






一、模型评估的性能度量
在机器学习和统计建模中,模型评估的性能度量是衡量模型预测能力的关键指标。根据任务类型(分类、回归、聚类等),常用的性能度量如下:
1.混淆矩阵
对于一个二分类模型(正类 Positive vs. 负类 Negative),混淆矩阵是一个 2×2 的表格:
| 实际为正(P) | 实际为负(N) | |
| 预测为正(P^) | True Positive (TP) 真正例 | False Positive (FP) 假正例 |
| 预测为负(N^) | False Negative (FN) 假负例 | True Negative (TN) 真负例 |
True Positive (TP):模型正确预测为正的样本,即真正例。
False Positive (FP):模型错误预测为正的样本(误报),即假正例。
False Negative (FN):模型错误预测为负的样本(漏报),即假负例。
True Negative (TN):模型正确预测为负的样本,即真负例。
由混淆矩阵我们可以求得准确率,精确率等性能度量。
2.准确率(Accuracy)
准确率(Accuracy)是分类正确的样本数占总样本数的比例,是指分类模型对所有样本进行分类的正确率,即分类正确的样本数除以总样本数。准确率是最常用的模型评估指标之一,它可以告诉我们模型在对数据进行分类时的整体表现。
准确率(Accuracy)的计算公式:
实际上,准确率对不平衡数据尤为敏感(如99%负样本时,全预测负的准确率为99%但无意义)。
3.精确率(Precision)
精确率(Precision)关注的是模型预测为正的样本中真正为正的比例(减少误报),又叫查准率,是指在被预测为正例的样本中,真正例的比例。精确率衡量了模型预测为正例的样本中有多少是真正的正例,是评估模型预测结果质量的重要指标之一。
精确率(Precision)的计算公式:
精确率越高,说明模型在预测正例时更加准确,但精确率高并不意味着模型的整体性能就很好,因为它没有考虑到模型可能漏掉的真正例。
4.召回率(Recall)
召回率(Recall)关注的是实际为正的样本中被正确预测的比例(减少漏报),又叫查全率,真正率,是指在所有实际正例样本中,被正确预测为正例的比例。它衡量了模型能够正确预测出正例样本的能力,也是评估分类模型性能的重要指标之一。
召回率(Recall)的计算公式:
召回率越高,说明模型在识别出实际为正例的样本时表现得越好,假反例的数量较少。但与精确率类似,高召回率并不一定代表模型整体性能良好,因为它没有考虑到模型可能会将负例错误地预测为正例。
5.F1值
F1值是精确率和召回率的调和平均数,其计算公式为:
F1值的取值范围为0到1,其中1表示最佳性能,0表示最差性能。当模型的精确率和召回率同时较高时,F1值也会相应较高。
6.真正率与假正率
( 1 ) 真正率(TPR):
真正率(TPR)又叫召回率(Recall),查全率,即实际为正的样本中,被模型正确预测为正的比例。TPR的值越高越好(1为最佳),其计算公式为:
( 2 ) 假正率(FPR):
