






DeepSeek有多火、效果有多好,自不必多说!而这其中核心技术之一,便是模型蒸馏!相信未来该方向也必然迎来新一轮的火爆,想发论文的伙伴不要错过。
其主旨在于把将一个复杂的大型模型,也即“教师模型”的知识,迁移到一个较小、更简单的模型中,实现低计算复杂度和高性能兼备。且大多CV任务、大模型、语音识别等领域都能用。在CVPR、NeurIPS等顶会也不乏其身影!
目前好发论文的方向主要有:设计更有效的蒸馏算法、选择合适的蒸馏策略(像是动态蒸馏等)、结合其他技术提高模型效率和性能(比如多模态、自监督学习)……
为让大家能够获得更多灵感启发,早点发出自己的顶会,我给大家准备了9篇必读论文,原文和源码都有,一起来看!
论文原文+开源代码需要的同学看文末
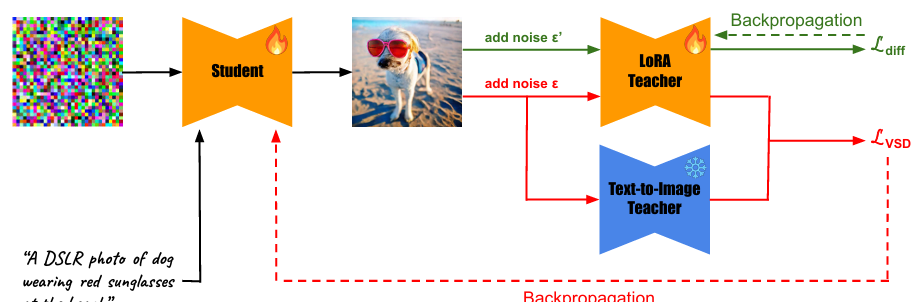
SwiftBrush:One-StepText-to-ImageDiffusionModel withVariationalScoreDistillation
内容:本文介绍了一种名为SwiftBrush的一步式文本到图像扩散模型,通过变分分数蒸馏技术,能够将预训练的多步文本到图像模型蒸馏到一个学生网络中,仅需单次推理步骤即可生成高质量图像。SwiftBrush无需任何训练图像数据,仅依赖文本提示即可实现高效的图像生成。该方法在COCO-30K基准测试中取得了16.67的FID分数和0.29的CLIP分数,显著优于现有的蒸馏技术,并且是首次在不使用任何训练图像的情况下实现如此高质量的一步式图像生成。SwiftBrush的提出为文本到图像生成的加速和简化训练过程提供了新的思路,推动了该领域的发展。
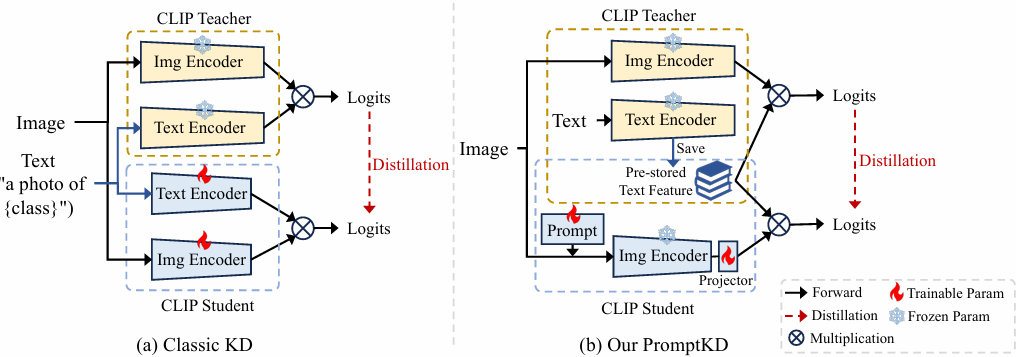
PromptKD: Unsupervised Prompt Distillation for Vision-Language Models
内容:本文提出了一种名为PromptKD的无监督提示蒸馏框架,用于将大型视觉-语言模型(如CLIP)的知识迁移到轻量级目标模型中。该框架通过提示驱动的模仿学习,利用未标记的领域图像进行蒸馏。具体而言,PromptKD包含两个阶段:首先在少量标记数据上预训练大型CLIP教师模型,然后利用CLIP的独特解耦模态特性,将教师文本编码器生成的文本特征作为类别向量保存并共享给学生图像编码器,以计算预测的logits。接着通过KL散度对齐教师和学生的logits,促使学生图像编码器通过可学习的提示生成与教师相似的概率分布。
