







 本文详细介绍了如何在GlusterFS环境中创建和管理各种类型的卷(如分布式、条带、复制等),包括卷的创建过程、Brick的配置以及客户端的挂载和测试。此外,还涉及到了集群设置、节点添加和故障恢复等内容。
本文详细介绍了如何在GlusterFS环境中创建和管理各种类型的卷(如分布式、条带、复制等),包括卷的创建过程、Brick的配置以及客户端的挂载和测试。此外,还涉及到了集群设置、节点添加和故障恢复等内容。
4)具备冗余性
创建复制卷
创建名为rep-volume的复制卷,文件将同时存储两个副本,分别在Server1 :/dir1和Server2:/dir2两个Brick中
(4)分布式条带卷
1)兼顾分布式卷和条带卷的功能
2)主要用于大文件访问处理
3)至少最少需要4台服务器(5)分布式复制卷
1)兼顾分布式卷和复制卷的功能
2)用于需要冗余的情况
3)创建分布式复制卷
4)创建名为dis-rep的分布式条带卷,配置分布式复制卷时,卷中Brick所包含的存储服务器数必须是条带数的倍数(>=2倍)条带卷(默认):类似RAID0,文件被分成数据块并以轮询的方式分布到多个BrickServier上,文件存储以数据块为单位,支持大文件存储,文件越大,读取效率越高。
复制卷(Replica volume) :将文件同步到多个Brick上,使其具备多个文件副本, 属于文件级RAID
具有容错能力。因为数据分散在多个Brick 中,所以读性能得到很大提升,但写性能下降。分布式条带卷(Distribute Stripe volume) : Brick Server 数量是条带数(数据块分布的Brick
数量)的倍数,兼具分布式卷和条带卷的特点。分布式复制卷(Distribute Replica volume) : Brick Server数量是镜像数(数据副本
数量)的倍数,兼具分布式卷和复制卷的特点。条带复制卷(stripe Replica volume) :类似RAID 10,同时具有条带卷和复制卷的特点。
分布式条带复制卷(Distribute Stripe Replicavolume) :三种基本卷的复合卷,通常用于类Map Reduce 应用。
二、GlusterFS 集群
Node1节点: node1/192.168.22.126
磁盘 挂载点 /dev/sdb1 /data/sdb1 /dev/sdc1 /data/sdc1 /dev/sdd1 /data/sdd1 /dev/sde1 /data/sde1
Node2节点: node2/192.168.22.168
磁盘 挂载点 /dev/sdb1 /data/sdb1 /dev/sdc1 /data/sdc1 /dev/sdd1 /data/sdd1 /dev/sde1 /data/sde1
Node3节点: node1/192.168.22.196
磁盘 挂载点 /dev/sdb1 /data/sdb1 /dev/sdc1 /data/sdc1 /dev/sdd1 /data/sdd1 /dev/sde1 /data/sde1
Node4节点: node1/192.168.22.206
磁盘 挂载点 /dev/sdb1 /data/sdb1 /dev/sdc1 /data/sdc1 /dev/sdd1 /data/sdd1 /dev/sde1 /data/sde1
客户端节点: 192.168.22.186
1.准备环境(所有node节点上操作)
(1)关闭防火墙
systemctl stop firewalld systemctl disable firewalld setenforce 0(2)磁盘分区,并挂载
vim /opt/fdisk.sh #! /bin/bash echo "the disks exist list:" fdisk -l |grep '磁盘 /dev/sd[a-z]' echo "==================================================" PS3="chose which disk you want to create:" select VAR in `ls /dev/sd*|grep -o 'sd[b-z]'|uniq` quit do case $VAR in sda) fdisk -l /dev/sda break ;; sd[b-z]) echo "n p w" | fdisk /dev/$VAR #make filesystem mkfs.xfs -i size=512 /dev/${VAR}"1" &> /dev/null #mount the system mkdir -p /data/${VAR}"1" &> /dev/null echo -e "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0\n" >> /etc/fstab mount -a &> /dev/null break ;; quit) break;; *) echo "wrong disk,please check again";; esac donechmod +x /opt/fdisk.sh cd /opt/ ./fdisk.sh 使用df-hT确认是否全部分区挂载完成(3)配置/etc/hosts文件
以Node1节点为例:
