










第二十九部分 Layer Diffusion
29.1 概述
Layer Diffusion是一种在图像生成过程中,通过分层处理不同部分以实现更细致和高质量图像生成的方法。该技术可以有效地减少生成图像中的瑕疵,并提高整体图像的细节表现力,也可以直接生成各类透明背景的PNG素材图。通过Layer Diffusion,我们就可以一定程度解决AI生图后需要大量的后期处理等工作内容。和一些智能抠图工具不同,它在生成时候就直接通过运算生成了透明背景的图片,所以它能将各类细节甚至是人物的毛发都能生成的细致分明。它可以只生成前景,也可以只生成背景,甚至可以背景和前景同时生成并分图层将画面组合在一起。
29.2 工作原理
Layer Diffusion通过将图像生成过程分解为多个层次,每个层次处理图像的一部分。这样可以对每个层次应用不同的生成策略,以确保最终图像的每个部分都能达到最佳效果。该过程包括以下步骤:
图像分层:将输入图像分解为多个层,每个层代表图像的不同部分或特征。
单层处理:对每个层分别应用生成模型,进行图像生成或增强处理。
层间融合:将处理后的各层重新组合,形成完整的高质量图像。
29.3 安装和部署
虽然Layer Diffusion理论上属于Stable Diffusion WebUI中的一个插件,但目前它还不能直接运行在Stable Diffusion WebUI中,而是需要安装在Stable Diffusion ForgeUI中,所以我们首先要下载和安装Stable Diffusion ForgeUI。
下载地址:
GitHub - lllyasviel/stable-diffusion-webui-forge
下载后解压缩即可,执行"run.bat"即可启动,但每次在启动前,务必先运行"update.bat"更新一下。
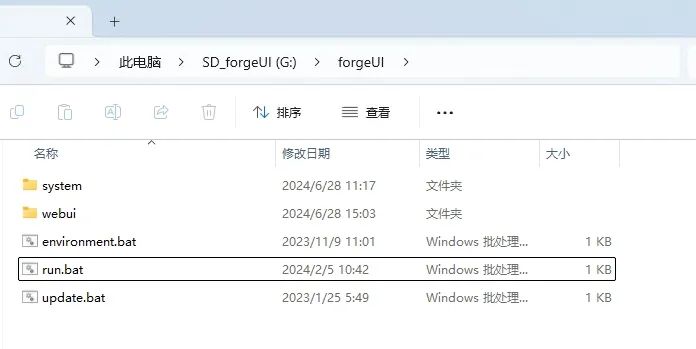
默认运行后是本地地址"127.0.0.1:7860",需要修改成网络地址和更改端口号的小伙伴可以用记事本打开webui目录下的"webui.bat"文件的内容,找到":launch"这部分的代码,在代码"%PYTHON% launch.py%*"内添加" --listen --port 7880",如图所示。
和Stable Diffusion WebUI一样,在webui目录中的extensions文件夹内是安装插件,embeddings文件夹放置embeddings模型,models文件夹放置checkpoints、Lora、hypernetworks等模型,大家可以把Stable Diffusion WebUI目录内的模型和插件都复制过来,可以在ForgeUI中使用。
最重要的是我们需要下载并安装Layer Diffusion插件。
下载地址:
GitHub - lllyasviel/sd-forge-layerdiffuse: [WIP] Layer Diffusion for WebUI (via Forge)
下载后解压缩在extensions文件夹内即可。
Layer Diffusion的模型我打包在网盘中,大家可以自行下载后将文件放在webui\models\layer_model文件夹目录中
下载地址:
另外使用Layer Diffusion需要用到大模型stable-diffusion-xl-base-1.0,放置位置在webui\models\Stable-diffusion文件夹目录中
下载地址:
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main
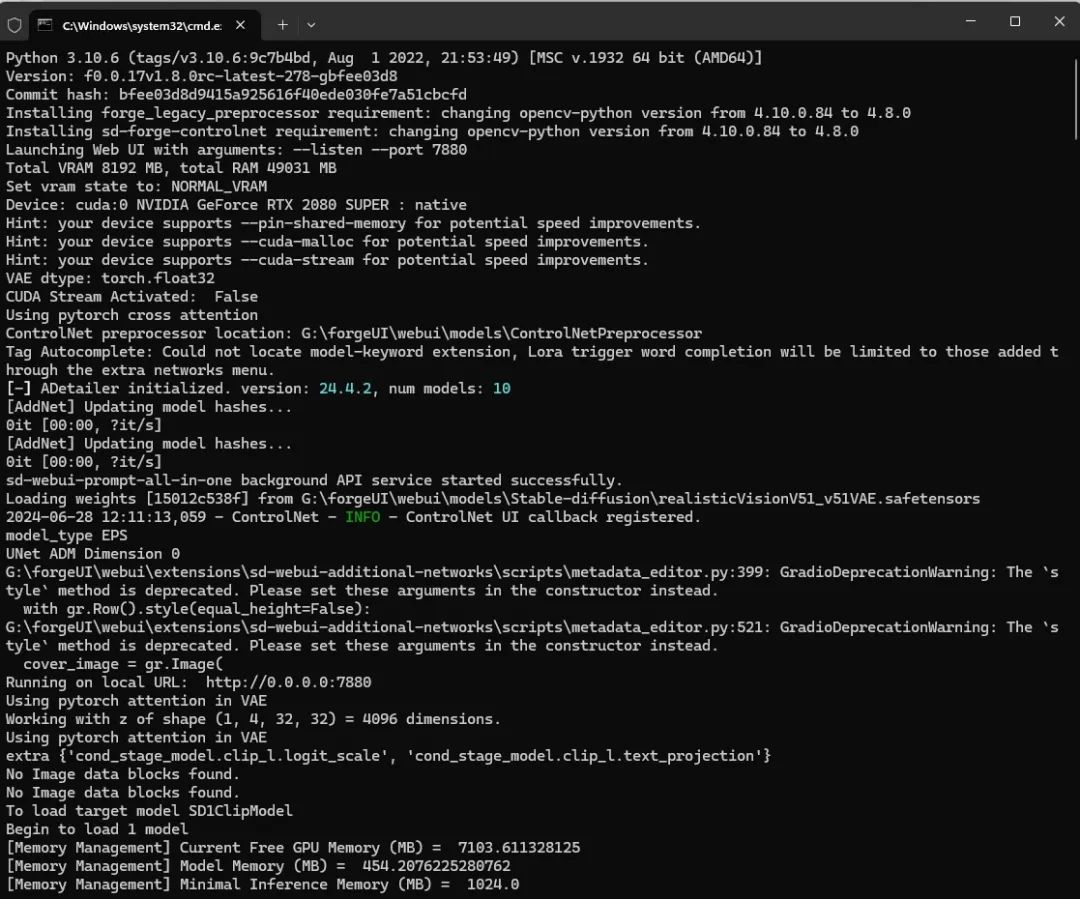
准备工作全部完成后,点击"run.bat"启动,第一次启动时候会下载和安装各类环境,如果你安装了很多插件和模型的话也会加载和更新下载所有必要的支持,会比较慢,需要耐心等待,等看到类似"Running on local URL: http://0.0.0.0:7880"的字样后代表ForgeUI已经成功启动了。
AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了: 
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC 
有需要的朋友,可以点击下方卡片免费领取!
