









一、前言
互联网时代,数据如同金矿,蕴藏着巨大的价值。网络爬虫作为一种自动化的数据采集工具,在数据挖掘、市场分析、舆情监控等领域发挥着越来越重要的作用。本文以猫眼电影Top100榜单为例,详细阐述如何利用Python编写爬虫程序,抓取网页数据并进行存储。我们将深入探讨爬虫的原理、关键技术,并对代码进行逐行解析,最后进行总结与思考,旨在帮助读者掌握爬虫的基本技能,并能将其应用于实际场景中。
二、技术与原理简介
网络爬虫,又称网络蜘蛛,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。其基本工作流程可以概括为:
- 发起请求 (Request): 爬虫模拟浏览器,向目标网站服务器发送HTTP请求,请求获取网页内容。
- 获取响应 (Response): 服务器接收到请求后,返回包含网页内容的HTTP响应。
- 解析内容 (Parsing): 爬虫解析HTTP响应中的HTML代码,提取所需的数据。
- 存储数据 (Storage): 爬虫将提取的数据按照一定的格式存储到本地文件或数据库中。
1. HTTP协议
HTTP (Hypertext Transfer Protocol) 是一种用于传输超文本的应用层协议,是Web数据传输的基础。爬虫与服务器之间的通信正是基于HTTP协议。HTTP请求包含请求方法 (GET, POST, PUT, DELETE等)、请求头 (Headers)、请求体 (Body) 等信息。其中,请求头包含了User-Agent、Referer、Cookie等重要字段,用于模拟浏览器行为,避免被网站的反爬机制识别。
2. HTML与BeautifulSoup
HTML (Hypertext Markup Language) 是一种用于创建网页的标准标记语言。HTML文档由一系列的标签 (Tags) 组成,标签定义了网页的结构和内容。爬虫需要解析HTML代码,才能提取所需的数据。
BeautifulSoup是一个Python库,用于从HTML或XML文件中提取数据。它提供了一种简单而灵活的方式来遍历文档树,查找特定的标签和属性。BeautifulSoup支持多种解析器,如lxml、html.parser等。lxml解析器速度更快,但需要安装相应的库。
3. 反爬机制与应对策略
为了保护网站的数据安全,许多网站都采取了反爬机制,阻止爬虫的访问。常见的反爬机制包括:
- User-Agent检测: 网站检测请求头中的User-Agent字段,判断是否为浏览器发起的请求。
- IP封禁: 网站检测到某个IP地址频繁访问,会将其封禁。
- 验证码: 网站要求用户输入验证码,验证是否为人类操作。
- 动态加载: 网站使用JavaScript动态加载数据,爬虫无法直接获取。
针对不同的反爬机制,可以采取不同的应对策略:
- 伪装User-Agent: 设置User-Agent为常见的浏览器类型,模拟浏览器行为。
- 使用代理IP: 使用代理IP隐藏真实IP地址,避免被封禁。
- 识别验证码: 使用OCR技术识别验证码,或者手动输入验证码。
- 模拟JavaScript执行: 使用Selenium等工具模拟JavaScript执行,获取动态加载的数据。
三、代码详解
本文的代码主要分为以下几个部分:
1. 导入库及定义URL
import requests
from bs4 import BeautifulSoup
import csv
