






今天给大家推荐一个小白也能快速产出高区论文的方向:多模态特征融合!
一方面,其能够把不同来来源、不同形式的数据(图像、文本、视频……)特征进行整和,在提高准确性和鲁棒性方面举足轻重。且在医疗诊断、情感分析、自动驾驶、金融等热门领域,都有广泛应用,可发挥空间很大!
另一方面,其自带创新基因!像是数据对齐、跨模态检索、联合表征学习等每个方向,我们都能裂变出多个创新点。更为特别的是,其利用现有的模型通过微创新,就能发论文!
因此,其在各大顶会的录用率都在不断提升,光是NeurIPS24就有多篇!比如在视觉定位任务中性能和效率都远超SOTA的SimVG。为方便大家研究的进行,我给大家准备了14种创新思路和源码,一起来看!
论文原文+开源代码需要的同学看文末
SimVG: ASimple Framework for Visual Grounding with Decoupled Multi-modal Fusion
内容:提出了一种简单而高效的视觉定位(Visual Grounding)框架SimVG,通过解耦多模态特征融合与下游任务,利用现有的多模态预训练模型来增强跨模态理解能力。该框架引入了动态权重平衡蒸馏(DWBD)方法,通过动态调整权重来优化多分支学习过程,同时简化了模型结构,仅需一个轻量级MLP层即可完成任务。在多个视觉定位数据集上的实验表明,SimVG不仅性能优异,还提高了效率和收敛速度
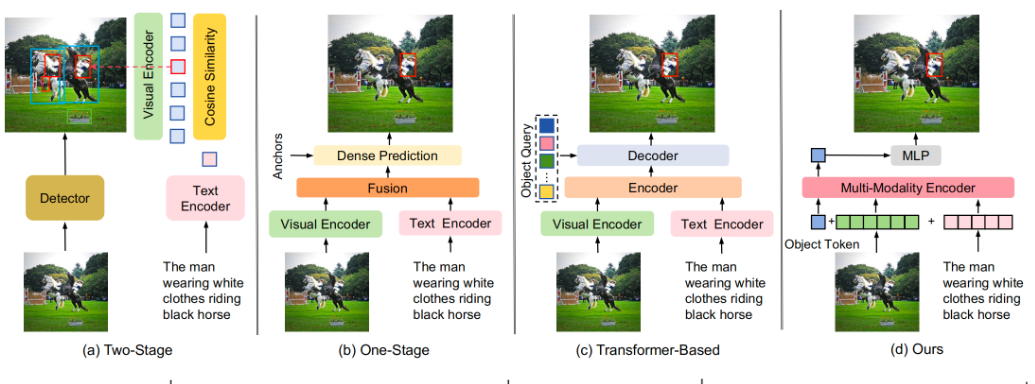
Multimodal Inverse Attention Network with Intrinsic Discriminant Feature Exploitation for Fake News Detection
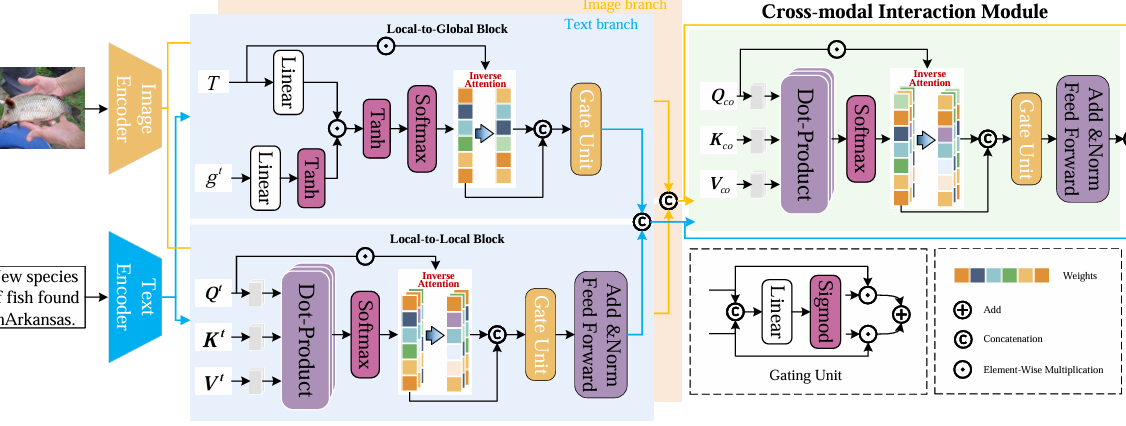
