






1. 指针
1.1 左值 与 右值.
首先看下图:

对于同一个a来说, 在不同得表达式中往往具有不同的含义.
这里完成了两个动作:
- 空间开辟: 空间的开辟大小与定义的类型有关
- 初始化操作: 把10初始化给a
- 赋值操作: 把20赋值给a
结论: 同样的一个变量, 在不同的表达式中, 名称是一样的, 但是含义却不一样~
比如在上面示例中, 左边的a代表的是a的左值概念, 更加强调一个空间的概念, 而对于右边的a则更加强调a中的值的概念.
简单总结一下:
左值: 并不是说变量名一定在左边的意思, 而是强调该变量在当前表达式中更加强调空间的概念, 因此说是左值. 相对应的, 右值不一定一定在=右边, 而是更加强调变量中值的概念, 因此说是右值.
1.2 什么是指针? 地址? 指针变量?
我们C中常说的指针, 实际上基本等价于地址和指针变量的概念. 但是为了严谨, 我们下面还是重点区分一下三者的区别.
地址: 更加侧重于计算机组成原理中的一个称呼, 往往指的是计算机内存中为了标识不同字节空间的一个编号.
指针: C中对内存地址的一种更加规范的称呼, 跟内存中的地址实际上是一个概念, 两者基本是等价的, 区别类似于下面这个例子:
红薯, 北京人叫白薯,东北人称为地瓜,上海人和天津人称山芋,江苏南部称为山芋,苏北徐州地区称为白芋,安徽北方大部分地域和苏北地区的丰县附近称为红芋,安徽中南部合肥六安一带则称之为芋头,陕西、湖北、重庆、四川和贵州称其为红苕,浙江人称其为番薯,江西人称为红薯、白薯、红心薯、粉薯之类,福建、广西称其为红薯或地瓜。
指针变量: 严格来说指针变量与前两者完全不是一个概念, 但是因为口语比较随意的缘故实际上渐渐淡化了"变量". 指针变量是C的一种变量, 而指针/地址是一个编号, 两者是完全不同的, 最明显的区别在于指针变量有空间的概念!
首先, 这个 指针 和 指针变量 在很多教材说法非常混乱~
问: 为啥这么乱呢? (问: 为啥很多人(教材)喜欢把指针和指针变量混在一起谈?)
答: 就是上面说的翻译问题或者说本身作者也不做区分而已~ 口语比较好表达而已~

问: 为啥可以说指针 == 地址呢? 指针变量 == 指针?
答: 因为当我们想要去强调指针变量中的值属性的时候, 指针变量就是指针!
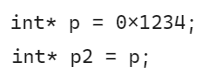
在上图中, 第二行代码中的p是一个指针变量, 但是这里更加强调p中的内容, 也就是值, 所以说在这种情况下指针变量就是指针.
1.3 指针存在的意义?
答: 提高查找效率 + 准确性
在C中, 具有指向性的数字, 叫做指针
这个"查找效率"和"准确性"如何理解呢?
很简单, 因为不给内存地址的话CPU得去遍历, 所以说直接告诉你在哪直接拿效率更高
然后这个准确性, 就是计算机里每个字节都是0/1组成的, 谁知道你修改的/访问的是不是你需要修改/访问的那个字节呢?
1.4 地址的编制是如何的?
我们说的指针也好, 地址也罢, 实际上是通过地址编制而来的. 那我们大体了解一下内存编制是如何弄得.
答: 所谓的编制, 体现在地址总线的排列组合上.
理论上, x86系统下的CPU可以访问总的字节数 = 2^32个字节, 换算出来是4GB.
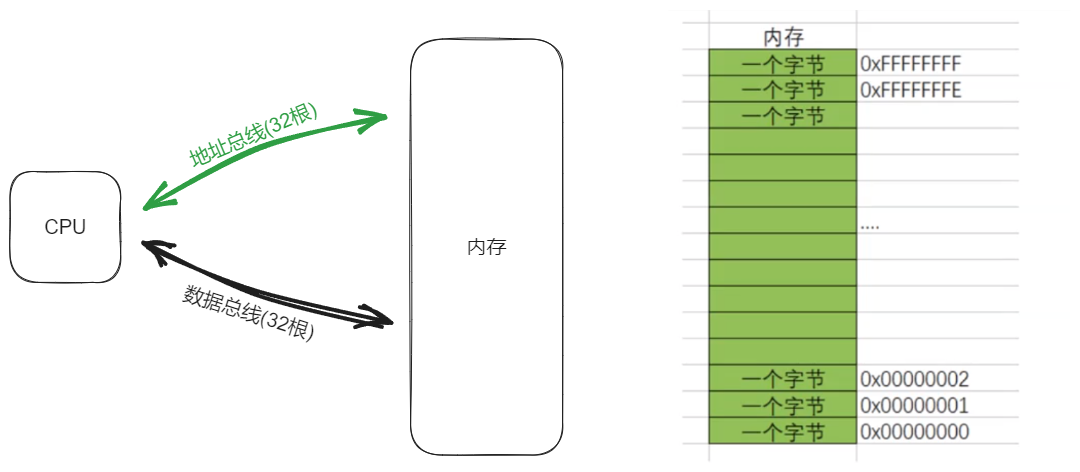
看到上面那个绿色的那个地址总线了吗? 在x86下有32根地址总线, 每一根可以根据电平信号的高低来区分0/1的概念, 然后每一根可以标识一个二进制位, 总共32根, 自然排列组合出来的总地址个数是2^32个.
1.5 指针的内存布局
下面展示如何画一个比较准确的内存图: 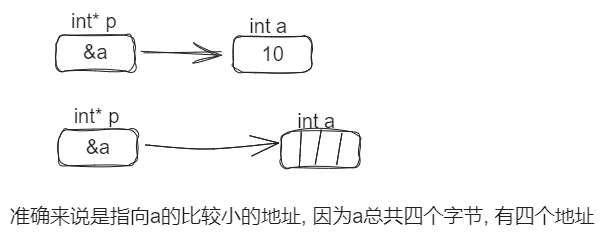
1.6 指针的解引用?
我们先来看一个代码例子:
int a = 10;
int* pa = &a;
int b = *pa;
*pa = 20;

