






论文简介:
- 作者:
Huiqiang Xie
Zhijin Qin
Geoffrey Ye Li
Biing-Hwang Juang
- 发表期刊or会议:
《IEEE》
- 发表时间:
2021年
摘要:
本文主要提出了一个基于深度学习的语义通信系统,命名为DeepSC,用于文本传输。 基于Transformer, DeepSC旨在通过恢复句子的含义来最大化系统容量并最小化语义错误,而不是传统通信中的比特或符号错误。 此外,利用迁移学习确保DeepSC适用于不同的通信环境,并加快模型的训练过程。 为了准确地证明语义通信的性能,初始化了一个新的度量,称为句子相似度。 大量的仿真结果表明,与不考虑语义信息交换的传统通信系统相比,所提出的DeepSC对信道变化具有更强的鲁棒性,特别是在低信噪比(SNR)条件下能够获得更好的性能。
本文提出三个问题:
Question 1: How to define the meaning behind the bits?
Question 2: How to measure the semantic error ofsentences?
Question 3: How to jointly design the semantic and channel
coding?
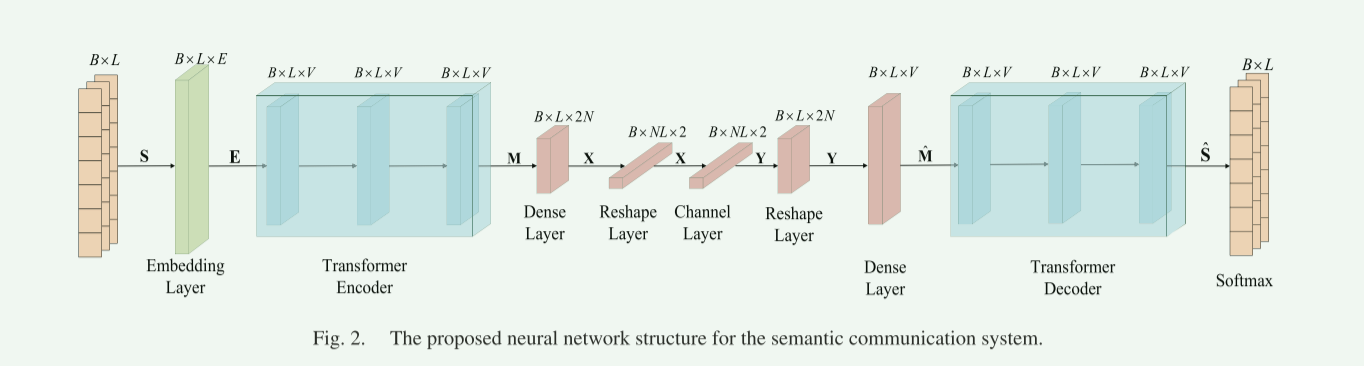
一、DeepSC通信系统模型
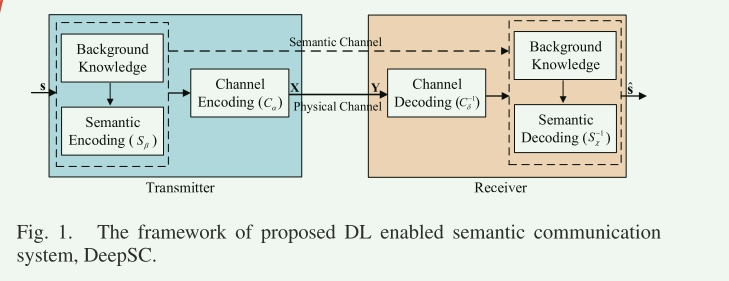
论文将系统模型分为语义层和传输层,语义层处理语义信息,进行编码和解码,提取语义信息。 传输层保证了语义信息在传输介质上的正确交换。(虚线框中为语义层,虚线框外为传输层)
首先文本信息S(假如是一个句子)经过语义层处理(经过Transformer)被分割为一个特征矩阵,再经过信道编码(转化为适合传输)表示为X
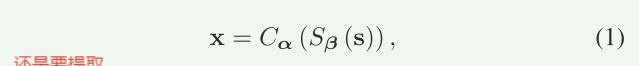
其中X为复数向量,维度为。
X经过物理信道传输,接收端接收的数据为:
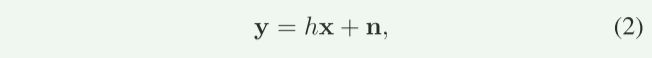
其中,论文指出,对于编码器和解码器的端到端训练,信道必须允许反向传播。(我理解就是可微)
然后经过信道解码和语义解码,恢复的信号可以表示为:(红色信道解码,蓝色语义解码)
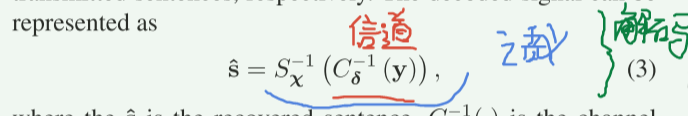
二、两个损失函数设计
