







1. 二叉搜索树的概念
二叉搜索树是一种查找效率很高的数据结构,它要求任何一个节点的左子树比当前节点小,右子树比当前节点大,满足这样的条件的树叫做二叉搜索树
二叉搜索树分为Key模型和Key-Value模型,Key模型主要用于查找,Key-Value模型在查找时还能取到Key对应的Value值
两种模型分别有什么用,会在后面讲,我们先用代码实现
二叉搜索树不建议修改Key值,因此我们实现增、删、查的功能即可
2. Key模型
2.1 节点的定义
template<class K>
struct BSTNode
{
BSTNode(const K& key)
:_left(nullptr)
, _right(nullptr)
, _key(key)
{}
BSTNode<K>* _left;
BSTNode<K>* _right;
K _key;
};
2.2 插入
bool insert(const K& key)
{
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else return false;
}
Node* newnode = new Node(key);
if (key < parent->_key) parent->_left = newnode;
else parent->_right = newnode;
return true;
}
2.3 查找
Node* find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (key < cur->_key) cur = cur->_left;
else if (key > cur->_key) cur = cur->_right;
else return cur;
}
return nullptr;
}
2.4 删除
由于插入、查找较简单,不再过多叙述,这里重点讲讲删除
删除总共有三种情况(记要删除的节点为cur,它的父亲节点为parent):
- cur的左右子树都为空
- cur的左/右子树为空
- cur的左右子树都不为空
第二种情况包含第一种情况,因此一二可以合并为一种
cur的左子树为空:如果cur是parent的左子树,parent的左子树指向cur的右子树;如果cur是parent的右子树,parent的右子树指向cur的右子树
cur的右子树为空:如果cur是parent的左子树,parent的左子树指向cur的左子树;如果cur的parent的右子树,parent的右子树指向cur的左子树
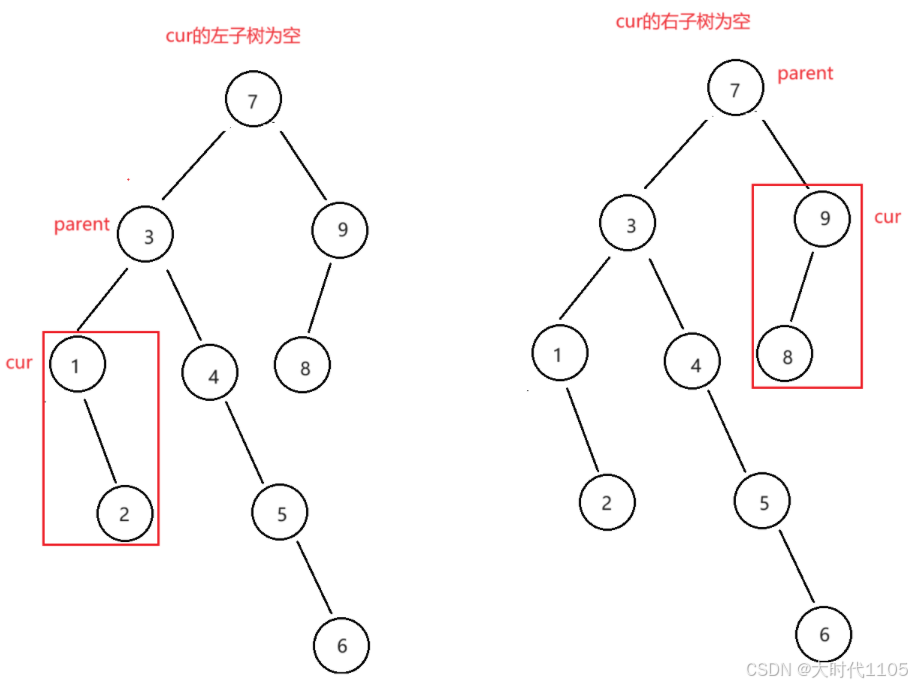
