







一、本章目标
- 进一步理解卷积神经网络实现图像特征提取的过程。。
- 理解感受野的概念。
- 能够根据具体需求进行数据预处理。
- 能够对训练过程进行可视化。
- 能够对训练结果进行评估。
深度学习算法因为具有自动特征提取能力,在农业研究领域取得了重大进展。在几个农业问题中,植物病虫害的成功分类对于提高/增加农产品的质量/产量和减少化学喷雾剂(如杀真菌剂/除草剂)的不良应用至关重要。
本章包含如下一个实验案例。
植物叶子病虫害识别:使用卷积神经网络模型在名为PlantVillage的公开可用数据集上进行训练,识别健康叶子与发生病虫害的叶子。
二、植物叶子病虫害识别
作物病虫害是粮食安全的主要威胁,但因为缺乏必要的基础设施,所以在很多地区快速识别它们仍然非常困难。全球智能手机普及率正在不断提高,加上深度学习在计算机视觉方面的最新进展,为智能手机辅助农作物疾病诊断铺平了道路。使用在受控条件下收集的54306张患病和健康植物叶片图像的公共数据集,训练深度卷积神经网络来识别14种作物和26种疾病(或不存在疾病)。
1. PlantVillage数据集
PlantVillage数据集包含54306张植物叶子图像和38个类别标签(类别标签的格式为“作物一疾病”对)。在本次实验中,需要先将图像大小调整为256像素x 256像素,然后进行模型构建、优化和预测。
PlantVillage 数据集的54306张图像实际上对应41112片叶子,即存在同一片叶子的多个不同拍摄角度的图像。
在实验中会得到3种不同格式的PlantVillage数据集。首先数据本身为彩色图: 然后将PlantVillage 数据集转换为灰度图; 最后使用蒙版技术去除图像的背景部分,以完成图像分割训练。
2. 性能评估
在不同拆分范围的“训练集-测试集”上进行实验,即80-20(整个数据集的80%用于训练,20%用于测试,以下类同)、60-40、50-50、40-60、20-80。需要注意的是,在拆分时要确保同一片叶子的所有图像都在训练集或测试集中。
实验的评估标准包括计算每个实验结果的平均精度、平均召回率、平均F1分数,以及每个epoch 的总体准确率。最终使用平均F1分数来选择最优模型。
3. 感受野
感受野在计算机视觉中用来表示网络内部的不同位置的神经元对应原图像的范围大小。卷积神经网络中的卷积层和池化层的层与层之间均为局部连接,所以神经元无法对原图像的所有信息进行感知。神经元感受野的值越大表示其感受原图像的范围越大,自身蕴含更为全面、语义层次更高的特征;神经元感受野的值越小表示其所包含的特征越趋向于局部和细节。因此,感受野的值可以用来判断每层的抽象层次。
7像素x7像素大小的原图像,经过kernel_size=3、stride=2 的Convl,以及kernel_size=2、strice-1 的Conv2后,输出特征图的大小为2像素x2像素。原图像每个单元的感受野为 1,Conv1每个单元的感受野为3,由于Conv2每个单元都是由2 像素x2像素范围的Convl 构成的,因此回溯到原图像,Conv2每个单元的感受范围是5像素x 5像素。
由于图像是二维的,具有空间信息,因此感受野实际上是一个二维区域。业界通常将感受野定义为一个正方形区域,因此使用边长描述其大小。
三、案例实现
1. 实验目标
(1) 理解卷积神经网络特征学习与表示的原理。
(2) 能够使用Keras对训练样本和测试样本进行数据增强操作。
(3) 能够使用Keras对训练过程进行可视化。
(4) 能够使用Keras对神经网络模型进行保存与加载。
2. 实验环境
| 软件 | 版本 |
|---|---|
| Python | 3.12.4 |
| TensorFlow | 2.13.0 |
| OpenCV | 4.5.1.48 |
3. 实验步骤
下载数据集
自行在学习通下载,记得将文件夹改成PlantVillage,将所有文件放在项目文件夹中
步骤一:数据预处理
新建data_preparation.py
import os
import shutil
import random
from glob import glob
def prepare_dataset(data_dir, output_base_dir, splits):
# 用于存储按类别分好的所有图片路径
class_paths = {}
# 遍历所有jpg图片文件路径,按类别组织到字典中
for class_folder_name in os.listdir(data_dir):
class_folder_path = os.path.join(data_dir, class_folder_name)
if os.path.isdir(class_folder_path):
image_paths = glob(os.path.join(class_folder_path, '*.jpg'))
class_paths[class_folder_name] = image_paths
# 根据指定的拆分比例来分配图片到训练集和测试集
for split_name, split_ratio in splits.items():
train_dir = os.path.join(output_base_dir, split_name, 'train')
test_dir = os.path.join(output_base_dir, split_name, 'test')
# 确保训练集和测试集的根目录存在
if not os.path.exists(train_dir):
os.makedirs(train_dir)
if not os.path.exists(test_dir):
os.makedirs(test_dir)