本文设计系统模型的目的主要有两个:一个是最小化语义误差,一个是最大化信道容量。(个人理解是通过两个不同的损失函数完成的。也可以说三个,因为第三个是将前两个合并起来训练整个网络的)。
1、cross-entropy (CE)损失函数
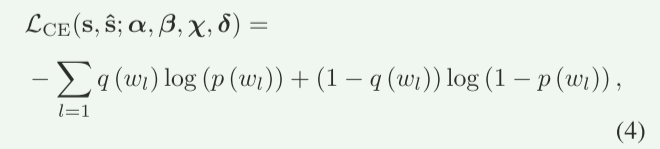
首先要先了解cross-entropy交叉熵的概念,详细可以参考这篇文章:交叉熵损失函数(Cross-Entropy Loss)。论文使用的是二元交叉熵函数,而非多类交叉熵函数。
CE损失通过惩罚L每个位置的错误词预测,迫使模型学习词与词之间的共现规律(如语法、短语搭配)。通过降低CE损失值网络可以学习信源S的实际概率,表明网络可以学习上下文中的语法,短语,单词的含义,同时共同设计和训练使信道编码可以更加注重保护与传输目标相关的语义信息,而忽略其他无关的信息。(个人理解就是这部分最小化了语义误差,通过比较预测和真实概率进行优化权重参数)
2、Mutual Information(MI)损失函数
首先,互信息 I(x;y) 的定义是发送符号x和接收符号y之间的统计依赖性。它衡量的是通过信道传输后,接收端能获取到多少关于发送符号的信息。根据信息论中的香农定理,信道的最大可靠传输速率(即信道容量)等于互信息的最大值.即C=max I(xy)。所以我们要最大化互信息值。
首先补充KL散度的知识:KL散度和交叉熵
论文给出,发送符号x和接收符号y的互信息可以通过: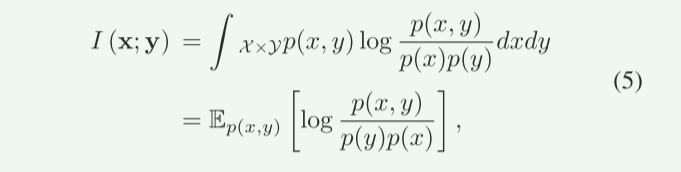
并且互信息可由联合分布和边缘分布乘积之间的KL散度表示: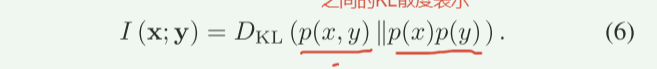
由N. Kalchbrenner, E. Grefenstette, and P. Blunsom, “Aconvolutional neural
network for modelling sentences,”这篇文献又知道:KL散度的对偶表示:
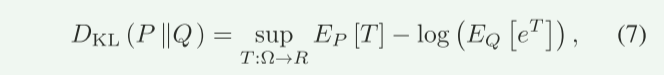
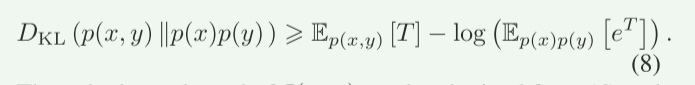
其中T可以用神经网络逼近。同时,(8)中的期望可以通过抽样计算得到,随着样本数量的增加,期望收敛于真实值。 然后,我们可以通过最大化式(8)中定义的互信息来优化编码器,其损失函数可以由式给出: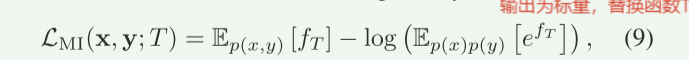