问: *p, 是一个表达式的情况下, *就是一个操作符, 而p代表的是p的左值还是右值呢?
答: 右值, 左值代表的是空间, *是去根据右值找到对应的目标的~
1.7 int *p = NULL 和 *p=NULL的区别
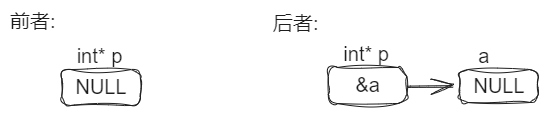
问: int* p == NULL 与 *p == NULL是一回事吗?
答: 不是一回事, 前者是把p这个变量里面的内容设置为NULL, 后者是把p所指向的空间的内容设置为NULL.
拓展: 0与NULL与’\0’?
答: 上面三个0呢, 数字层面都是零, 但是含义却不一样.
- NULL: 指针0, 表示0号地址空间, 一般四个/八个字节
- 0: 字面量, 一般用来当作数字0处理(整形), 通常占四个字节
- ‘\0’:字符0, 不可打印字符, 占一个字符
1.8 如何将数值存储到指定的内存地址 -> 只能通过指针变量, 而不是自己随便写个地址去访问内存对应空间.
答: 基本是通过指针变量去存储的, 而不是自己去写字面量访问地址. 因为基本不合法.
拓展: 栈随机化技术 与 "金丝雀"技术
为了安全考量, 在一些比较新的编译器中, 往往会随机的给你的变量开辟随机地址, 而不是固定的~ 比如, VS2022环境下:

想说明的是: 想要通过直接使用地址字面量的方式访问地址, 基本上成功概率不大~
为程序员不关心底层指针到底是多少提供了方便.
1.9 编译器的bug??? -> 指针可以自己指向自己吗?
这个地方是因为很老的编译器上如果指针指向自己, 会有bug问题, 现在编译器基本都解决了这个问题, 看一下下面代码了解一下还可以这样玩即可.
问: 我们下面来看下面例子, 体会一下解引用问题: 指针指向自己的问题.
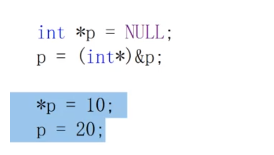
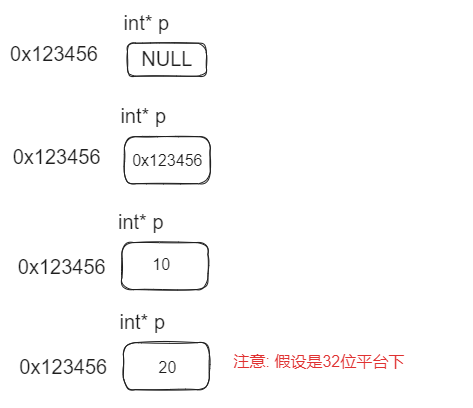
1.10 小总结
至此, 我们基本就把指针这个小话题说完了, 算是简单了解了一下指针. 实际上因为知识之间都是关联的, 单单了解上面指针的基本概念或者定义是完全不够的, 还需要去了解一般跟他有关的东西才算比较全面的了解一个指针概念.
2. 数组
C中, 啥是数组呢?
在C中, 数组算是一种比较特殊的类型. 然后的话其定义是:
数组: 具有相同类型的数据的集合
数组的基本特性以及定义啥的, 我们不再多说, 下面分享一点数组的比较小的知识点.
2.1 数组地址内存分布(重要)
这个知识点十分重要!!!

