






这个创造灵感还是来自监控小孩学习情况,但由于在公司开发,不方便调试,干脆监控自己的工作情况。
首先准备好照片,我是用DroidCamX这个安卓app,电脑版是个服务端,不用安装也能用。之前在家里用的是萤石摄像头,后来发现萤石摄像头是没有在本地局域网做优化的,即是,你的手机和萤石摄像头在同一个局域网,网络速度仍受外网网速影响(会上传我们的监控视频到服务器,所以影响网速)。 Pytorch+Mumu模拟器+萤石摄像头实现对小孩学习的监控_主机使用小米摄像头做深度学习-优快云博客
一、采集照片:
1.找一部旧手机,把DroidCamX app安装到手机中,打开app,得到下面界面:

在浏览器输入上面图片中的网址:得到

2.使用selenium,每隔10秒(可以自己设定)点击上面网页的“把相片保存在这里”,保存照片:
以下是代码:
# -*- coding: utf-8 -*-
"""
Created on Wed Jan 15 19:00:10 2025
@author: Ybk
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.chrome.options import Options
import time
import datetime
import os
# 设置下载路径
# 创建一个ChromeOptions对象
chrome_options = Options()
now = datetime.datetime.now()
date_str = now.strftime("%Y%m%d")
date_path = 'D:\\picdown\\' + date_str
if os.path.exists(date_path):
pass
else:
print("创建文件夹")
os.makedirs(date_path, exist_ok=True)
prefs = {"download.default_directory": date_path}
chrome_options.add_experimental_option("prefs", prefs)
driver = webdriver.Chrome(options=chrome_options)
driver.get('http://192.168.1.97:4747/override')
# 等待网页加载完成,可以根据实际情况调整等待时间
time.sleep(3)
# 无限循环,每隔10秒点击一次按钮
try:
now = datetime.datetime.now()
date_str0 = now.strftime("%Y%m%d")
while True and date_str0 == date_str:
now = datetime.datetime.now()
date_str0 = now.strftime("%Y%m%d")
button = driver.find_element(By.XPATH, '//button[contains(., "把相片保存在这里")]')
# 点击按钮
ActionChains(driver).move_to_element(button).pause(0.5).click().perform()
# 等待10秒
time.sleep(10)
except KeyboardInterrupt:
# 捕获用户中断(如Ctrl+C),以便优雅地关闭浏览器
print("Script interrupted by user. Closing browser...")
driver.quit()
上面代码将照片按日期保存到带日期名称的文件夹中。
3.整理照片,建立dataset2,里面建0,1,2的子文件夹
把采集到的照片,按屏幕前没有人、认真工作、摸鱼的情况分别移动到0,1,2的子文件夹中。
二、resnet18训练,生成torch模型。
# -*- coding: utf-8 -*-
"""
Created on Sat Dec 28 16:37:27 2024
@author: YBK
"""
import torch
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms, models
# 检查是否有可用的GPU设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义数据转换
data_transforms = transforms.Compose([
transforms.Resize((224, 224)), # ResNet模型通常接受224x224的输入
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载数据集
data_dir = 'dataset2'
image_datasets = datasets.ImageFolder(data_dir, transform=data_transforms)
# 划分数据集为训练集和验证集
train_size = int(0.8 * len(image_datasets))
val_size = len(image_datasets) - train_size
train_dataset, val_dataset = random_split(image_datasets, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=0)
val_loader = DataLoader(val_dataset, batch_size=128, shuffle=False, num_workers=0)
class_names = image_datasets.classes
import torch.nn as nn
# 加载预训练的ResNet模型(这里以ResNet18为例)
model = models.resnet18(pretrained=True)
# 修改最后的全连接层以适应6个分类
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 3)
# 将模型移动到GPU上
model = model.to(device)
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.002, momentum=0.9)