这一部分可能比较乱,用一张图汇总一下和一段解释说明应该就能理解。
说明:我们目的是最大化信道容量,又因为信道的最大可靠传输速率(即信道容量)等于互信息的最大值。所以现在要互信息最大值。因为互信息 I(X;Y)可以表示为联合分布 p(x,y) 与边缘分布乘积 p(x)p(y) 之间的KL散度公式(5)(6)。所以我们要优化KL散度。又因为KL散度的变分下界(对偶表示)可以写成公式(7)形式,其中KL散度是所有可能的函数 T 的上确界(最大值)。如果我们选择一个具体的函数 T,则公式(8),其中右边是KL散度的下界。在论文中,函数 T 被替换为一个神经网络 Tθ,输入为(x,y),输出为标量。通过优化Tθ,最大化下界(本质:通过优化神经网络 Tθ,逼近KL散度的真实值,从而逼近互信息的上界)作者通过最大化下界(即公式9的 LMI),间接优化信道编码器的符号分布p(x),从而逼近信道容量。(其中p(x) 是发送符号 X 的概率分布,决定了符号的生成方式(如符号的幅度、相位等统计特性)。)在深度学习中,p(x)通过信道编码器(神经网络)隐式定义。编码器将语义特征映射为符号 X,其分布p(x) 由网络参数决定。故达到最大化信道容量。

三、句子相似度
BER不能很好反映文本传输性能,所以需要BLEU,但BLEU只能比较两个句子中单词的差异,而不能比较它们的语义信息。文中指出关于BLEU,如果改变一个同义词,也会引起BLEU分数改变,没有考虑语义环境。其问题是如何使用数字向量来表达单词,而数字向量在不同的语境下是不同的。所以为弥补BLEU Score的不足,论文提出 句子相似度(Sentence Similarity) 作为新指标。具体使用预训练的BERT模型将句子映射为语义向量,计算余弦相似度:
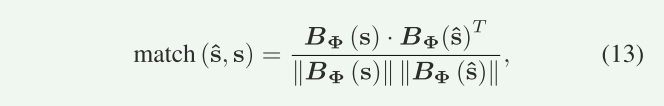
表示BERT模型,
为句子的语义向量。
四、DeepSC训练
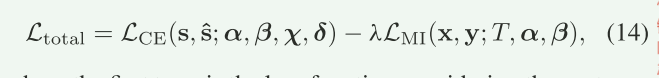

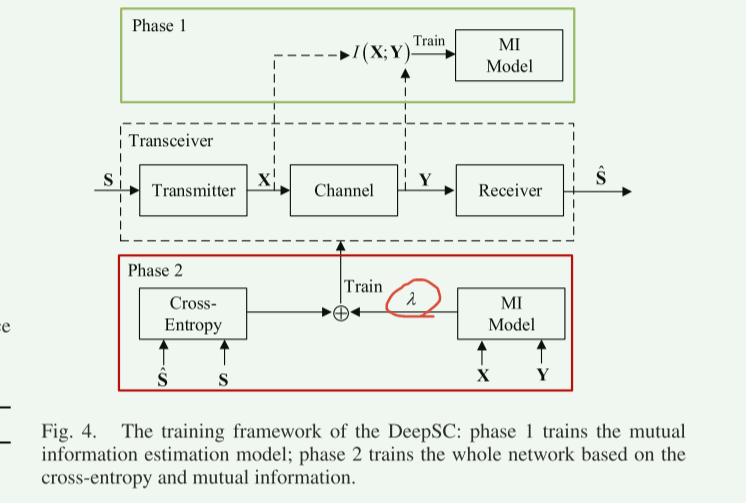
这部分主要讲了如何利用三个损失函数(4)(9)(14)去训练模型,没什么好讲的,可以自己看原文,放几张图可以看下。



















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