问: 按照栈的申请规律来说, 栈申请会逐渐减少的, 但是这里结果是逐渐增大的, 这是怎么回事?
答: 在开辟空间的时候, 不应该将数组认为是一个个独立的空间, 这个数组是按照一个整体直接在栈开辟空间的. 整个数组是整体开辟, 整体释放的.
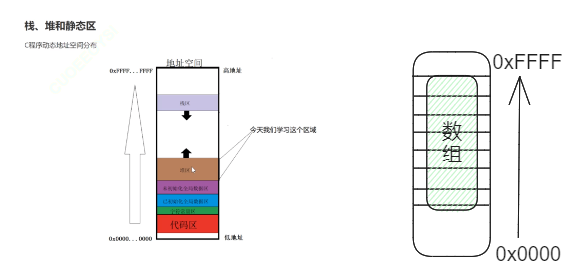
老师启示:
1. 数组是整体看待的.
2. 数组的下标是逐渐增大的
2.2 理解&a[0] 和 &a的区别
&a[0]: 首元素的地址
&a: 整体数组的地址
注意: 两者的值是一样的, 但是两者的类型却不一样!
我们写下面代码体会一下: 对指针+1, 实际上+的是指针所指向类型的大小.

结论: 上面所说的这个道理同样适用于a[0], 和a, 其+1, 增加的一个地址长度取决于他的类型.
char* p1 = NULL;
char** p2 = &p1;
printf("%d\n", p1);
printf("%d\n", p1 + 1);
printf("%d\n", p2);
printf("%d\n", p2 + 1);
结果:
0
1
0x1234
0x1238
我们继续体会一下数组名和数组首元素地址的区别
首先铺垫一个前置知识:
- sizeof(数组名) 计算的是整个数组的大小
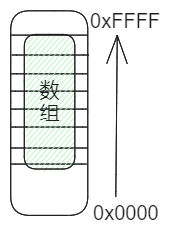
- &数组名 拿到的也是整个数组的地址

为什么数组首元素地址 与 数组地址的值是一样大的?
答: 因为首元素的地址和数组的地址最小的地址是重叠的. 因此两者的地址值是相同的
2.3 数组名的左值和右值问题
当数组是右值的时候, 充当的是数组首元素的地址.
比如见下面代码:
char arr[10] = { 0 };
char* p = arr;
printf("%p\n", arr); //结果是arr的数组首地址
printf("%p\n", p); //结果也是arr的数组首地址
数组只能进行整体初始化, 而不支持整体赋值(数组名作左值的情况), 数组只能按照索引的方式赋值.
3. 指针和数组的关系
结论: 两者没有任何关系
但是两者在访问元素的时候存在很大的相似性
3.1 我们从内存角度去看一下两者的差异~
我们写出下面代码:
char buff[10] = {'h', 'e', 'l', 'l', 'o', ' ', 'b', 'u', 'f', 'f'};
const char* str = "hello str";

显然, 我们可以从上图中总结出数组和指着你的区别如下:
- 存储区域不同, str指针本身存储在栈中, 但是其指向内容存储在字符常量区中; 而对于数组来说, 是存储在栈中的.
- 寻址方案不同, buff本身代表的就是数组首元素地址, 而str是指向字符串地址
- 类型不同
3.2 为什么C会把数组和指针设计的"使用上"如此一致? (两者在访问元素的时候存在很大的相似性)