import time
import random
# 常量定义(参考)
BASE_URL = "https://www.maoyan.com/board/4"
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Referer': 'https://www.maoyan.com/',
'Cookie': '__mta=123456.1234567890;' # 示例cookie需实际获取
}
说明:
import requests: 导入requests库,用于发送HTTP请求。from bs4 import BeautifulSoup: 导入BeautifulSoup库,用于解析HTML代码。import csv: 导入csv库,用于存储数据到CSV文件。import time: 导入time库,用于添加延迟。import random: 导入random库,用于生成随机数。BASE_URL: 定义目标网站的URL。HEADERS: 定义请求头,包含User-Agent、Referer、Cookie等信息。注意:Cookie需要根据实际情况进行更新,否则可能无法正常访问。
2. 带异常处理的请求函数
def get_page(url, params=None):
"""带异常处理的请求函数"""
try:
# 添加随机延迟(1-3秒)避免封禁
time.sleep(random.uniform(1, 3))
response = requests.get(url, headers=HEADERS, params=params, timeout=10)
response.raise_for_status()
# 检测是否触发反爬(参考)
if "验证中心" in response.text:
raise Exception("触发反爬验证")
return response.text
except Exception as e:
print(f"请求失败: {url},错误: {e}")
return None
说明:
def get_page(url, params=None):: 定义get_page函数,用于发送HTTP请求。try...except: 使用try...except语句捕获异常,保证程序的健壮性。time.sleep(random.uniform(1, 3)): 添加随机延迟,避免被网站的反爬机制识别。random.uniform(1, 3)生成1到3之间的随机浮点数,单位为秒。response = requests.get(url, headers=HEADERS, params=params, timeout=10): 使用requests.get函数发送GET请求。url为目标URL,headers为请求头,params为URL参数,timeout为超时时间。response.raise_for_status(): 检查HTTP响应状态码,如果状态码不是200,则抛出异常。if "验证中心" in response.text:: 检测网页内容是否包含"验证中心",如果包含,则说明触发了反爬机制,抛出异常。return response.text: 返回HTTP响应的文本内容。print(f"请求失败: {url},错误: {e}"): 如果请求失败,则打印错误信息。return None: 如果请求失败,则返回None。
