






注意力机制+多任务学习,不管在学术界还是工业界,都备受欢迎!就连DeepSeek等头部AI公司也下场研究,提出NSA等新架构。
其在提高模型处理多个相关任务时的性能和效率方面,有奇效!比如模型TADFormer便通过该方法,参数狂减840%倍!核心便在于:该结合,充分利用了注意力机制的动态权重分配特点;和多任务学习,能同时学习多个相关任务来提高模型的泛化能力的优势。
这一方面克服了传统多任务学习方法的局限;另一方面,注意力机制的引入,也把研究领域从传统的CV任务,拓展到工业控制、医学诊断等,给我们论文创新提供了诸多新场景。
为让大家能够紧跟领域前沿,找到更多idea启发,早点发出顶会,我给大家准备了14种创新思路,原文和源码都有。
论文原文+开源代码需要的同学看文末
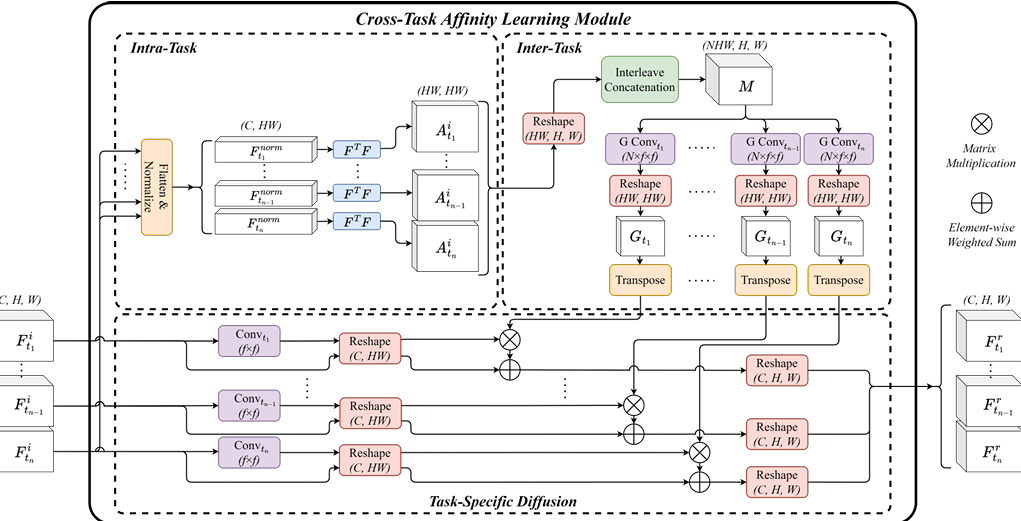
EMA-Net: Efficient Multitask Affinity Learning for Dense Scene Predictions
内容:EMA-Net是一种用于密集场景预测的高效多任务学习网络。它通过引入跨任务亲和学习(CTAL)模块,能够以参数高效的方式捕捉任务间的局部和全局交互关系。CTAL模块通过优化任务亲和矩阵,利用分组卷积来减少模型参数,同时避免信息丢失,显著提升了多任务性能。EMA-Net在使用更少参数的情况下,实现了比单任务学习更好的性能,并且适用于CNN和Transformer架构。
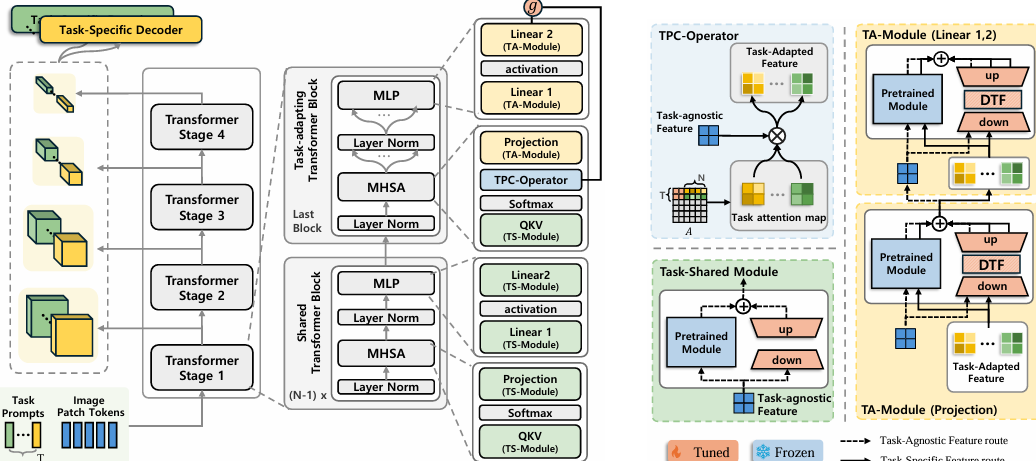
TADFormer : Task-Adaptive Dynamic TransFormer for Efficient Multi-Task Learning
内容:本文介绍了一种名为 TADFormer的新型参数高效微调(PEFT)框架,用于高效的多任务学习(MTL)。TADFormer通过动态考虑任务特定的输入上下文,以细粒度的方式进行任务感知特征适应。它提出了参数高效的提示机制用于任务适应,并引入动态任务滤波器(DTF)来捕捉基于输入上下文的任务信息。实验表明,TADFormer在PASCAL-Context基准测试中实现了更高的密集场景理解任务精度,同时将可训练参数数量减少了高达8.4倍,相比现有的PEFT方法具有更高的参数效率和准确性。
