










第十九部分 模型之Embeddings(文本嵌入)
** **
19.1 关于Embeddings
词嵌入模型的基本概念
词嵌入(Embeddings),又称为Textual Inversion(文本倒置),是一种将文本数据转化为向量表示的方法,使得词语在高维空间中具有一定的语义信息。通过这种向量表示,可以更好地进行文本处理和分析,特别是在自然语言处理(NLP)和生成对抗网络(GAN)中应用广泛。
Embeddings模型就像书签一样可以帮我们快速方便的从大模型这本字典里搜寻出我们特定需要呈现的词汇表达,精准的让AI知道我们所需的特定词汇的含义。Embeddings本身不包含任何信息,所以它的大小非常小,一般的格式为.pt后缀结尾。
基本原理:
-
每个词或短语被映射到一个固定维度的向量。
-
向量的维度通常在几十到几百之间。
-
词嵌入可以通过预训练模型(如Word2Vec、GloVe)或在特定任务中训练来获得。
模型位置:Embeddings模型放置于WebUI文件根目录下的Embeddings文件夹内
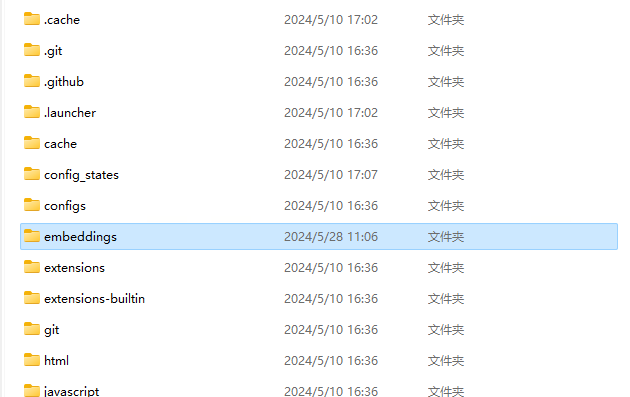
如何调用:每个Embeddings模型都有特定的词汇来激活启用它,一般在模型的说明文件中都有。
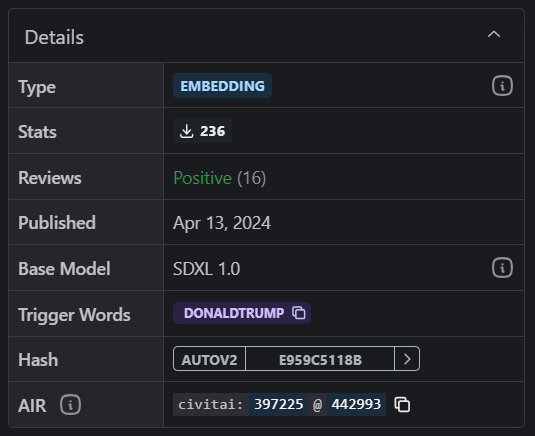
示例:
以这个donaldtrump的Embeddings模型为例,我先不加入这个模型的提示词。
1man,smile,standing,outdoors,street,handsome,best quality,ultra-detailed,masterpiece,hires,8k,

然后加入关键字:donaldtrump
donaldtrump,1man,smile,standing,outdoors,street,handsome,best quality,ultra-detailed,masterpiece,hires,8k,

值得注意的是有些模型的关键字顺位放在靠前的位置所产生的效果会更好。
19.2 Embeddings的其他重要作用:
这类Embeddings收集了大量AI出图的错误示例,我们只需要将其添加到反向提示词中,便能一定程度避免AI生成错误的手指。比如模型EasyNegative(该模型主要针对二次元画风)、Deep Negative(该模型主要针对真实画风)。
下载地址:
https://civitai.com/models/7808?modelVersionId=9208
https://civitai.com/models/4629/deep-negative-v1x
正向提示词:1girl,close-up,portrait,hands up,Covering eyes with hands,(masterpiece:1.2),best quality,masterpiece,highres,original,extremely detailed wallpaper,perfect lighting,(extremely detailed CG:1.2),drawing,paintbrush,
反向提示词:NSFW,(worst quality:2),(low quality:2),(normal quality:2),lowres,normal quality,((monochrome)),((grayscale)),skin spots,acnes,skin blemishes,age spot,(ugly:1.331),(duplicate:1.331),(morbid:1.21),(mutilated:1.21),(tranny:1.331),mutated hands,(poorly drawn hands:1.5),blurry,(bad anatomy:1.21),(badproportions:1.331),extra limbs,(disfigured:1.331),(missingarms:1.331),(extra legs:1.331),(fused fingers:1.61051),(too many fingers:1.61051),(unclear eyes:1.331),lowers,bad hands,missing fingers,extra digit,bad hands,missing fingers,(((extraarms and legs)))