精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。

这份完整版的学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

我们只要在浏览器中输入IP地址加端口号就能访问使用了,如果是本机的话直接输入127.0.0.1加端口号即可(如127.0.0.1:7880)。
29.4 Layer Diffusion的基本使用
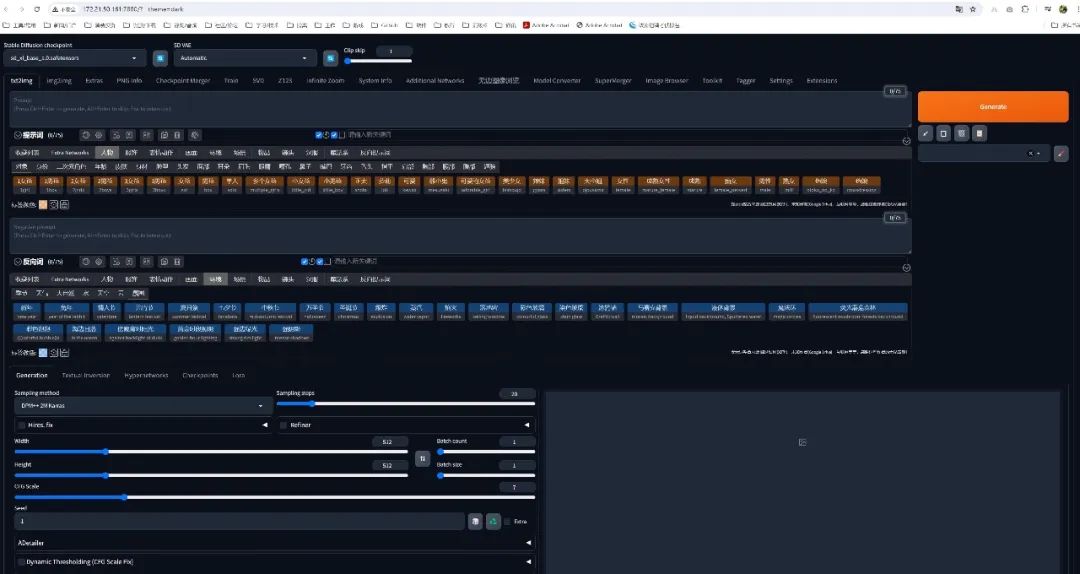
首先,在文生图的下面下方找到LayerDiffuse模块,勾选开启,方案选择"(SDXL)Only Generate Transparent Image(Attention Injection)"(只生成透明背景的图片)。

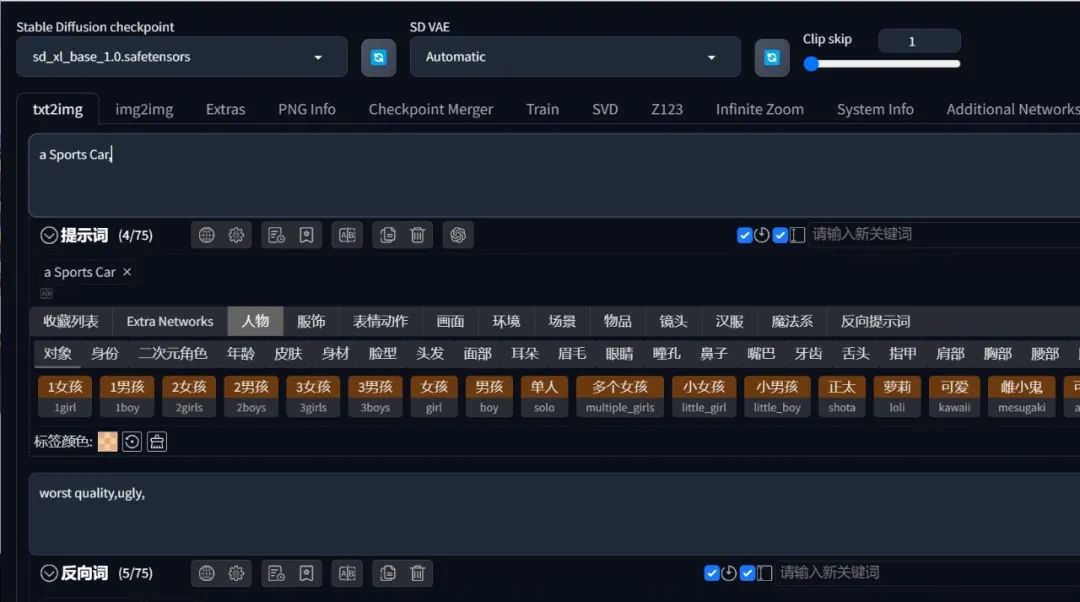
然后选择stable-diffusion-xl-base-1.0大模型,在提示词框内输入你想要生成的内容,比如"a Sports Car"
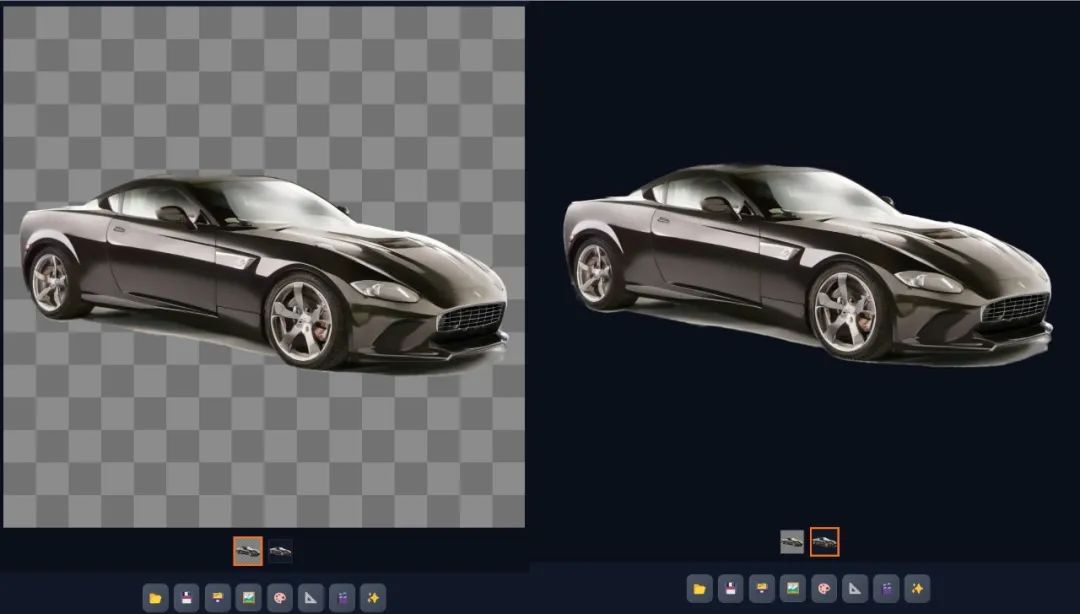
调整合适的分辨率后点击生成,它便生成了两张图片,第一张是预览图,第二张便是透明背景的PNG图片,我们可以直接下载使用。
我们也可以生成更为细致的人物图片。
示例
正向提示词:
best quality,ultra-detailed,masterpiece,hires,8k,raw photo,(photorealistic:1.4),1girl,(solo),Messy hair,ligh beige hair,blue eyes,cat ears,(cat girl:1.1),parted lips,hair between eyes,(low twintails:1.2),long hair,hair ribbon,hair ornament,smooth skin,bowtie,china dress,qi lolita,white thighhighs,standing,upper body,
反向提示词:
NSFW,(worst quality:2),(low quality:2),(normal quality:2),lowres,normal quality,((monochrome)),((grayscale)),skin spots,acnes,skin blemishes,age spot,(ugly:1.331),(duplicate:1.331),(morbid:1.21),(mutilated:1.21),(tranny:1.331),mutated hands,(poorly drawn hands:1.5),blurry,(bad anatomy:1.21),(badproportions:1.331),extra