







目录
1.1 准备好虚拟机,换源,net-tools,vim 的安装编辑
3.6 使用浏览器访问 使用你虚拟机ip:8080 打开tomcat管理界面即成功编辑
5.2. 在服务器根目录下创建images用于保存图片编辑
5.3. 打开资料目录中 oapro.war ,确认 oapro.war\WEB-INF\classes\ 目录下的jdbc.properties 文件中
5.5.将第3步修改好的oapro.war 上传至 tomcat安装目录下的 webapps 目录下编辑
systemctl start tomcat.service
服务器ip:8080/oapro, 用户: admin 密码:123编辑
一. 部署环境配置
1.1 准备好虚拟机,换源,net-tools,vim 的安装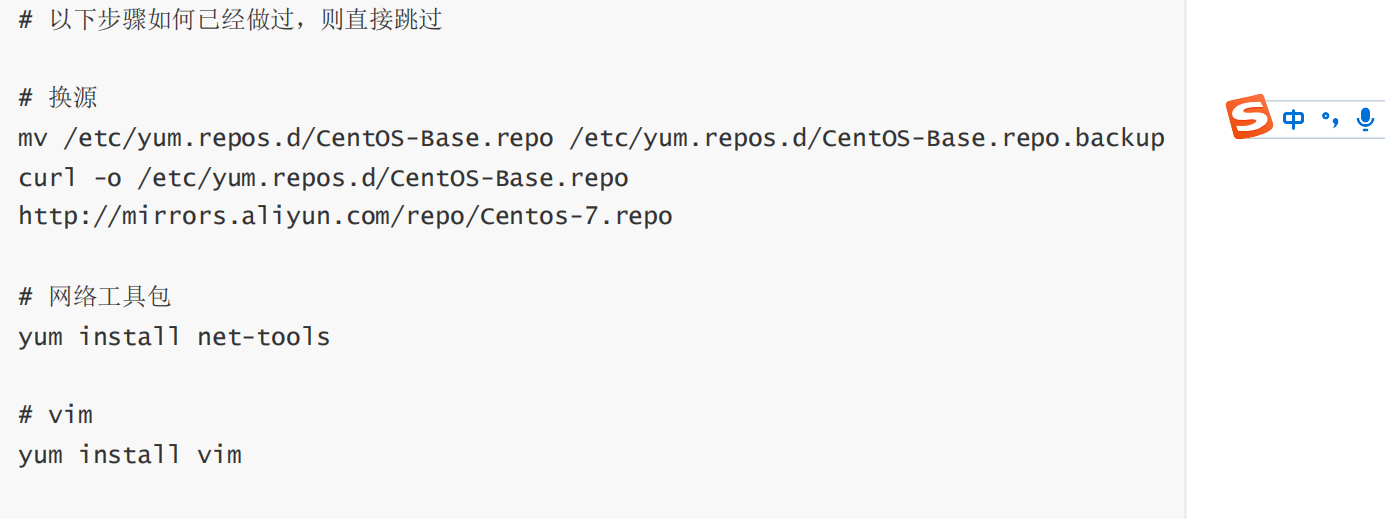
1.2 将需要的软件上传到服务器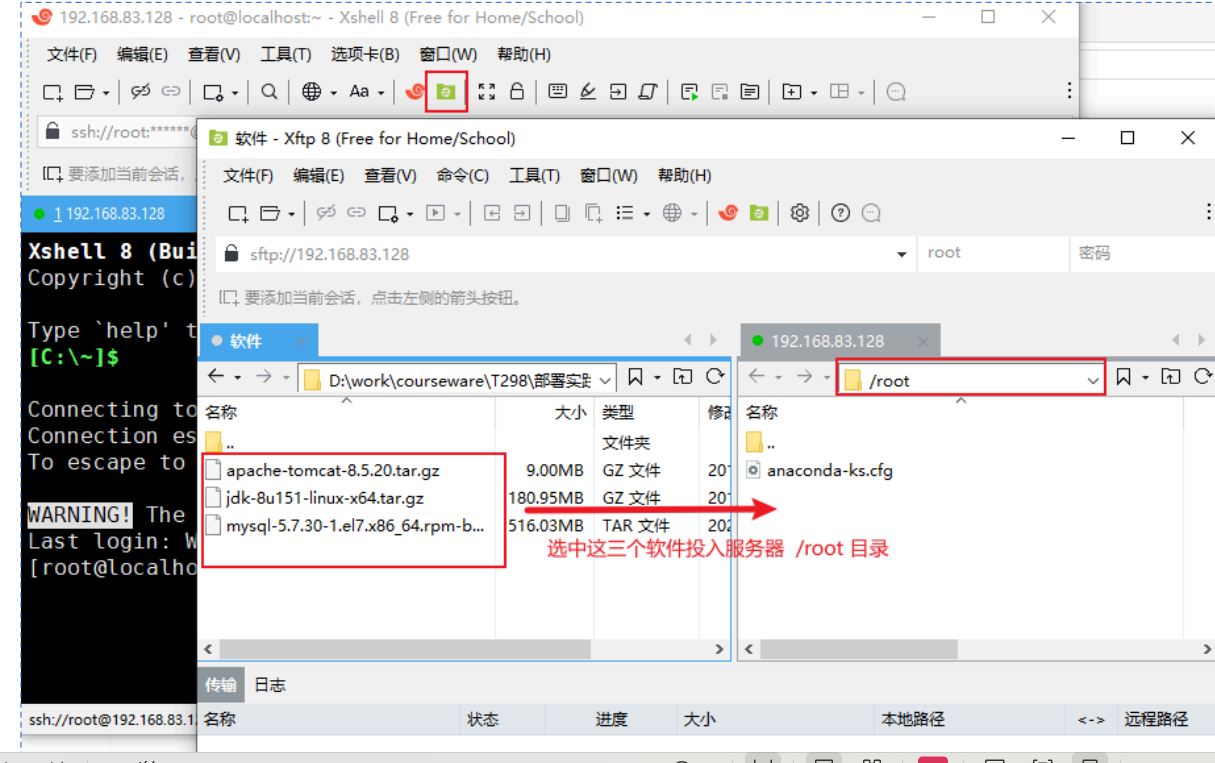
二.安装JDK
2.1 安装配置jdk环境
#
在
/usr/local
下创建
java
目录
mkdir/usr/local/java
#
进入
root
cd/root

