






残差神经网络(ResNet, Residual Neural Network) 是由 何恺明(Kaiming He)等人 在 2015 年提出的一种深度学习模型,旨在解决深度神经网络中的 梯度消失(vanishing gradient) 和 梯度爆炸(exploding gradient) 问题,使得网络可以更轻松地训练 极深的结构。何恺明大神也凭借这一paper斩获CVPR 2016 Best Paper Honorable Mention!
1.梯度消失和梯度爆炸是什么关系?resnet主要解决什么问题呢?
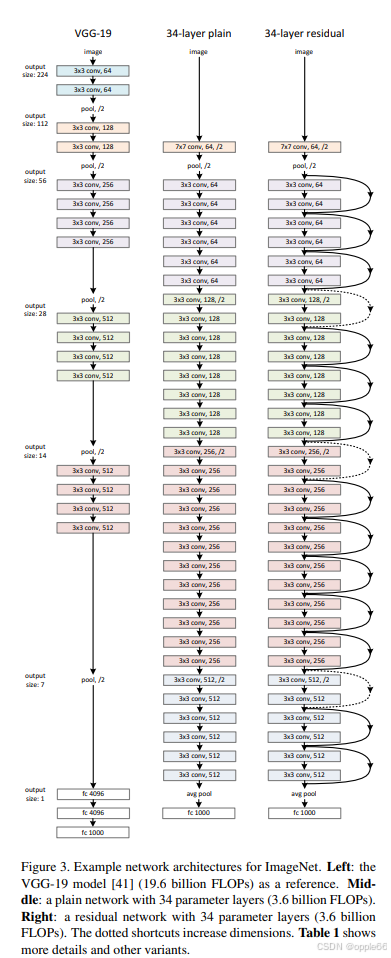
上图来自论文《Deep Residual Learning for Image Recognition》,地址https://arxiv.org/pdf/1512.03385
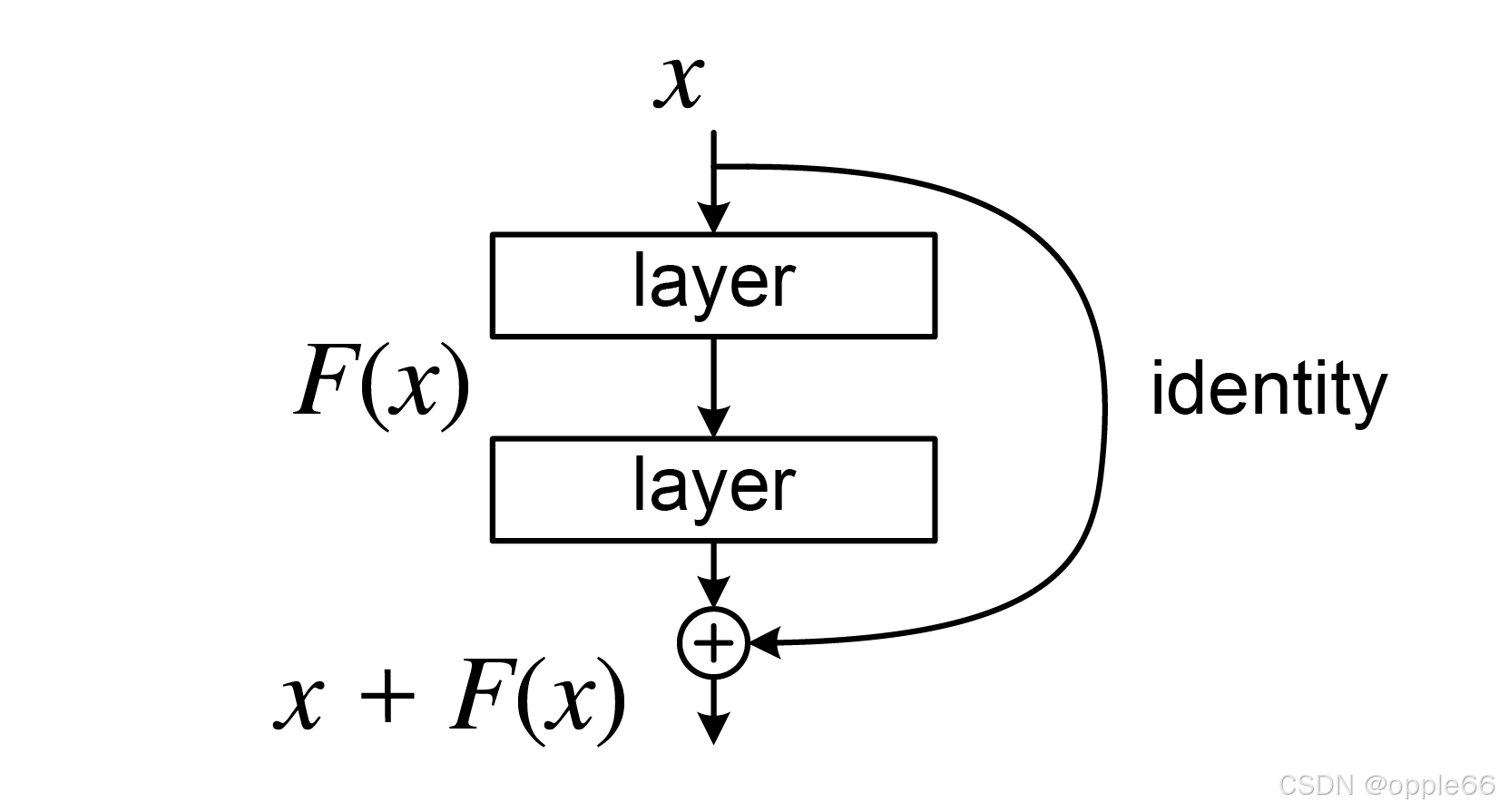
神经网络的目标就是通过训练数据来 学习输入与输出之间的映射关系,并通过不断调整参数来优化这种映射。但残差神经网络并没有直接学习这种映射,而是如上图所示,残差网络的目的没有去学习x到H(x)的映射,而是x与H(x)的不同,残差F(x)=H(x)-x,一样可以得到H(x),效果超过了一众热门的模型。
在传统的深层网络中,随着层数增加,反而可能出现性能下降的现象(退化问题)。ResNet的初衷,就是让网络拥有这种恒等映射的能力,能够在加深网络的时候,至少能保证深层网络的表现至少和浅层网络持平。
什么是恒等映射(identity mapping)?
恒等映射(Identity Mapping) 是指一个函数,它将输入直接输出,不做任何改变,即对任意输入 x,都有:
在数学中,这种映射也被称为“恒等函数”或“单位映射”。
举例:如果你在一条复杂的道路上增加了一条直通车道,车(信息)可以直接走这条车道而不受其他路段的影响,确保信息可以不被干扰地从前端传递到后端。
在 ResNet 的残差块中,输出通常表示为:
f(x)是残差部分,由卷积、BN 和激活函数组成的非线性变换。x 是输入,通过直接加法(即恒等映射)传递到输出。这种设计允许网络自动决定是否利用新增层的信息:如果 f(x)学习到的残差接近于零,那么输出 y≈x,即实现了恒等映射;这样就能保证即使网络加深,新层未能提供额外信息,也不会对整体性能产生负面影响。
