






介绍
RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。
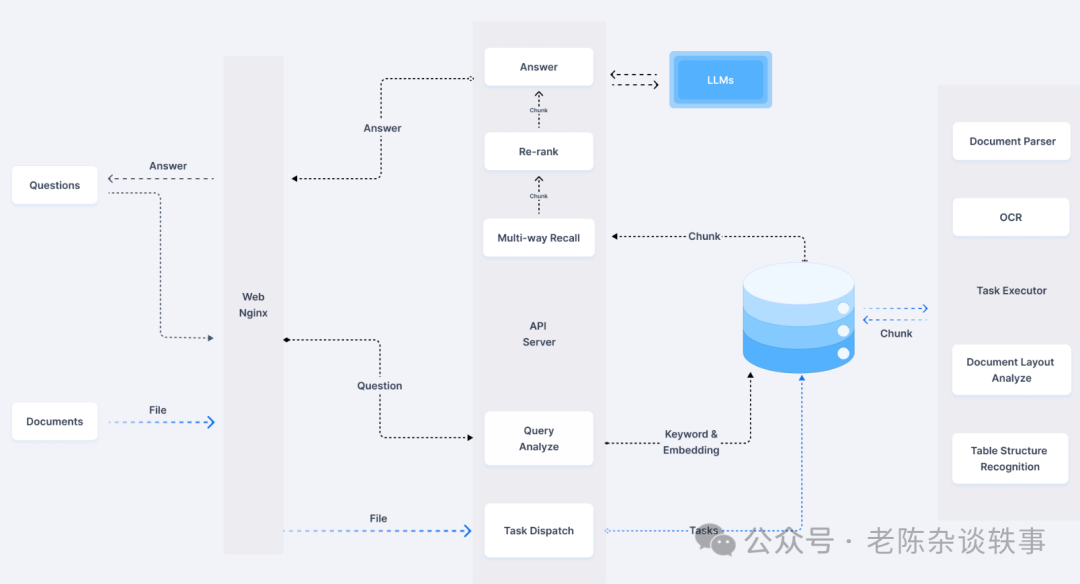
系统架构
安装
- 环境要求
CPU >= 4 cores
RAM >= 16 GB
Disk >= 50 GB
Docker >= 24.0.0 & Docker Compose >= v2.26.1
启动服务器
确保 vm.max_map_count 不小于 262144。如需确认 vm.max_map_count 的大小,服务执行:
sysctl vm.max_map_count
如果 vm.max_map_count 的值小于 262144,可以进行重置:
# 这里我们设为 262144:``sudo sysctl -w vm.max_map_count=262144
你的改动会在下次系统重启时被重置。如果希望做永久改动,还需要在 /etc/sysctl.conf 文件里把 vm.max_map_count 的值再相应更新一遍:
vm.max_map_count=262144
