




目录
一、为什么要使用缓存
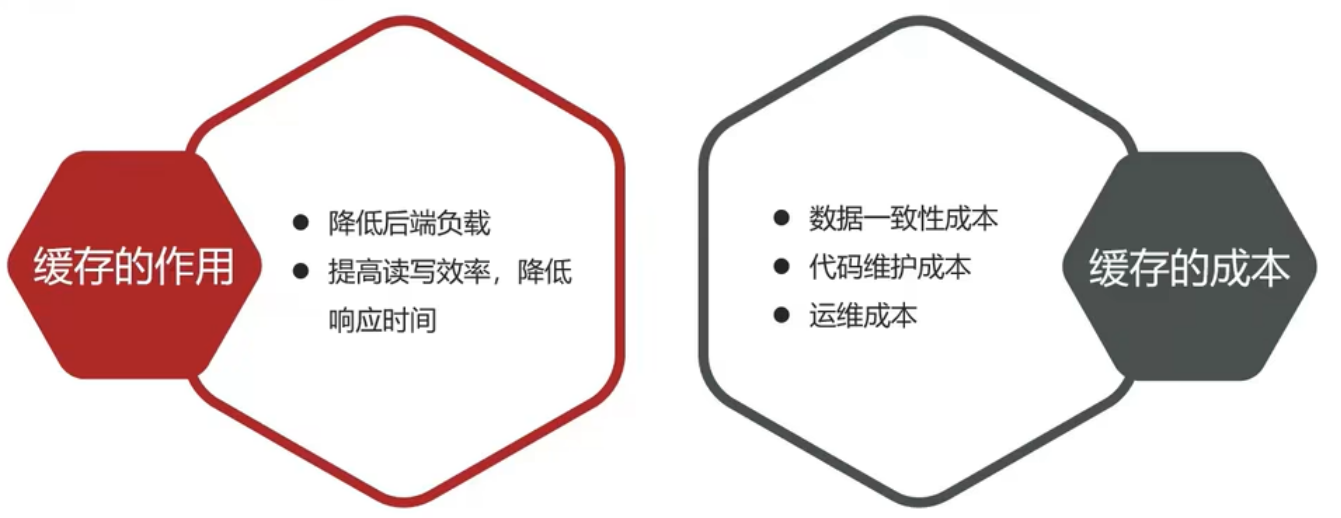
一句话:因为速度快,好用
缓存数据存储于代码中,而代码运行在内存中,内存的读写性能远高于磁盘,缓存可以大大降低**用户访问并发量带来的**服务器读写压力
实际开发过程中,企业的数据量,少则几十万,多则几千万,这么大数据量,如果没有缓存来作为"避震器",系统是几乎撑不住的,所以企业会大量运用到缓存技术;
但是缓存也会增加代码复杂度和运营的成本:
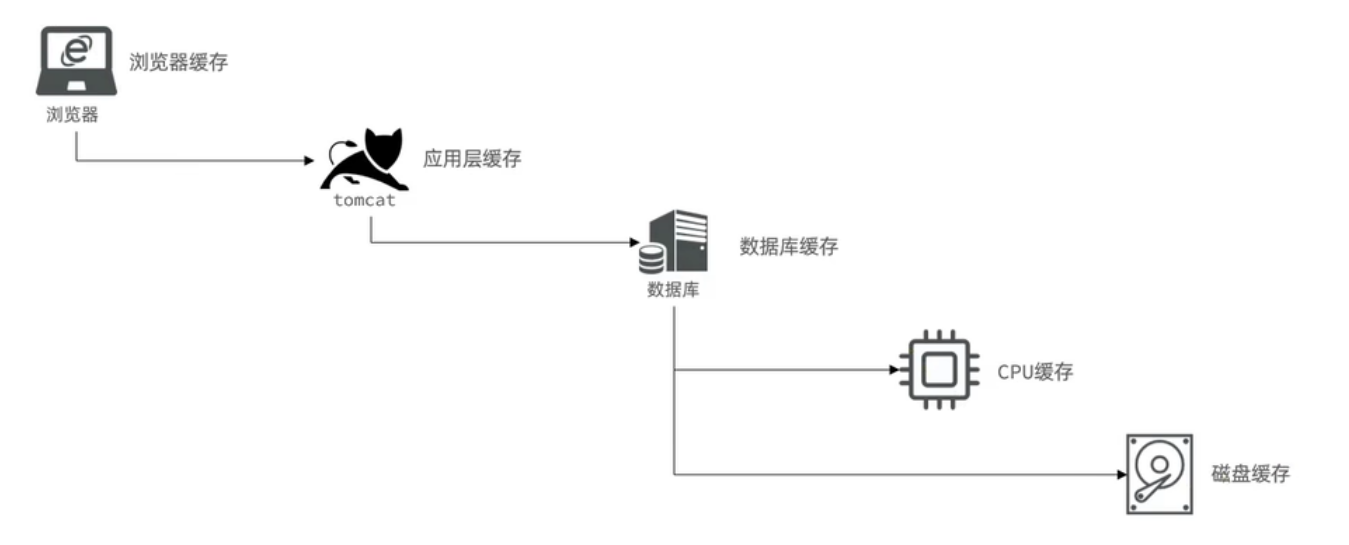
实际开发中,会构筑多级缓存来使系统运行速度进一步提升,例如:本地缓存与redis中的缓存并发使用
浏览器缓存:主要是存在于浏览器端的缓存
应用层缓存:可以分为tomcat本地缓存,比如之前提到的map,或者是使用redis作为缓存
数据库缓存:在数据库中有一片空间是 buffer pool,增改查数据都会先加载到mysql的缓存中
CPU缓存:当代计算机最大的问题是 cpu性能提升了,但内存读写速度没有跟上,所以为了适应当下的情况,增加了cpu的L1,L2,L3级的缓存
二、添加商户缓存
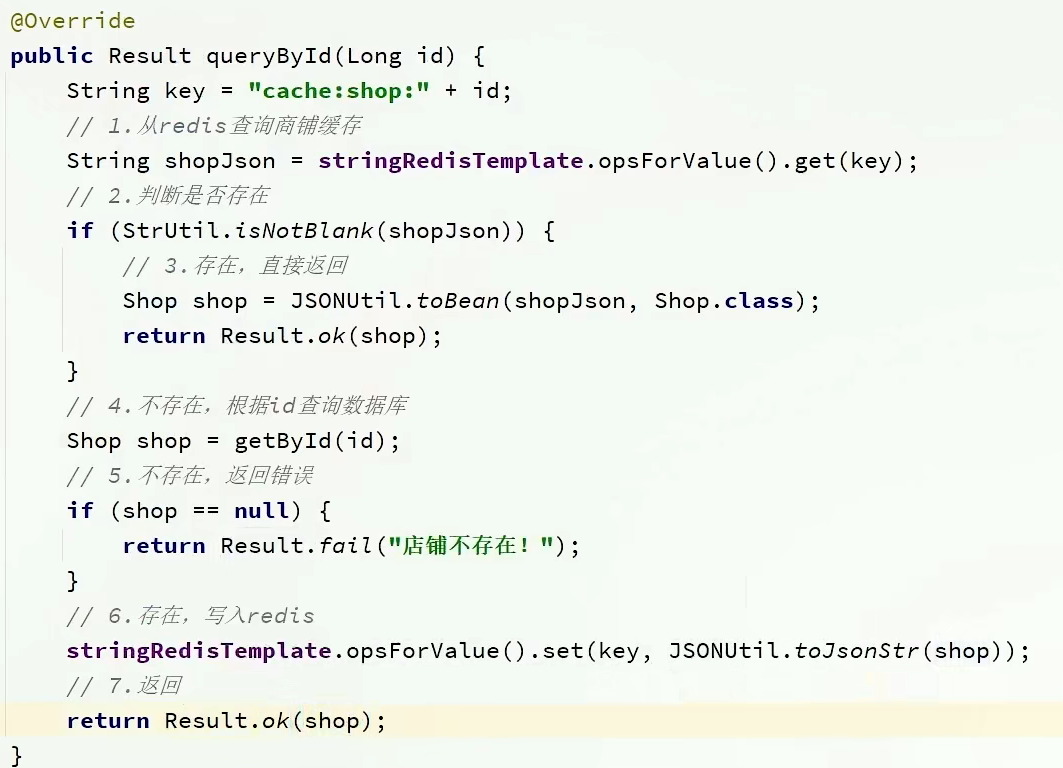
在我们查询商户信息时,我们是直接操作从数据库中去进行查询的,大致逻辑是这样,直接查询数据库那肯定慢咯,所以我们需要增加缓存
@GetMapping("/{id}")
