







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
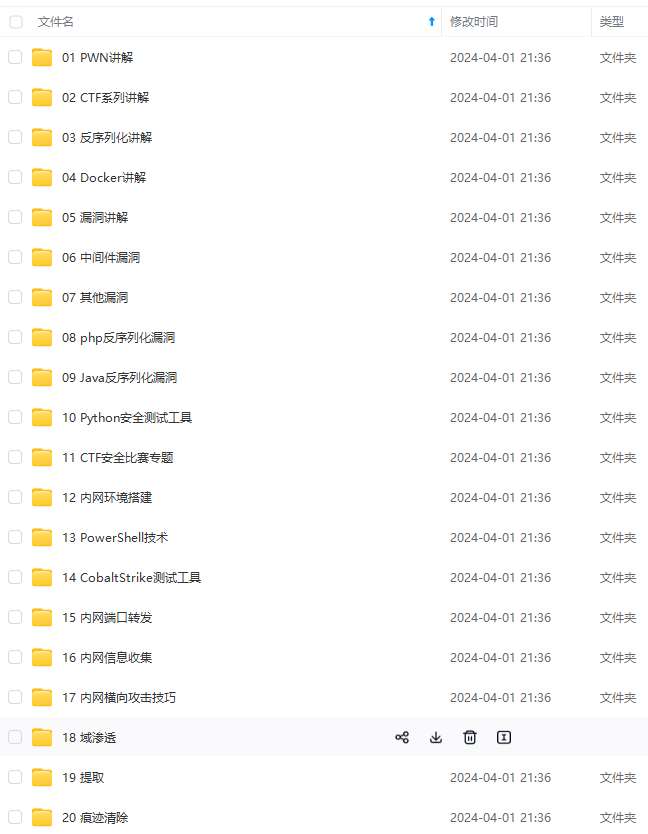
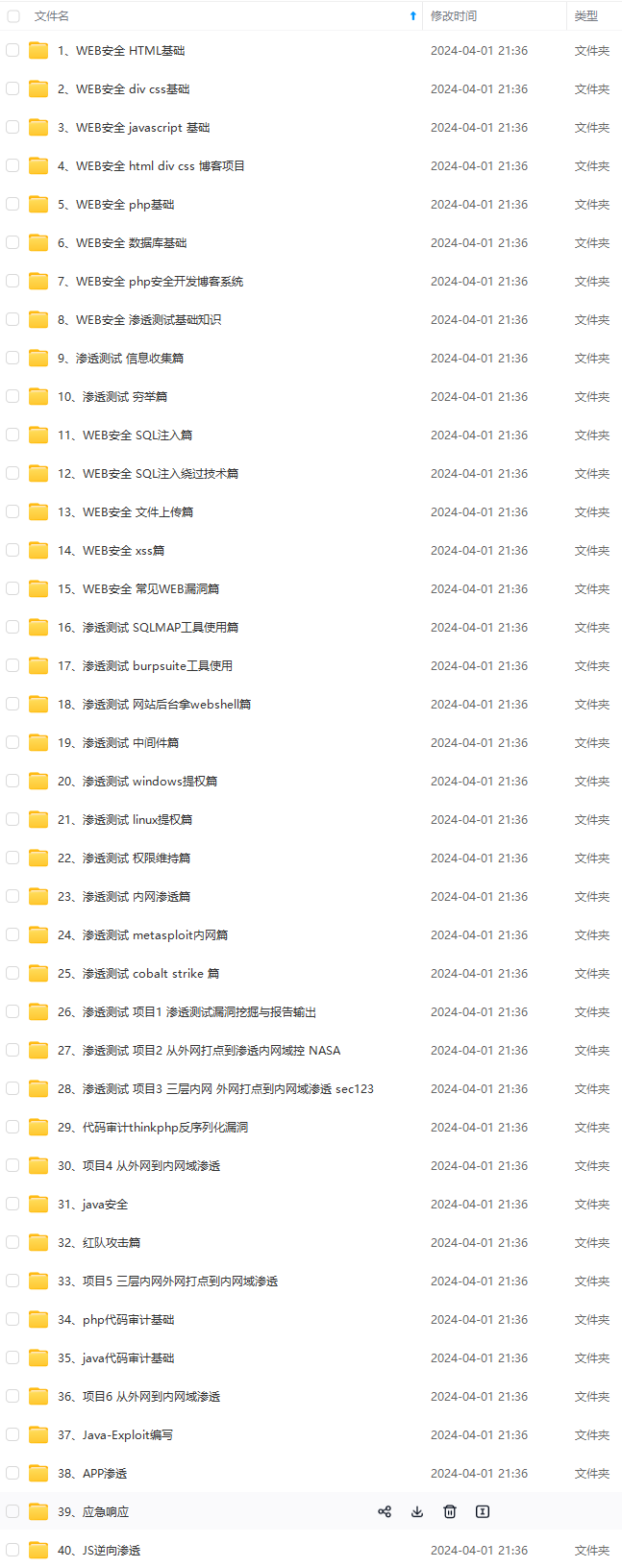
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注网络安全)