为什么要降维?
答: 如果不降低维度, 就会发生临时拷贝, 从而导致空间浪费和效率降低问题.
降维成啥?
答: 指针, 函数传参形成临时拷贝.
结论: 我们回答一下这个小标题提出的问题. 就是为啥要如此相像呢? 主要是为了方便使用.
C是面向过程语言, C中函数是核心, 因此呢函数定义, 函数传参问题都是核心问题, 但是数组传参如果不降维, 浪费空间和效率,
降维了虽然解决了降维和效率问题, 但是呢, 就要求我们用指针的方式去访问数据(如果两者访问方式不相像), 显然这肯定不舒服(不方便),
考虑到这一点, 因此C设计者把数组访问和指针访问的两种方式规定为可以相互兼容的一种状态.
3.3 a 和 &a的区别
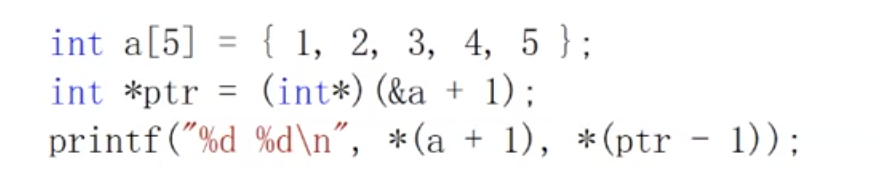
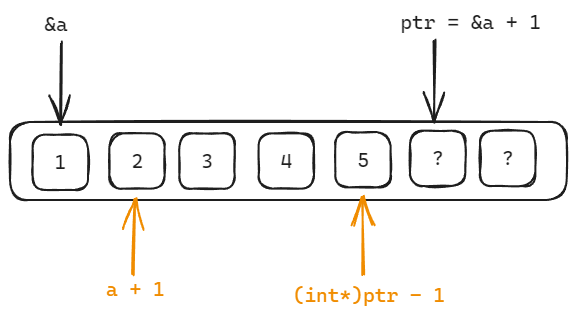
结论: 两者在数值上一致, 但是类型不一样!
3.4 指针与数组的 混合定义与声明???
假如说我在A文件下定义数组, 在B文件下声明为指针, 在A文件下定义指针, 却在B文件下声明为数组, 有什么现象呢?
因为这是错误语法, 这里不在测试.

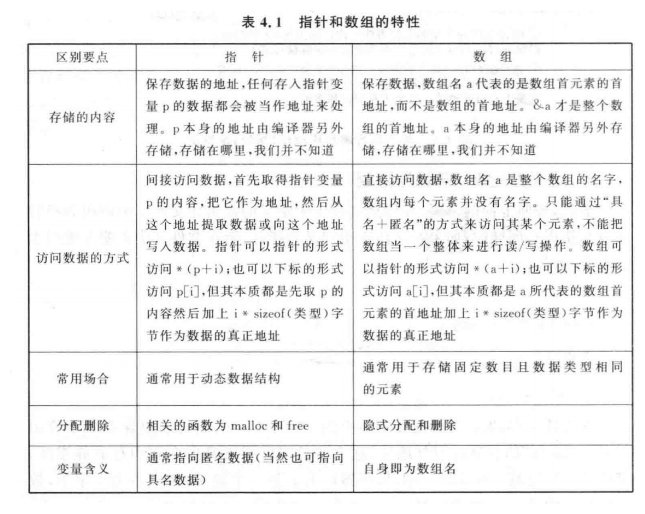
(本图截自<C语言深度解析-陈正冲>一书)
4. 指针数组和数组指针
4.1 指针数组和数组指针的内存布局
这个问题好像在前面说过, 这里不再细谈.
首先指针数组是一个数组, 因此地址是连续的, 且连续增大的(随着下标增大)
齐次呢数组指针是一个指针, 因此其大小是固定4/8字节.
4.2 也许该这么定义数组指针
不知道你是否见过Java中定义数组:
// Java中:
int[10] a;
// C/CPP中:
int a[10];
如果你对C和Java这两个编程语言都有接触, 你可能会感觉C的这个数组定义不太正常, 因为数组的类型明明是int[10], 但是却被数组名分割开来, 而Java中的定义方式显然更加"令人舒畅"一些.
当然, 这并不是吐槽C设计的不好, 这里只是想说明的是int[10]后面这个[10]也算类型的一部分.
4.3 再讨论a 和 &a之间的区别
#include <stdio.h>
#include <windows.h>
int main()
{
char a[5] = { 'A', 'B', 'C', 'D' };
char(*p3)[5] = &a; //ok,因为类型匹配
char(*p4)[5] = a; //no,类型不匹配
system("pause");
return 0;
}
4.4 地址的强制转化
强制类型转换: 所谓强制类型转换, 只有相关类型才可以相互强制类型转换, 并且改变的是编译器看待特定数据的看待方式而已.
下面来看例子:
#include <stdio.h>
#include <windows.h>
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p = (struct Test*)0x100000;
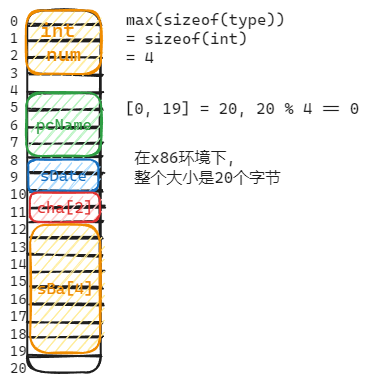
//假设p 的值为0x100000。 如下表表达式的值分别为多少?
int main()
{
printf(“%p\n”, p + 0x1);
解析: 0x100000 + 0x1 * sizeof(struct Test) = 0x100014
printf(“%p\n”, (unsigned long)p + 0x1);
解析: 0x100000 + 0x1 = 0x100001
printf(“%p\n”, (unsigned int*)p + 0x1);
解析: 0x100000 + 0x1 * sizeof(int) = 0x100004
system(“pause”);
return 0;
}
我们下面再来看一个问题:

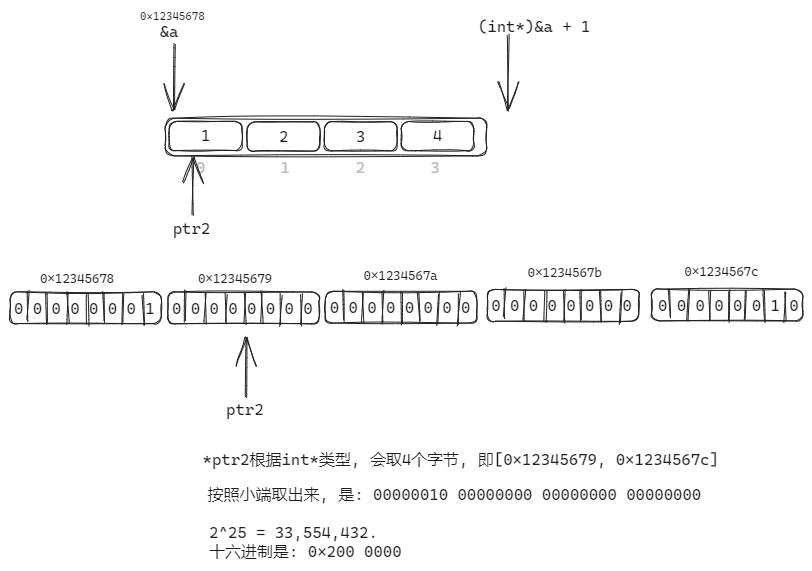
5. 多维数组和多级指针
5.1 二维数组(多维数组)
先说结论: 对于一个n维数组, 可以简单理解为是一个1维数组, 只不过其元素是n-1维数组而已.
//2. 基本内存布局
#include <stdio.h>
#include <windows.h>
int main()
{
char a[3][4] = { 0 };
for (int i = 0; i < 3; i++){
for (int j = 0; j < 4; j++){
printf("a[%d][%d] : %p\n", i, j, &a[i][j]);
}
}
system("pause");
return 0;
}
显示结果:
a[0][0] : 00AFF99C
a[0][1] : 00AFF99D
a[0][2] : 00AFF99E
a[0][3] : 00AFF99F
a[1][0] : 00AFF9A0
a[1][1] : 00AFF9A1
a[1][2] : 00AFF9A2
a[1][3] : 00AFF9A3
a[2][0] : 00AFF9A4
a[2][1] : 00AFF9A5
a[2][2] : 00AFF9A6
a[2][3] : 00AFF9A7
请按任意键继续. . .
结论:二维数组在内存地址空间排布上,也是线性连续且递增的。
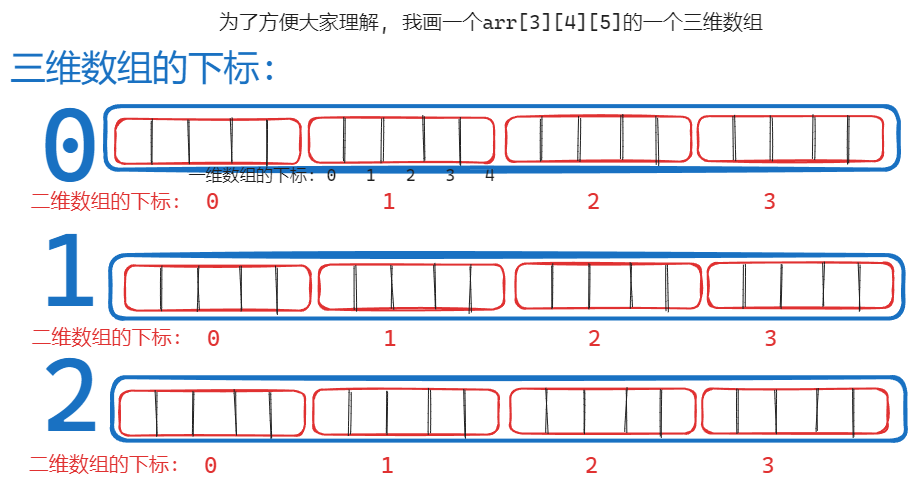
结论:二维数组在内存地址空间排布上,也是线性连续且递增的.
理解:
现在假设有下面二维数组:
int a[3][4] = { 0 };
请你依次回答下面问题:
printf(“%d\n”,sizeof(a)); //什么含义?数组名补充:两种情况代表整个数组,其他都是首元素地址.