num_epochs = 50
best_acc = 90
for epoch in range(num_epochs):
# 训练阶段
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# 验证阶段
model.eval()
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_accuracy = 100 * correct / total
print(f'Epoch [{epoch+1}/{num_epochs}], Train Loss: {running_loss/len(train_loader):.4f}, Val Loss: {val_loss/len(val_loader):.4f}, Val Accuracy: {val_accuracy:.2f}%')
if val_accuracy > best_acc:
best_acc = val_accuracy
torch.save(model.state_dict(), 'best33_resnet18_model.pth')
print('Best model saved with accuracy: {:.2f}%'.format(best_acc))
torch.save(model.state_dict(), 'last33_resnet18_model.pth')训练过程:
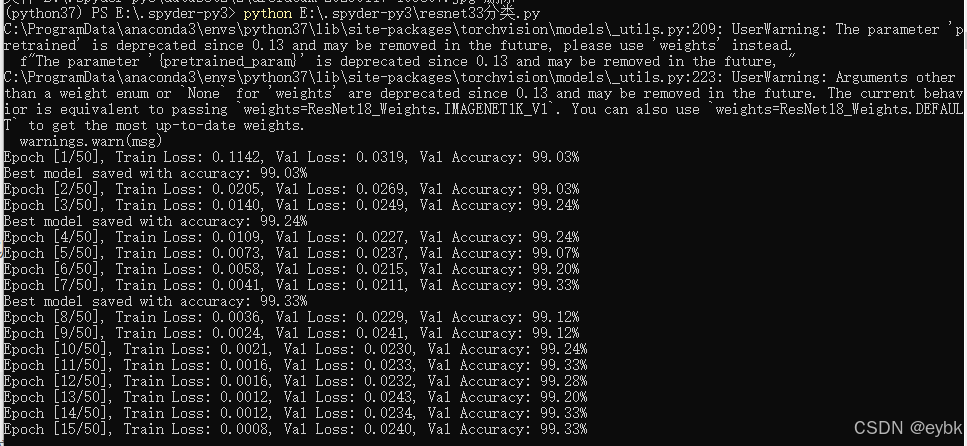
最后生成best33_resnet18_model.pth文件。
三、再检查照片优化,再训练。
因为图片比较多,所以训练的准确率不是很高,我们也不知道电脑是否能有效判断,为此,对训练的照片要再调整,再进行训练。提高准确率,我用tkinter做了这么一个小工具。
# -*- coding: utf-8 -*-
"""
Created on Tue Dec 31 16:55:22 2024
@author: YBK
"""
import tkinter as tk
from PIL import Image, ImageTk
import torch
import torch.nn as nn
from torchvision import transforms, models
import os
import shutil
import cv2
import numpy as np
# 加载模型
# 加载模型并设置为评估模式
model = models.resnet18(pretrained=False) # 假设使用的是resnet18
num_ftrs = model.fc.in_features # 获取输入特征数量
model.fc = nn.Linear(num_ftrs, 3) # 将输出特征数量改为4
model.load_state_dict(torch.load('best33_resnet18_model.pth')) # 加载模型参数
model.to('cuda' if torch.cuda.is_available() else 'cpu') # 移动到设备上
model.eval() # 设置为评估模式
# 定义预处理步骤
preprocess = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
class ImageSwitcher(tk.Tk):
def __init__(self, image_paths):
super().__init__()
self.title("图片切换、移动和删除")
# 图片路径列表和当前图片索引
self.image_paths = image_paths
self.current_index = 0
# 初始化图片变量
self.photo = None
# 创建显示图片的Label
self.image_label = tk.Label(self)
self.image_label.grid(row=0, column=0, columnspan=6)
# 显示当前图片
self.display_image()
# 创建并布局控制按钮
self.prev_button = tk.Button(self, text="上一张", command=self.show_prev_image)
self.prev_button.grid(row=1, column=0)
self.delete_button = tk.Button(self, text="删除", command=self.delete_current_image)
self.delete_button.grid(row=1, column=1)
self.t0_button = tk.Button(self, text="To无人", command=self.t0_current_image)
self.t0_button.grid(row=1, column=2)
self.t1_button = tk.Button(self, text="To认真工作", command=self.t1_current_image)
self.t1_button.grid(row=1, column=3)
self.t2_button = tk.Button(self, text="To摸鱼", command=self.t2_current_image)
self.t2_button.grid(row=1, column=4)
self.next_button = tk.Button(self, text="下一张", command=self.show_next_image)
self.next_button.grid(row=1, column=5)
self.bq_label = tk.Label(self, text="\n\n" + yc(self.image_paths[self.current_index]))
self.bq_label.grid(row=3, column=0, columnspan=6)
def display_image(self):
# 根据当前索引加载并显示图片
if self.image_paths:
image = Image.open(self.image_paths[self.current_index])