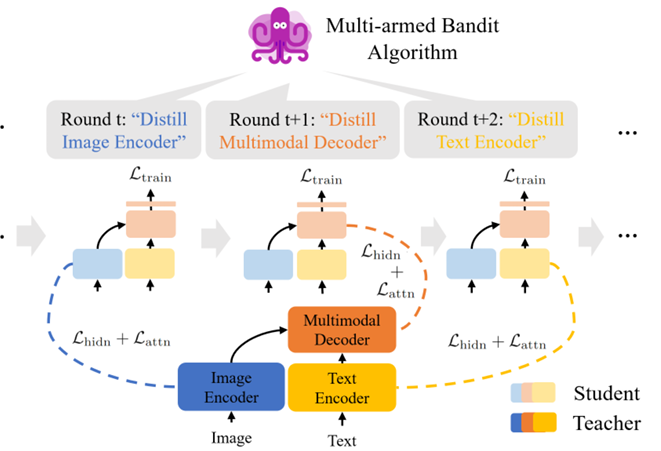
Module-wise Adaptive Distillation for Multimodality Foundation Models
内容:本文提出了一种名为Module-wise Adaptive Distillation for Multimodality Foundation Models的方法,旨在通过模块化的自适应蒸馏技术来压缩大型多模态基础模型。这些预训练的多模态模型虽然具有出色的泛化能力,但由于其庞大的参数规模,给实际部署带来了挑战。为此,研究者们采用了一种分层蒸馏的方法,即通过训练小型的学生模型来匹配大型教师模型在每一层的隐藏表示
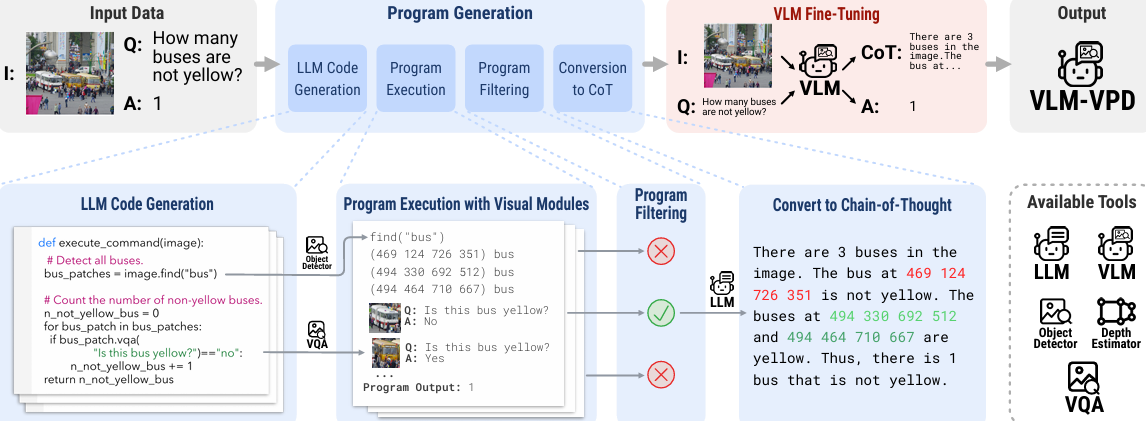
Visual Program Distillation: Distilling Tools and Programmatic Reasoning into Vision-Language Models
内容:本文介绍了一种名为VPD的方法,用于将大型语言模型(LLM)的推理能力和视觉工具的技能蒸馏到视觉-语言模型(VLM)中。VPD通过生成多个候选程序,执行并验证这些程序以找到正确的答案,然后将正确的程序转换为自然语言的推理步骤,并将其蒸馏到VLM中。这种方法使得VLM能够在单次前向传播中解决复杂的视觉任务,显著提高了VLM在视觉问答(VQA)、计数、空间关系理解和综合推理等任务上的性能,并在多个基准测试中达到了新的最高水平。此外,VPD还通过人类评估确认了其在提高模型回答的事实性和一致性方面的有效性。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【模型蒸馏】获取完整论文
👇


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









