







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
<value>org.apache.spark.network.shuffle.RemoteBlockPushResolver</value>
### 客户端配置
spark-defaults.conf
spark.shuffle.push.enabled true
spark.master yarn
spark.shuffle.service.enabled true
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.io.encryption.enabled false
关闭 adaptive 执行,此项不是必须的,仅在测试中不自动调整下游任务的并发度。
spark.sql.adaptive.enabled false
### 执行流程
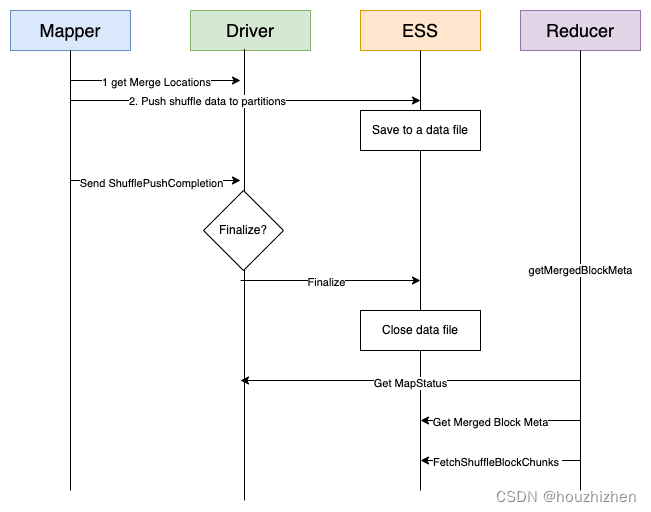
#### 1.Get Merger Locations
因为同一个shuffle partition 的数据要放到同一个 ESS。ESS 要把收到的多个 mapper 的同一个 shuffle partition 的数据进行合并, Merger Location 就是进行合并的这些 ESS 的地址。
整个 Stage 的所有 Map Task 拿到的是相同的 merge locations。
计算逻辑:
如果正在运行 Executor 的 host 的数量大于需要的 locations 的数量,则直接返回正在运行执行器的 host 列表。
如果不够的话,加上第 2 部分。第2部分从所有运行过执行器的 host 中查找,去除第 1 部分中重叠的 host,并且去除加入黑名单的host。第 2 部分的 host 是开启 Dynamic Allocation 后,在这些 host 上启动过 Executor, 并且 Executor 没有任务正常退出。
触发时机:
第 1 版是在 Stage 启动的时候计算,发现开启 Dynamic Allocation 后,开始运行的 Executor 是 initialExecutors。造成大任务的 shuffle 数据被 push 到少数的 ESS 上。
第 2 版是 Mapper 把 shuffle 数据写到本地磁盘后,再调用 get merger locations。比第 1 版好一些。
问题: merger location 是现在运行的 executor 地址。如 application 刚开始运行时队列资源紧张,第 1 个 mapper 处理完时,getMergerLocation 时,申请到的 executor 不多,但是任务很大,后续可能申请到更多 executor。就会出现把 shuffle 数据 push 到少数 ess 上, 照成 shuffle 数据倾斜。
是否可能用所有的 ESS 地址参加 get merger locations 的计算?这样就不会有 shuffle 数据倾斜的问题。难点:如果一个 node 上没有运行 application 的 executor,就不会向 ess 注册 appl 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2668
2668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