可以看到生成出来的手指是错误的。我们在反向提示词中加入该模型的关键词:(easynegative:1.2),这里具体权重大家可以根据实际情况进行调试。加入该Embeddings后,便修正了错误的手指。

-
解决AI出图手指容易出错的问题:
-
生成角色多视图:
如CharTurner - Character Turnaround helper,可用于生成人物的多角度视图,非常适合产品及人物的设计。
下载地址:
https://civitai.com/models/3036/charturner-character-turnaround-helper-for-15-and-21

正向提示词:A character turnaround of a handsome wearing T-shirt,(charturnerv2:1.2),Multiple views of the same characterin the same outft,full body,((character sheet)),((turnaround)),(reference sheet),character concept,(masterpiece:1.2),best quality,masterpiece,highres,original,extremely detailed wallpaper,perfect lighting,(extremely detailed CG:1.2),drawing,paintbrush,
反向提示词:NSFW,(worst quality:2),(low quality:2),(normal quality:2),lowres,normal quality,((monochrome)),((grayscale)),skin spots,acnes,skin blemishes,age spot,(ugly:1.331),(duplicate:1.331),(morbid:1.21),(mutilated:1.21),(tranny:1.331),mutated hands,(poorly drawn hands:1.5),blurry,(bad anatomy:1.21),(badproportions:1.331),extra limbs,(disfigured:1.331),(missingarms:1.331),(extra legs:1.331),(fused fingers:1.61051),(too many fingers:1.61051),(unclear eyes:1.331),lowers,bad hands,missing fingers,extra digit,bad hands,missing fingers,(((extraarms and legs))),(easynegative:1.2),

-
图像生成:在Stable Diffusion中,可以使用词嵌入来描述要生成的对象或概念。例如,输入“sunset over a mountain range”时,系统会将其转换为向量,并生成相应的图像。
-
语义搜索:通过词嵌入,可以实现语义搜索,即根据语义相似度进行搜索,而不仅仅是关键词匹配。
-
文本分类:使用词嵌入表示文本,然后输入分类模型进行分类。
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!




第二十部分 低秩模型(LoRA)
20.1 LoRA的基本概念
LoRA(Low-Rank Adaptation) 是一种优化生成图像的方法。它可以让图像生成模型在保持高质量的前提下,变得更高效、更快速。
在Stable Diffusion中,LoRA模型可以让AI针对更具体的形象、特征来生成图片,同时简化了生成图片的步骤,让整个过程变得更加具体和便捷。
20.2 LoRa的作用与应用简析
LoRa的作用:
精准生图:LoRA可以让图像特征生成得更为精准,虽然不如Embeddings那样轻巧,但却可以更具象化的生成你想要的目标人物或特征。
应用场景:
目前LoRA常用于游戏、电影等应用场景的人物创造,可以通过大量的训练来创造出特征鲜明的人物角色。
模型位置:LoRA模型放置于WebUI文件根目录下Models文件夹内的LoRA文件夹内
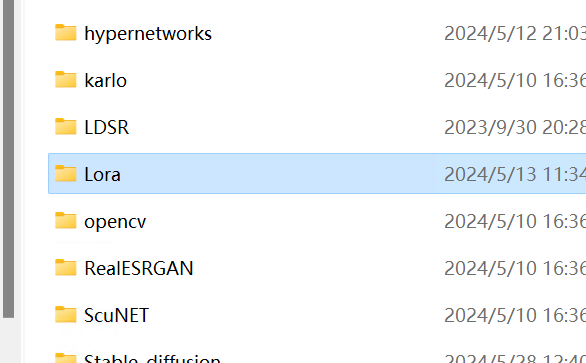
如何调用:在提示词中输入lora:模型名称即可调用。例如:lora:princess_xl_v2,也有一些LoRA有固定的触发提示词,具体可以参考各LoRA的说明文件。
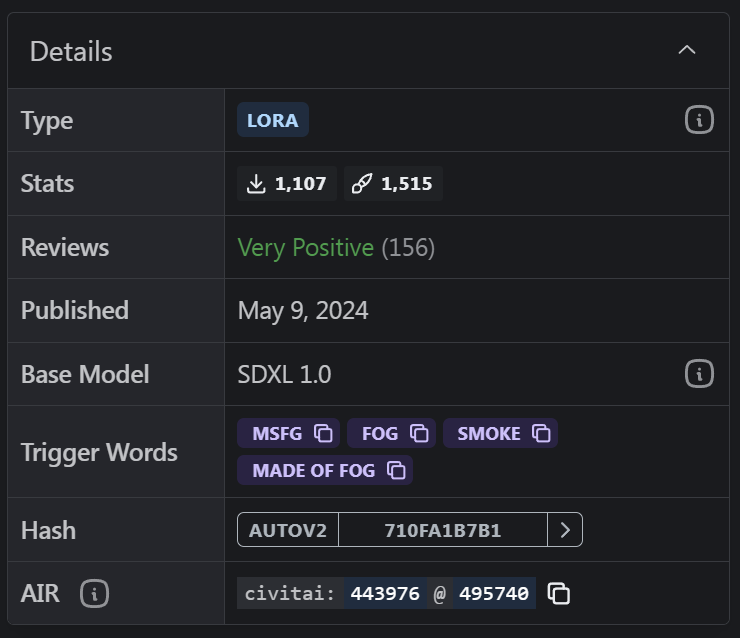
20.3 LoRa的具体示例
我这里采用All Disney Princess XL LoRA Model结合一些二次元的大模型来生成迪士尼的人物形象。
下载地址:https://civitai.com/models/212532/all-disney-princess-xl-lora-model-from-ralph-breaks-the-internet
该LoRA模型可以生成多个人物形象,我们在正向提示词中加入lora:princess_xl_v2:0.4(*权重可以根据模型的说明文件来设定*)触发该模型并加入人物名称elsa来生成爱莎公主的形象。(你也可以输入其他形象名称)
正向提示词:cinematic photo casual elsa,<lora:princess_xl_v2:0.4>,35mm photograph,film,bokeh,professional,4k,highly detailed,
反向提示词:drawing,painting,crayon,sketch,graphite,impressionist,noisy,blurry,soft,deformed,ugly,