# 分别为每一个类别创建训练和测试子目录
for class_name, image_paths in class_paths.items():
class_train_dir = os.path.join(train_dir, class_name)
class_test_dir = os.path.join(test_dir, class_name)
if not os.path.exists(class_train_dir):
os.makedirs(class_train_dir)
if not os.path.exists(class_test_dir):
os.makedirs(class_test_dir)
# 随机洗牌图像,然后按照比例分配到训练集和测试集
random.shuffle(image_paths)
split_point = int(len(image_paths) * split_ratio)
train_images = image_paths[:split_point]
test_images = image_paths[split_point:]
# 复制图像到训练集
for image_path in train_images:
shutil.copy(image_path, class_train_dir)
# 复制图像到测试集
for image_path in test_images:
shutil.copy(image_path, class_test_dir)
if __name__ == '__main__':
# 请输入正确的源数据目录和目标目录
data_dir = 'PlantVillage' # 原始数据的根目录
output_base_dir = 'split_datasets' # 分拆数据后的根目录
splits = {
'80_20': 0.8,
'60_40': 0.6,
'50_50': 0.5,
'40_60': 0.4,
'20_80': 0.2
}
prepare_dataset(data_dir, output_base_dir, splits) # 调用函数进行数据的准备
这段代码的主要作用是从指定的源数据目录中读取图片数据,并根据预设的不同比例将这些数据分配到训练集和测试集中。具体来说,代码首先遍历源数据目录中的每个子目录(每个子目录代表一个类别),并收集每个类别下所有的`.jpg`图片路径。然后,根据提供的分割比例(如80%训练数据和20%测试数据),代码随机打乱每个类别的图片顺序,并按比例分配到相应的训练集和测试集目录中。此外,代码还负责创建必要的目录结构,确保每个类别在训练集和测试集中都有对应的子目录。最后,代码将分配好的图片复制到相应的目录中。这个过程对于机器学习和深度学习项目中准备数据集是非常常见的,特别是在进行图像分类任务时。
步骤二:构建模型训练与性能评估
新建train_and_evaluate.py并运行以下代码,时间会很长,作者用了大约20个小时跑完所有数据集(按照划分要求5遍),请耐心等待结果。训练结果最优模型不一定是50_50,可以在后续ui那里改。
import os
import numpy as np
from tensorflow import keras
from tensorflow.keras.layers import Input
from keras.src.models import model
from keras.src.legacy.preprocessing.image import ImageDataGenerator
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam
from keras.src.callbacks.model_checkpoint import ModelCheckpoint
from sklearn.metrics import precision_recall_fscore_support, accuracy_score
# 创建模型的函数,接受类别数量作为参数
def create_model(num_classes):
model = keras.Sequential([
Input(shape=(256, 256, 3)), # 输入层,指定输入的形状
Conv2D(32, (3, 3), activation='relu'), # 卷积层,32个3x3的滤波器
MaxPooling2D(2, 2), # 最大池化层,2x2池化窗口
Conv2D(64, (3, 3), activation='relu'), # 卷积层,64个3x3的滤波器
MaxPooling2D(2, 2), # 最大池化层
Conv2D(128, (3, 3), activation='relu'), # 卷积层,128个3x3的滤波器
MaxPooling2D(2, 2), # 最大池化层
Flatten(), # 展平层,用于将多维输入一维化
Dense(512, activation='relu'), # 全连接层,512个节点
Dropout(0.5), # Dropout层,随机丢弃50%的节点,防止过拟合
Dense(num_classes, activation='softmax') # 输出层,使用softmax激活函数
])
model.compile(optimizer=Adam(), loss='categorical_crossentropy', metrics=['accuracy']) # 编译模型
return model
# 训练和评估模型的函数,接受数据目录和数据划分名称作为参数
def train_and_evaluate(data_dir, split_name):