limbs,(disfigured:1.331),(missingarms:1.331),(extra legs:1.331),(fused fingers:1.61051),(too many fingers:1.61051),(unclear eyes:1.331),lowers,bad hands,missing fingers,extra digit,bad hands,missing fingers,(((extraarms and legs))),
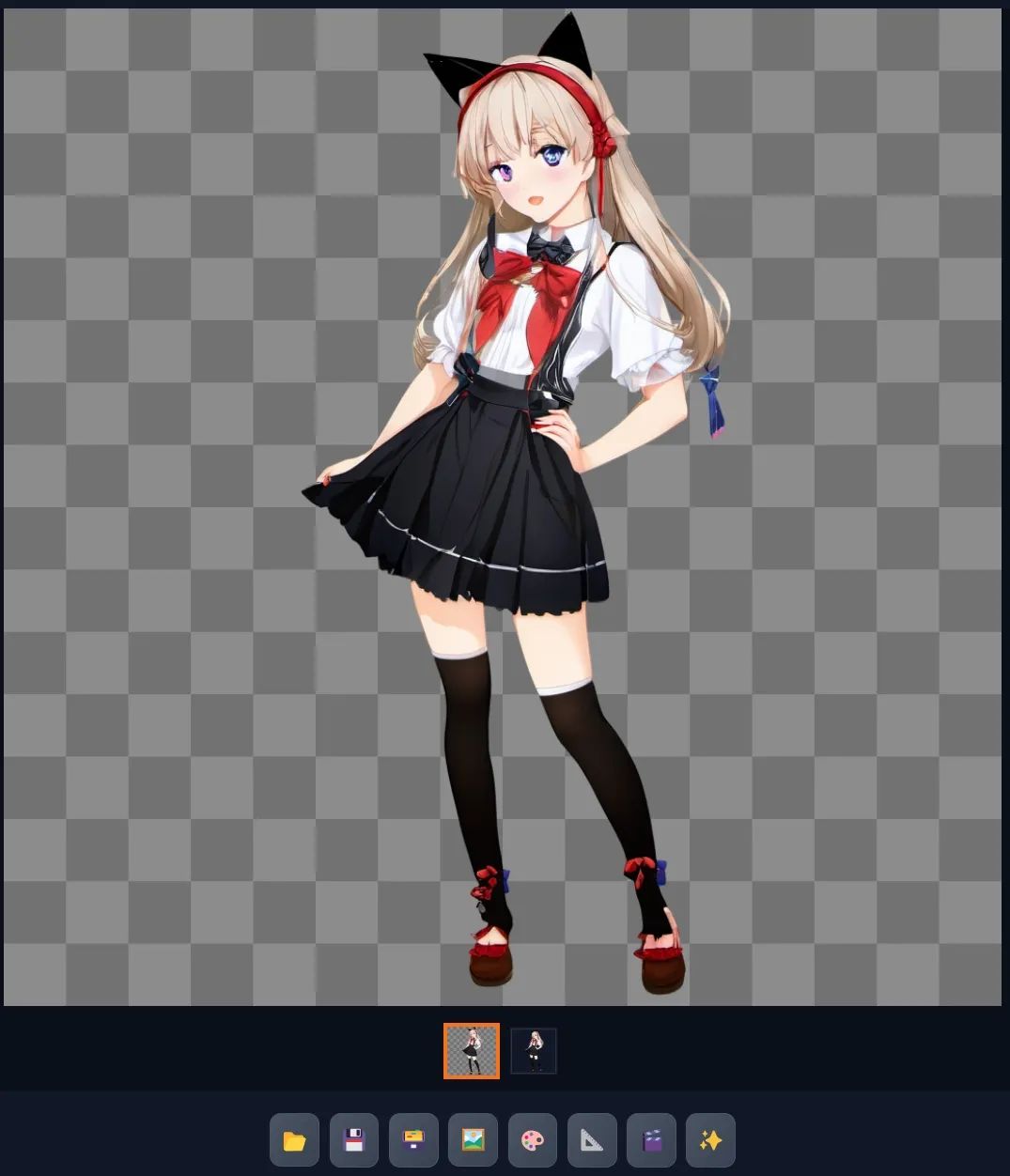
LayerDiffuse不仅能够生成这种轮廓清晰的透明PNG图片,也可以生成一些半透明的PNG素材。
示例
正向提示词:
best quality,ultra-detailed,masterpiece,hires,8k,raw photo,(photorealistic:1.4),A transparent glass bottle,
反向提示词:
NSFW,(worst quality:2),(low quality:2),(normal quality:2),lowres,normal quality,((monochrome)),((grayscale)),skin spots,acnes,skin blemishes,age spot,(ugly:1.331),(duplicate:1.331),(morbid:1.21),(mutilated:1.21),(tranny:1.331),mutated hands,(poorly drawn hands:1.5),blurry,(bad anatomy:1.21),(badproportions:1.331),extra limbs,(disfigured:1.331),(missingarms:1.331),(extra legs:1.331),(fused fingers:1.61051),(too many fingers:1.61051),(unclear eyes:1.331),lowers,bad hands,missing fingers,extra digit,bad hands,missing fingers,(((extraarms and legs))),

这个透明的玻璃瓶是真的完全透明的,可以运用在不同的素材中。

我们也可以使用SD1.5的其他的大模型来生成各种风格的图片,但在使用这些大模型时候也务必在LayerDiffuse模块中选择适用SD1.5的模型哦。

示例:生成火焰之剑
正向提示词:
A flaming sword,high quality,best quality,masterpiece,
反向提示词:
NSFW,(worst quality:2),(low quality:2),(normal quality:2),lowres,normal quality,((monochrome)),((grayscale)),skin spots,acnes,skin blemishes,age spot,(ugly:1.331),(duplicate:1.331),(morbid:1.21),(mutilated:1.21),(tranny:1.331),mutated hands,(poorly drawn hands:1.5),blurry,(bad anatomy:1.21),(badproportions:1.331),extra limbs,(disfigured:1.331),(missingarms:1.331),(extra legs:1.331),(fused fingers:1.61051),(too many fingers:1.61051),(unclear eyes:1.331),lowers,bad hands,missing fingers,extra digit,bad hands,missing fingers,(((extraarms and legs))),

可以看到火焰部分的刻画也是非常细腻的。
我们也可以使用它来生成动漫人物角色。
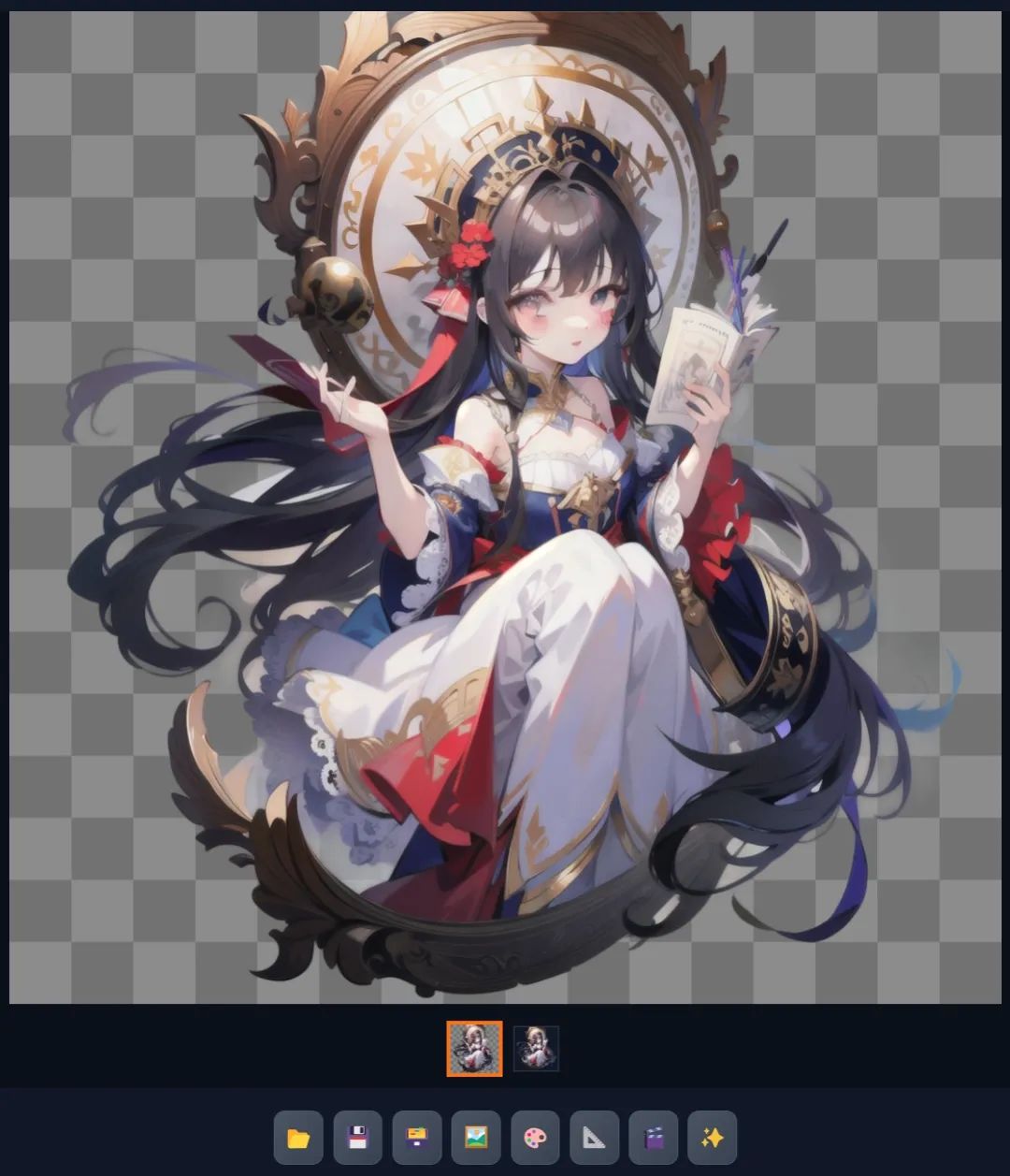
建筑场景。
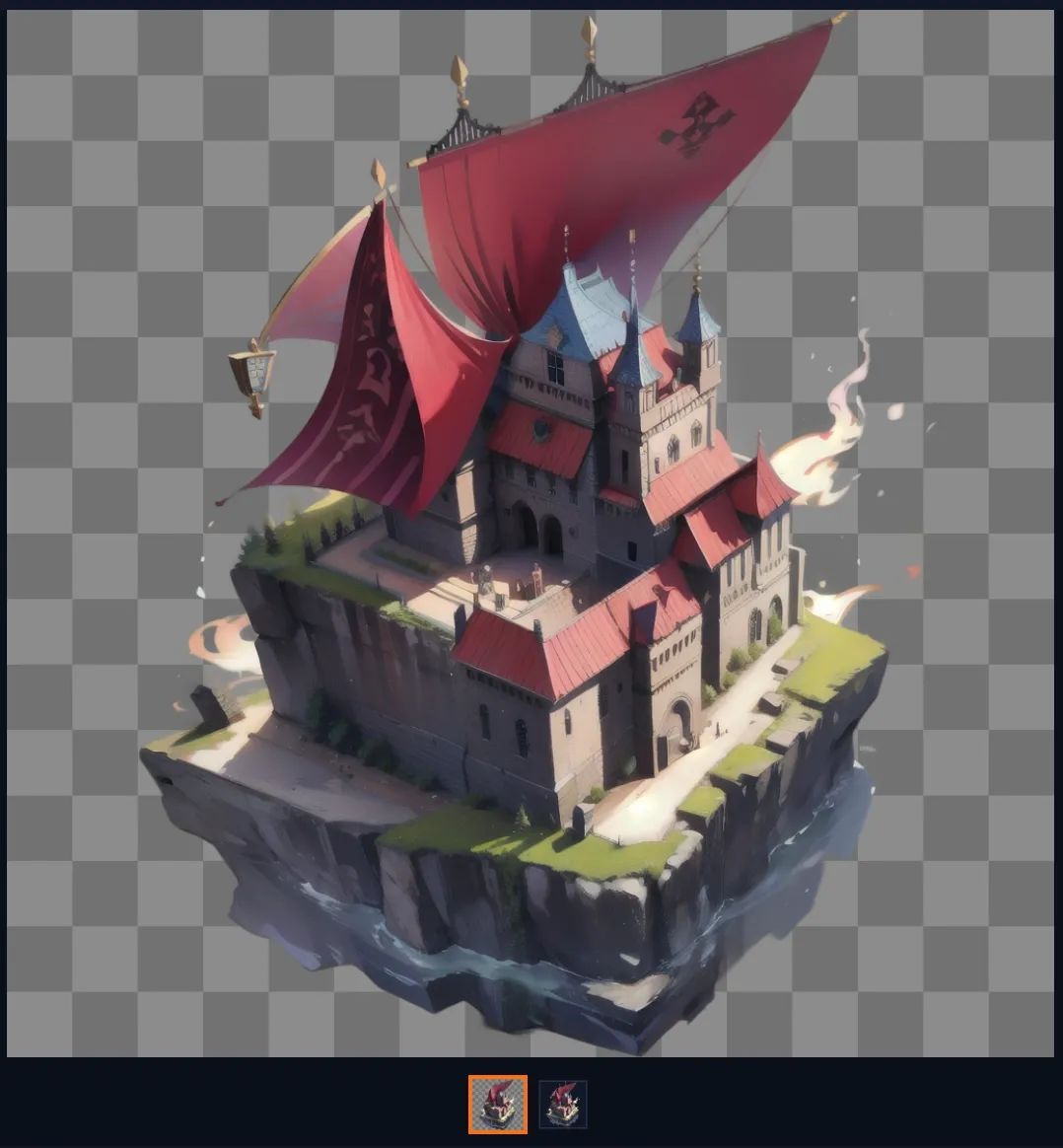
产品设计。

29.5 Layer Diffusion的进阶使用
Layer Diffusion的菜单中,包括我们之前用到的"(SDXL)Only Generate Transparent Image(Attention Injection)",目前有十个选项,你第一次运行某个选项时,后台会自动进行模型文件的下载,需要稍等一会儿。
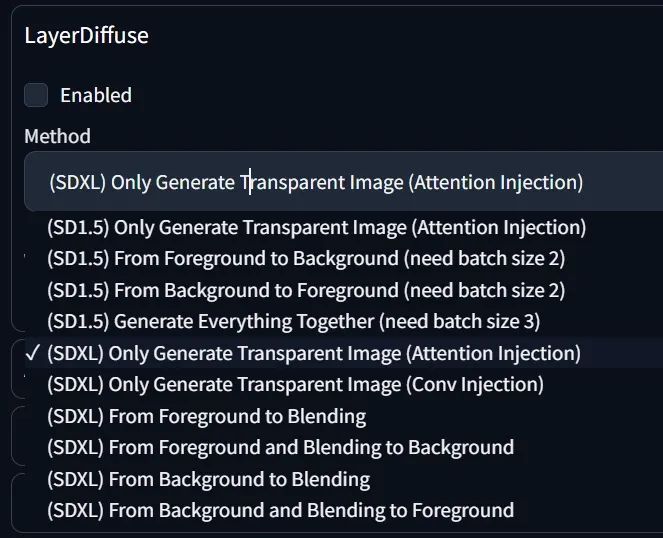
其中"SDXL"开头的选项适用于sd_xl_base_1.0的checkpoint大模型。其中,"(SDXL)From Foreground to Blending"是根据前景(Foreground)补全背景(Background)。
我们可以导入一张前景图。
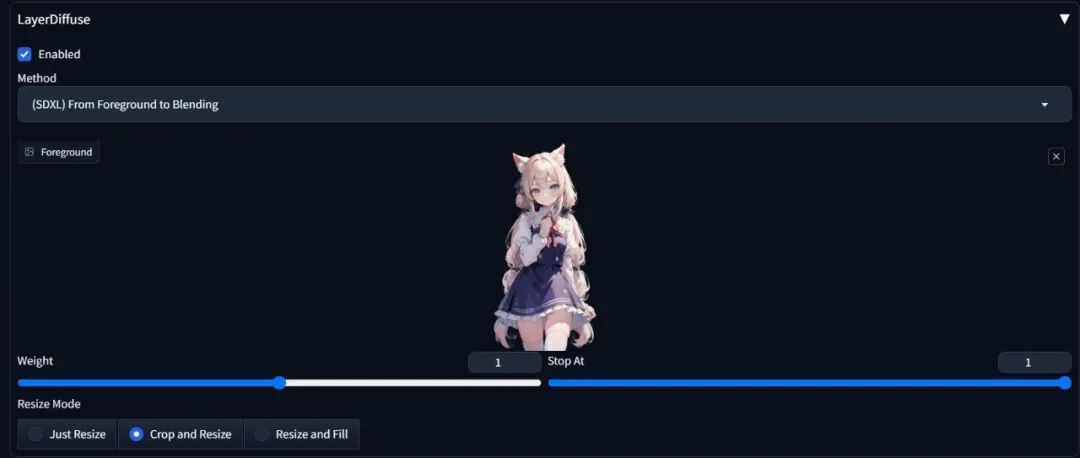
输入包括人物和背景的完整提示词,比如:
正向提示词:
best quality,ultra-detailed,masterpiece,hires,8k,raw photo,(photorealistic:1.4),1girl,(solo),ligh beige hair,blue eyes,cat ears,(cat girl:1.1),parted lips,hair between eyes,(low twintails:1.2),long hair,hair ribbon,hair ornament,smooth skin,bowtie,china dress,qi lolita,white thighhighs,standing,upper body,On the playground,Teaching Building,grassland,Flowers,