self.photo = ImageTk.PhotoImage(image)
self.image_label.config(image=self.photo)
else:
# 如果图片列表为空,则清除显示的图片
self.image_label.config(image="")
def show_prev_image(self):
# 如果不是第一张图片,则显示上一张
if self.current_index > 0:
self.current_index -= 1
self.display_image()
self.bq_label.config(text = "\n\n" + yc(self.image_paths[self.current_index]))
def show_next_image(self):
# 如果不是最后一张图片,则显示下一张
if self.current_index < len(self.image_paths) - 1:
self.current_index += 1
self.display_image()
self.bq_label.config(text = "\n\n" + yc(self.image_paths[self.current_index]))
def delete_current_image(self):
# 删除当前显示的图片,并更新图片列表和索引
if self.image_paths:
fimg = self.image_paths[self.current_index]
if os.path.exists(fimg): # 检查文件是否存在
os.remove(fimg) # 删除文件
print(f"文件 {fimg} 删除")
else:
print(f"文件 {fimg} 不存在")
del self.image_paths[self.current_index]
# 如果删除的是最后一张图片,则显示上一张(如果存在)
if self.current_index == len(self.image_paths):
self.current_index -= 1
# 更新显示的图片
self.display_image()
self.bq_label.config(text = "\n\n" + yc(self.image_paths[self.current_index]))
def t0_current_image(self):
# 删除当前显示的图片,并更新图片列表和索引
if self.image_paths:
fimg = self.image_paths[self.current_index]
todir = r'E:\.spyder-py3\dataset2\0'
shutil.move(fimg, os.path.join(todir,os.path.basename(fimg)))
del self.image_paths[self.current_index]
# 如果删除的是最后一张图片,则显示上一张(如果存在)
if self.current_index == len(self.image_paths):
self.current_index -= 1
# 更新显示的图片
self.display_image()
self.bq_label.config(text = "\n\n" + yc(self.image_paths[self.current_index]))
def t1_current_image(self):
# 删除当前显示的图片,并更新图片列表和索引
if self.image_paths:
fimg = self.image_paths[self.current_index]
todir = r'E:\.spyder-py3\dataset2\1'
shutil.move(fimg, os.path.join(todir,os.path.basename(fimg)))
del self.image_paths[self.current_index]
# 如果删除的是最后一张图片,则显示上一张(如果存在)
if self.current_index == len(self.image_paths):
self.current_index -= 1
# 更新显示的图片
self.display_image()
self.bq_label.config(text = "\n\n" + yc(self.image_paths[self.current_index]))
def t2_current_image(self):
# 删除当前显示的图片,并更新图片列表和索引
if self.image_paths:
fimg = self.image_paths[self.current_index]
todir = r'E:\.spyder-py3\dataset2\2'
shutil.move(fimg, os.path.join(todir,os.path.basename(fimg)))
del self.image_paths[self.current_index]
# 如果删除的是最后一张图片,则显示上一张(如果存在)
if self.current_index == len(self.image_paths):
self.current_index -= 1
# 更新显示的图片
self.display_image()
self.bq_label.config(text = "\n\n" + yc(self.image_paths[self.current_index]))
def yc(img_path):
result = 4
if img_path:
img = Image.open(img_path) # 加载图片
img_tensor = preprocess(img) # 预处理图片
img_tensor = img_tensor.unsqueeze(0) # 增加batch维度
img_tensor = img_tensor.to('cuda' if torch.cuda.is_available() else 'cpu') # 移动到设备上
# 进行推理
with torch.no_grad():
outputs = model(img_tensor)
