






特征融合新巅峰!AAAI25这篇文章通过把特征融合与对比学习结合,不仅性能远超SOTA,还解决了医学图像分割中的“软边界”和“共现象”两大挑战!
这是因为,特征融合能整合不同来源的特征信息;对比学习长于区分不同样本相似性、差异性。当两者结合,融合后的丰富信息,便能够使模型更准确的区分类别,从而提高性能!
因此,各顶会的审稿人都对其青眼有加!像是CVPR上准确率超99%的AVFF;NeurIPS上多模态3D目标检测的ContrastAkign……
目前与GNN、强化学习等技术结合;设计动态对比学习方法;开拓自适应融合策略等都是热门思路,伙伴们可得抓紧上车!
为方便大家研究的进行,我还给大家准备了13篇必备的参考论文和源码!
论文原文+开源代码需要的同学看文末
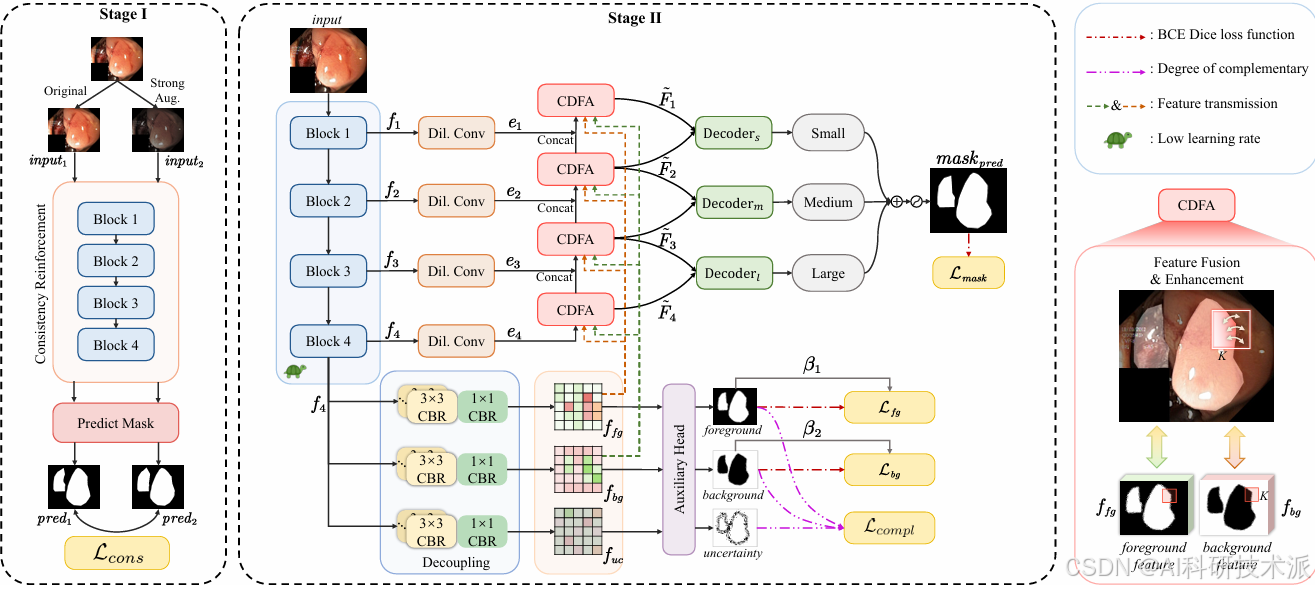
ConDSeg: A General Medical Image Segmentation Framework via Contrast-Driven Feature Enhancement
内容:这篇文章介绍了一个名为ConDSeg的通用医学图像分割框架,旨在解决医学图像中边界模糊和共现现象导致的分割挑战。它通过对比驱动的特征增强方法,提出了一致性强化训练策略来提高编码器在不同光照和对比度条件下的鲁棒性,并设计了语义信息解耦模块将特征图分解为前景、背景和不确定性区域,逐步减少不确定性。此外,对比驱动特征聚合模块利用前景和背景特征指导
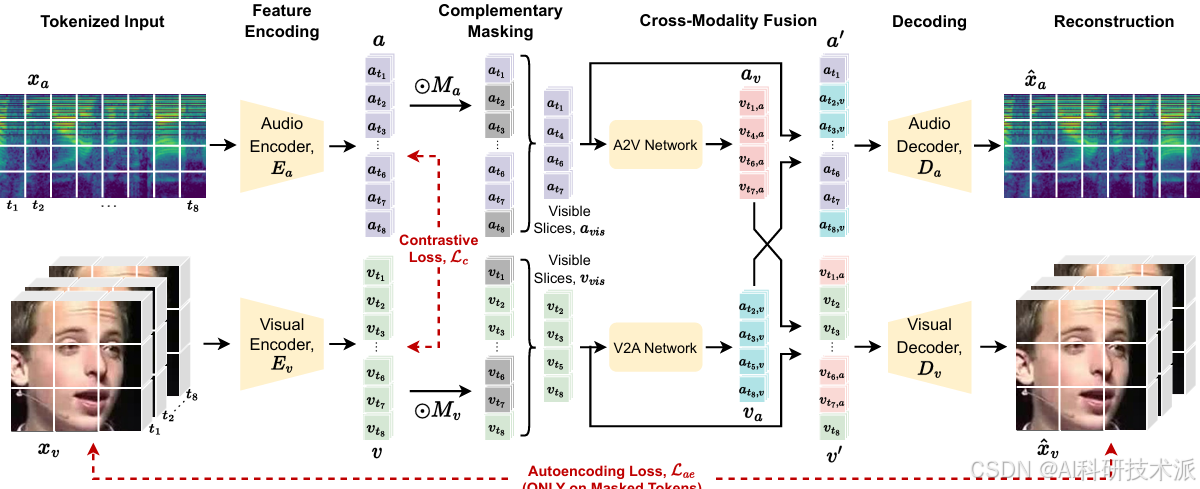
AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection
内容:这篇文章介绍了一种名为AVFF的两阶段跨模态学习方法,用于视频深度伪造检测。该方法通过自监督学习在真实视频上捕捉音频和视觉模态之间的内在对应关系,并在监督学习阶段对深度伪造视频进行分类。具体来说,AVFF在表示学习阶段使用对比学习和自编码目标,引入了一种新颖的音频-视觉互补掩码和特征融合策略,以提取丰富的跨模态表示。在分类阶段,利用这些表示来区分真实视频和深度伪造视频。实验表明,AVFF在多个基准测试中表现出色,特别是在FakeAVCeleb数据集上,达到了98.6%的准确率和99.1%的AUC,显著优于现有的音频-视觉深度伪造检测方法。