反向提示词:
NSFW,(worst quality:2),(low quality:2),(normal quality:2),lowres,normal quality,((monochrome)),((grayscale)),skin spots,acnes,skin blemishes,age spot,(ugly:1.331),(duplicate:1.331),(morbid:1.21),(mutilated:1.21),(tranny:1.331),mutated hands,(poorly drawn hands:1.5),blurry,(bad anatomy:1.21),(badproportions:1.331),extra limbs,(disfigured:1.331),(missingarms:1.331),(extra legs:1.331),(fused fingers:1.61051),(too many fingers:1.61051),(unclear eyes:1.331),lowers,bad hands,missing fingers,extra digit,bad hands,missing fingers,(((extraarms and legs))),
点击生成,就会根据你的提示词生成背景,并且组成一张完全的全景图,注意尺寸需要和原图一致。

如果你需要的只是这幅图中的背景图的话,那只需要将Layer Diffusion中的选项更改为"(SDXL)From Foreground and Blending to Background",左侧的"Foreground"中还是加载前景图,然后将刚刚生成的全景图加载到右侧的"Blending"中。
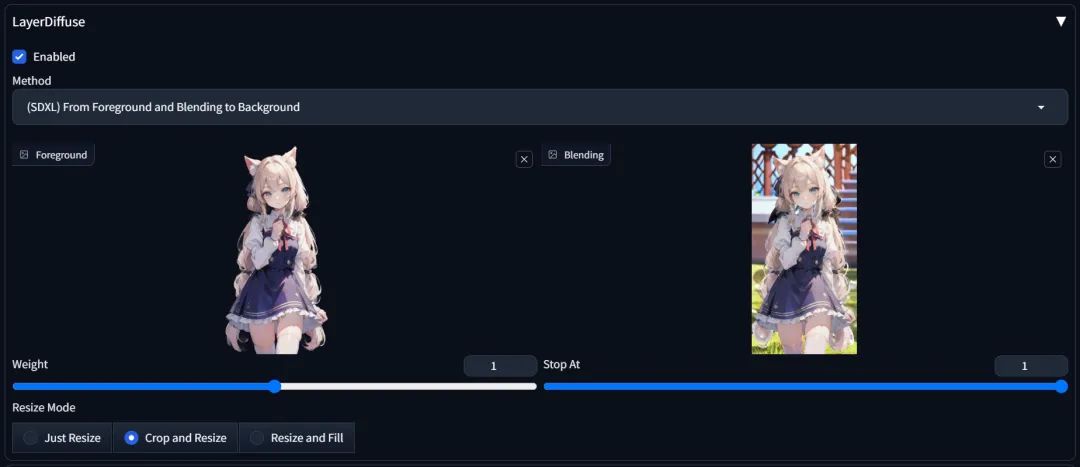
然后把提示词中关于人物的描写去掉,调整一致的尺寸,点击生成,便能生成一张去掉人物的背景图。

同样,我们也可以利用"(SDXL)From Background to Blending"来根据背景补全前景。我们加载一张背景图片。
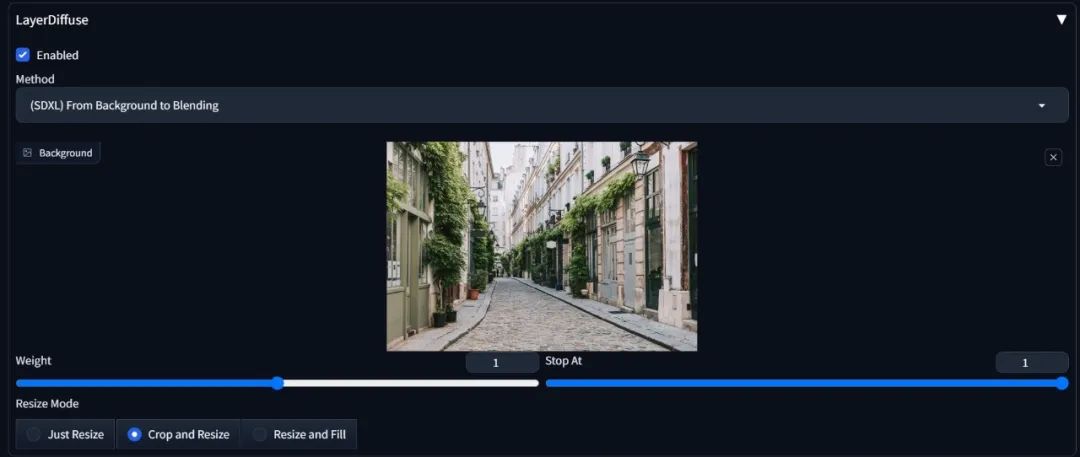
然后在提示词中输入你希望在这张背景中呈现的前景内容,比如加入"A man walking down the street":
正向提示词:
best quality,ultra-detailed,masterpiece,hires,8k,raw photo,(photorealistic:1.4),A man walking down the street
反向提示词:
NSFW,(worst quality:2),(low quality:2),(normal quality:2),lowres,normal quality,((monochrome)),((grayscale)),skin spots,acnes,skin blemishes,age spot,(ugly:1.331),(duplicate:1.331),(morbid:1.21),(mutilated:1.21),(tranny:1.331),mutated hands,(poorly drawn hands:1.5),blurry,(bad anatomy:1.21),(badproportions:1.331),extra limbs,(disfigured:1.331),(missingarms:1.331),(extra legs:1.331),(fused fingers:1.61051),(too many fingers:1.61051),(unclear eyes:1.331),lowers,bad hands,missing fingers,extra digit,bad hands,missing fingers,(((extraarms and legs))),
输出尺寸调整为和原图一致,点击生成。

就目前阶段而言,这个功能对原图的空调理解还不够,所以生成出来的人物比例和原图的结合可能还不够完美。可能直接生成透明背景的人物后再手动调整大小放进背景图中会来的更有效率。
接下来就是"(SDXL)From Background and Blending to Foreground",意思是输入背景图和全景图,生成前景图。在"background"中加载背景图,在"blending"中加载全景图。
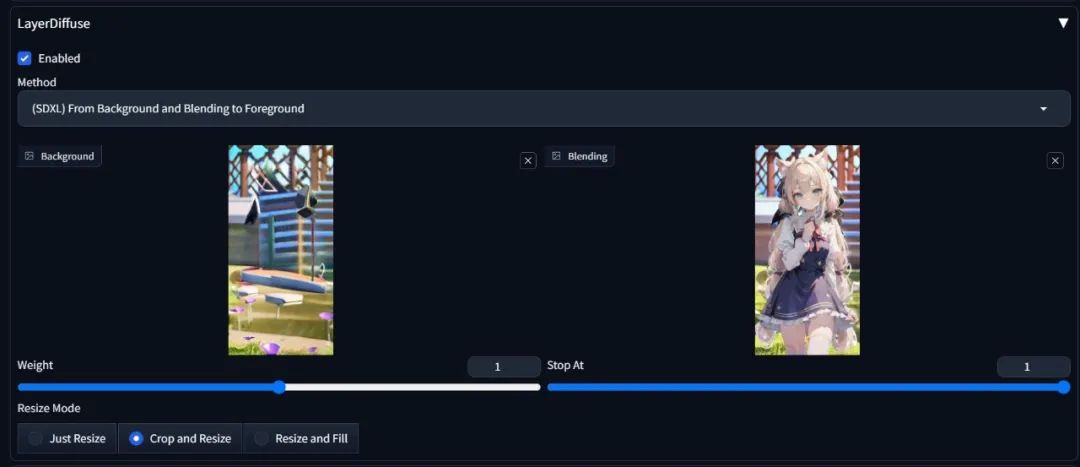
提示词中输入相关的提示词,并且尺寸调至和原图一致,点击生成即可。

"(SDXL)Only Generate Transparent Image(Attention Injection)"和"(SDXL)Only Generate Transparent Image(Conv Injection)"的区别是,前者基于注意力层训练,后者基于卷积层训练。
扩展知识:
注意力层(Attention Layer)
什么是注意力层?
注意力层是一种神经网络层,用于捕捉输入数据中不同部分之间的关系。它通过计算输入序列中每个元素的重要性得分(注意力权重),然后将这些权重应用于输入序列,产生加权和的输出。注意力机制在自然语言处理(如机器翻译)和图像处理(如图像生成)中非常流行,因为它能够有效地捕捉长距离依赖关系。
常规注意力层的工作原理
计算注意力权重:使用输入的查询(Query)、键(Key)和值(Value)向量计算注意力权重。
加权求和:将注意力权重应用于值向量,得到加权和的输出。
卷积层(Convolutional Layer)
什么是卷积层?