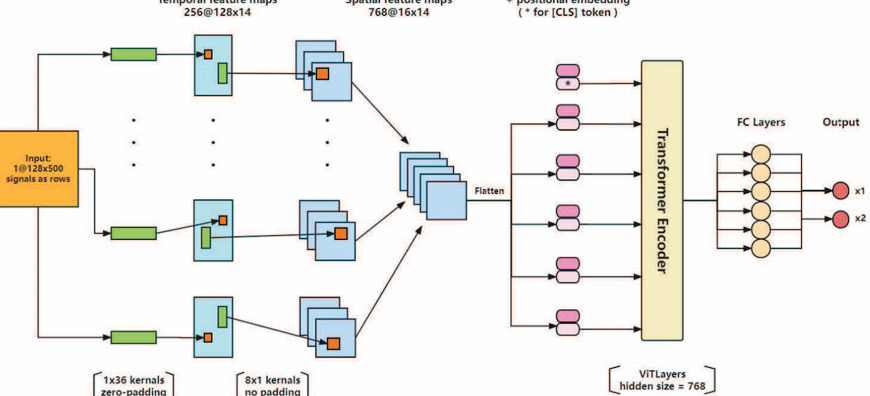
Enhancing Eye-Tracking Performance through Multi-Task Learning Transformer
内容:本文提出了一种基于多任务学习框架的创新方法,通过引入EEG信号重建子模块来增强深度学习模型在EEG眼动追踪任务中的性能。该子模块可以在多种基于编码器-分类器的深度学习模型中集成,并在多任务学习框架内进行端到端训练。实验结果表明,该方法显著提升了特征表示能力,将均方根误差(RMSE)降低至54.1毫米,优于现有方法。此外,该子模块在主任务下作为子任务运行,无需预训练,具有更高的灵活性和适应性。
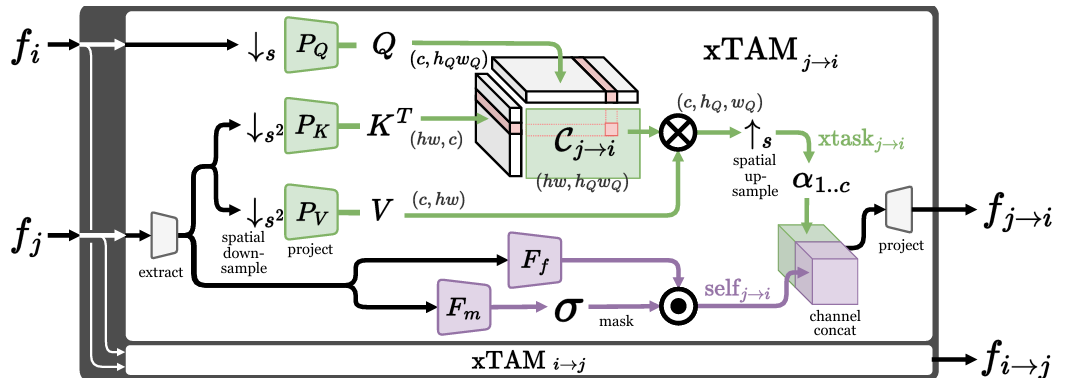
Cross-task Attention Mechanism for Dense Multi-task Learning
内容:本文提出了一种用于密集多任务学习的跨任务注意力机制,旨在通过相关性引导的注意力和自注意力机制增强不同任务之间的信息交流。作者设计了一个多任务学习框架,联合处理语义分割、密集深度估计、表面法线估计和边缘估计等任务,并通过多任务交换块(Multi-Task Exchange Block, mTEB)实现任务间的特征交互。实验表明,该方法在多个基准数据集上优于现有的多任务学习基线,并在多任务无监督领域自适应(MTL-UDA)场景中展现出优势。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【注意多任务】获取完整论文
👇


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