第二十一部分 超网络(Hypernetwork)
** **
21.1 超网络的基本概念
超网络(Hypernetwork) 是一种生成网络参数的网络。简单来说,就是一个网络(超网络)用来生成另一个网络(目标网络)的参数。超网络通过预测目标网络的权重,使得目标网络在特定任务上表现得更好。
通俗点讲,超网络就像是一个“厨师”,它通过调整“配方”(即网络参数),来生成特定口味的“菜肴”(即目标网络的输出)。这样可以使目标网络更快速地适应不同的任务和数据。
22.2 Hypernetwork的作用与应用简析
Hypernetwork的作用:
Hypernetwork和LoRA类似,可以用于生成经过训练的特定特征的画面,但LoRA更针对于人物或局部的细节,而Hypernetwork更侧重于调整生成图像的整体风格,可以说Hypernetwork定义的整体画风要更精细于Checkpoint模型。
应用场景:
-
图像生成:
-
在图像生成领域,超网络可以用来生成不同风格的图像。例如,生成具有特定艺术风格的图像。
-
-
自然语言处理:
-
在自然语言处理任务中,超网络可以用来生成特定领域的语言模型参数,使得模型更适应特定领域的文本数据。
-
-
迁移学习:
-
在迁移学习中,超网络可以用来生成目标任务的初始参数,使得模型更快适应新任务。
-
** **
*模型位置:*Hypernetwork模型放置于WebUI文件根目录下Models文件夹内的Hypernetwork文件夹内
*如何调用:*在“设置-扩展模型”中,找到“将hypernetwork添加到提示词”的下拉菜单,选择你需要使用的hypernetwork模型,然后点击上方的保存。

*20.3 **Hypernetwork**的具体示例*
我这里采用[LamaPanama] Waven Chibi Style的模型,这个模型可以将画风变成Q版,结合之前LoRA生成的爱莎来生成她Q版风格的人物形象。
下载地址:
https://civitai.com/models/4379/lamapanama-waven-chibi-style
我们所有提示词和之前的一致,仅加载了Hypernetwork模型,我们便生成了爱莎的Q版形象。
正向提示词:cinematic photo casual elsa,<lora:princess_xl_v2:0.4>,. 35mm photograph,film,bokeh,professional,4k,highly detailed,
反向提示词:drawing,painting,crayon,sketch,graphite,impressionist,noisy,blurry,soft,deformed,ugly,

总结
今天我们详细介绍了Stable Diffusion中的三种重要技术:低秩模型(LoRa)、超网络(Hypernetwork)以及文本嵌入(Embeddings)。这些技术各自有其独特的功能和应用场景,能够显著提升图像生成和处理的效率与效果。
-
理解基础概念:掌握每种技术的基本原理,有助于更好地应用这些技术。
-
结合应用场景:根据具体需求选择合适的技术。
-
不断实践优化:通过实际操作和不断优化,提升对这些技术的熟练度和应用效果。\
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。
2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。
3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。
4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。
5.SD从0到落地实战演练
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!
![]()
![]()

















 626
626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