echo "192.168.22.126 node01" >> /etc/hosts echo "192.168.22.168 node02" >> /etc/hosts echo "192.168.22.196 node03" >> /etc/hosts echo "192.168.22.206 node04" >> /etc/hosts

2.安装、启动GlusterFS。(所有node节点上操作)
cd /etc/yum.repos.d/ mkdir repo.bak mv *.repo repo.bak unzip gfsrepo.gzip vim glfs.repo [glfs] name=glfs baseurl=file:///opt/gfsrepeo gpgcheck=0 enabled=1 yum clean all && yum makecache yum -y install centos-release-gluster 如采用官方yum 源安装,可以直接指向互联网仓库 yum -y install glusterfs-server glusterfs-rdma glusterfs glusterfs-fuse systemctl start glusterd.service systemctl enable glusterd.service systemctl status glusterd.service安装时出现以下错误,现在装的rpm版本比repo源里的版本高。先查询后,找到名字在卸载
先安装glusterfs-server glusterfs-rdma


添加DNS,进行时间同步
ntpdate ntp1.aliyun.com
3.添加节点到存储信任池中(在node1 节点上操作)
只要在一台Node节点上添加其它节点即可
gluster peer probe node01 gluster peer probe node02 gluster peer probe node03 gluster peer probe node04
在每个Node节点上查看群集状态
gluster peer status
4.创建卷
根据规划创建
卷名称 卷类型 Brick dis-volume 分布式卷 node1 (/data/sdb1)、node2 (/data/ sdb1) stripe-volume 条带卷 node1 (/data/sdc1)、node2 (/data/ sdc1) rep-volume 复制卷 node3 (/data/sdb1)、node4 (/data/ sdb1) dis-stripe 分布式条带卷 node1 (/data/sdd1)、node2 (/data/sdd1)、 node3 (/data/sdd1)、node4 (/data/sdd1) dis-rep 分布式复制卷 node1 (/data/sde1)、node2 (/data/sde1)、node3(/data/sde1)、 node4 (/data/sde1) (1)创建分布式卷
1)创建分布式卷,没有指定类型,默认创建的是分布式卷
gluster volume create dis-volume node1: /data/sdb1 node2:/data/sdb1 force2)查看卷列表
gluster volume list3)启动新建分布式卷
gluster volume start dis-volume4)查看创建分布式卷信息
gluster volume info dis-volume
(2)创建条带卷
指定类型为stripe,数值为2,且后面跟了2个Brick Server, 所以创建的是条带卷。
gluster volume create stripe-volume stripe 2 node01:/data/sdc1 node02:/data/sdc1 force gluster volume start stripe-volume gluster volume info stripe-volume
(3) 创建复制卷
指定类型为replica, 数值为2,且后面跟了2个Brick Server, 所以创建的是复制卷。
gluster volume create rep-volume replica 2 node03:/data/sdb1 node04:/data/sdb1 force gluster volume start rep-volume gluster volume info rep-volume
(4)创建分布式条带卷
指定类型为stripe, 数值为2,而且后面跟了4个Brick Server,是2的两倍,所以创建的是分布式条带卷。
gluster volume create dis-stripe stripe 2 node01:/data/sdd1 node02:/data/sdd1 node03: /data/sdd1 node04:/data/sdd1 force gluster volume start dis-stripel gluster volume info dis-stripe
(5)创建分布式复制卷
指定类型为replica, 数值为2,而且后面跟了4个Brick Server, 是2的两倍,所以创建的是分布式复制卷。
gluster volume create dis-rep replica 2 node01:/data/sde1 node02:/data/sde1 node03:/data/sde1 node04:/data/sde1 force gluster volume start dis-rep gluster volume info dis-rep gluster volume list