假正率(FPR)是实际为负的样本中,被模型错误预测为正的比例。FPR的值越低越好(0为最佳),其计算公式为:
7.ROC曲线与AUC值
( 1 ) ROC曲线:
ROC曲线使用的指标是真正率(TPR)与假正率 ( FPR),其横坐标为FPR, 纵坐标为TPR。通过调整分类阈值,计算不同阈值下的(FPR, TPR)点,然后将各个点连接起来。
示例如下图:
( 2 ) AUC值:
AUC值是ROC曲线下方的面积,取值范围为 0.5 ~ 1,
当AUC=0.5时,模型等同于随机猜测(ROC曲线为对角线)。
当AUC=1时,完美模型(ROC曲线紧贴左上角)。
当AUC<0.5时,模型反向预测(需反转预测结果)。
8.PR曲线
PR曲线是一种二分类模型的评估工具,它以精确率(Precision)为纵轴,召回率(Recall)为横轴,描述了模型在不同阈值下的分类性能。通过调整分类阈值(如从0到1),计算每个阈值下的(Recall, Precision)点,然后连接所有点形成曲线,其越靠近右上角,模型性能越好。
示例如下图:
二、KNN分类模型评估
1.导入库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import roc_curve, auc
from sklearn.metrics import precision_recall_curve, average_precision_scorenumpy:数值计算基础库
matplotlib.pyplot:绘图库
make_classification:生成模拟分类数据集
train_test_split:划分训练集和测试集
KNeighborsClassifier:K近邻分类器
roc_curve和auc:绘制ROC曲线和计算AUC值
precision_recall_curve和average_precision_score:绘制PR曲线和计算AP值
2.图例文字显示
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False plt.rcParams["font.family"] = ["SimHei"]:设置 Matplotlib 的全局字体为 "SimHei"(黑体),确保图表中的中文(如标题、标签、图例)能正确显示,而不是乱码或方框。
plt.rcParams['axes.unicode_minus'] = False:解决保存图像时负号'-'显示为方块的问题。默认情况下,Matplotlib 使用 Unicode 的减号,但某些中文字体可能不兼容该符号。此设置会强制使用 ASCII 的负号,从而解决保存图像时负号 ' - ' 显示为方块的问题。
3.生成样本数据
使用Python的scikit-learn库中的make_classification函数来生成一个样本数量为2000,每个样本特征为20,二分类的分类数据集。
# 生成样本数据
X, y = make_classification(n_samples=2000, n_features=20, n_classes=2, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 不同的K值