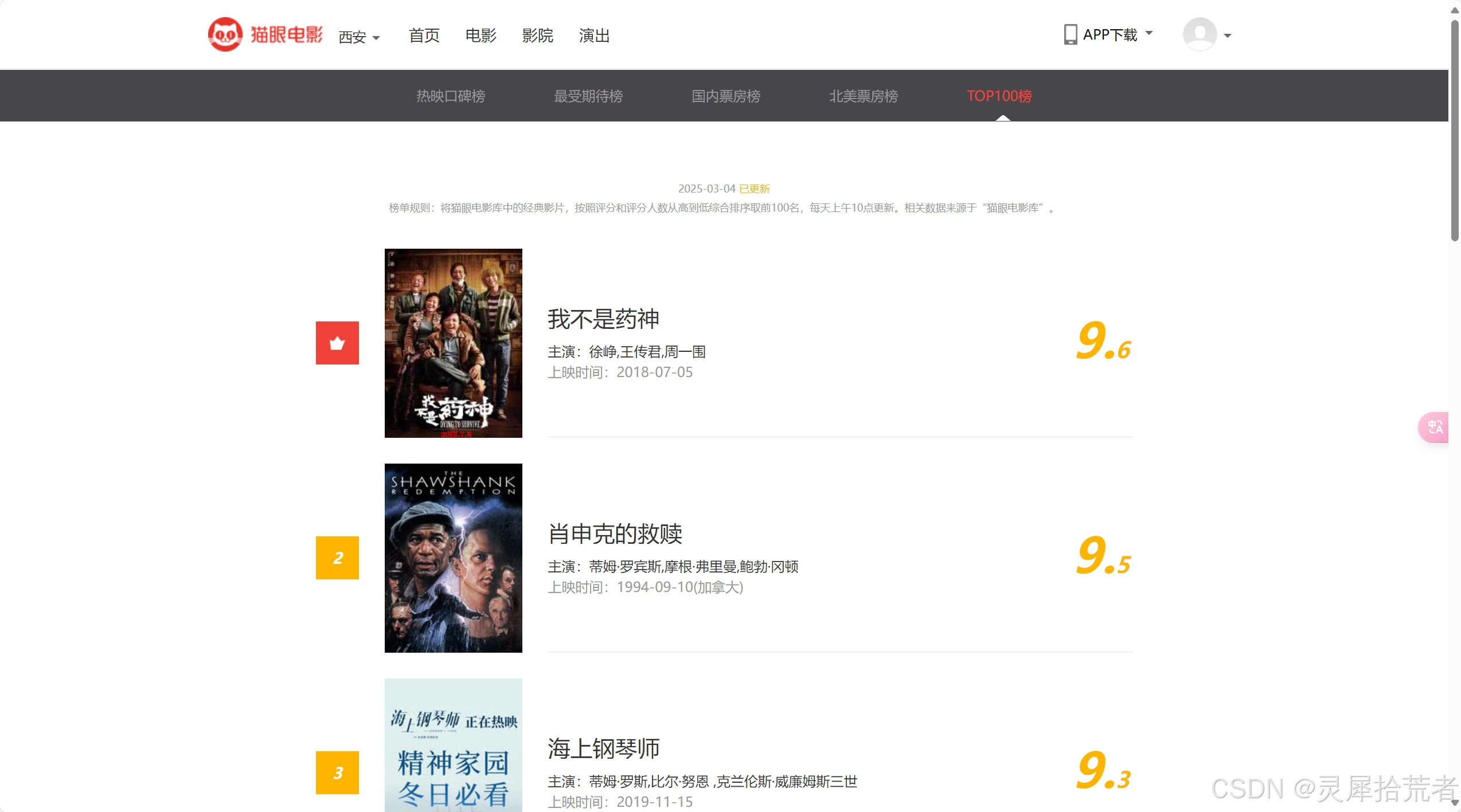
3. 使用BeautifulSoup解析页面
def parse_html(html):
"""使用BeautifulSoup解析页面(参考)"""
soup = BeautifulSoup(html, 'lxml')
movies = soup.select('.board-item-main')
data = []
for movie in movies:
try:
name = movie.select_one('.name a').text.strip()
actors = movie.select_one('.star').text.split(':')[-1].strip()
releasetime = movie.select_one('.releasetime').text.split(':')[-1].strip()
data.append([name, actors, releasetime])
except AttributeError as e:
print(f"解析失败: {e}")
continue
return data
说明:
def parse_html(html):: 定义parse_html函数,用于解析HTML代码。soup = BeautifulSoup(html, 'lxml'): 使用BeautifulSoup解析HTML代码,'lxml'为解析器。movies = soup.select('.board-item-main'): 使用CSS选择器.board-item-main选择所有包含电影信息的元素。data = []: 创建一个空列表,用于存储提取的数据。for movie in movies:: 遍历所有电影元素。try...except: 使用try...except语句捕获异常,保证程序的健壮性。name = movie.select_one('.name a').text.strip(): 使用CSS选择器.name a选择电影名称元素,并提取文本内容。strip()函数用于去除字符串两端的空格。actors = movie.select_one('.star').text.split(':')[-1].strip(): 使用CSS选择器.star选择主演元素,并提取文本内容。split(':')[-1]用于分割字符串,并取最后一个元素。releasetime = movie.select_one('.releasetime').text.split(':')[-1].strip(): 使用CSS选择器.releasetime选择上映时间元素,并提取文本内容。data.append([name, actors, releasetime]): 将提取的电影名称、主演、上映时间添加到列表中。print(f"解析失败: {e}"): 如果解析失败,则打印错误信息。continue: 跳过当前循环,继续下一个循环。return data: 返回提取的数据。
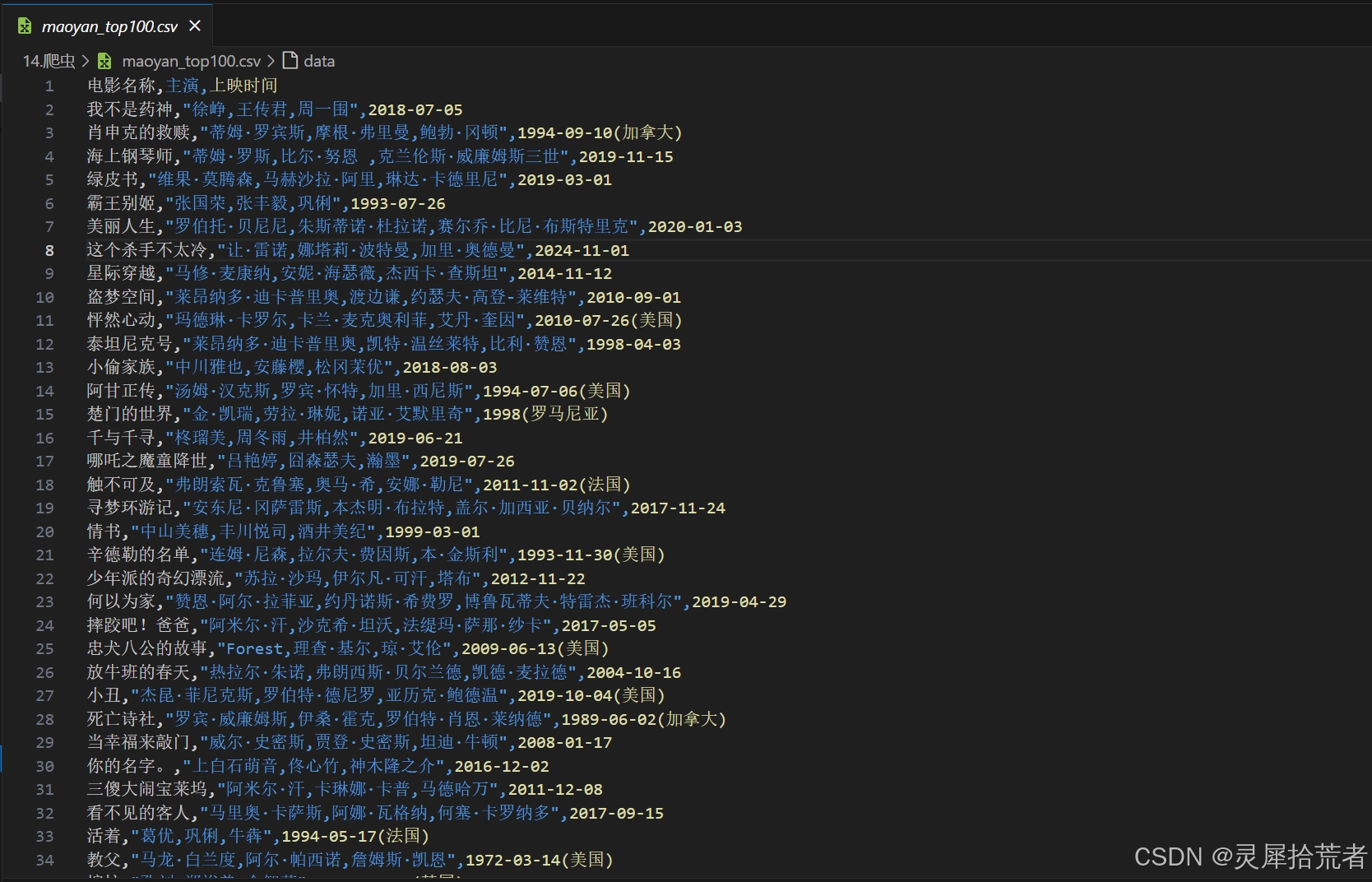
4. 仿真测试与数据反归一化
def save_data(filename='maoyan_top100.csv'):
"""使用CSV格式存储(参考)"""