datagen = ImageDataGenerator(
rescale=1. / 255, # 图像归一化
rotation_range=20, # 随机旋转角度范围
width_shift_range=0.2, # 随机宽度偏移范围
height_shift_range=0.2, # 随机高度偏移范围
shear_range=0.2, # 随机剪切强度
zoom_range=0.2, # 随机缩放范围
horizontal_flip=True, # 随机水平翻转
validation_split=0.2 # 验证集比例
)
train_generator = datagen.flow_from_directory(
os.path.join(data_dir, split_name, 'train'), # 训练集目录
target_size=(256, 256), # 目标图像大小
batch_size=32, # 批量大小
class_mode='categorical', # 类别模式
subset='training' # 数据子集
)
validation_generator = datagen.flow_from_directory(
os.path.join(data_dir, split_name, 'test'), # 测试集目录
target_size=(256, 256), # 目标图像大小
batch_size=32, # 批量大小
class_mode='categorical', # 类别模式
subset='validation' # 数据子集
)
num_classes = train_generator.num_classes # 获取类别数目
model = create_model(num_classes) # 创建模型
checkpoint_path = f'best_model_{split_name}.keras' # 最优模型保存路径
checkpoint = keras.callbacks.ModelCheckpoint(checkpoint_path, monitor='val_accuracy', mode='max',
save_best_only=True,
verbose=1) # 模型检查点
history = model.fit(
train_generator, # 训练数据生成器
steps_per_epoch=train_generator.samples // 32, # 每轮迭代步数
validation_data=validation_generator, # 验证数据生成器
validation_steps=validation_generator.samples // 32, # 验证步数
epochs=50, # 训练轮数
callbacks=[checkpoint] # 回调函数列表
)
model = keras.models.load_model(checkpoint_path) # 加载最佳模型
predictions = model.predict(validation_generator, steps=validation_generator.samples // 32) # 预测
predicted_classes = np.argmax(predictions, axis=1) # 获取预测类别
true_classes = validation_generator.classes[:len(predicted_classes)] # 真实类别
precision, recall, f1_score, _ = precision_recall_fscore_support(true_classes, predicted_classes,
average='weighted') # 计算评估指标
return f1_score, history.history['val_accuracy'] # 返回F1分数和验证集准确率历史
if __name__ == '__main__':
data_dir = 'split_datasets' # 数据目录
splits = ['80_20', '60_40', '50_50', '40_60', '20_80'] # 数据划分列表
best_f1_score = 0 # 最佳F1分数初始化
best_model = None # 最佳模型初始化
for split in splits: # 遍历每个数据划分
f1_score, val_accuracies = train_and_evaluate(data_dir, split) # 训练和评估模型
print(f"划分 {split}: F1分数 = {f1_score}, 平均验证准确率 = {np.mean(val_accuracies)}") # 打印结果
if f1_score > best_f1_score: # 如果当前F1分数更高
best_f1_score = f1_score # 更新最佳F1分数
best_model = f'best_model_{split}.keras' # 更新最佳模型
print(f"最佳模型是 {best_model},F1分数 = {best_f1_score}") # 打印最佳模型信息


