






你好,欢迎查看我的第5个笔记。这是本人为了保存一些代码而写的博客,由于精力实在有限,无法从头开始介绍爬虫相关的知识故仅仅罗列了几段代码案例
1.编写url管理器
class UrlManager():
"""
url管理器罢了
"""
def __init__(self):
self.new_urls=set()
self.old_urls=set()
def add_new_url(self,url):
if url is None or len(url)==0:
return
if url in self.new_urls or url in self.old_urls:
return
self.new_urls.add(url)
def add_new_urls(self,urls):
if urls is None or len(urls)==0:
return
for url in urls:
self.new_urls.add(url)
def get_url(self):
if self.is_has_url():
url = self.new_urls.pop()
self.old_urls.add(url)
return url
else:
return None
def is_has_url(self):
return len(self.new_urls) > 0
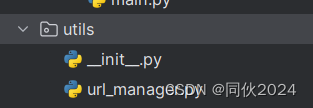
要先创建一个包(utils),在里面建个py文件(url_manager),里面写上面的代码
像这样:
2.爬取www.crazyant.net的全部标题网页
import requests
from bs4 import BeautifulSoup
from utils import url_manager
import re
fout=open("crazyant_all_pages.text","w")
root_url ="http://www.crazyant.net"#定义入口网站
urls=url_manager.UrlManager()#实例化UrlManager类
urls.add_new_url(root_url)#调用add_new_url()方法,把入口网站放在new_urls里面
while urls.is_has_url():#当new_urls里面有网站时
cur_url=urls.get_url()#从newurls里面拿出一个网站
r=requests.get(cur_url,timeout=3)#发送request,抓取r的信息
soup=BeautifulSoup(r.text,"html.parser")#用html。parser解析r
title=soup.title.string#抓取r的title信息
print("success: %s,%s\n" % (cur_url, title))#打印cur_url 和 title
fout.write("%s\t%s\n"%(cur_url,title))
links=soup.find_all("a")#得到所有的a标签
pattern=r'^http://www.crazyant.net/\d+.html$'#设置正则语句
for link in links:##遍历每一个a
href=link["href"]#得到每个a的链接
if href is None or len(href)==0:
continue
if re.match(pattern,href) :
urls.add_new_url(href)
fout.close()
注:www.crazyant.net是b站up主的个人博客,见下面链接[3.2]--Python爬虫实战爬取所有博客页面_哔哩哔哩_bilibili
附一张up主的主页图片
3.爬取四川农业大学教务网的通知
import requests
from bs4 import BeautifulSoup
fout = open("jiaowu_Notice.text","w",encoding="utf8")
url ="https://jiaowu.sicau.edu.cn/web/web/web/gwmore.asp"
response=requests.get(url)
response.encoding="gb2312"
soup = BeautifulSoup(response.text,"html.parser")
form=soup.find("form",attrs={"method":"post"})
trs=form.find_all("tr",attrs={"class":"text-c"})
num=1
for tr in trs:
links=tr.find("div",attrs={"align":"left"})
if links is None or len(links) == 0:
continue
for link in links:
try:
href=link["href"]
if href is None or len(href) == 0:
continue
print(f"{num}. https://jiaowu.sicau.edu.cn/web/web/web/{href}\t{link.get_text()}\n")
num+=1
fout.write(f"{num}.\thttps://jiaowu.sicau.edu.cn/web/web/web/{href}\t{link.get_text()}\n")
except:
pass
fout.close()4.爬取打印四川农业大学理学院所有的通知告示
import requests
from bs4 import BeautifulSoup
num=0
url_list=["https://lixueyuan.sicau.edu.cn/xwjtz/tzgg.htm"]
for n in [2,3]:
url_list.append(f"https://lixueyuan.sicau.edu.cn/xwjtz/tzgg/{n}.htm")
for url in url_list:
r=requests.get(url)
r.encoding="utf8"
soup=BeautifulSoup(r.text,"html.parser")
lis=soup.find("div",attrs={"class":"newm"}).find_all("li")
for li in lis:
a=li.find("a")
text_list=a.get_text().split("\n")
text = text_list[1]
time = text_list[2]
href=a["href"].strip("..")
num+=1
print(f"{num}\thttps://lixueyuan.sicau.edu.cn{href}\t{time}\t{text}")

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