解析: 这个算是一个特例, 我们规定, 当sizeof只有数组名的时候, 计算的是该数组的整体大小.
因此这个sizeof(a)算的是二维数组a[3][4]总共多大?
3 * 4 * sizeof(int) = 48字节
printf(“%d\n”,sizeof(a[0][0])); //什么含义?
解析: 首先a[0]表示二维数组a[3][4]的第一个元素, 即下面红色区域.

那么, a[0][0]表示的就是二位数组的第一个元素是一维数组, 一维数组的第一个元素是int整形, 因此答案是4字节.

printf(“%d\n”,sizeof(a[0])); //什么含义?
解析: a[0]表示的就是a[3][4]的第一个元素, 他的第一个元素是一个一维数组, 恰好满足sizeof(数组名)这种特例, 计算的是二维数组第一个元素的大小.
大小为4*4=16字节

printf(“%d\n”,sizeof(a[0]+1)); //什么含义?
解析: 同上, a[0]代表a[3][4]的第一个元素, 他的第一个元素是一个一维数组, 然后在表达式中, a[0]是数组名, 代表的是一维数组int[4]的第一个元素的地址, 然后+1, 得到的是int[4]的第二个元素的地址.
大小为4/8字节.
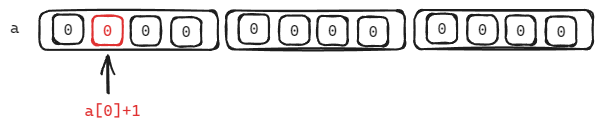
printf(“%d\n”,sizeof((a[0]+1))); //什么含义?
解析: a[0]代表的是二维数组第一个元素, 在表达式"a[0]+1"中, a[0]是一个一维数组, 代表的数组的第一个元素的地址, 然后+1,
表示的是第二个元素的地址, 然后解引用, 拿到的是一维数组的第二个元素.
综上, 其大小为4字节.

printf(“%d\n”,sizeof(a+1)); //什么含义?
解析: a是一个数组, 在表达式"a+1"中, a代表的是a[3][4]第一个元素的地址, 他的第一个元素是一个一维数组, 然后+1, 是第二个元素的地址但不满足sizeof(数组名), 因此还是按照原地址计算.
其大小是4/8字节.
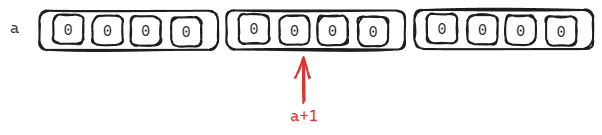
printf(“%d\n”,sizeof((a+1))); //什么含义?
解析: a在表达式中, 表示的是二维数组的第一个元素的地址, 然后+1操作, 拿到的是二维数组第二个元素的地址, 然后解引用, 拿到的是二维数组第二个元素, 也就是一个一维数组.
其大小为44=16字节.