卷积层是卷积神经网络(CNN)的核心组件,广泛用于图像处理。卷积层通过卷积操作提取输入数据中的局部特征。卷积操作使用一个或多个滤波器(卷积核)在输入数据上滑动,产生特征图。卷积层擅长捕捉局部空间特征。
卷积层的工作原理
卷积操作:使用卷积核在输入数据上滑动,进行点积运算,产生特征图。
非线性激活:将卷积结果通过非线性激活函数(如ReLU)处理,增加模型的非线性能力。
两种注入技术的区别
注意力注入(Attention Injection)
描述:在生成透明图像时,使用注意力机制将相关信息注入到图像生成过程中。
适用场景:注意力注入通常用于需要捕捉长距离依赖关系和复杂上下文的任务。
优点:能够捕捉输入数据中不同部分之间的复杂关系,适合处理具有高度依赖关系的输入数据。
卷积注入(Conv Injection)
描述:在生成透明图像时,使用卷积层将相关信息注入到图像生成过程中。
适用场景:卷积注入适用于捕捉局部特征的任务,如图像中的边缘、纹理等。
优点:擅长提取局部空间特征,计算效率高,适合处理大规模图像数据。
总结
注意力注入 适用于需要捕捉长距离依赖关系和复杂上下文的任务,适合生成具有高度依赖关系的图像。
卷积注入 适用于捕捉局部特征的任务,计算效率高,适合处理具有明显局部特征的图像。
选择哪种注入技术取决于具体的图像生成需求和输入数据的特征。根据作者推荐,实践中注意力层的表现会更好。
除了SDXL的方案,剩下的方案都是基础SD1.5相关的模型训练出来的,基本上里面每一项对应的原理和SDXL相似,如果使用这些Layer Diffusion模型,那对应的checkpoint大模型也要选择SD1.5对应的(就是我们之前下载的那些常用大模型)。但其中"(SD1.5)Generate Everything Together(need batch size 3)"选项为直接生成包含前景、背景、全景的组合图。
示例:
选择这个选项后,一次会输出3张图,所以需要把"Batch size"(单批数量)设置为3或3的倍数,然后在Layer Diffusion模块中的"Foreground Additional Prompt"内输入前景的额外提示词、在"Background Additional Prompt"内输入背景的额外提示词、在"Blended Additional Prompt"内输入全景的额外提示词,而在正向和反向提示词内仅需输入画质部分的起手式提示词即可。
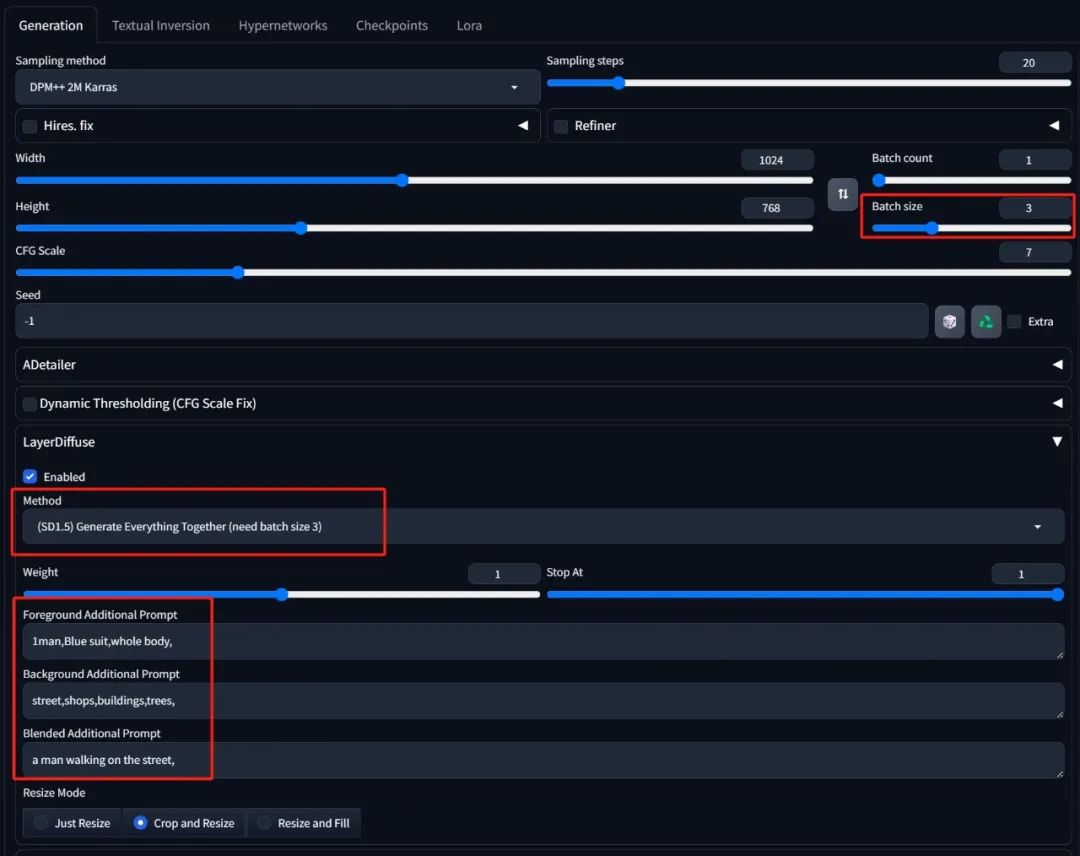
比如:
Foreground Additional Prompt:1girl,red dress,whole body,