_, predicted = torch.max(outputs, 1)
# 解释结果
result = int(predicted.item())
if result == 0:
res = '无人'
elif result == 1:
res = '认真工作'
elif result == 2:
res = '摸鱼玩手机等'
else:
res = '错误'
if os.path.basename(os.path.dirname(img_path)) == '0':
res0 = '放在目录为“0无人”,预测为' + res
elif os.path.basename(os.path.dirname(img_path)) == '1':
res0 = '放在目录为“1认真工作”,预测为' + res
elif os.path.basename(os.path.dirname(img_path)) == '2':
res0 = '放在目录为“2摸鱼玩手机等”,预测为' + res
return res0
def printfl(path0):
# path = r'E:\.spyder-py3\dataset'
image_list = []
for i in [0,1,2]:
print(os.path.join(path0,str(i)))
path = os.path.join(path0,str(i))
for filename in os.listdir(path):
if os.path.splitext(filename)[1].strip(".") == 'jpg':
img_path = os.path.join(path,filename)
img = Image.open(img_path) # 加载图片
img_tensor = preprocess(img) # 预处理图片
img_tensor = img_tensor.unsqueeze(0) # 增加batch维度
img_tensor = img_tensor.to('cuda' if torch.cuda.is_available() else 'cpu') # 移动到设备上
# 进行推理
with torch.no_grad():
outputs = model(img_tensor)
_, predicted = torch.max(outputs, 1)
# 解释结果
result = int(predicted.item())
if result == 0 and result != i:
# print(f'{filename}——{result}无人')
image_list.append(os.path.join(path,filename))
elif result == 1 and result != i:
# print(f'{filename}——{result}认真')
image_list.append(os.path.join(path,filename))
elif result == 2 and result != i:
# print(f'{filename}——{result}没有认真')
image_list.append(os.path.join(path,filename))
return image_list
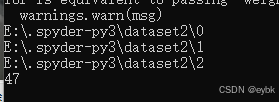
image_files = printfl(r'E:\.spyder-py3\dataset2')
print(len(image_files))
# 初始化Tkinter窗口并传入图片路径列表
app = ImageSwitcher(image_files)
app.mainloop()
运行后,找出47张,放置错误的照片,提供给你选择是否需要移动到正确位置。
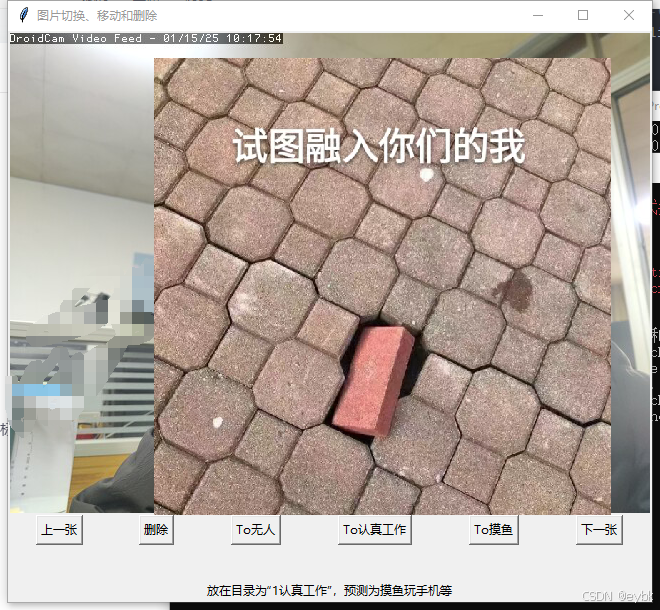
处理好图片后,再运行“二”步骤,再训练。
四、实时采集图片,分析并存入数据库
基本上,上面的模型是比较成熟了,我们可以用了实时监控自己。为了确保成果的运用,提供给老板作为绩效评价的工具,还需要将数据保存到数据库中,以便下一步的开发利用。
# -*- coding: utf-8 -*-
"""
Created on Tue Jan 14 20:03:39 2025
@author: Ybk
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.chrome.options import Options
import time
import os
import shutil
import datetime
from PIL import Image, ImageTk
import torch
import torch.nn as nn
from torchvision import transforms, models
import sqlite3
from pathlib import Path
db_filepath = Path(__file__).joinpath("../jk.db").resolve()
def insertdb(sj,furl,xl,zt,qk): #插入一行数据zt1为有人0为无人
conn = sqlite3.connect(db_filepath, timeout=10, check_same_thread=False)
c = conn.cursor()
insert_query = "INSERT INTO jkme(sj,furl,xl,zt,qk) VALUES(?,?,?,?,?);"
insert_data = (sj,furl,xl,zt,qk)
c.execute(insert_query,insert_data)
conn.commit()
c.close()
conn.close
# 加载模型
# 加载模型并设置为评估模式
model = models.resnet18(pretrained=False) # 假设使用的是resnet18
num_ftrs = model.fc.in_features # 获取输入特征数量
model.fc = nn.Linear(num_ftrs, 3) # 将输出特征数量改为4
model.load_state_dict(torch.load('best33_resnet18_model.pth')) # 加载模型参数