正文

老三睡到上三杆,窗口排队都爆满。
经理一看开新口,排队同志赶紧办。

这天业务太火爆,柜台排队都用完。
老三一看急上火,经理你说怎么办。

经理挥手一笑间,这种场面已见惯。四种办法来处理,你猜我会怎么办。
- 小小银行不堪负,陈旧系统已瘫痪。
- 我们庙小对不起,谁叫你来找谁办。
- 看你情况特别急,来去队里加个塞。
- 今天实在没办法,不行你看改一天。

对,没错,其实这个流程就和JDK线程池ThreadPoolExecutor的工作流程类似,先卖个关子,后面结合线程池工作流程,保证你会豁然开朗。
实战:线程池管理数据处理线程
光说不练假把式,show you code,我们来一个结合业务场景的线程池实战。——很多同学面试的时候,线程池原理背的滚瓜烂熟,一问项目中怎么用的,歇菜。看完这个例子,赶紧琢磨琢磨,项目里有什么地方能套用的。
应用场景
应用场景非常简单,我们的项目是一个审核类的系统,每年到了核算的时候,需要向第三方的核算系统提供数据,以供核算。
这里存在一个问题,由于历史原因,核算系统提供的接口只支持单条推送,但是实际的数据量是三十万条,如果一条条推送,那么起码得一个星期。
所以就考虑使用多线程的方式来推送数据,那么,线程通过什么管理呢?线程池。
为什么要用线程池管理线程呢?当然是为了线程复用。

思路也很简单,开启若干个线程,每个线程从数据库中读取取(start,count]区间未推送的数据进行推送。

具体代码实现
我把这个场景提取了出来,主要代码:

代码比较长,所以用了carbon美化,代码看不清,没关系,可运行的代码我都上传到了远程仓库,仓库地址:https://gitee.com/fighter3/thread-demo.git ,这个例子比较简单,没有用过线程池的同学可以考虑你有没有什么数据处理、清洗的场景可以套用,不妨借鉴、演绎一下。
本文主题是线程池,所以我们重点关注线程池的代码:
线程池构造
//核心线程数:设置为操作系统CPU数乘以2
private static final Integer CORE_POOL_SIZE = Runtime.getRuntime().availableProcessors() \* 2;
//最大线程数:设置为和核心线程数相同
private static final Integer MAXIMUM\_POOl\_SIZE = CORE_POOL_SIZE;
//创建线程池
ThreadPoolExecutor pool = new ThreadPoolExecutor(CORE_POOL_SIZE, MAXIMUM\_POOl\_SIZE \* 2, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>(100));
线程池直接采用ThreadPoolExecutor构造:
- 核心线程数设置为CPU数×2
- 因为需要分段数据,所以最大线程数设置为和核心线程数一样
- 阻塞队列使用
LinkedBlockingQueue - 拒绝策略使用默认
线程池提交任务
//提交线程,用数据起始位置标识线程
Future<Integer> future = pool.submit(new PushDataTask(start, LIMIT, start));
- 因为需要返回值,所以使用
submit()提交任务,如果使用execute()提交任务,没有返回值。
代码不负责,可以done下来跑一跑。
那么,线程池具体是怎么工作的呢?我们接着往下看。
原理:线程池实现原理
线程池工作流程
构造方法
我们在构造线程池的时候,使用了ThreadPoolExecutor的构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
先来看看几个参数的含义:
corePoolSize: 核心线程数maximumPoolSize:允许的最大线程数(核心线程数+非核心线程数)workQueue:线程池任务队列
用来保存等待执行的任务的阻塞队列,常见阻塞队列有:
+ `ArrayBlockingQueue`:一个基于数组结构的有界阻塞队列
+ `LinkedBlockingQueue`:基于链表结构的阻塞队列
+ `SynchronousQueue`:不存储元素的阻塞队列
+ `PriorityBlockingQueue`:具有优先级的无限阻塞队列
handler: 线程池饱和拒绝策略
JDK线程池框架提供了四种策略:
+ `AbortPolicy`:直接抛出异常,默认策略。
+ `CallerRunsPolicy`:用调用者所在线程来运行任务。
+ `DiscardOldestPolicy`:丢弃任务队列里最老的任务
+ `DiscardPolicy`:不处理,丢弃当前任务也可以根据自己的应用场景,实现`RejectedExecutionHandler`接口来自定义策略。
上面四个是和线程池工作流程息息相关的参数,我们再来看看剩下三个参数。
keepAliveTime:非核心线程闲置下来最多存活的时间unit:线程池中非核心线程保持存活的时间threadFactory:创建一个新线程时使用的工厂,可以用来设定线程名等
线程池工作流程
知道了几个参数,那么这几个参数是怎么应用的呢?
以execute()方法提交任务为例,我们来看线程池的工作流程:

向线程池提交任务的时候:
- 如果当前运行的线程少于
核心线程数corePoolSize,则创建新线程来执行任务 - 如果运行的线程等于或多于
核心线程数corePoolSize,则将任务加入任务队列workQueue - 如果
任务队列workQueue已满,创建新的线程来处理任务 - 如果创建新线程使当前总线程数超过
最大线程数maximumPoolSize,任务将被拒绝,线程池拒绝策略handler执行
结合一下我们开头的生活事例,是不是就对上了:

线程池工作源码分析
上面的流程分析,让我们直观地了解了线程池的工作原理,我们再来通过源码看看细节。
提交线程(execute)
线程池执行任务的方法如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
//获取当前线程池的状态+线程个数变量的组合值
int c = ctl.get();
//1.如果正在运行线程数少于核心线程数
if (workerCountOf(c) < corePoolSize) {
//开启新线程运行
if (addWorker(command, true))
return;
c = ctl.get();
}
//2. 判断线程池是否处于运行状态,是则添加任务到阻塞队列
if (isRunning(c) && workQueue.offer(command)) {
//二次检查
int recheck = ctl.get();
//如果当前线程池不是运行状态,则从队列中移除任务,并执行拒绝策略
if (! isRunning(recheck) && remove(command))
reject(command);
//如若当前线程池为空,则添加一个新线程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//最后尝试添加线程,如若添加失败,执行拒绝策略
else if (!addWorker(command, false))
reject(command);
}
我们来看一下execute()的详细流程图:

新增线程 (addWorker)
在execute方法代码里,有个关键的方法private boolean addWorker(Runnable firstTask, boolean core),这个方法主要完成两部分工作:增加线程数、添加任务,并执行。
- 我们先来看第一部分增加线程数:
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 1.检查队列是否只在必要时为空(判断线程状态,且队列不为空)
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
//2.循环CAS增加线程个数
for (;;) {
int wc = workerCountOf(c);
//2.1 如果线程个数超限则返回 false
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//2.2 CAS方式增加线程个数,同时只有一个线程成功,成功跳出循环
if (compareAndIncrementWorkerCount(c))
break retry;
//2.3 CAS失败,看线程池状态是否变化,变化则跳到外层,尝试重新获取线程池状态,否则内层重新CAS
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
}
}
//3. 到这说明CAS成功了
boolean workerStarted = false;
boolean workerAdded = false;
- 接着来看第二部分添加任务,并执行
Worker w = null;
try {
//4.创建worker
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
//4.1、加独占锁 ,为了实现workers同步,因为可能多个线程调用了线程池的excute方法
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//4.2、重新检查线程池状态,以避免在获取锁前调用了shutdown接口
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
//4.3添加任务
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
//4.4、添加成功之后启动任务
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
我们来看一下整体的流程:

执行线程(runWorker)
用户线程提交到线程池之后,由Worker执行,Worker是线程池内部一个继承AQS、实现Runnable接口的自定义类,它是具体承载任务的对象。