1.克隆仓库
git clone https://github.com/infiniflow/ragflow.git
2.修改配置
cd ragflow/docker``vi .env
- 修改配置RAGFLOW_IMAGE,我们测试安装使用包含推理模型的镜像v0.16.0,如果自己本地部署了embedding模型,我们可以选择v0.16.0-slim版本,以减少体积。
RAGFlow 镜像tag | 大小 | 是否包含推理模型 |
v0.16.0 | ≈9 | 包含 |
v0.16.0-slim | ≈2 | 不包含 |
RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0
- 修改配置RAGFLOW_IMAGE,默认的地址可能下载会比较慢,我们可以使用国内镜像源
华为云镜像名:swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow
阿里云镜像名:registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow
RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:v0.16.0
- 其他配置,.env中定义了使用的各种服务对外端口、用户名、密码,版本号以及内存限制等其他信息,如果需要修改请确保修改的配置与service_conf.yaml.template 文件中的配置保持一致。
3.启动、停止
启动:
cd ragflow/docker``docker compose -f docker-compose.yml up –d
停止:
docker compose -f docker/docker-compose.yml down –v
注意:-v 将会删除 docker 容器的 volumes,已有的数据会被清空,正常停止不要携带该参数。
5.查看服务是否正常启动
docker logs -f ragflow-server
出现以下信息,即可使用浏览器打开登陆页面

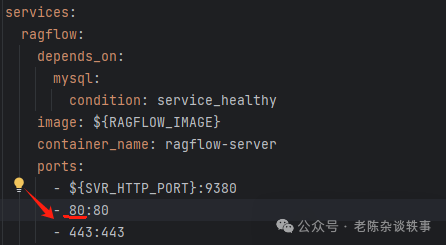
默认首页地址: http://部署机器的IP:端口 端口默认【80】具体端口参考docker-compose.ym 文件中的配置