Background Additional Prompt:street,shops,buildings,trees,
Blended Additional Prompt:a girl walking on the street,
正向提示词:
best quality,masterpiece,Exquisite facial features
反向提示词:
worst quality,text,ugly,(deformed ris,deformed pupils),worst qualty,low qualty,jpeg artifacts,ugly,duplicate,morbid,mutilated,(extra fingers),(mutated hands),poorly drawn hands,poorly drawn face,mutation,
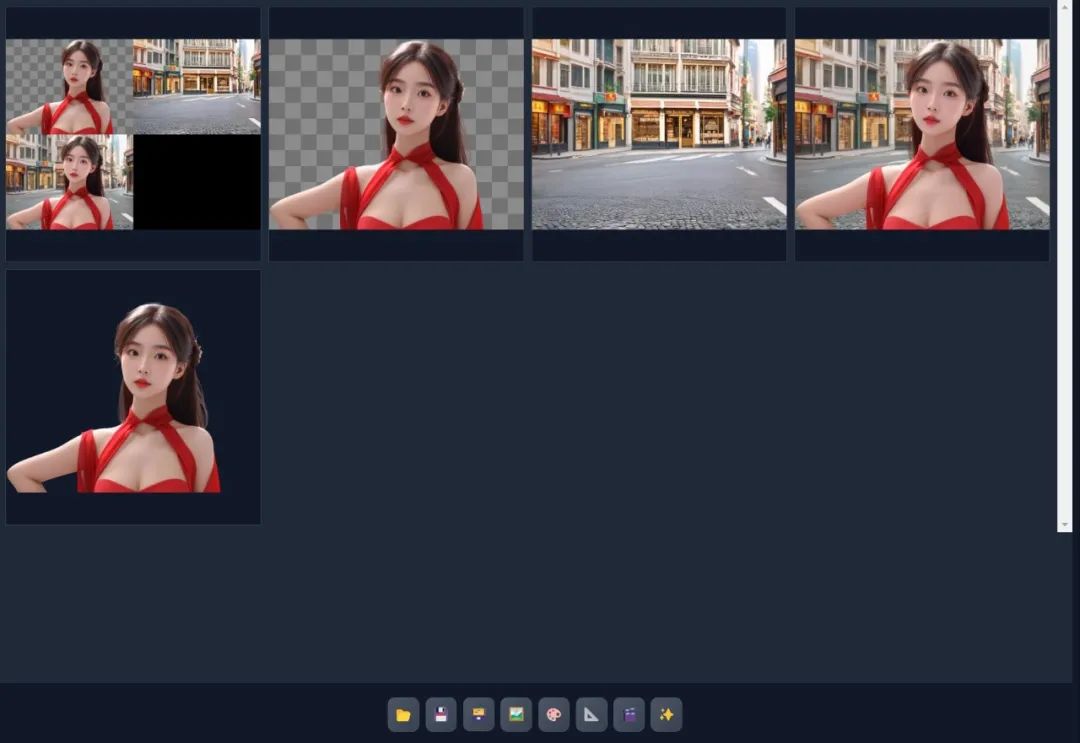
点击生成,便可以生成包含前景图、背景图、全景图的一套素材图了。
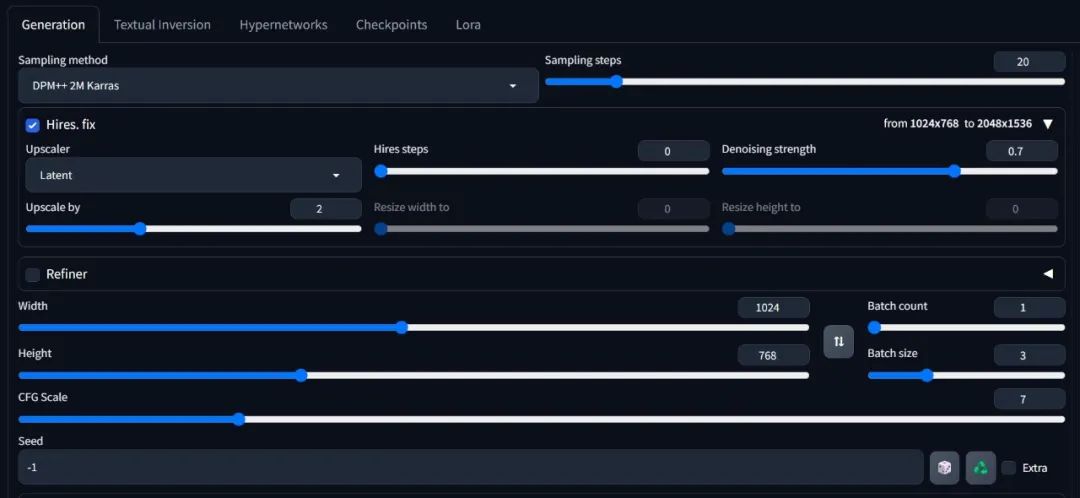
29.6 Stable Diffusion ForgeUI的拓展
对于Stable Diffusion ForgeUI来说,它几乎和Stable Diffusion WebUI是同样使用的,我们也可以勾选高分辨率修复等选项来生成更为精细、符合自己需求的图片。也可以使用Lore,Hypernetwork等模型来生成图片。
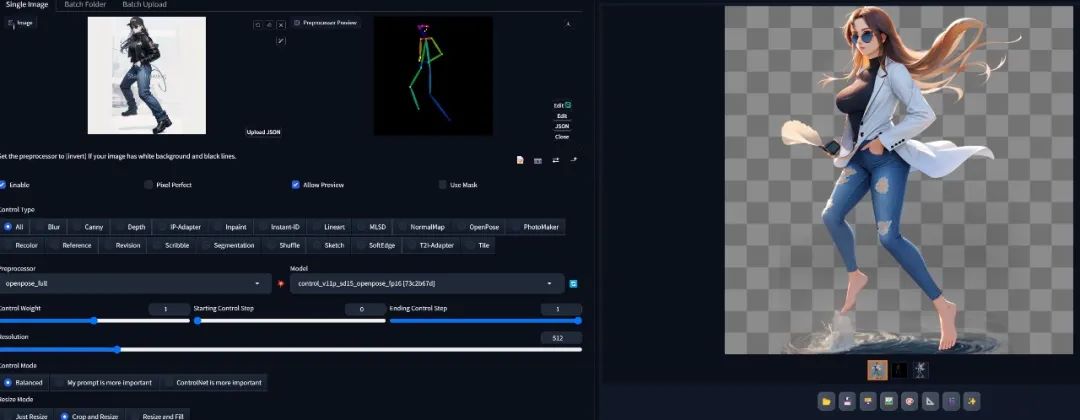
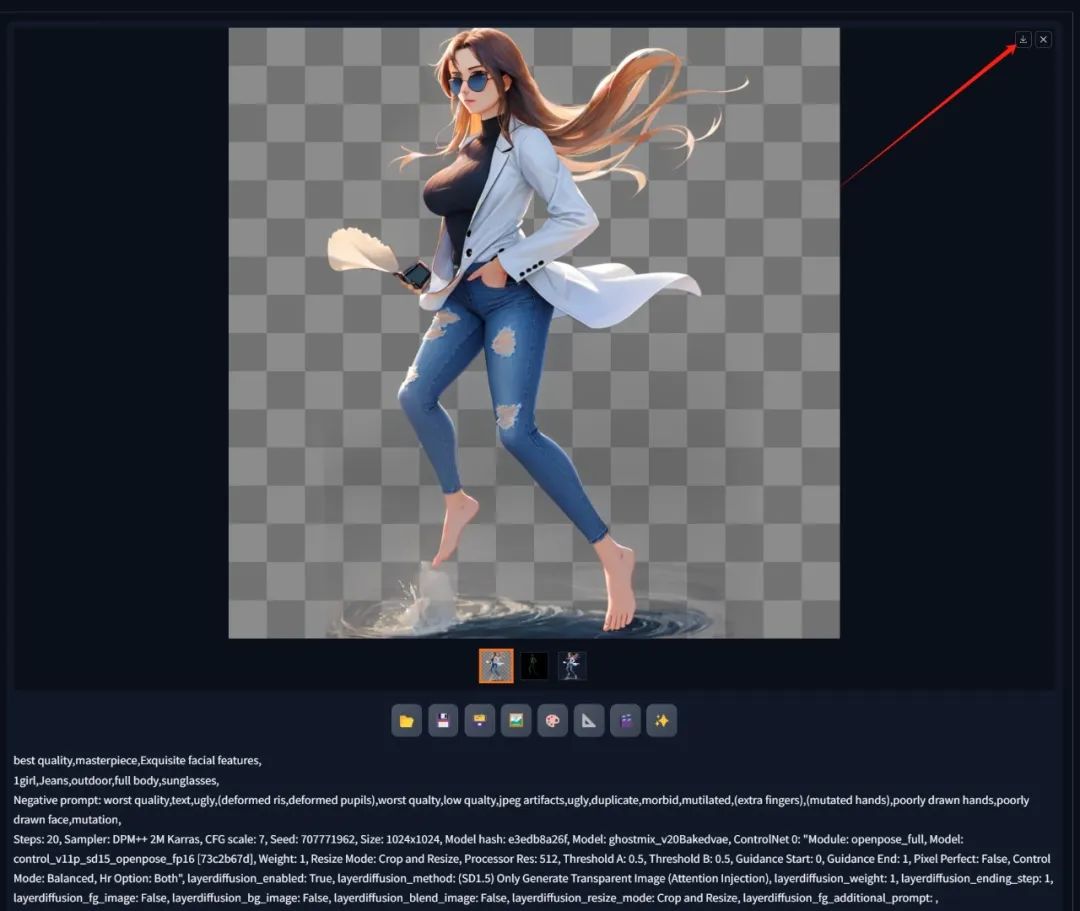
另外最新版本的Stable Diffusion ForgeUI也以将支持ControlNet插件,我们也可以在ForgeUI中使用ControlNet了,可以根据我们的姿势引导生成透明的人物图片。需要注意的是图片分辨率建议是1024*1024,提示词不能过长,并且必须使用SD1.5的模型。
这份完整版的学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
我们一般生成的图片都会自动保存在webui\output文件夹内,但生成的透明底的PNG文件不会,所以你生成出你需要的图片时务必手动下载保存下来。

















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