先看一下它的构造方法:
Worker(Runnable firstTask) {
setState(-1); // 在调用runWorker之前禁止中断
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this); //创建一个线程
}
- 在构造函数内 首先设置 state=-1,现了简单不可重入独占锁,state=0表示锁未被获取状态,state=1表示锁已被获取状态,设置状态大小为-1,是为了避免线程在运行runWorker()方法之前被中断
- firstTask记录该工作线程的第一个任务
- thread是具体执行任务的线程
它的run方法直接调用runWorker,真正地执行线程就是在我们的runWorker 方法里:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // 允许中断
boolean completedAbruptly = true;
try {
//获取当前任务,从队列中获取任务
while (task != null || (task = getTask()) != null) {
w.lock();
…………
try {
//执行任务前做一些类似统计之类的事情
beforeExecute(wt, task);
Throwable thrown = null;
try {
//执行任务
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// 执行任务完毕后干一些些事情
afterExecute(task, thrown);
}
} finally {
task = null;
// 统计当前Worker 完成了多少个任务
w.completedTasks++;
w.unlock();
}
}
本人从事网路安全工作12年,曾在2个大厂工作过,安全服务、售后服务、售前、攻防比赛、安全讲师、销售经理等职位都做过,对这个行业了解比较全面。
最近遍览了各种网络安全类的文章,内容参差不齐,其中不伐有大佬倾力教学,也有各种不良机构浑水摸鱼,在收到几条私信,发现大家对一套完整的系统的网络安全从学习路线到学习资料,甚至是工具有着不小的需求。