k_values = [1, 4, 8]
( 1 ) make_classification函数:生成模拟分类数据
参数说明:
n_samples=2000:生成2000个样本
n_features=20:每个样本有20个特征
n_classes=2:二分类问题
random_state=42:随机种子,保证每次运行结果一致
返回值:
X:特征矩阵,形状为(2000, 20)
y:标签向量,形状为(2000,)
( 2 ) train_test_split函数:将数据集划分为训练集和测试集
参数说明:
test_size=0.2:20%的数据作为测试集,80%作为训练集
random_state=42:保证每次划分结果一致
返回值:
X_train:训练集特征(1600, 20)
X_test:测试集特征(400, 20)
y_train:训练集标签(1600,)
y_test:测试集标签(400,)
4.ROC曲线绘制
绘制不同K值的K近邻(KNN)分类器在测试集上的ROC曲线,并计算对应的AUC值。
plt.figure(figsize=(10, 8))
for k in k_values:
# 遍历k_values列表中的每个K值(1,4,8),创建对应K值的KNN分类器,并在训练集上拟合模型
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
# 获取测试集样本属于正类的概率,predict_proba返回的是每个类别的概率,[:,1]表示取正类的概率
y_score = knn.predict_proba(X_test)[:, 1]
#计算不同阈值下的假正例率(FPR)和真正例率(TPR),_的作用是充当第三个返回值,因为roc_curve函数有三个返回值
fpr, tpr, _ = roc_curve(y_test, y_score)
# 计算AUC
roc_auc = auc(fpr, tpr)
# 绘制ROC曲线
plt.plot(fpr, tpr, label='K = %d (AUC = %0.2f)' % (k, roc_auc))
plt.plot([0, 1], [0, 1], color='navy', linestyle='--') # 绘制随机分类器的对角线
plt.xlim([0.0, 1.0]) # x轴范围0-1
plt.ylim([0.0, 1.05]) # y轴范围0-1.05(留出少量空间)
plt.xlabel('假正例') # x轴标签
plt.ylabel('真正例') # y轴标签
plt.title('ROC曲线') # 图形标题
plt.legend(loc="lower right") # 图例位置在右下角
plt.grid(True) # 显示网格线
plt.show() # 显示图形
5.PR曲线绘制
绘制不同K值的K近邻(KNN)分类器在测试集上的PR曲线(精确率-召回率曲线),并计算对应的平均准确率(AP)。
