







alert是一个单独的模块,需要单独配置,需要声明邮箱地址。配置以configmap进行配置,altermanager用pod部署在k8s集群中
prometheus监控告警实验
1、设置发送告警邮箱授权码

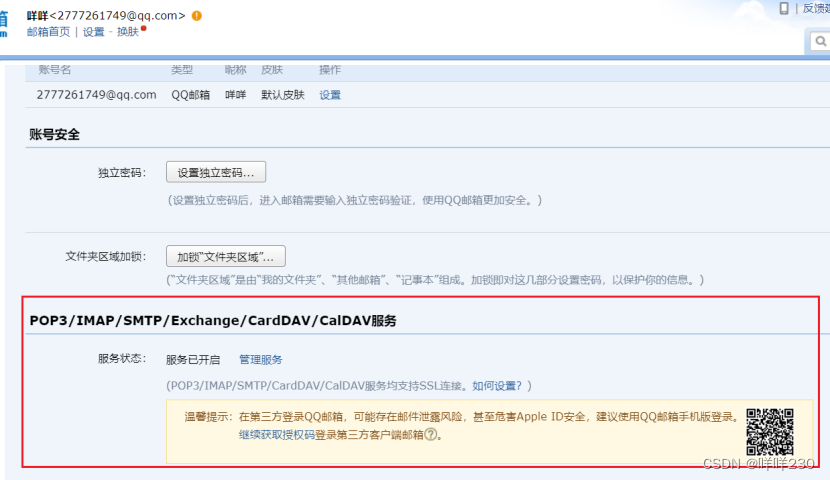
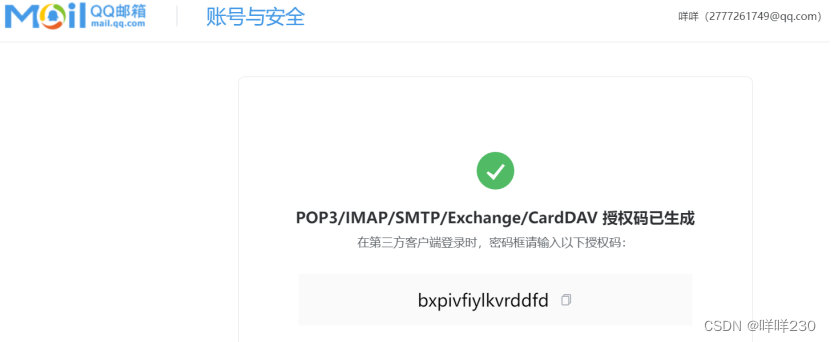 2、创建告警configmap配置文件
2、创建告警configmap配置文件
![]()
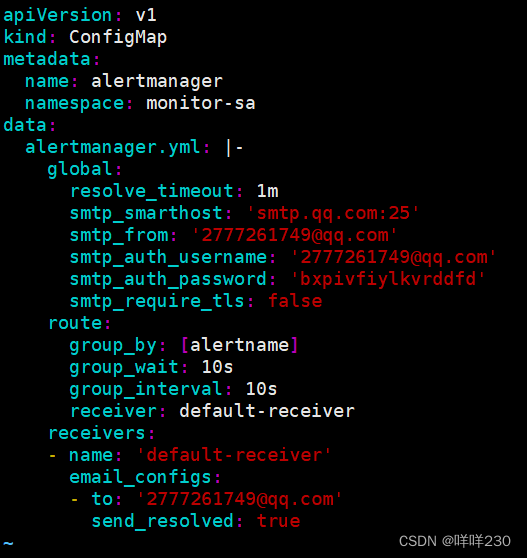
![]()

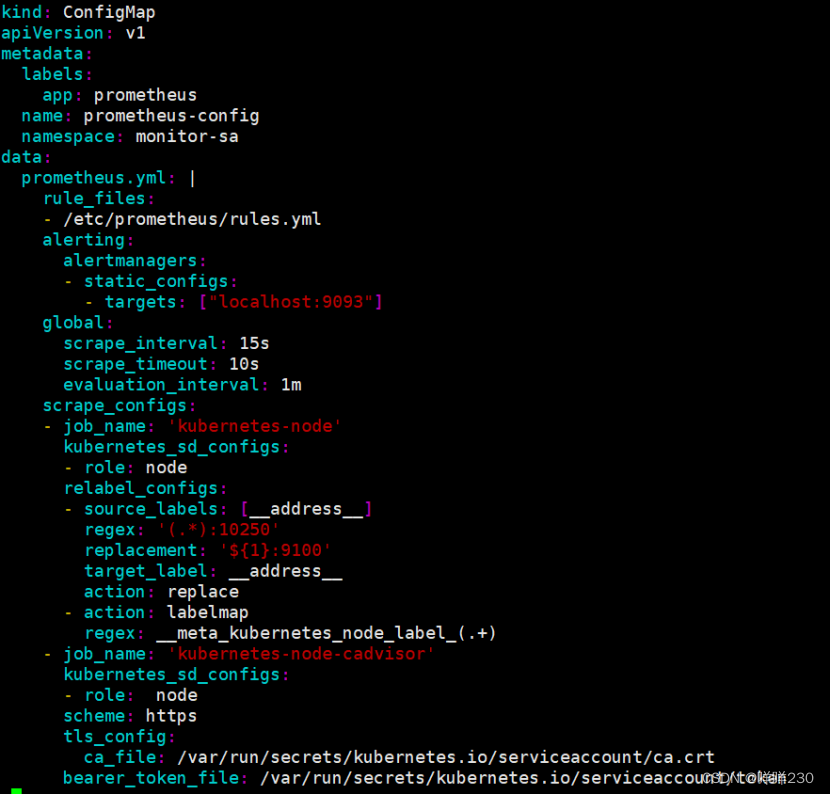
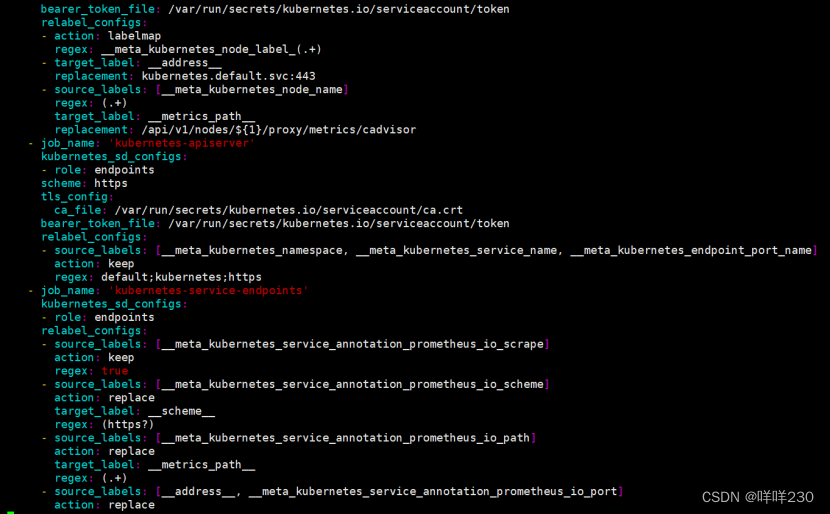
3、创建prometheus的configmap文件
![]()
alert是一个单独的模块,需要单独配置,需要声明邮箱地址。配置以configmap进行配置,altermanager用pod部署在k8s集群中
1、设置发送告警邮箱授权码
2、创建告警configmap配置文件![]()
![]()
3、创建prometheus的configmap文件
![]()

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6万+
6万+