如果内容有帮助麻烦点赞加收藏,我将继续更新本系列!!!!!!!!!!!!!
QA:
1.梯度消失和梯度爆炸是什么关系?resnet主要解决什么问题呢?
两者完全不一样的,梯度消失/爆炸是因为神经网络在反向传播的时候,反向连乘的梯度小于1(或大于1),导致连乘的次数多了之后,传回首层的梯度过小甚至为0(过大甚至无穷大),这就是梯度消失/爆炸的概念。
梯度消失:梯度太小,导致网络前几层无法更新权重,难以训练深层模型。
梯度爆炸:梯度太大,导致权重更新过度,训练变得不稳定。
残差网络(ResNet)主要是为了解决梯度消失,便于训练更深的神将网络,1在这里格外关键,也是resnet精髓所在,保证梯度不会轻易地降低,有效避免了梯度消失!
2.使用残差块改变网络结构遇上维度对不上咋办?
在使用残差块改变网络结构时,如果遇到输入和输出的维度(通道数或空间尺寸)不匹配的情况,常常会采用 1×1 卷积来调整维度。这种方法被称为 投影快捷连接(Projection Shortcut)。
其中 Ws就是通过1×1卷积获得的权重矩阵。通过这种方式,网络不仅可以保持信息的传递,还能确保残差块内的加法操作顺利进行,从而使得网络能够训练得更深,而不会因为维度不匹配而出错。
3.resnet和其他网络的相似
Highway Networks 的核心思想也是为了解决深层网络中信息传递困难的问题,它们通过在网络中增加直接的传递路径(通常是带有门控机制的跳跃连接)来让信息能够不受干扰地从前端传递到后端。Highway Networks在跳跃连接的基础上还有门控(如 carry gate 和 transform gate),允许网络自适应地控制信息是否直接通过或经过非线性变换。
T(x, W_T)是transform gate,C(x,WC)是carry gate (通常 C(x)=1−T(x))。
感谢收看,若有误请指正,欢迎讨论!

















 715
715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