cur的左右子树都不为空:使用替换法,找cur左子树的最大节点或者cur右子树的最小节点中的值去替换cur中的值,再删除替换的节点
为什么是左子树的最大节点或者右子树的最小节点?首先直接删除肯定是不好做的,我们需要保证替换的值要比左子树所有的值要大,比右子树所有的值要小,这样替换后才能继续保持二叉搜索树的性质,而左子树的最大节点或者cur右子树的最小节点满足这点

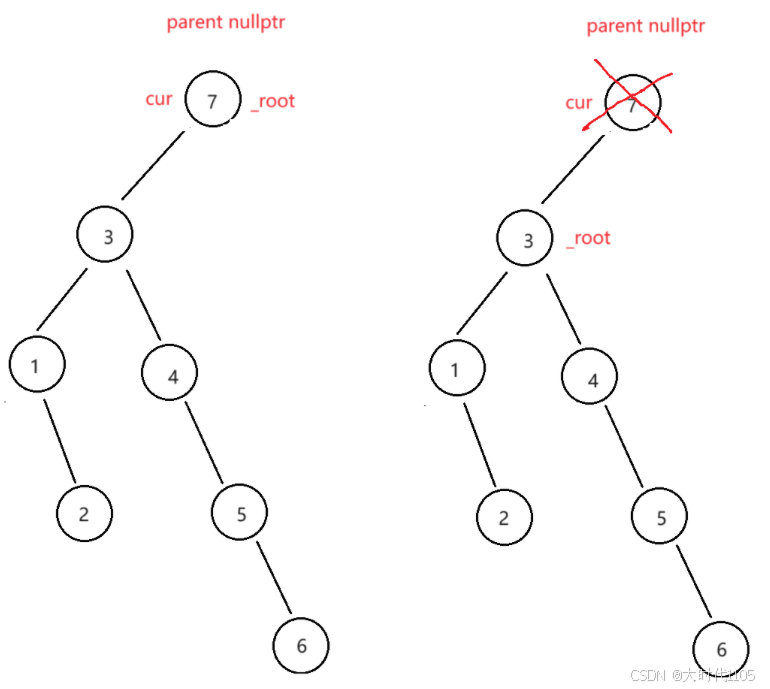
还有种特殊情况,如果要删除的节点为根,且根的左右子树有一个为空,此时根节点需要更换,单独处理即可
bool erase(const K& key)
{
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else
{
if (cur == _root && (cur->_left == nullptr || cur->_right == nullptr))
{
if (cur->_left == nullptr)
{
_root = cur->_right;
delete cur;
}
else
{
_root = cur->_left;
delete cur;
}
}
else
{
if (cur->_left == nullptr)
{
if (cur == parent->_left) parent->_left = cur->_right;
else parent->_right = cur->_right;
delete cur;
}
else if (cur->_right == nullptr)
{
if (cur == parent->_left) parent->_left = cur->_left;
else parent->_right = cur->_left;
delete cur;
}
else
{
Node* leftMax = cur->_left;
Node* leftMaxP = cur;
while (leftMax->_right)
{
leftMaxP = leftMax;
leftMax = leftMax->_right;
}
swap(leftMax->_key, cur->_key);
if (leftMax == leftMaxP->_right) leftMaxP->_right = leftMax->_left;
else leftMaxP->_left = leftMax->_left;
delete leftMax;
}
}
return true;
}
}