public Result queryShopById(@PathVariable("id") Long id) {
//这里是直接查询数据库
return shopService.queryById(id);
}1.缓存的模型和思路
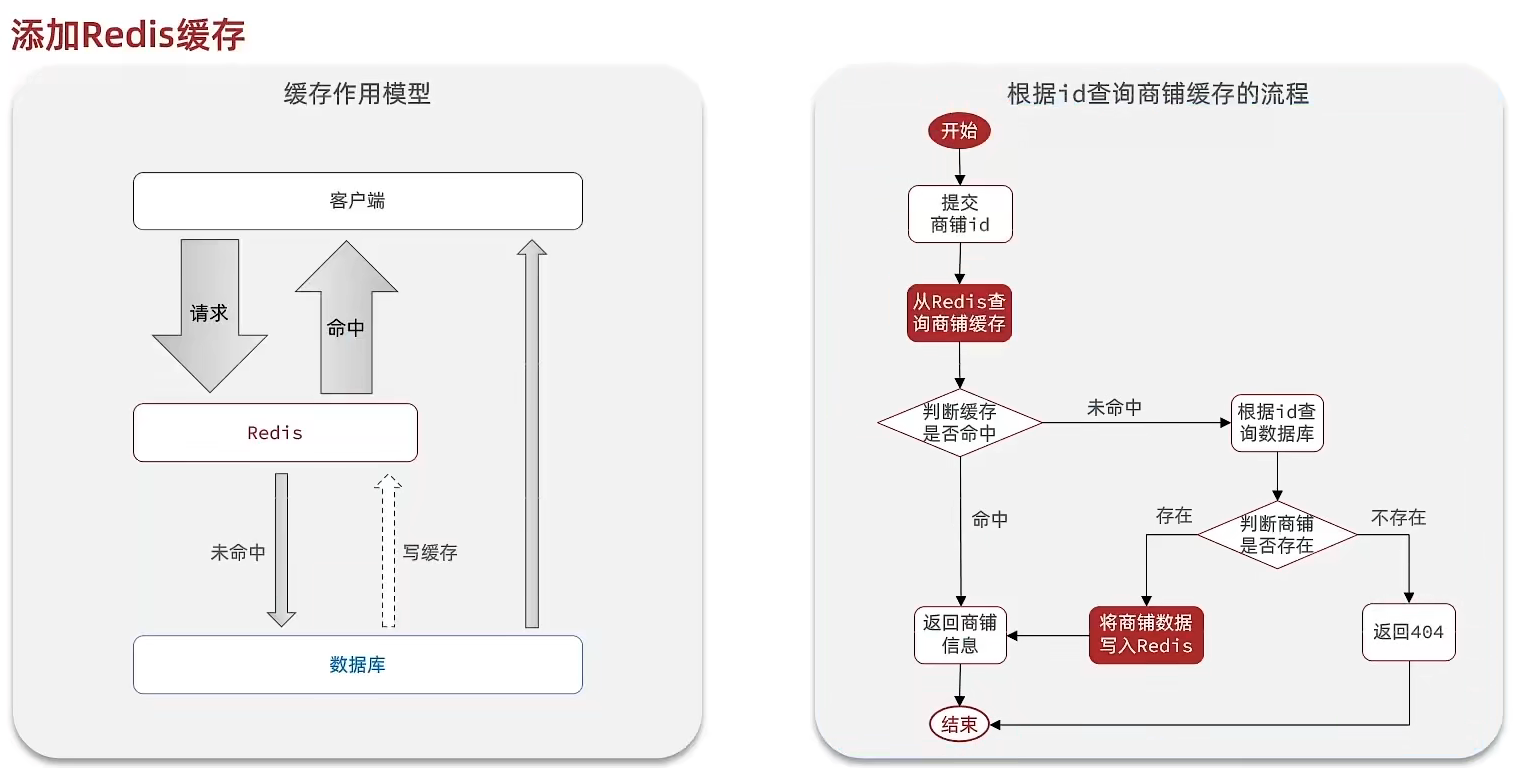
标准的操作方式就是查询数据库之前先查询缓存,如果缓存数据存在,则直接从缓存中返回,如果缓存数据不存在,再查询数据库,然后将数据存入redis。
2.代码
代码思路:如果缓存有,则直接返回,如果缓存不存在,则查询数据库,然后存入redis。
3.缓存更新策略
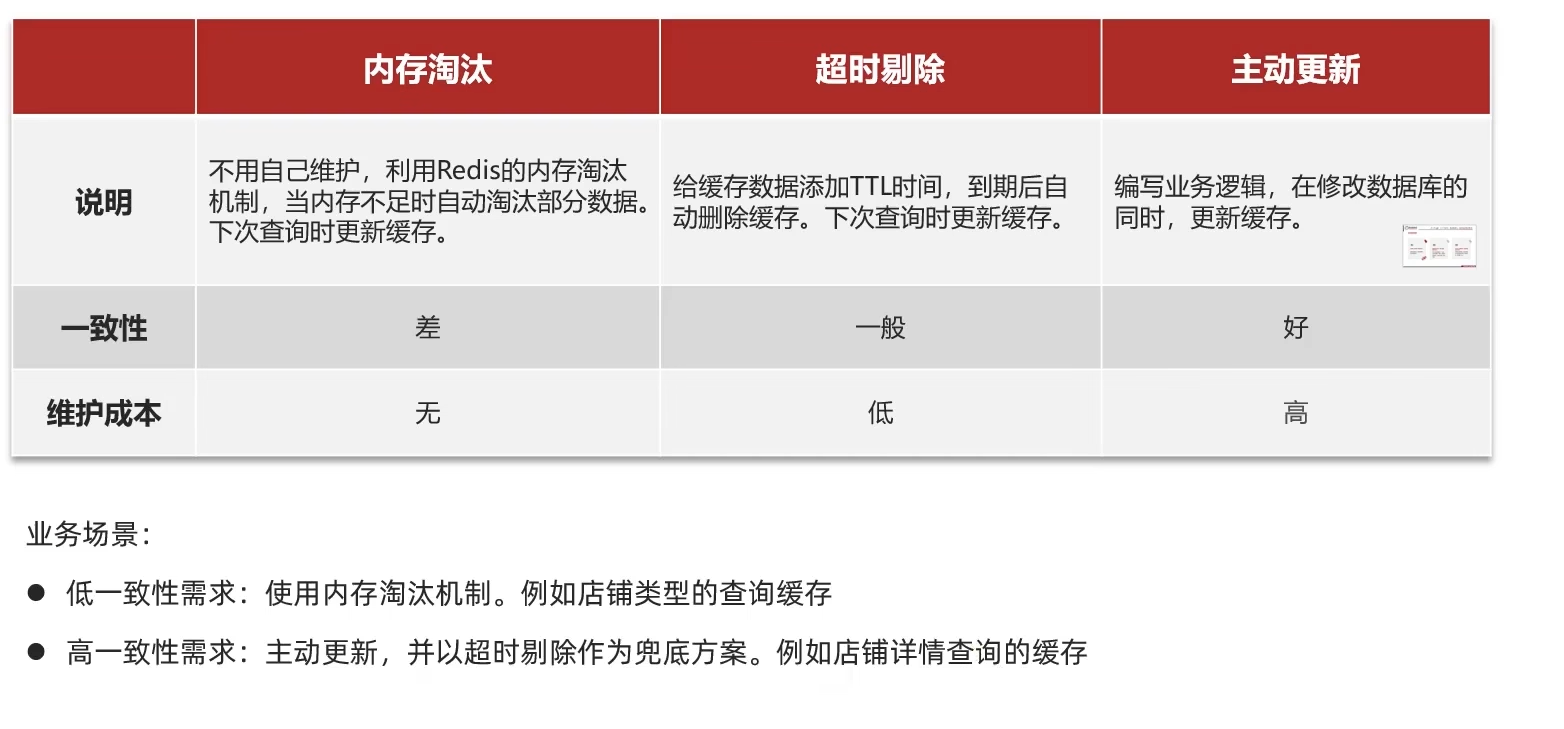
Redis内存淘汰机制:
Redis 内存淘汰策略
│
├─ 被动淘汰策略(noeviction)
│ └─ 机制:内存不足时拒绝写操作,读操作正常
│ └─ 适用:不允许数据丢失的场景
│
└─ 主动淘汰策略
│
├─ 基于过期时间(仅淘汰设置过期时间的键)
│ │
│ ├─ volatile-lru
│ │ └─ 机制:淘汰过期键中最久未使用的数据
│ │ └─ 适用:热点数据缓存
│ │
│ ├─ volatile-ttl
│ │ └─ 机制:淘汰过期键中剩余时间最短的数据
│ │ └─ 适用:时效性强的数据(如限时活动)
│ │
│ └─ volatile-random
│ └─ 机制:随机淘汰过期键
│ └─ 适用:数据访问无规律的场景
