







MapReduce工作过程
设计思路分析分为六个模块:input输入数据、splitting拆分、Mapping映射、Shuffing派发、Reducing缩减、Final result输出。
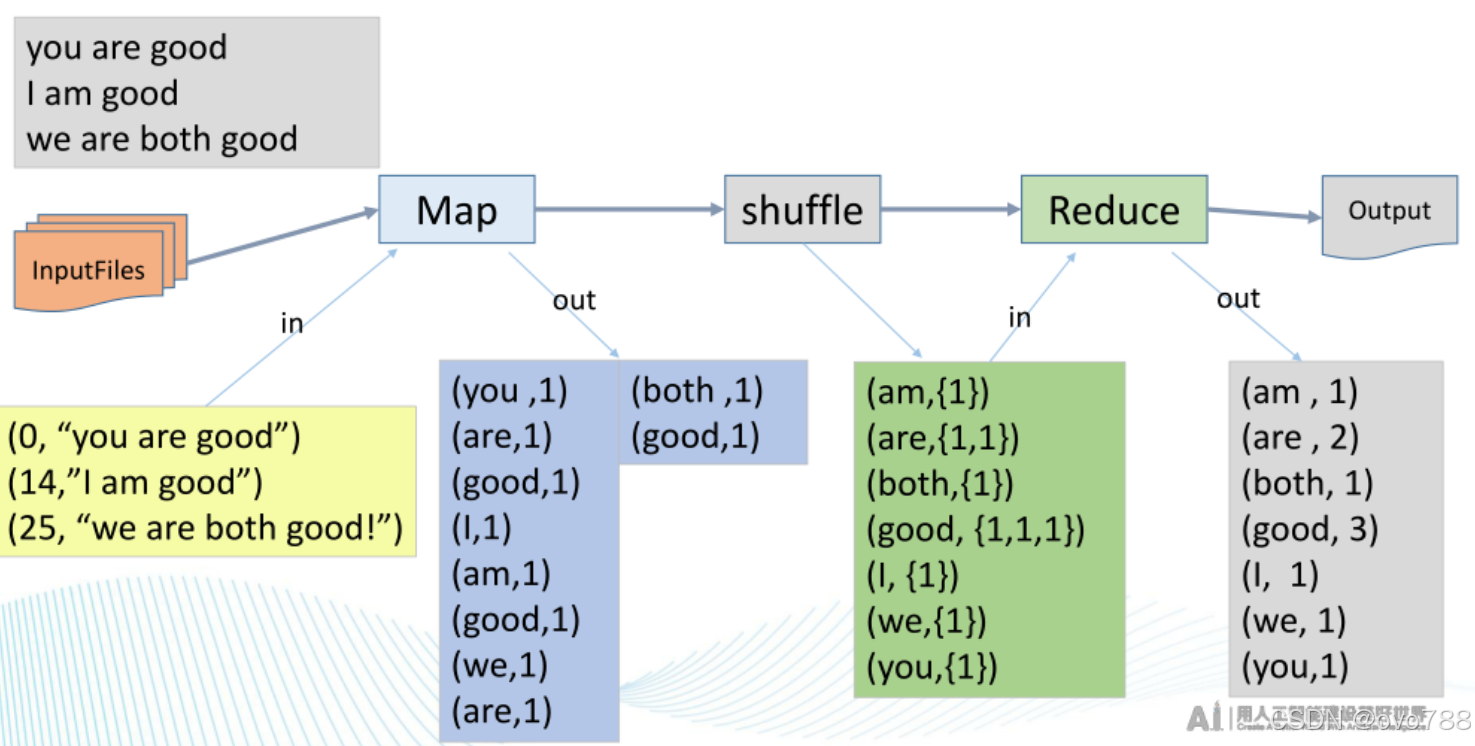
分片、格式化数据源⟹ Longrightarrow⟹执行MapTask⟹ Longrightarrow⟹执行Shuffle过程⟹ Longrightarrow⟹执行ReduceTask过程⟹Longrightarrow⟹写入文件
1.数据输入
输入数据:直接读入文本不进行分片,数据项本身作为单个Map Worker的输入。
2、Map阶段
MapTask作为MapReduce工作流程前半部分,它主要经历5个阶段,分别是Read阶段、Map阶段、Collect阶段、Spill阶段和Combiner阶段。
Map阶段:Map处理输入,每获取一个数字,将数字的Count设置为1,并将此<Word, Count>对输出,此时以Word作为输出数据的Key。
减少溢写(spill)次数
减少合并(merge)次数
在map之后,不影响业务逻辑前提下,先进行combine处理,减少 I/O
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