内容:这篇论文提出了一种名为 Multimodal Inverse Attention Network (MIAN) 的新型多模态假新闻检测框架。该框架通过层次化学习模块和跨模态交互模块,分别增强单模态特征和融合多模态特征,并引入逆向注意力机制来显式提取模态内和模态间的不一致性特征。实验结果表明,MIAN在多个基准数据集上显著优于现有方法,能够有效识别各种类型的假新闻,为提升社交媒体信息真实性提供了新的技术手段。
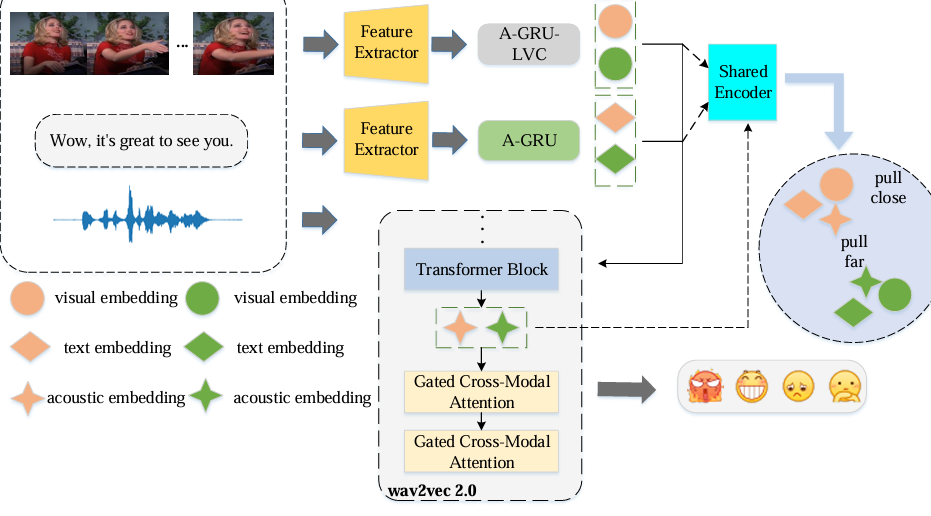
WavFusion: Towards wav2vec 2.0 Multimodal Speech Emotion Recognition
内容:这篇论文提出了一个名为 WavFusion 的多模态语音情感识别框架,旨在通过改进多模态融合技术来提升情感识别的准确性。WavFusion 结合了 wav2vec 2.0 的预训练音频特征,并引入了门控跨模态注意力机制和多模态同质特征差异学习,以动态融合音频、文本和视觉模态的信息。实验结果表明,WavFusion 在 IEMOCAP 和 MELD 两个基准数据集上均优于现有的最先进方法,证明了其在多模态语音情感识别中的有效性。
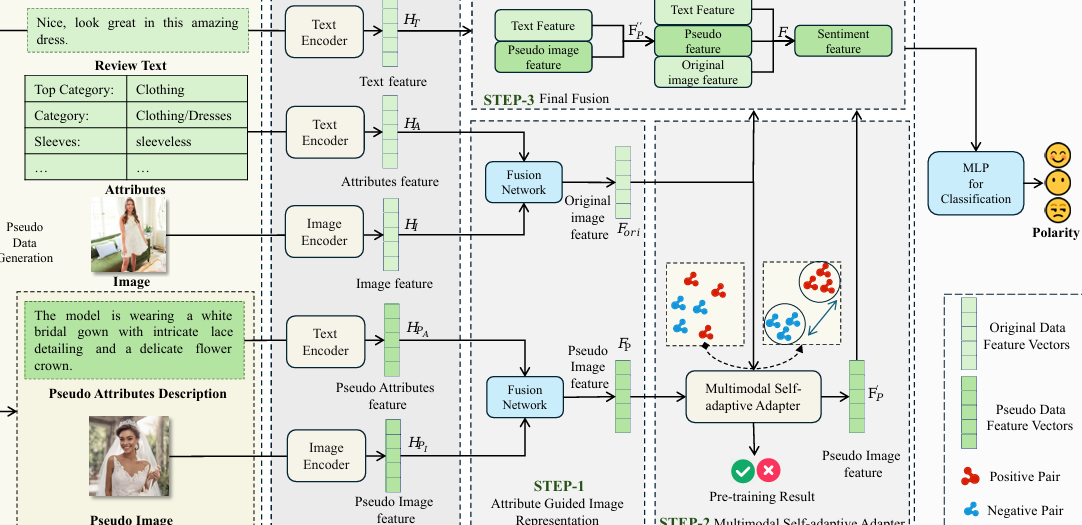
Bridging Modality Gap for Effective Multimodal Sentiment Analysis in Fashion-related Social Media
内容:本文提出了一种用于时尚相关社交媒体的多模态情感分析框架,旨在弥合文本和图像之间的模态差距。该框架通过两阶段生成伪数据来增强模态间的融合,并利用多模态融合方法高效整合不同模态的信息,从而实现对时尚帖子情感分类的准确预测。实验结果表明,该框架在综合数据集上的表现显著优于现有的单模态和多模态基线方法。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【多模特融】获取完整论文
👇


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