plt.figure(figsize=(10, 8))
for k in k_values:
# 创建并训练KNN分类器
knn = KNeighborsClassifier(n_neighbors=k)#n_neighbors=k --> 控制分类器参数
knn.fit(X_train, y_train)
# 获取测试集样本属于正类的概率,predict_proba返回的是每个类别的概率,[:,1]表示取正类的概率
y_score = knn.predict_proba(X_test)[:, 1]
# 计算不同阈值下的精确率(Precision)和召回率(Recall)
precision, recall, _ = precision_recall_curve(y_test, y_score)
# 计算PR曲线下的面积(AP,Average Precision),AP值越接近1,模型性能越好
average_precision = average_precision_score(y_test, y_score)
# 绘制当前K值对应的PR曲线,并在图例中显示K值和对应的AP值(保留两位小数)
plt.plot(recall, precision, label='K = %d (平均准确率 = %0.2f)' % (k, average_precision))
plt.xlim([0.0, 1.0]) # x轴范围0-1
plt.ylim([0.0, 1.05]) # y轴范围0-1.05
plt.xlabel('召回率') # x轴标签
plt.ylabel('精确率') # y轴标签
plt.title('PR曲线') # 图形标题
plt.legend(loc="lower right") # 图例位置在右下角
plt.grid(True) # 显示网格线
plt.show() # 显示图形
三、实验结果
1.实验结果截图
( 1 )ROC曲线:
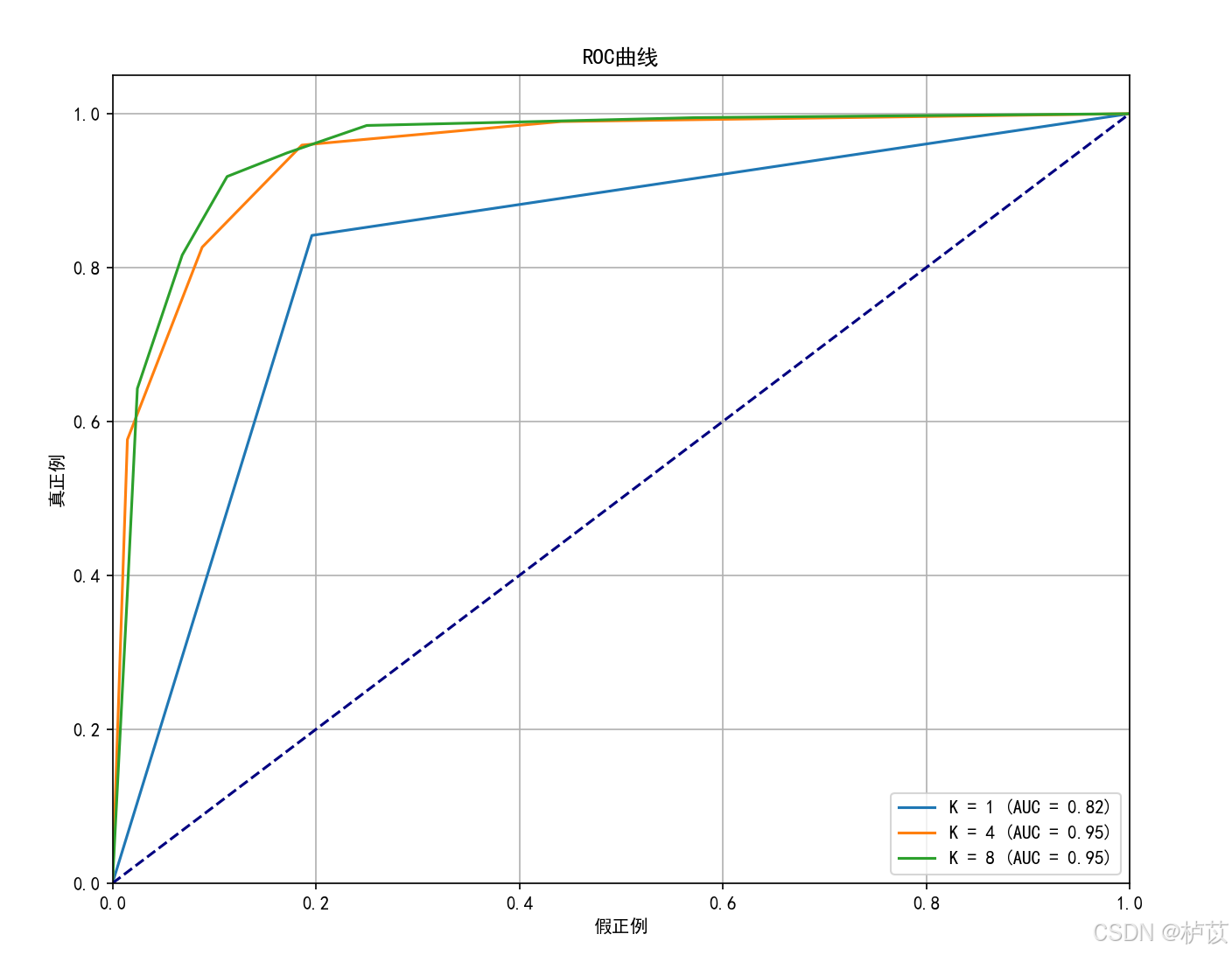
( 2 )PR曲线:
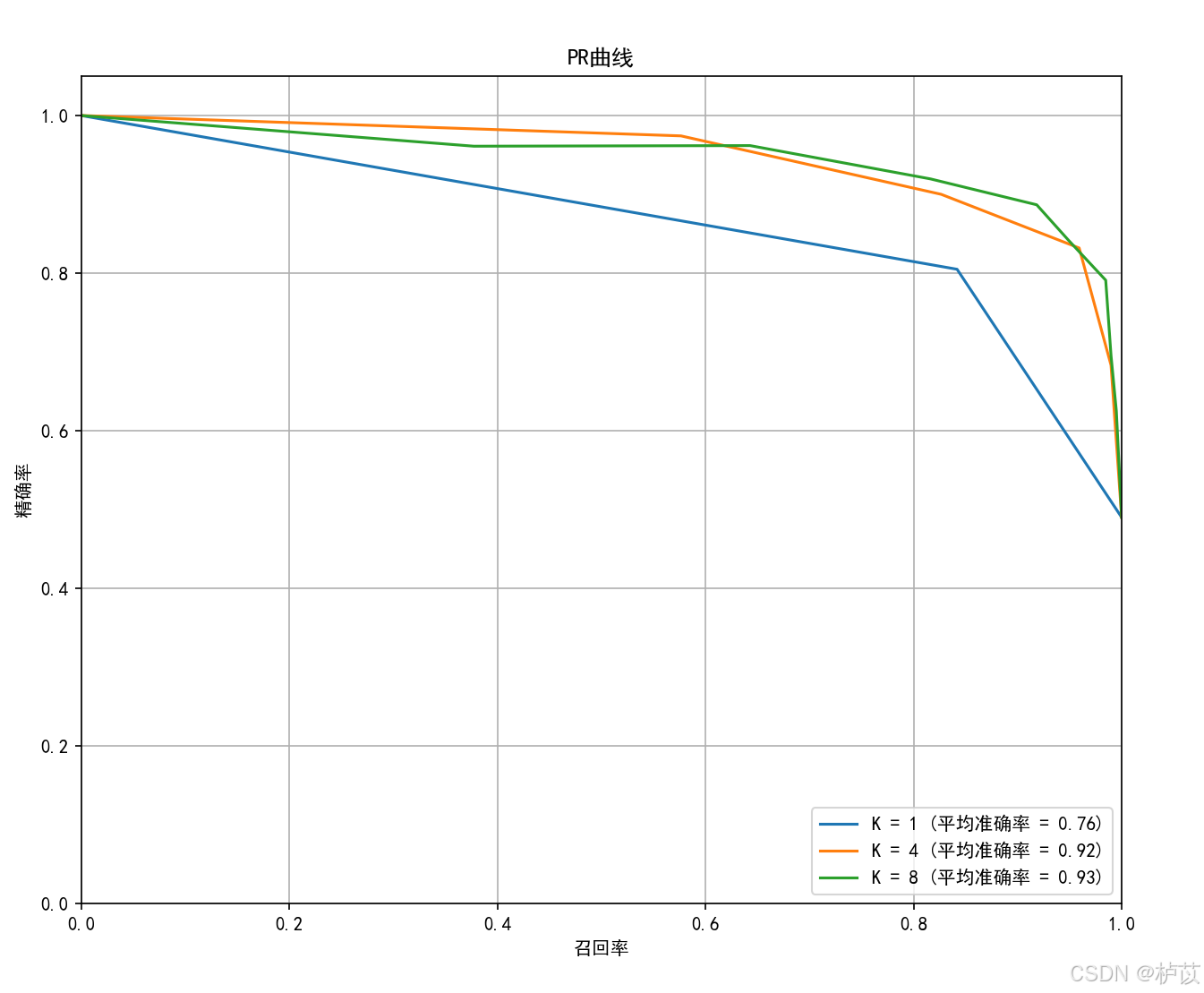
2.总结
1.通过实验,当k=8时,AUC值和平均准确率均最接近1,模型分类性能最好
2.ROC曲线描述了不同阈值下的假正率(FPR)和真正率(TPR)之间的关系。PR曲线描述了不同阈值下的召回率(Recall)和精确率(Precision)之间的关系。
3.在KNN算法中,K值的选择对模型性能有较大影响。可以通过训练不同K值的KNN模型,绘制其在测试集上的ROC曲线,并比较各个K值下的ROC曲线面积(AUC)大小。通过分析不同K值下的ROC曲线可以选择合适K值以获得最佳模型性能。
4.通过实验的学习,我们掌握了分类模型的评估方法和ROC曲线、PR曲线的应用,以及如何利用不同K值绘制和比较KNN模型的ROC曲线。些知识对于深入理解和评价机器学习模型的性能至关重要。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