使用
1.注册登录
填写基础信息,点击继续,进入登录页面
2.配置语言模型
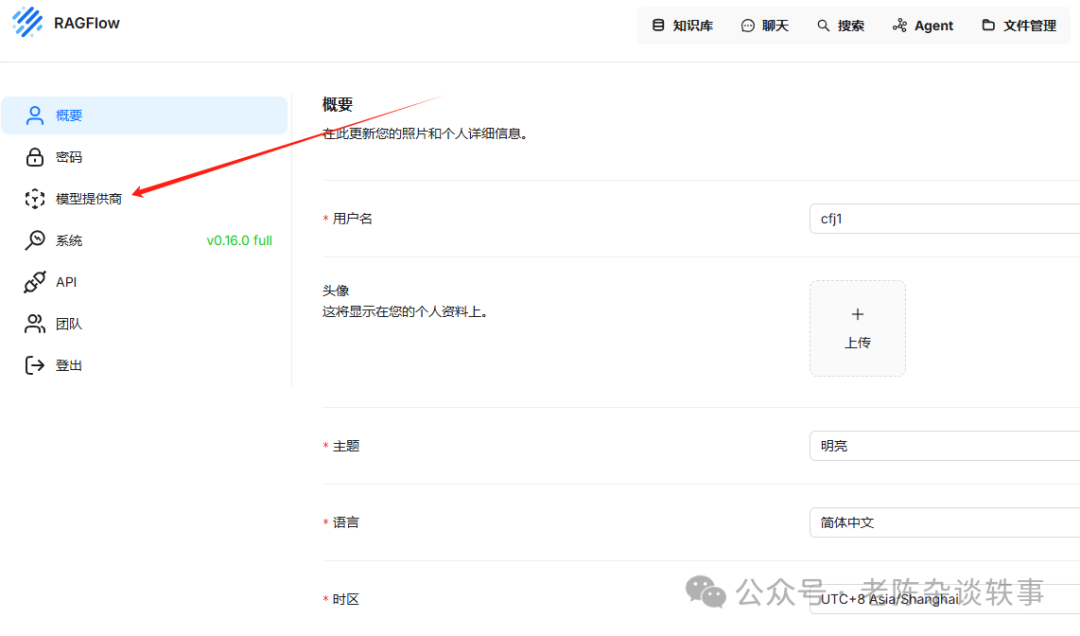
进入模型提供商页面,我们可以看到各种模型厂商信息,这里我们配置本地模型经常用到的三个类型分别是 Ollama、OpenAI-API-Compatible、LocalAI。如果是其他模型厂商官网提供的可以使用对应的厂商模型,直接配置官网提供的API-key、Base-Url即可。我这边重点说明一下本地接入三种方式的区别,用聊天补全接口作为示例,其他接口类似:
模型类型 | 请求路径 | Header中Authorization是否生效 |
Ollama | /v1 /completions | 是 |
OpenAI-API-Compatible | /v1/chat/completions | 是 |
LocalAI | /v1/chat/completions | 否 |
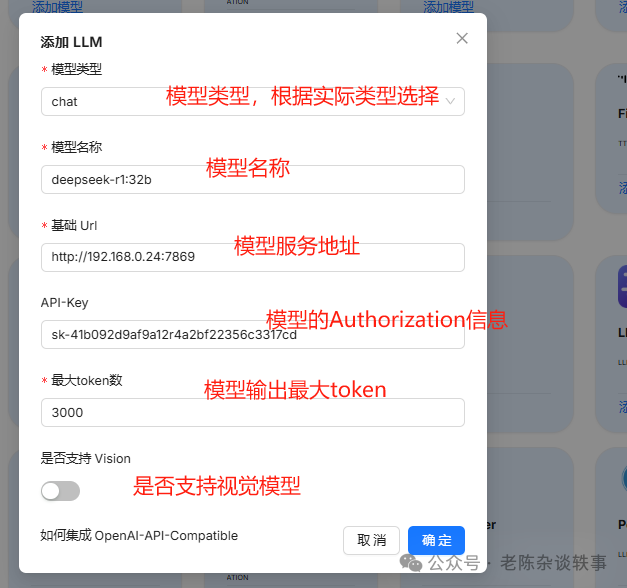