5.Gluster客户端
(1)安装客户端软件
cd /etc/yum.repos.d/ mkdir repo.bak mv *.repo repo.bak vim glfs.repo [glfs] name=glfs baseurl=file:/L Lopt /gfsrepe : gpgcheck=0 enabled=1 yum clean all && yum makecache yum -y install glusterfs-fuse glusterfs
(2)创建挂载目录
mkdir -p /test/{dis,stripe,rep,dis_stripe,dis_rep} ls /test
(3)配置/etc/hosts 文件
echo "192.168.22.126 node01" >> /etc/hosts echo "192.168.22.168 node02" >> /etc/hosts echo "192.168.22.196 node03" >> /etc/hosts echo "192.168.22.206 node04" >> /etc/hosts
(4)挂载Gluster 文件系统
1)临时挂载
mount.glusterfs node01:dis-volume /test/dis mount.glusterfs node01:stripe-volume /test/stripe mount.glusterfs node01:rep-volume /test/rep mount.glusterfs node01:dis-stripe /test/dis_stripe mount.glusterfs node01:dis-rep /test/dis_rep df -Th2)永久挂载
vim /etc/ fstab node01:dis-volume /test/dis glusterfs defaults,_netdev 0 0 node01:stripe-volume /test/stripe glusterfs defaults,_netdev 0 0 node01:rep-volune /test/rep glusterfs defaults,_netdev 0 0 node01:dis-stripe /test/dis_stripe glusterfs defaults,_netdev 0 0 node01:dis-rep /test/dis_rep glusterfs defaults,_netdev 0 0
6.测试Gluster 文件系统
(1)卷中写入文件,客户端操作
cd /opt dd if=/dev/zero of=/opt/demo1.log bs=1M count=20 dd if=/dev/zero of=/opt/demo2.log bs=1M count=20 dd if=/dev/zero of=/opt/demo3.log bs=1M count=20 dd if=/dev/zero of=/opt/demo4.log bs=1M count=20 dd if=/dev/zero of=/opt/demo5.log bs=1M count=20 ls -1h /opt cp demo* /test/dis cp demo* /test/stripe/ cp demo* /test/rep/ cp demo* /test/dis_stripe/ cp demo* /test/dis_rep/
(2)查看文件分布
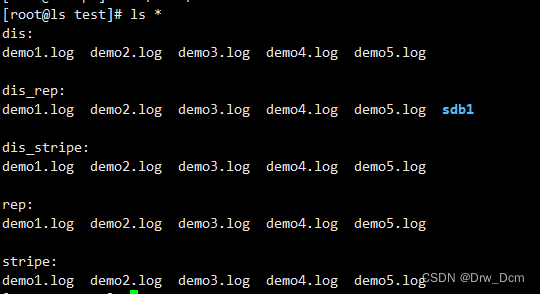
查看分布式文件分布
ls -lh /data/sdb1 数据没有被分片 ll -h /data/sdb1
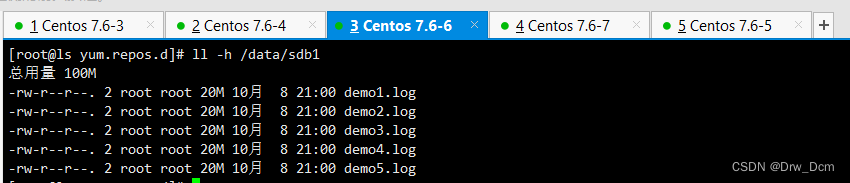
查看条带卷文件分布
ls -lh /data/sdc1 数据被分片50%没副本没冗余 ll -h /data/sdc1 数据被分片50%没副本没冗余
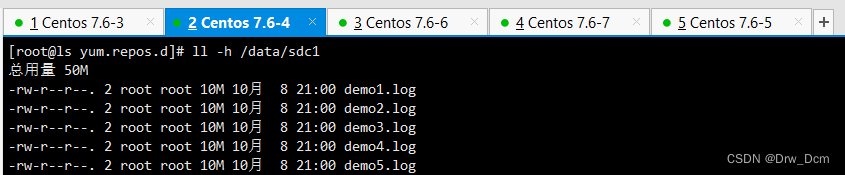
查看复制卷分布
ll -h /data/sdb1 数据没有被分片有副本有冗余 ll -h /data/sdb1 数据没有被分片有副本有冗余
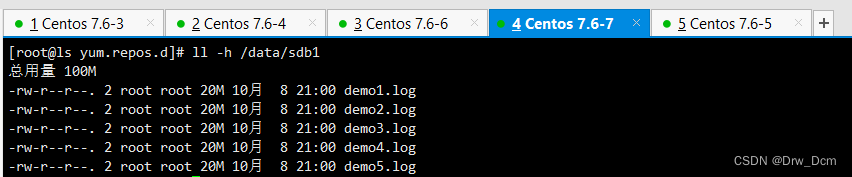
查看分布式条带卷分布
ll -h /data/sdd1 数据被分片50%没副本没冗余 ll -h /data/sdd1 ll -h /data/sdd1 ll -h /data/sdd1
查看分布式复制卷分布
数据没有被分片有副本有冗余
























































网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
a/sdd1 数据被分片50%没副本没冗余
ll -h /data/sdd1
ll -h /data/sdd1
ll -h /data/sdd1    查看分布式复制卷分布 数据没有被分片有副本有冗余
[外链图片转存中…(img-fFQYUtsb-1714404950905)]
[外链图片转存中…(img-XoxtFaC9-1714404950905)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









