






poi获取与解译提取所需数据声明:自用复盘,非教程,无商用
1、所需信息的检索
开发者频道→开发文档→需要爬取的内容(地点检索)
2、key的获取(对于自己的电脑)
控制台→应用管理→我的应用→创建应用
应用浏览器端:白名单可写为‘localhost’
应用服务器端:1、注意:白名单使用本机ip地址时(win+R→cmd→输入命令ipconfig→IPV4即本机ip地址)获取poi为空
2、使用0.0.0.0/0则正常

3、api的获取与补充
选择需要的内容(圆形区域检索,可根据半径控制数据量,社媒数据同理,但需要根据时间跨度控制量)→获取api→根据请求参数修改api
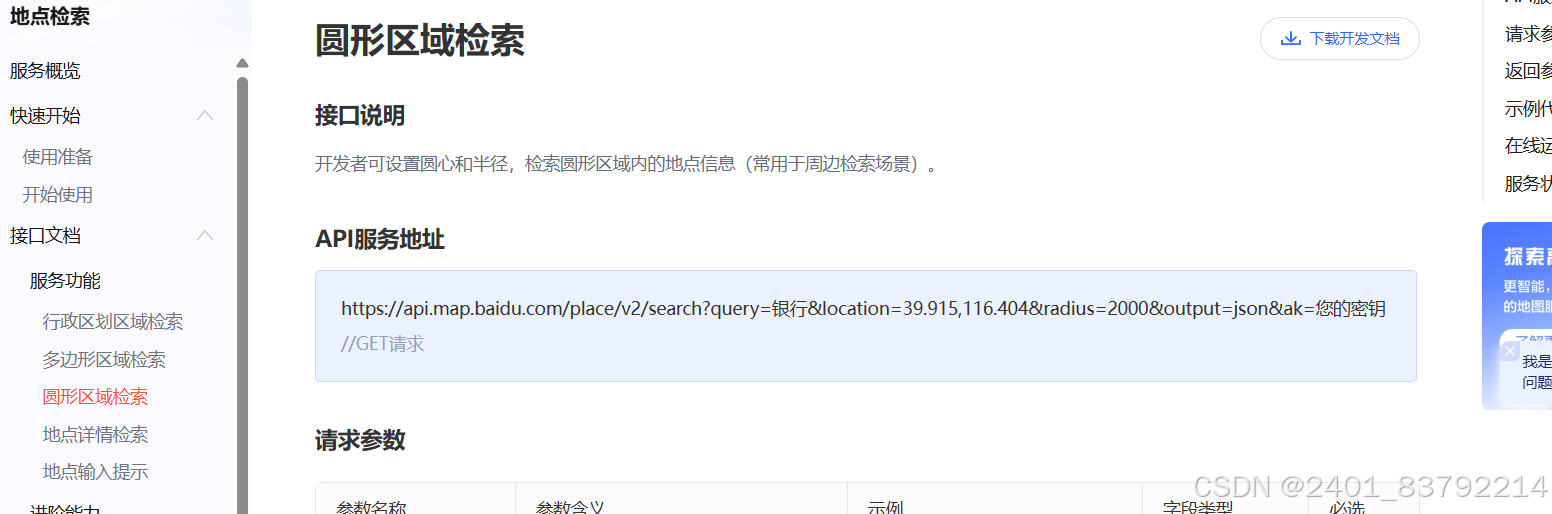
由于需要加快效率,因此此处修改了
4.poi获取与解译提取所需数据
点击更改后的markdown,跳出网站显示信息

导入requests包,使用get()进行获取,由于已经在url定义了output为json格式,所以再使用json(),之后使用对字典可使用的方法获取自己需要的部分数据(并进行循环)
以下是第0页,一页最大容纳20条所以len为20,如果要获取全部95条数据,需要更改url的page_num来循环4.poi获取与解译提取所需数据
import requests
url=
r=requests.get(url)
json_obj=r.json()
# 为了防止出现total=0的情况,及什么都没有采集到,需要规避
if json_obj['message']=='ok':
#当你可以全部爬取时,会有‘total’信息
if json_obj['total']!=0:
for i in json_obj['results']:
"""i:字典"""
j={}
j['name']=i['name']
j['lng']=i['location']['lng']
j['lat']=i['location']['lat']
j['address']=i['address']
print(j)
else:print('没有数据')
else:print('出问题了')5.url的循环
此处用到了'{}'.format(),注意与f'{}'区别于联系
\n:使对象表现为换行,\:使代码在编写时可以换行
urls=[]
for m in range(0,8):
url='https://api.map.baidu.com/place/v2/search?query=银行&location=39.915,116.404&radius=2000&output=json&ak=3OJisows4IoSHLKUVBcwejb1HEUkgGNr&page_size=20&page_num={}'.\
format(m)
break
urls.append(url)6.以上代码组合并优化
在信息获取长度为0时,url可以停止,则可以停止循环
import requests
urls=[]
j={}
list_items=[]
for m in range(0,8):
#自己添加
url='xxxxxx&page_size=20&page_num={}'.\
format(m)
urls.append(url)
for url in urls:
json_obj=requests.get(url).json()
if json_obj['message']=='ok':
if len(json_obj['results'])!=0:
for i in json_obj['results']:
"""i:字典"""
j['name']=i['name']
j['lng']=i['location']['lng']
j['lat']=i['location']['lat']
j['address']=i['address']
list_items.append(j)
else:
print('本页及以后没有数据')
break
else:
print('出问题了')7.封装为函数。

















 1305
1305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