printf(“%d\n”,sizeof(&a[0]+1)); //什么含义?
解析: a[0]表示二维数组的第一个元素, 然后取地址, 拿到的是二维数组第一个元素的地址, 然后+1, 拿到的是二维数组第二个元素的地址.
其大小为4/8字节.

printf(“%d\n”,sizeof(a)); //什么含义?
解析: a在表达式中表示的是二维数组a[3][4]的第一个元素的地址, 然后解引用,
拿到的二维数组a[3][4]的第一个元素, 即一个一维数组
其大小是: 44=16字节.

printf(“%d\n”,sizeof(a[3])); //什么含义?
解析: a[3]表示的是a[3][4]的第四个元素, 然后满足sizeof(数组名)的要求,
因此计算的是二维数组a[3][4]的第四个元素的大小, 即一个一维数组.
注意: sizeof()内的表达式不会真正参与计算.
其大小是: 44=16字节.

然后, 下面是一个练习题, 有兴趣可以自己做一下:
// &p[4][2] - &a[4][2]的值为多少?// 练习题
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf( "a_ptr=%p,p_ptr=%p\n", &a[4][2], &p[4][2]);
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}
5.2 二级指针(多级指针)
因为很简单, 就不再详说了, 自己看下面代码即可.
#include <stdio.h>
#include <windows.h>
int main()
{
int a = 10;
int *p = &a;
int **pp = &p;
p = 100; //什么意思
*p = 100; //什么意思
pp = 100; //什么意思
*pp = 100; //什么意思
**pp = 100; //什么意思
system("pause");
return 0;
}

6. 数组参数和指针参数
6.1 一维数组传参
先说结论: 一维数组传参, 会把数组降级为指针进行传参.
好处: 提高效率, 节省空间(减少临时拷贝的消耗).
坏处: 不够直观.
void show(int a[10])
{
printf("show: %d\n", sizeof(a));
}
int main()
{
int a[10];
printf("main: %d\n", sizeof(a));
show(a);
system("pause");
return 0;
}
问: 为啥要降维??? 以及 降维成什么???
答: 因为直接拷贝一个数组过去成本很大, 为了提高效率和节省空间考虑.
降维成指针, 直接变成指针传个首元素地址过去.
问: 有没有形成临时变量的拷贝?
答: 形成了, 临时拷贝的指针, 只不过消耗很小. 达到了节省空间和提高效率的目的.
6.2 一级指针传参
问: 函数调用,指针作为参数,要不要发生拷贝?
#include <stdio.h>
#include <windows.h>
比特就业课
void test(char *p)
{
printf("test: &p = %p\n", &p);
}
int main()
{
char *p = "hello world";
printf("main: &p = %p\n", &p);
test(p);
system("pause");
return 0;
}
答: 需要. 因为指针变量,也是变量,在传参上,它也必须符合变量的要求,进行临时拷贝!
6.3 二维(多维)数组参数和二级(多级)指针参数
实际上同上面一样, 数组传参也需要降维为指针, 然后指针也需要临时拷贝传参.
这里有个比较好的对于多维数组的理解: 就是任何多维数组都可以理解为一维数组, 只不过这个数组中的元素是n-1维数组而已.
我们这里不再多说, 不过这个地方算是一个小重点.
问: 多维数组的内存分布图是???
也是连续分布的, 比如a[3][4]的内存分布图是:

7. 函数指针
7.1 函数指针的定义
非常简单, 这个不再多说, 见下图:

7.2 函数指针的使用
问: 函数名和&函数名有区别吗?
答: 没区别. 两者等价.
#include <stdio.h>
#include <string.h>
#include <windows.h>
char* fun(char *s1, char *s2)
{
int i = strcmp(s1, s2);
if (0 == i){
return s1;
}
else{
return s2;
}
}
int main()
{
char *(*funp)(char*, char*) = fun;
char *s = (*fun)("hello", "world");
printf(s);
system("pause");
return 0;
}
*(int*)&p ---- 这是什么?
#include <stdio.h>
#include <string.h>
#include <windows.h>
void fun()
{
printf("call function!\n");
}
int main()
{
void(*p)();
*(int*)&p = (int)&fun;
(*p)();
p();
system("pause");
return 0;
}
7.3 (*((void(*)())0)() 这是什么?
对于上面这个东西, 我们就区分一个事就可以.
对于上面这个代码来说, 如果不考虑编译问题, 你说他调用的函数在0x00000000位置处呢? 还是0x00000000中所指向的位置呢?
答: 所调用的函数在0位置处.
为啥呢? 下面来简单解释:
对于任何一个函数指针, 我们可以如下进行调用:

下面是上面代码的详细解读 (来自字节跳动旗下的豆包AI):
// 假设该函数的地址是 0x12345678
void func(int x, int y)
{
printf("void func(int x, int y)\n");
}
int main()
{
// 定义一个函数指针 pfunc,指向函数 func,函数类型为 void (*)(int, int)
void (*pfunc)(int, int) = func;
// 调用函数 func,传递参数 1 和 2
func(1, 2);
// -> 这里的 func 是函数名,在表达式中使用函数名会自动转换为函数指针,也就是函数的入口地址
// 实际上是调用地址为 0x12345678 的函数,传递参数 1 和 2。
// func 在这里是函数的名称,作为函数调用表达式的一部分,它确实可以被看作是右值,因为它代表了函数的地址。
// 调用函数 func,传递参数 1 和 2
(*func)(1, 2);
// -> 这里的 *func 解引用操作对于函数指针来说是多余的,在 C 语言中,
// 直接使用函数名或者对函数指针进行解引用都可以调用函数。
// 这是因为在 C 语言中,函数名会自动转换为函数指针,而对函数指针解引用操作的结果还是函数指针,
// 所以 *func 和 func 在函数调用时的效果是一样的,都可以调用函数。
// 这里的 (*func) 等价于 func,最终还是调用地址为 0x12345678 的函数,传递参数 1 和 2。
return 0;
}
我想表达个啥意思呢? 就是0x00000000就是函数入口!!!
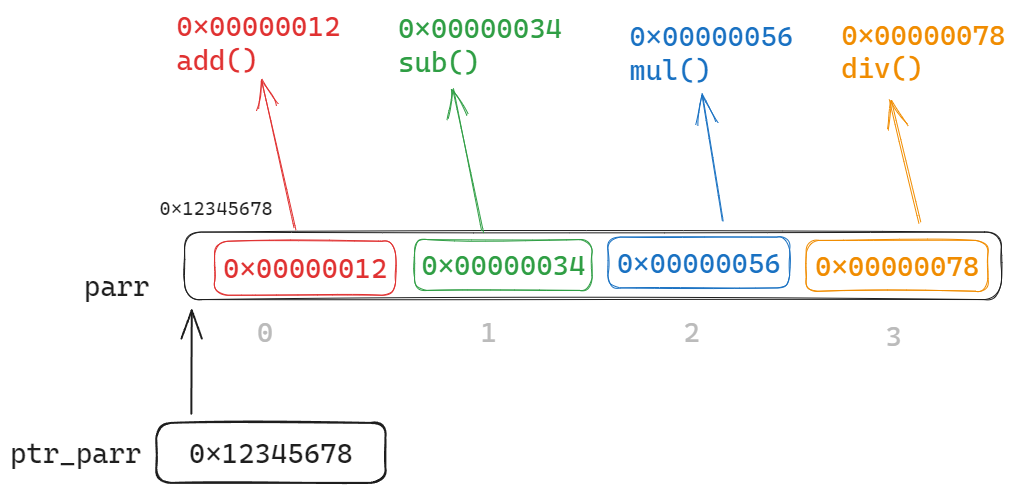
7.4 函数指针数组
这个用到的很少, 简单说一下吧.
函数指针数组,每个函数不都是有地址的嘛, 前面我们也说了对应的函数指针类型咋写, 所以说很多个函数指针也可以组成一个集合, 在C中叫做数组.
见7.5中的配图~
7.5 函数指针数组指针
函数指针数组指针: 这玩意是个指针, 只不过是个指向函数指针数组的指针而已.
为了弄清楚 函数指针数组 和 函数指针数组指针 是啥, 我写了个简单的例子:

画出抽象图来是这样滴:
8. 总结
这节呢, 咱们简单的去写了一些指针和数组的相关知识.
主题就是指针与数组.
从指针的概念到数组的概念, 然后又去着重分析了一下指着和数组的关系.
随后我们又去看了看啥是指针数组和数组指针, 即两者的一个组合问题.
然后又去分析了多维数组和多维指针, 以及数组和指针的一个传参问题.
最后又谈了比较特殊的函数指针问题.
算是深入了一下C中数组和指针的理解.
希望本文对你有帮助~ 到此结束.
EOF.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