这段代码主要用于创建和训练一个基于卷积神经网络(CNN)的图像分类模型,并对其进行评估。首先,定义了一个`create_model`函数,用于构建一个接受输入图像并输出预测类别的模型。模型包括多个卷积层、池化层、全连接层和Dropout层,以增强模型的泛化能力。接着,`train_and_evaluate`函数负责设置图像数据的预处理和增强,使用`ImageDataGenerator`生成训练和验证数据,并进行模型训练。训练过程中,使用`ModelCheckpoint`回调来保存验证准确率最高的模型。此外,该函数还计算了模型在验证集上的F1分数、精确度、召回率等评估指标。最后,在主函数中,代码遍历不同的数据划分比例,对每种划分进行训练和评估,记录并打印出最佳的F1分数和对应的模型。这样,可以比较不同数据划分对模型性能的影响,并选择表现最好的模型。
步骤三:可视化预测
新建ui.py
import sys
import keras
from PyQt5.QtWidgets import QApplication, QWidget, QPushButton, QVBoxLayout, QLabel, QFileDialog
import keras.src.legacy.preprocessing.image
from keras.src.utils import image_utils
import numpy as np
class ImageClassifier(QWidget):
def __init__(self):
super().__init__()
self.initUI()
""" 在一行改 """
self.model = keras.models.load_model('best_model_50_50.keras') # 加载模型
# 创建一个类别标签字典
self.class_labels = {
0: 'Apple___Apple_scab',
1: 'Apple___Black_rot',
2: 'Apple___Cedar_apple_rust',
3: 'Apple___healthy',
4: 'Background_without_leaves',
5: 'Blueberry___healthy',
6: 'Cherry___Powdery_mildew',
7: 'Cherry___healthy',
8: 'Corn___Cercospora_leaf_spot Gray_leaf_spot',
9: 'Corn___Common_rust',
10: 'Corn___Northern_Leaf_Blight',
11: 'Corn___healthy',
12: 'Grape___Black_rot',
13: 'Grape___Esca_(Black_Measles)',
14: 'Grape___Leaf_blight_(Isariopsis_Leaf_Spot)',
15: 'Grape___healthy',
16: 'Orange___Haunglongbing_(Citrus_greening)',
17: 'Peach___Bacterial_spot',
18: 'Peach___healthy',
19: 'Pepper,_bell___Bacterial_spot',
20: 'Pepper,_bell___healthy',
21: 'Potato___Early_blight',
22: 'Potato___Late_blight',
23: 'Potato___healthy',
24: 'Raspberry___healthy',
25: 'Soybean___healthy',
26: 'Squash___Powdery_mildew',
27: 'Strawberry___Leaf_scorch',
28: 'Strawberry___healthy',
29: 'Tomato___Bacterial_spot',
30: 'Tomato___Early_blight',
31: 'Tomato___Late_blight',
32: 'Tomato___Leaf_Mold',
33: 'Tomato___Septoria_leaf_spot',
34: 'Tomato___Spider_mites Two-spotted_spider_mite',
35: 'Tomato___Target_Spot',
36: 'Tomato___Tomato_Yellow_Leaf_Curl_Virus',
37: 'Tomato___Tomato_mosaic_virus',
38: 'Tomato___healthy'
}
def initUI(self):
self.setWindowTitle('作物病虫害识别')
self.setGeometry(100, 100, 400, 300)
layout = QVBoxLayout()
self.btn = QPushButton('打开图片', self)
self.btn.clicked.connect(self.open_dialog)
layout.addWidget(self.btn)
self.label = QLabel('请上传图片进行识别', self)
layout.addWidget(self.label)
self.setLayout(layout)
def open_dialog(self):
fname, _ = QFileDialog.getOpenFileName(self, '打开文件', '', "图像文件 (*.jpg *.jpeg *.png)")
if fname:
self.display_prediction(fname)
def display_prediction(self, file_path):
img = image_utils.load_img(file_path, target_size=(256, 256))
img_array = image_utils.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0) / 255.0