│
└─ 基于数据热度/大小(淘汰所有键)
│
├─ allkeys-lru
│ └─ 机制:淘汰所有键中最久未使用的数据
│ └─ 适用:通用缓存场景(热点数据优先)
│
├─ allkeys-random
│ └─ 机制:随机淘汰所有键
│ └─ 适用:性能优先、访问无规律的场景
│
├─ allkeys-lfu
│ └─ 机制:淘汰所有键中访问频率最低的数据
│ └─ 适用:长期高频访问数据(如常用功能缓存)
│
└─ volatile-lfu
└─ 机制:淘汰过期键中访问频率最低的数据
└─ 适用:需保留高频访问的过期数据场景Redis 提供了 8 种内存淘汰策略,可分为被动淘汰和主动淘汰两类:
3.1 被动淘汰策略(不主动淘汰,仅在查询时触发)
- noeviction(默认策略)
- 机制:当内存不足时,拒绝执行所有会导致内存增加的命令(如 set、lpush 等),但读命令(如 get)仍可正常执行。
应用场景:适用于不允许丢失数据的场景(如缓存与数据库强一致的场景),但需确保业务能处理写失败的情况。
3.2 主动淘汰策略(主动扫描内存,按规则淘汰数据)
主动淘汰策略又分为基于过期时间和基于数据热度 / 大小两类:
①基于过期时间的淘汰策略
此类策略仅淘汰设置了过期时间的键,适合缓存场景:
volatile-lru(Least Recently Used)
- 机制:在过期键中,淘汰最长时间未被访问的键。
- 原理:通过维护 “最近使用” 顺序,淘汰不活跃数据,适合热点数据场景(如用户行为缓存)。