最后,我将这部分内容融会贯通成了一套282G的网络安全资料包,所有类目条理清晰,知识点层层递进,需要的小伙伴可以点击下方小卡片领取哦!下面就开始进入正题,如何从一个萌新一步一步进入网络安全行业。
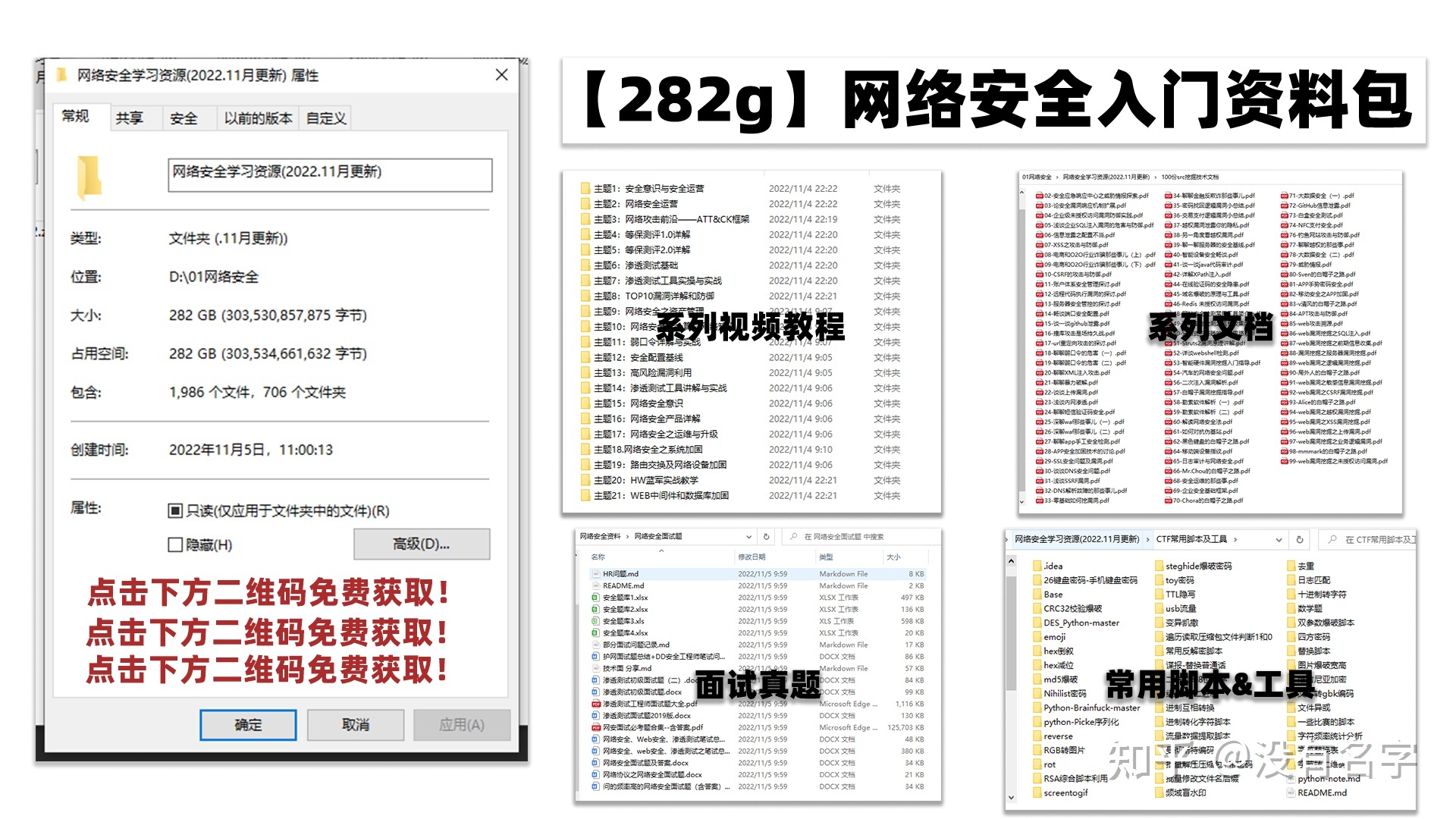
### 学习路线图
其中最为瞩目也是最为基础的就是网络安全学习路线图,这里我给大家分享一份打磨了3个月,已经更新到4.0版本的网络安全学习路线图。
相比起繁琐的文字,还是生动的视频教程更加适合零基础的同学们学习,这里也是整理了一份与上述学习路线一一对应的网络安全视频教程。
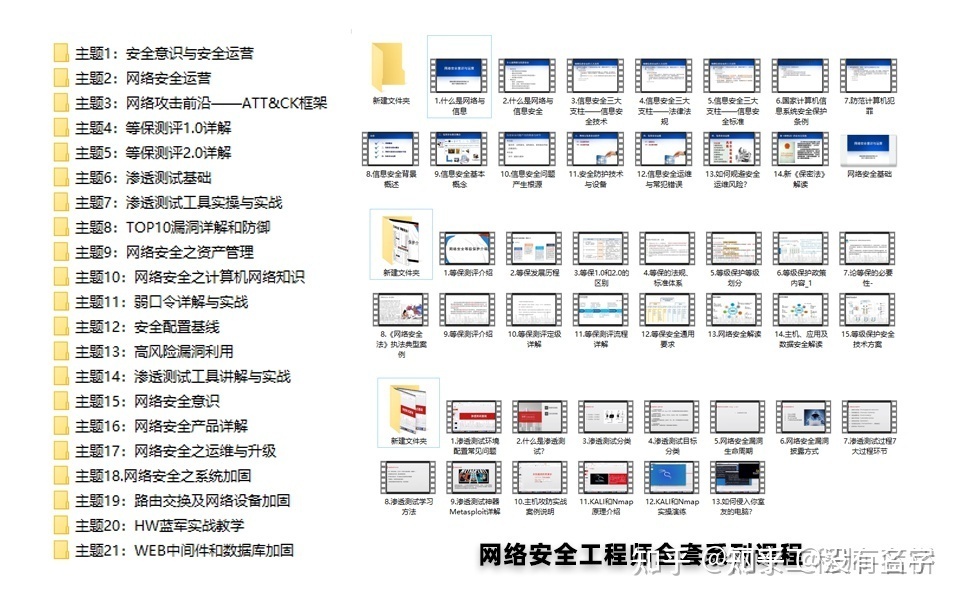
#### 网络安全工具箱
当然,当你入门之后,仅仅是视频教程已经不能满足你的需求了,你肯定需要学习各种工具的使用以及大量的实战项目,这里也分享一份**我自己整理的网络安全入门工具以及使用教程和实战。**
#### 项目实战
最后就是项目实战,这里带来的是**SRC资料&HW资料**,毕竟实战是检验真理的唯一标准嘛~

#### 面试题
归根结底,我们的最终目的都是为了就业,所以这份结合了多位朋友的亲身经验打磨的面试题合集你绝对不能错过!
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
996787388468bb227d8f959.jpeg)
#### 项目实战
最后就是项目实战,这里带来的是**SRC资料&HW资料**,毕竟实战是检验真理的唯一标准嘛~

#### 面试题
归根结底,我们的最终目的都是为了就业,所以这份结合了多位朋友的亲身经验打磨的面试题合集你绝对不能错过!
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)**
[外链图片转存中...(img-p42hFbFW-1713661074833)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**

















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