2.2 将jdk解压到/usr/local/java目录:
tar-zxf jdk-8u151-linux-x64.tar.gz-C/usr/local/java
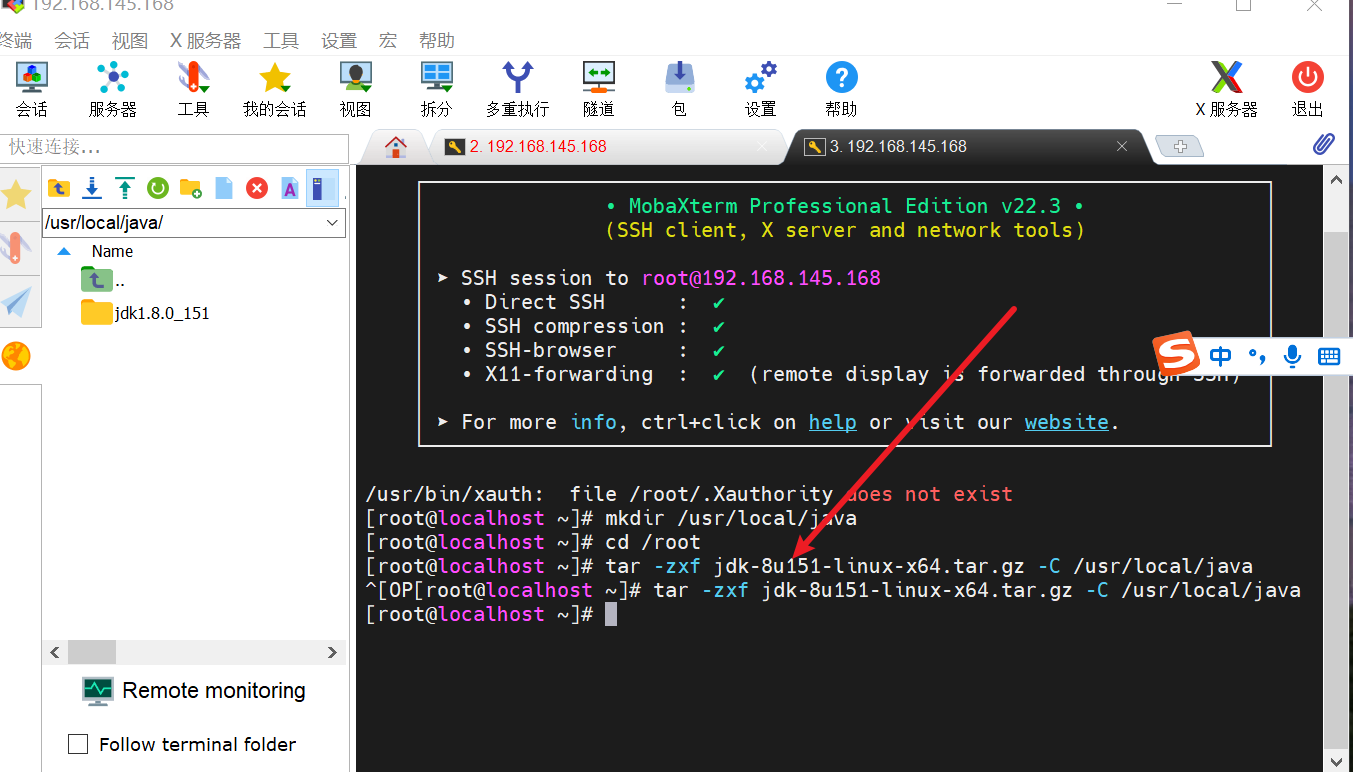
2.3 编辑环境变量配置文件
vim /etc/profile
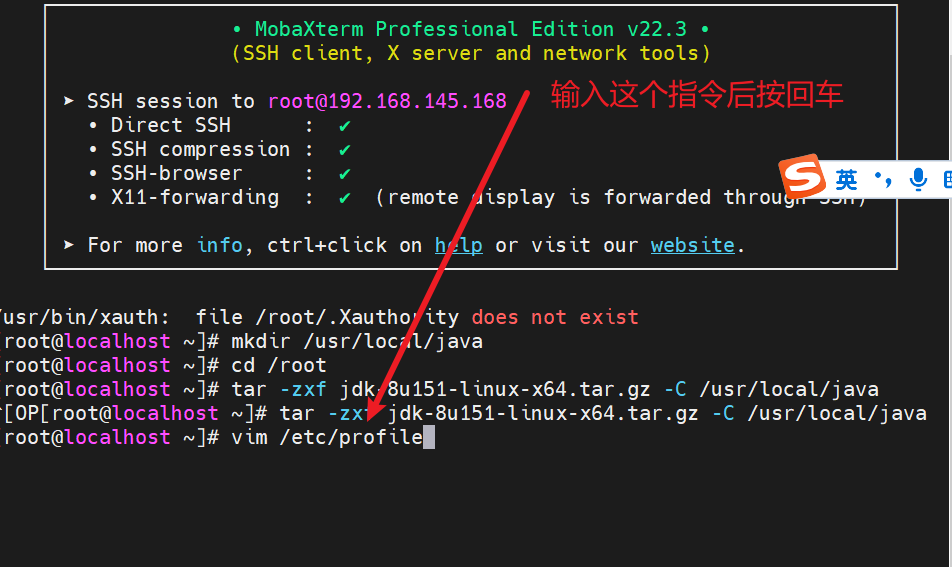
2.4 按i插入变量,在最后加入java的环境变量配置
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
export PATH=$PATH:${JAVA_HOME}/bin
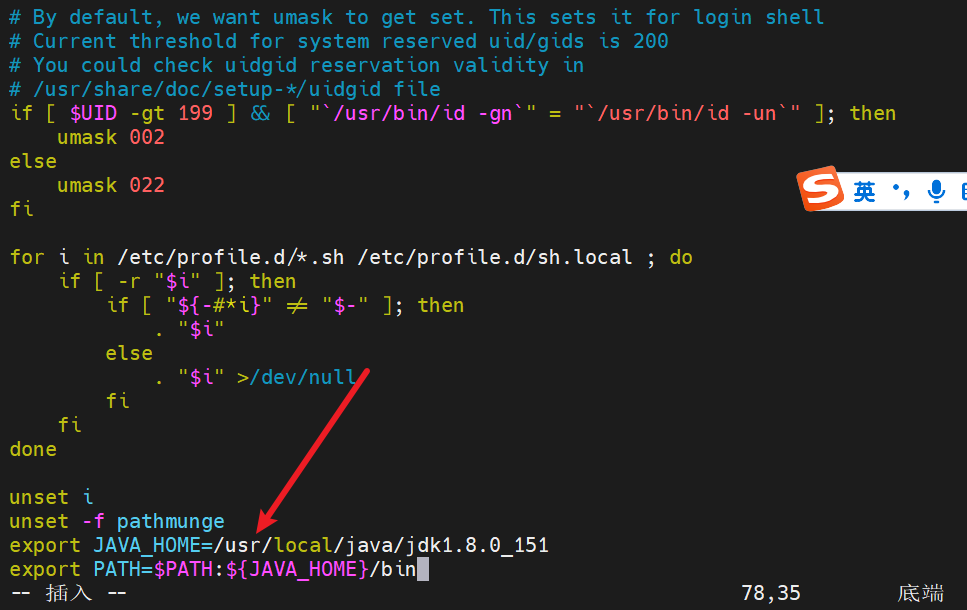
2.5 按wq保存
环境变量配置文件保存成功后,让新设置的环境变量生效
source /etc/profile

测试
jdk
,正常显示
java
的版本号即可
java -version

三.安装配置tomcat环境
3.1 进入root目录
cd /root
3.2 将tomcat解压到/opt下
tar -zxf apache-tomcat-8.5.20.tar.gz -C /opt

3.3 配置tomcat环境变量
export TOMCAT_HOME=/opt/apache-tomcat-8.5.20
环境变量配置文件保存成功后,让新设置的环境变量生效
source /etc/profile

#3.4 配置防火墙规则
firewall-cmd --zone=public --add-port=8080/tcp --permanent
firewall-cmd --reload

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3684
3684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