- 示例:电商首页商品缓存,频繁访问的商品保留,冷门商品被淘汰。
volatile-ttl
- 机制:在过期键中,优先淘汰剩余过期时间最短的键。
- 原理:根据 TTL(Time To Live)值判断,适合对时效性要求高的数据(如限时活动缓存)。
- 示例:秒杀活动倒计时缓存,剩余时间短的先淘汰。
volatile-random
- 机制:在过期键中随机淘汰数据。
- 特点:实现简单但缺乏针对性,适用于数据访问无明显规律的场景。
②基于数据热度 / 大小的淘汰策略
此类策略对所有键(无论是否设置过期时间)生效:
allkeys-lru
- 机制:在所有键中,淘汰最长时间未被访问的键。
- 应用场景:最常用的策略之一,适合缓存场景(如热点文章、用户会话缓存),能有效保留活跃数据。
- 优化:Redis 通过 “近似 LRU” 算法(采样少量数据而非全量扫描)平衡性能与准确性。
allkeys-random
- 机制:在所有键中随机淘汰数据。
- 特点:性能开销小,但可能淘汰活跃数据,适用于数据访问无规律且对缓存命中率要求不高的场景。
volatile-lfu(Least Frequently Used)
- 机制:在过期键中,淘汰访问频率最低的键。
- 原理:通过记录访问次数区分 “偶然访问” 和 “高频访问” 数据,避免 LRU 淘汰高频但近期未访问的键。
- 示例:新闻类应用中,高频访问的热点新闻即使近期未被访问也会被保留。