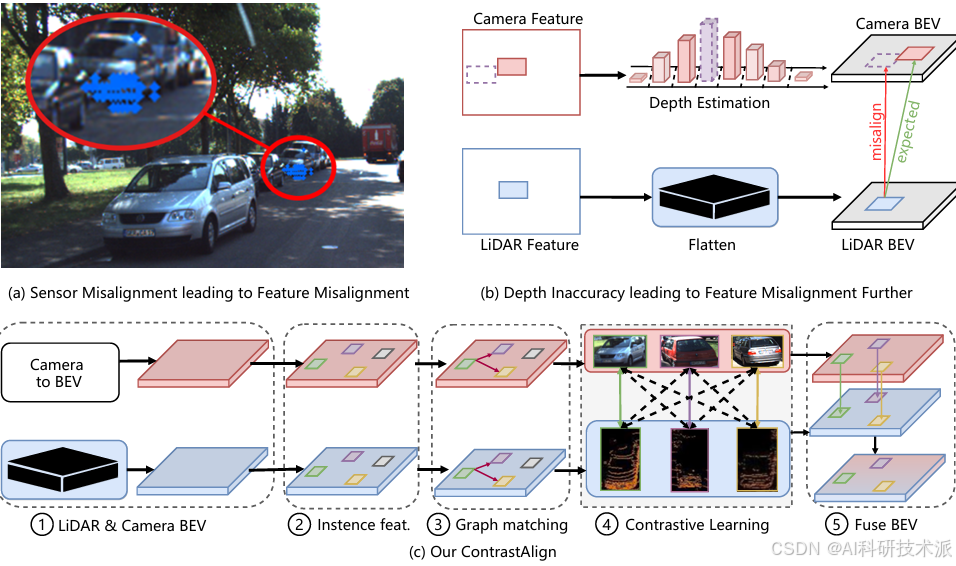
ContrastAlign: Toward Robust BEV Feature Alignment via Contrastive Learning for Multi-Modal 3D Object Detection
内容:这篇文章介绍了一种名为ContrastAlign的新型方法,旨在通过对比学习解决多模态3D目标检测中激光雷达(LiDAR)和相机特征在鸟瞰图(BEV)表示中的对齐问题。该方法通过L-Instance模块直接输出LiDAR实例特征,并通过C-Instance模块预测相机实例特征。然后,InstanceFusion模块利用对比学习生成跨异构模态的相似实例特征,并通过图匹配计算相邻相机实例特征之间的相似性,完成实例特征的对齐。
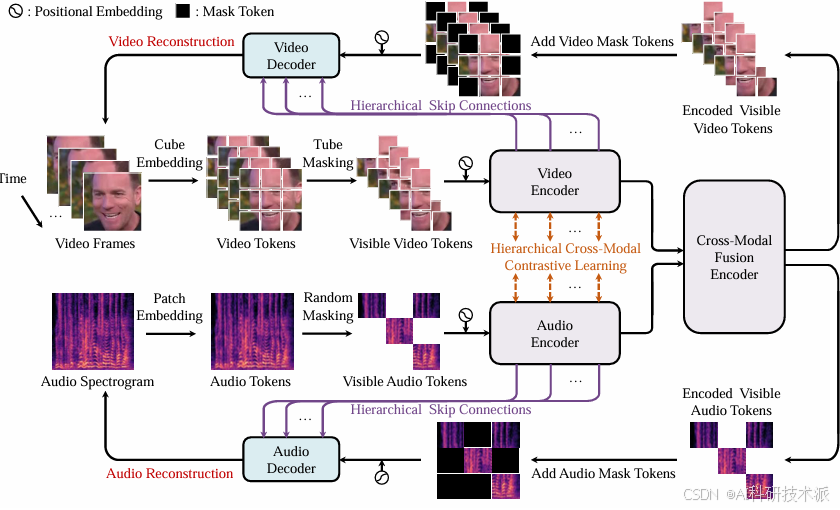
HiCMAE: Hierarchical Contrastive Masked Autoencoder for Self-Supervised Audio-Visual Emotion Recognition
内容:这篇文章提出了一种名为HiCMAE的新型自监督学习框架,用于音频-视觉情绪识别(AVER)。该框架通过大规模无监督预训练,利用对比学习和掩码数据建模两种自监督方式,促进音频和视觉模态之间的特征对齐和融合。HiCMAE通过引入层次化跳跃连接、层次化跨模态对比学习和层次化特征融合三种策略,有效地提升了音频-视觉特征学习的质量。在9个涵盖分类和连续情绪任务的数据集上进行的大量实验表明,HiCMAE显著优于现有的监督和自监督音频-视觉方法,证明了其在音频-视觉情绪表示学习方面的强大能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









