这时可以尝试着学习hadoop家族的组件,从hdfs,hive,hbase等学起,逐步深入,切忌欲速则不达。
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。

HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。

hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。


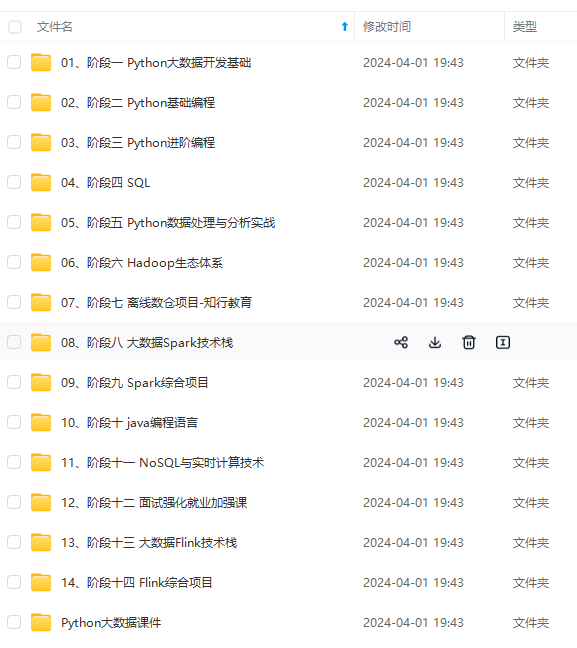
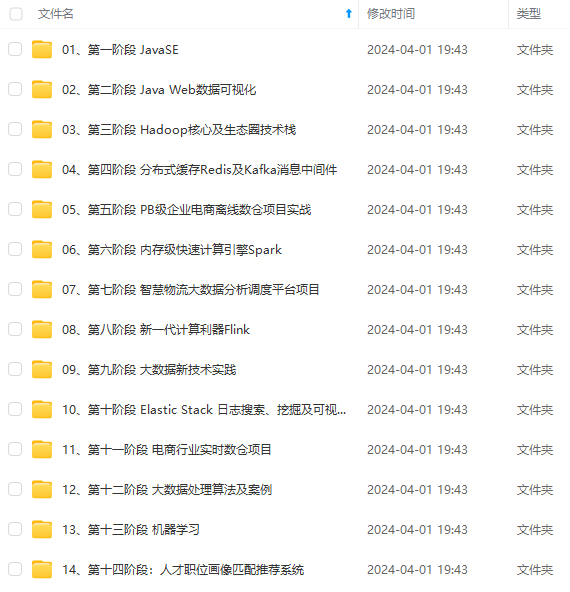
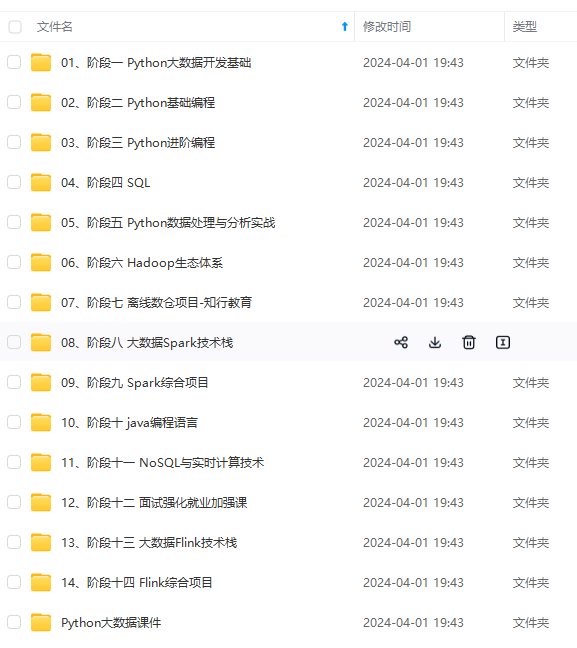
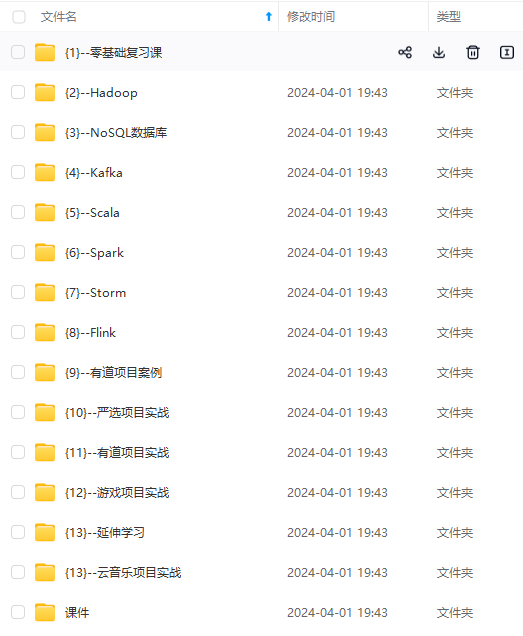
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