我这边的模型是符合 /v1/chat/completions 格式,并且需要校验Authorization,所以我这边选择OpenAI-API-Compatible厂商配置。配置好后点击确定。
3.创建知识库
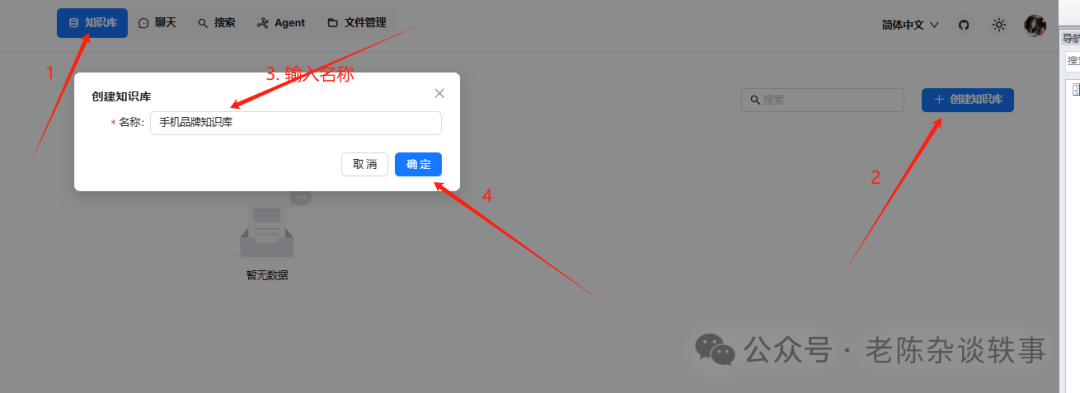
知识库配置页面,嵌入模型我们选择BAAI/bge-large-zh-v1.5即可,其他配置暂时默认,点击保存。
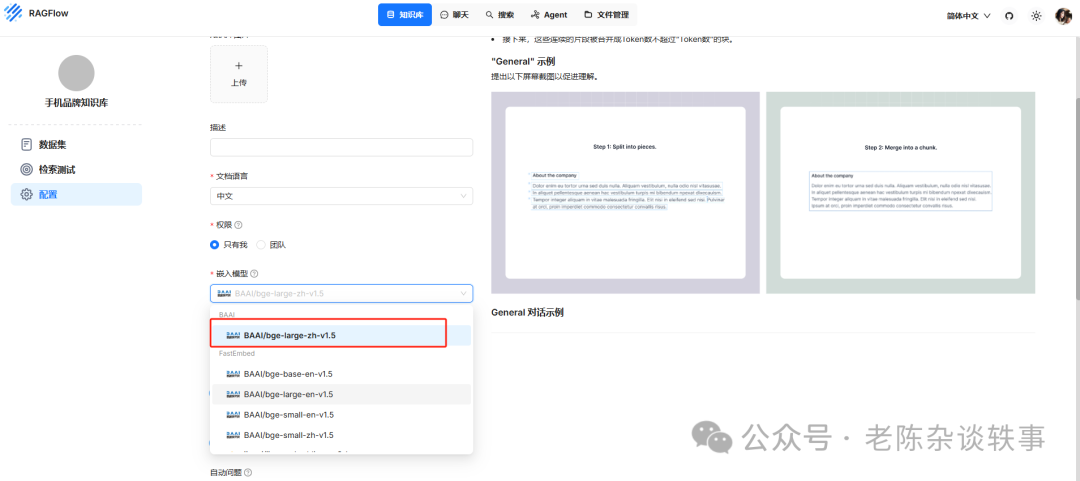
选择文件,我这边使用的word文档,然后确定。
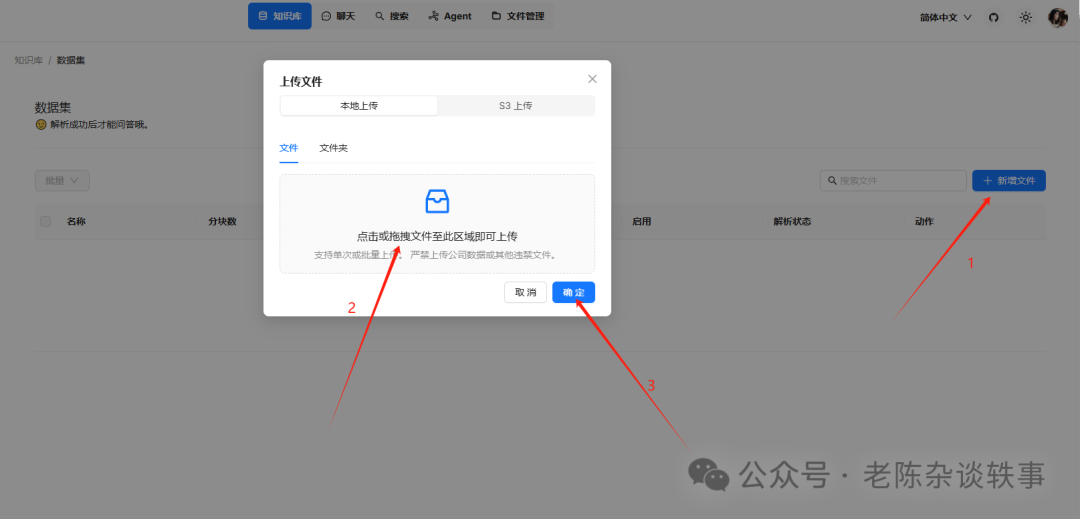
在数据集中看到我们刚刚上传的文档,我们点击这个开始解析按钮,等待解析成功
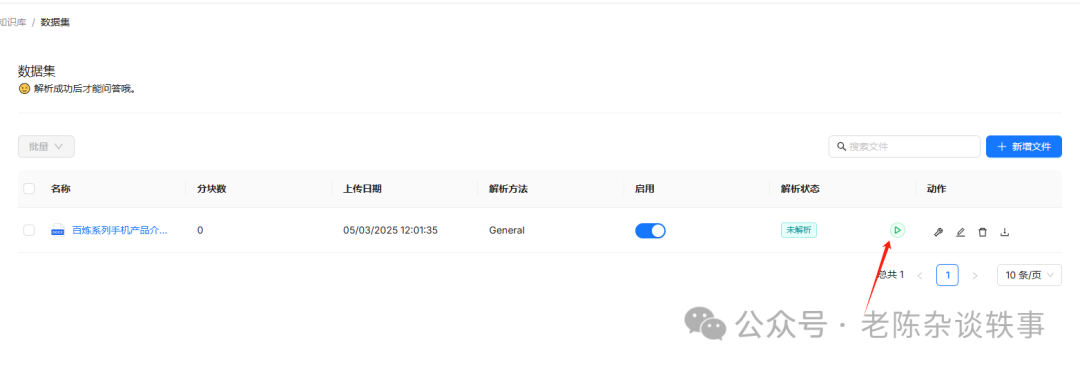
文件解析成功后,我们可以点击名称查看分块信息。我们可以禁用一些分块或者针对一些分块添加关键词增加检索匹配的能力。我这边对这个块自定义个关键词和问题,等会来测试效果。
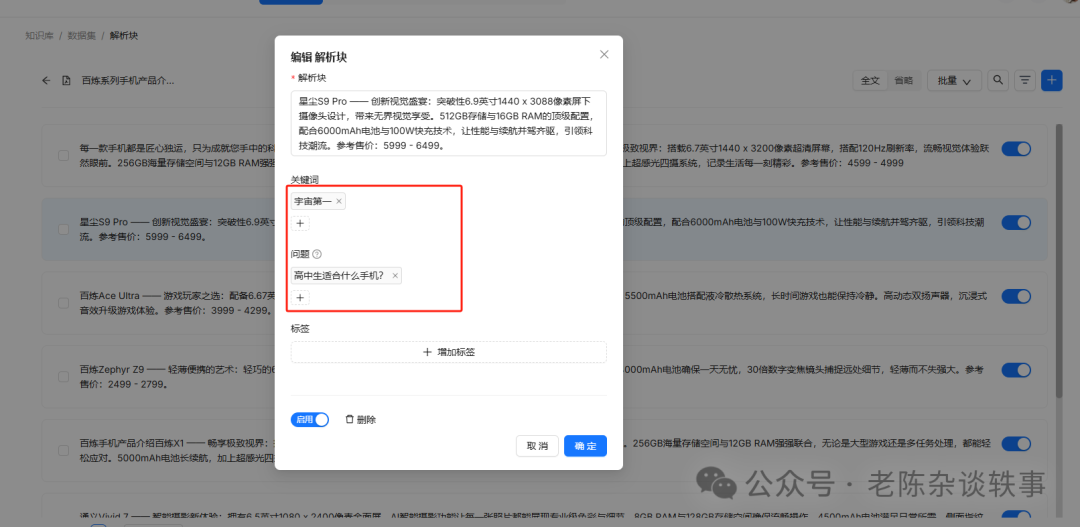
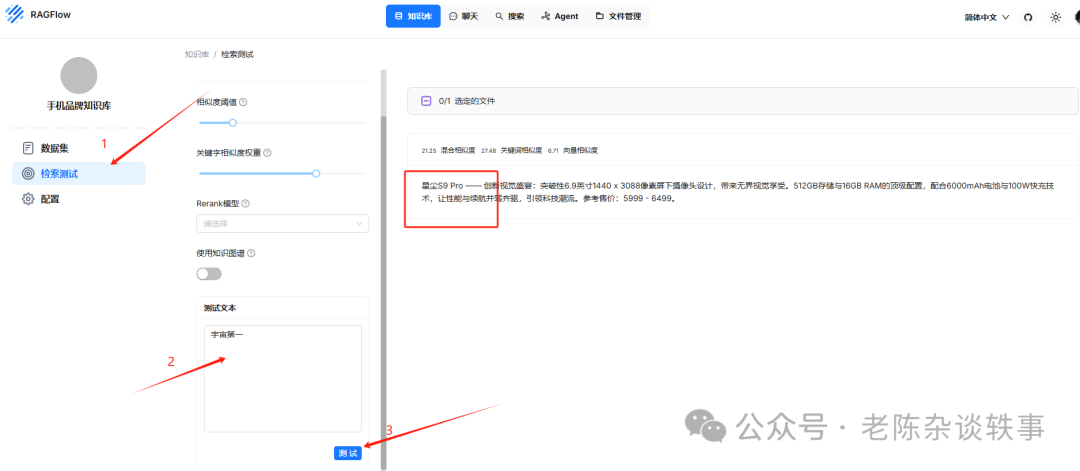