return false;
}
3. Key_Value模型
相较于Key模型,Key_Value模型每个节点多一个Value值,但是查找、删除依旧按照Key比较
除了插入,查找和删除的代码不变
3.1 节点的定义
template<class K, class V>
struct BSTNode
{
BSTNode(const K& key, const V& value)
:_left(nullptr)
, _right(nullptr)
, _key(key)
, _value(value)
{}
BSTNode<K, V>* _left;
BSTNode<K, V>* _right;
K _key;
V _value;
};
3.2 插入
bool insert(const K& key, const V& value)
{
if (_root == nullptr)
{
_root = new Node(key, value);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else return false;
}
Node* newnode = new Node(key, value);
if (key < parent->_key) parent->_left = newnode;
else parent->_right = newnode;
return true;
}
4. 二叉搜索树的应用
Key模型的二叉搜索树典型的应用是字典,我们将字典的所有单词插入到搜索树中,当需要查找某个单词时,就能较高的效率查找到
Key-Value模型的二叉搜索树典型的应用是翻译字典/Key的出现次数,将单词和单词的中文意思插入到搜索树中,查找到该单词的同时能知道该单词的意思
5. 性能分析
在大部分情况下,插入的数据顺序是乱的,此时查找效率接近于 O ( l o g 2 N ) O(log_2{N}) O(log2N)
但是,如果插入的数据顺序有序或接近于有序,查找的效率就变成了 O ( N ) O(N) O(N)
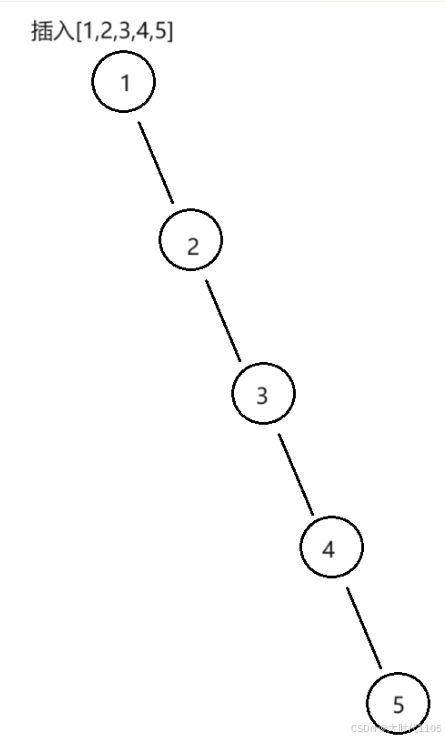
为了在插入数据顺序有序或接近于有序的情况下,效率依旧保持为 O ( l o g 2 N ) O(log_2{N}) O(log2N),二叉搜索树还可以优化为AVL树和红黑树,这是下篇文章的内容
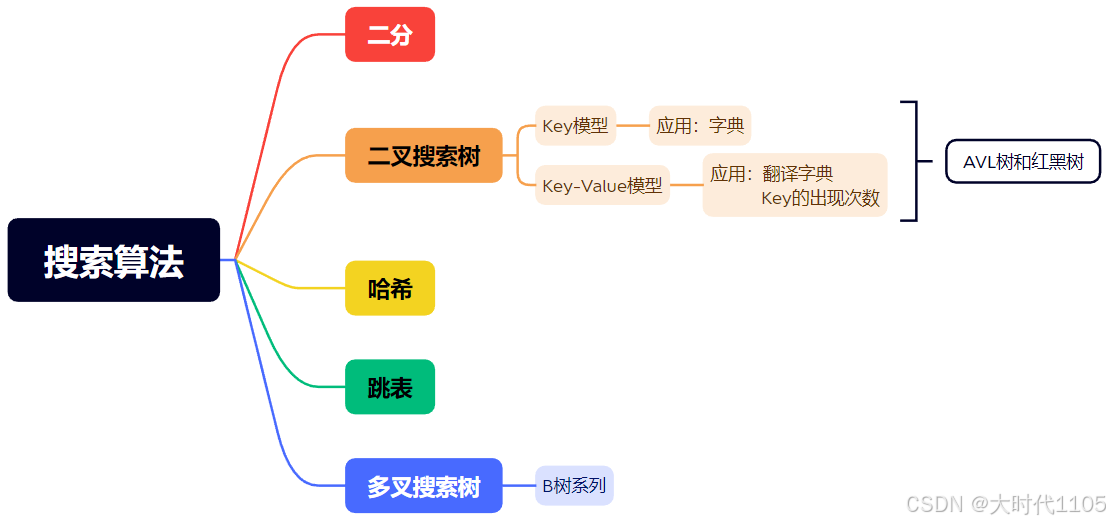
5.常见的搜索算法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