allkeys-lfu
- 机制:在所有键中,淘汰访问频率最低的键。
- 应用场景:适合长期保留高频访问数据,例如用户高频使用的功能缓存。
| 策略 | 淘汰范围 | 淘汰依据 | 适用场景 | 命中率 | 性能开销 |
|---|---|---|---|---|---|
| noeviction | 所有键 | 不淘汰,拒绝写操作 | 不允许数据丢失的场景 | 无 | 低 |
| allkeys-lru | 所有键 | 最近最少使用 | 通用缓存场景(热点数据明显) | 高 | 中 |
| volatile-lru | 过期键 | 最近最少使用 | 仅缓存过期数据的场景 | 高 | 中 |
| allkeys-lfu | 所有键 | 访问频率最低 | 长期高频访问数据的场景 | 最高 | 高 |
| volatile-ttl | 过期键 | 剩余过期时间最短 | 时效性强的数据(如限时活动) | 中 | 低 |
| random 策略 | 对应范围键 | 随机 | 数据访问无规律或性能优先的场景 | 低 | 低 |
Redis 过期删除策略
Redis 作为内存型数据库,需要高效处理过期键的删除,避免无效数据占用内存。其过期删除策略采用被动删除 + 主动删除的混合模式,平衡内存占用与 CPU 开销:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1191
1191




 到【灌水乐园】发言
到【灌水乐园】发言