我们进行一下检索测试,在测试文本中输入我们的关键词或问题看一下检索效果,测试结果跟预期一样。
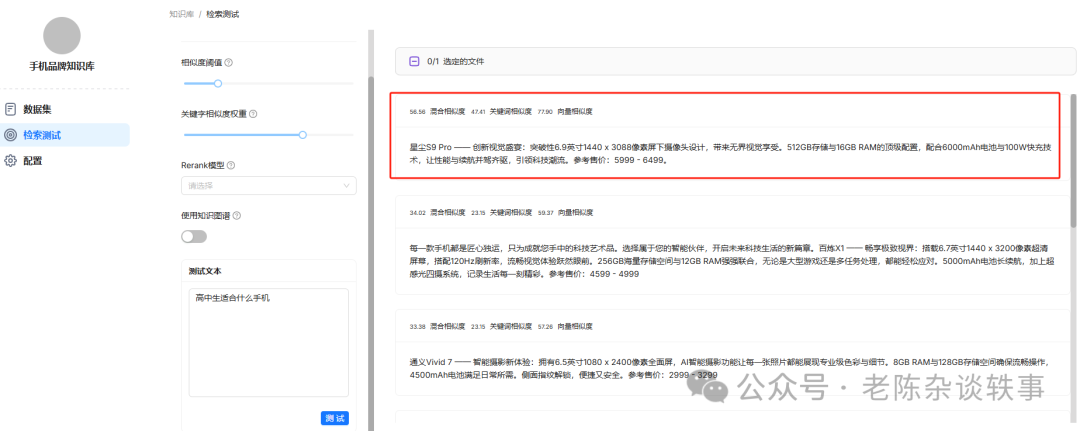
4.新建助理
注意知识库需要有文档才能在这个配置页面查看到,否则是看不见的。
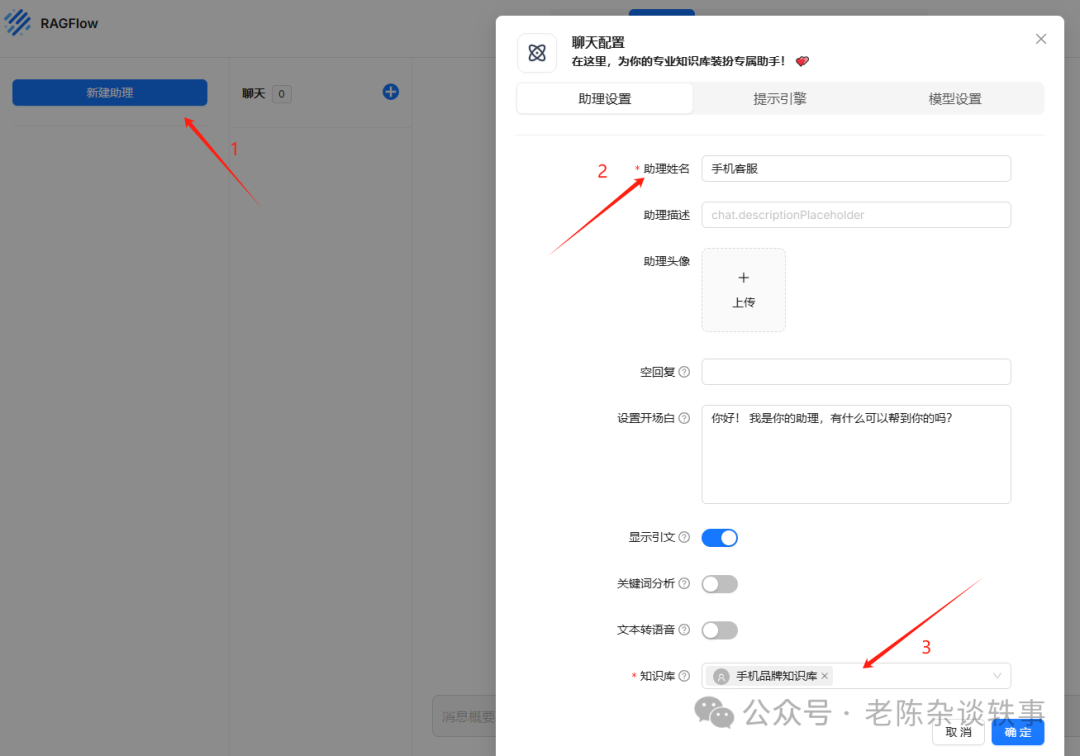
模型选择我们开始自己配置的模型,我配置的是DeepSeek,然后保存。
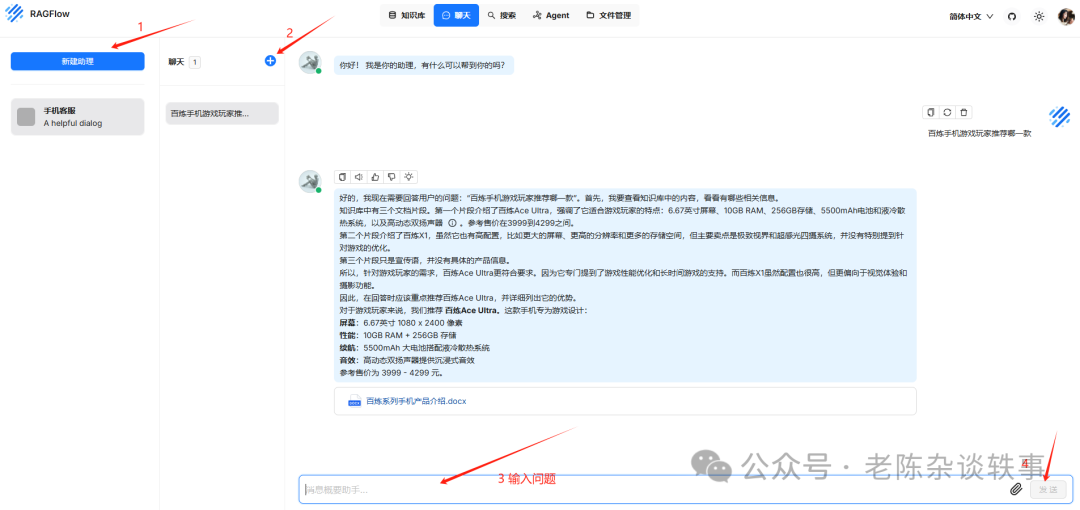
创建会话,查看知识库检索效果。我们提问问题,发现可以从知识库中检索出相关信息,并给我们相关引用信息。
其他说明
我们可以基于这个框架,然后上传我们的自己的文档,打造各种各样的私有助理,比如产品助理、医疗助理等等~~~
后续还会给大家整理更多 RAGFlow 实际使用中遇到的问题。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 5218
5218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