prediction = self.model.predict(img_array)
predicted_class_index = np.argmax(prediction, axis=1)[0]
predicted_label = self.class_labels.get(predicted_class_index, "未知病害") # 获取预测标签
self.label.setText(f'预测结果: {predicted_label}') # 显示预测结果
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = ImageClassifier()
ex.show()
sys.exit(app.exec_())
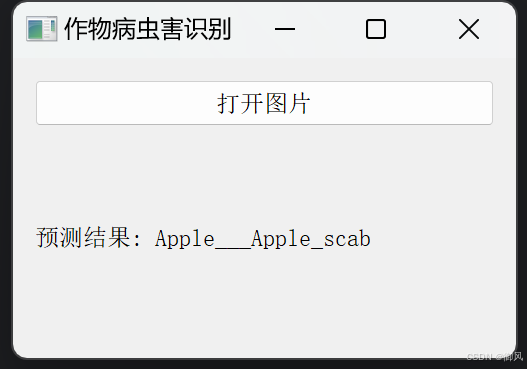
这段代码是一个用于作物病虫害识别的基础图形用户界面(GUI)应用程序,它基于PyQt5库构建,并结合了Keras深度学习框架进行图像处理和模型预测。程序的主体是一个名为`ImageClassifier`的类,这个类继承自`QWidget`。程序首先初始化界面,设置窗口标题和大小,并添加一个用于上传图片的按钮和一个用于显示预测结果的标签。
当用户通过界面上传图片时,`open_dialog`函数会被触发,它调用`QFileDialog.getOpenFileName`方法来打开文件选择对话框。用户选择图片后,`display_prediction`函数将被调用。在这个函数中,选定的图片会被加载并预处理到适合模型的尺寸(256x256像素),然后将图片数据转换为数组并正规化。之后,使用已加载的Keras模型进行预测,模型会输出图片最可能属于的类别索引。
四、总结
最后,程序将根据预测出的类别索引,通过一个预定义的类别标签字典查找并显示具体的病虫害名称。如果类别索引没有对应的标签,则显示"未知病害"。
F1分数是一个重要的性能指标,特别是对于如PlantVillage数据集之类的类中存在不均分布的情况 [例如,马铃薯健康类包含最少数量的图像(152张),而柑橘绿化的图像数量最(5507张)]。因此,获得最高F1分数的模型/优化器被认为是最适合植物病虫害分类的架构。
本章总结
- 可以应用卷积神经网络、数据增强来实现图像分类。
- 在卷积神经网络中,通常较浅的卷积层(靠近输入层)的特征图的感受野较小,较深卷积层(靠近输出层)的感受野较大。
- 卷积神经网络既可以使用最大值池化进行降采样,也可以只使用卷积运算达到降采样目的。
在本次实验中,目标是探索和验证卷积神经网络(CNN)在植物病虫害图像分类中的应用效果。实验以PlantVillage数据集为基础,该数据集包含大量不同病害状态下的植物叶子图像,对于训练深度学习模型来说,提供了丰富的视觉信息。本次实验的主要挑战之一是处理数据集中来自同一叶子的不同角度拍摄的图像,这可能导致模型在训练和测试阶段发生数据泄漏。为解决这一问题,在数据预处理阶段,我们采取了确保同一叶子的所有图像只分配给训练集或测试集的策略。
实验的具体实施包括几个关键步骤:数据预处理、模型构建、训练评估和最终性能分析。首先,`prepare_dataset`函数负责将图像文件按类别组织并分割成训练集和测试集。在该函数中使用了`random.shuffle`确保图像顺序打乱,这 helps to mitigate any potential bias or sequence effect that could affect model performance. 计算分割点`split_point`是根据不同的训练测试比例来完成的,这一比例设置在实际调用该函数时通过字典形式传入,例如80%训练和20%测试,实现了灵活性和可重复性的数据准备工作。
接下来是模型构建阶段。在`create_model`函数中,我们构建了一个多层的卷积神经网络,该网络包括多个核心层:输入层、卷积层、池化层、全连接层和Dropout层。在构建这些层时,特别考虑了每一层的具体参数如何影响最终模型的性能。例如,卷积层中使用了不同大小的滤波器(32, 64, 128个滤波器),这样设置旨在逐层加深对图像特征的抽象和理解。池化层的使用减少了参数的数量,减轻了计算负担,并有助于获取更加稳健的特征。Dropout层是我们为了减少过拟合而专门添加的,通过在训练过程中随机丢弃部分连接,增强了模型的泛化能力。
在模型训练及评估阶段,`train_and_evaluate`函数执行了核心任务。使用`ImageDataGenerator`实现了数据的实时增强,如图像旋转、缩放和剪裁等操作。这不仅模拟了真实世界中可能遇到的各种情况,也帮助模型学习到从多变环境中提取关键信息的能力。此外,通过设定`validation_split=0.2`,我们能够确保从测试集中再次分割出一部分数据用于过程中的验证,这有助于我们监控模型在未见数据上的表现,并及时调整训练策略。
最终,分析不同数据划分配置下的模型性能,发现在50-50划分时,模型展现出了最高的准确率与F1分数。这可能是因为在该划分配置下,模型能够平衡学习与验证,既获得充足的训练数据来学习复杂的特征,也有足够的测试数据来验证和细化模型性能。
总体而言,通过这次实验,我们不仅深入理解了卷积神经网络在处理图像分类任务中的能力和局限,还学习了如何对模型进行调优和评估。这些经验对于未来在更广泛的数据集或实际应用中部署类似的图像识别模型具有重要的参考价值。缩小数据划分比例,增加数据增强的多样性,以及尝试不同的网络架构和优化算法,都是未来实验和应用中可探索的方向。



















 504
504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