with open(filename, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(['电影名称', '主演', '上映时间'])
for page in range(10):
params = {'offset': page * 10}
html = get_page(BASE_URL, params=params)
if html:
page_data = parse_html(html)
writer.writerows(page_data)
print(f"已保存第{page+1}页数据")
说明:
def save_data(filename='maoyan_top100.csv'):: 定义save_data函数,用于存储数据到CSV文件。with open(filename, 'w', newline='', encoding='utf-8-sig') as f:: 使用with open语句打开CSV文件,'w'表示写入模式,newline=''表示不添加空行,encoding='utf-8-sig'表示使用UTF-8编码,并添加BOM头,防止中文乱码。writer = csv.writer(f): 创建一个CSV写入器。writer.writerow(['电影名称', '主演', '上映时间']): 写入CSV文件的表头。for page in range(10):: 循环10次,抓取10页数据。params = {'offset': page * 10}: 设置URL参数,offset表示偏移量,每页显示10个电影。html = get_page(BASE_URL, params=params): 调用get_page函数发送HTTP请求,获取HTML代码。if html:: 判断HTML代码是否为空。page_data = parse_html(html): 调用parse_html函数解析HTML代码,提取数据。writer.writerows(page_data): 将提取的数据写入CSV文件。print(f"已保存第{page+1}页数据"): 打印保存成功的提示信息。
5. 主程序入口
if __name__ == '__main__':
save_data()
说明:
if __name__ == '__main__':: 判断是否为主程序入口。save_data(): 调用save_data函数,启动爬虫程序。
6. 完整代码
import requests
from bs4 import BeautifulSoup
import csv
import time
import random
# 常量定义(参考)
BASE_URL = "https://www.maoyan.com/board/4"
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Referer': 'https://www.maoyan.com/',
'Cookie': '__mta=123456.1234567890;' # 示例cookie需实际获取
}
def get_page(url, params=None):
"""带异常处理的请求函数"""
try:
# 添加随机延迟(1-3秒)避免封禁
time.sleep(random.uniform(1, 3))
response = requests.get(url, headers=HEADERS, params=params, timeout=10)