model.to('cuda' if torch.cuda.is_available() else 'cpu') # 移动到设备上
model.eval() # 设置为评估模式
# 定义预处理步骤
preprocess = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
def get_latest_jpg_move(directory, destination_folder):
latest_jpg = None
source_file = None
latest_mtime = -1 # 初始化为一个较小的值,确保任何文件的修改时间都会比这个大
# 使用 os.scandir() 而不是 os.listdir() 来减少内存使用并提高扫描效率
with os.scandir(directory) as it:
for entry in it:
if entry.is_file() and entry.name.lower().endswith('.jpg'):
# 直接从 entry 对象中获取修改时间,避免额外的 os.path.getmtime() 调用
mtime = entry.stat().st_mtime
if mtime > latest_mtime:
latest_mtime = mtime
latest_jpg = entry.path
if latest_jpg:
source_file = os.path.join(directory, latest_jpg)
if source_file and os.path.exists(source_file):
shutil.move(source_file, destination_folder)
print(f"文件已移动到 {destination_folder}")
else:
print("未找到源文件")
return os.path.join(destination_folder, os.path.basename(latest_jpg))
# 设置下载路径
# 创建一个ChromeOptions对象
chrome_options = Options()
tempdirectory = "E:\\picdown\\temp"
prefs = {"download.default_directory": tempdirectory}
chrome_options.add_experimental_option("prefs", prefs)
driver = webdriver.Chrome(options=chrome_options)
driver.get('http://192.168.1.97:4747/override')
# 等待网页加载完成,可以根据实际情况调整等待时间
time.sleep(3)
# 无限循环,每隔10秒点击一次按钮
try:
while True:
# 记录开始时间
start_time = time.time()
now = datetime.datetime.now()
date_str = now.strftime("%Y%m%d")
date_path = 'e:\\picdown\\' + date_str
if os.path.exists(date_path):
pass
else:
print("创建文件夹")
os.makedirs(date_path, exist_ok=True)
button = driver.find_element(By.XPATH, '//button[contains(., "把相片保存在这里")]')
# 点击按钮
ActionChains(driver).move_to_element(button).pause(0.5).click().perform()
# 等待10秒
time.sleep(3)
lpic = get_latest_jpg_move(tempdirectory, date_path)
result = 3
if lpic:
img = Image.open(lpic) # 加载图片
img_tensor = preprocess(img) # 预处理图片
img_tensor = img_tensor.unsqueeze(0) # 增加batch维度
img_tensor = img_tensor.to('cuda' if torch.cuda.is_available() else 'cpu') # 移动到设备上
# 进行推理
with torch.no_grad():
outputs = model(img_tensor)
_, predicted = torch.max(outputs, 1)
# 解释结果
result = int(predicted.item())
if result == 0:
res = '无人'
elif result == 1:
res = '认真工作'
elif result == 2:
res = '在摸鱼'
else:
res = '错误'
print(res)
if result != 3:
insertdb(now.strftime("%Y-%m-%d %H:%M:%S"),lpic,0,0,result)
# 记录结束时间
end_time = time.time()
# 计算执行时间(秒)
execution_time = end_time - start_time
print(execution_time)
time.sleep(10 - execution_time)
except KeyboardInterrupt:
# 捕获用户中断(如Ctrl+C),以便优雅地关闭浏览器
print("Script interrupted by user. Closing browser...")
driver.quit()
运行测试一下:
里面的图片自动移动到带日期的文件夹,跟“一”的代码不同,在于提取保存图片的文件名,用于后续分析。
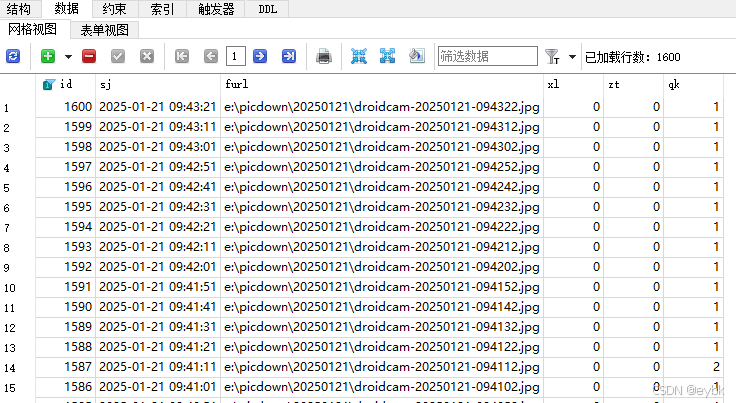
以下是有待开发利用的数据:

















 8289
8289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