response.raise_for_status()
# 检测是否触发反爬(参考)
if "验证中心" in response.text:
raise Exception("触发反爬验证")
return response.text
except Exception as e:
print(f"请求失败: {url},错误: {e}")
return None
def parse_html(html):
"""使用BeautifulSoup解析页面(参考)"""
soup = BeautifulSoup(html, 'lxml')
movies = soup.select('.board-item-main')
data = []
for movie in movies:
try:
name = movie.select_one('.name a').text.strip()
actors = movie.select_one('.star').text.split(':')[-1].strip()
releasetime = movie.select_one('.releasetime').text.split(':')[-1].strip()
data.append([name, actors, releasetime])
except AttributeError as e:
print(f"解析失败: {e}")
continue
return data
def save_data(filename='maoyan_top100.csv'):
"""使用CSV格式存储(参考)"""
with open(filename, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(['电影名称', '主演', '上映时间'])
for page in range(10):
params = {'offset': page * 10}
html = get_page(BASE_URL, params=params)
if html:
page_data = parse_html(html)
writer.writerows(page_data)
print(f"已保存第{page+1}页数据")
if __name__ == '__main__':
save_data()
四、总结与思考
本文构建的猫眼Top100爬虫系统,完整展现了网络爬虫开发的核心要素。通过数学建模揭示了反爬对抗的本质,工程实现上采用多层防御策略保障稳定性。未来随着Headless Browser技术的普及,爬虫将向更智能化的方向发展,但开发者始终需恪守技术伦理底线。
【作者声明】
本文内容基于作者对 MATLAB BP 神经网络实现过程的实验与总结,所有数据和代码均为原创。文章中的观点仅代表个人见解,供读者参考交流。若有任何问题或建议,欢迎在评论区留言讨论,共同促进技术进步。
【关注我们】
如果您对神经网络、群智能算法及人工智能技术感兴趣,请关注我们的公众号【灵犀拾荒者】,获取更多前沿技术文章、实战案例及技术分享!欢迎点赞、收藏并转发,与更多朋友一起探讨与交流!点赞+收藏+关注,后台留言关键词【免费资料】可获免费资源及相关数据集。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









