



国内已经有很多开源的大模型,但即使我们拥有强悍的硬件,在本地部署了满血版的开源模型,比如DeepSeek R1 671B,用起来还是跟官网有差别,各大平台接入的DeepSeek R1用起来也是各不相同。这是因为各平台在部署的过程中会进行优化,包括接入知识库、创建智能体、训练、超参数调整等,用户使用的是平台提供的应用程序,而不是单纯的开源模型。
对于个人用户,可能对隐私不是太在意,觉得我一个小市民,人家大公司也不会拿我的数据干什么,方便最重要,哪个平台的产品好用,直接用就是了。但对于有一定规模的公司来说,公司的数据就是资产,在把企业数据上传给平台时就要慎之又慎,考虑到脱敏的繁琐、数据泄露的风险和需要与本地应用交互完成特定任务,可能在公司局域网部署模型是更好的选择。大模型每日都在革新,各种新工具也是层出不穷,从langchian到FastGPT/dify/AnythingLLM,越来越简单易用,对开发要求越来越低。
这里就以Windows10下的Dify为例,分享大模型应用开发平台的搭建。dify的全称是do it for you,从名字就看出它就是为了简化流程而生的,虽说是开发,但基本也是拖拉拽的形式,可以不用写代码。
前排提示,文末有大模型AGI-优快云独家资料包哦!
一、安装Ollama
这步不是必要的,用LM Studio启动的模型也可以,不过一般服务器是Unix/Linux环境,用Ollama命令行更方便。
1. 下载与安装
-
在电脑的软件商店中搜索并安装Ollama,或者访问Ollama官网(https://ollama.com/)下载安装包。
-
安装完成后,Ollama没有图形界面,通过命令行进行操作,Ollama的整套命令都与Docker类似,很容易上手。
2. 配置环境变量
-
修改环境变量
OLLAMA_MODELS,将其设置为存放模型的地址,以节约C盘空间。 -
修改环境变量
OLLAMA_HOST,将其设置为0.0.0.0,让除本机以外的其他局域网机器也可以访问模型。
3. 下载与启动模型
-
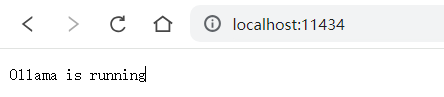
在浏览器中输入http://localhost:11434/验证,看到“Ollama is running”表示Ollama服务启动成功
-
Ollama的服务地址中的localhost可以替换为局域网地址地址。局域网地址可以通过命令行ipconfig查看。
-
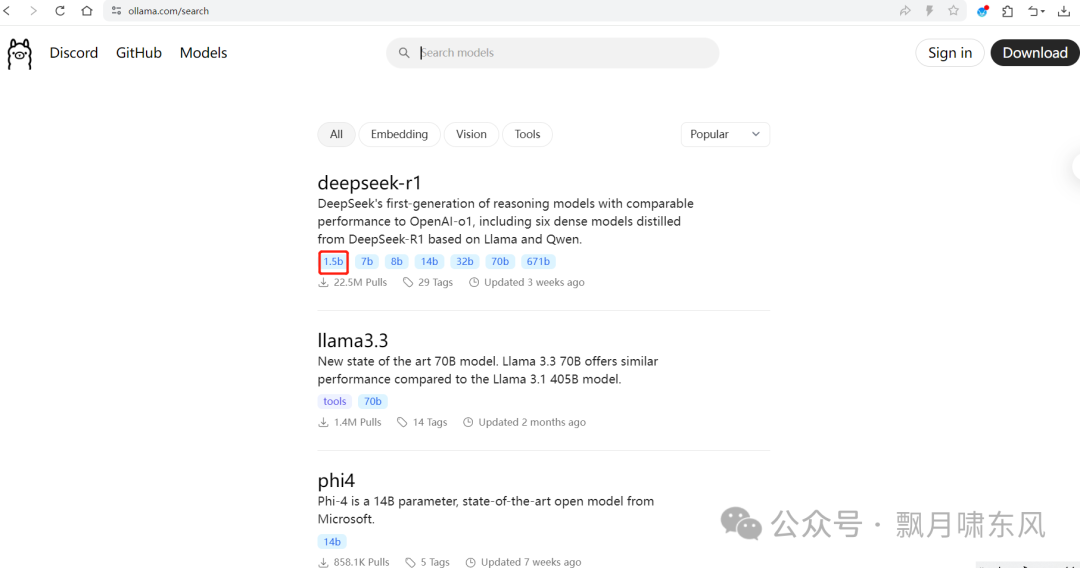
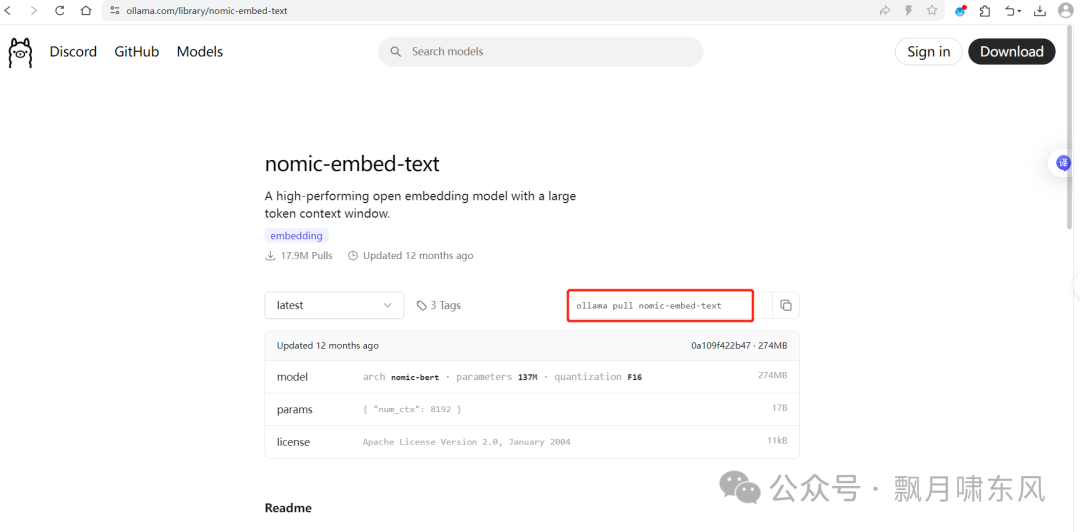
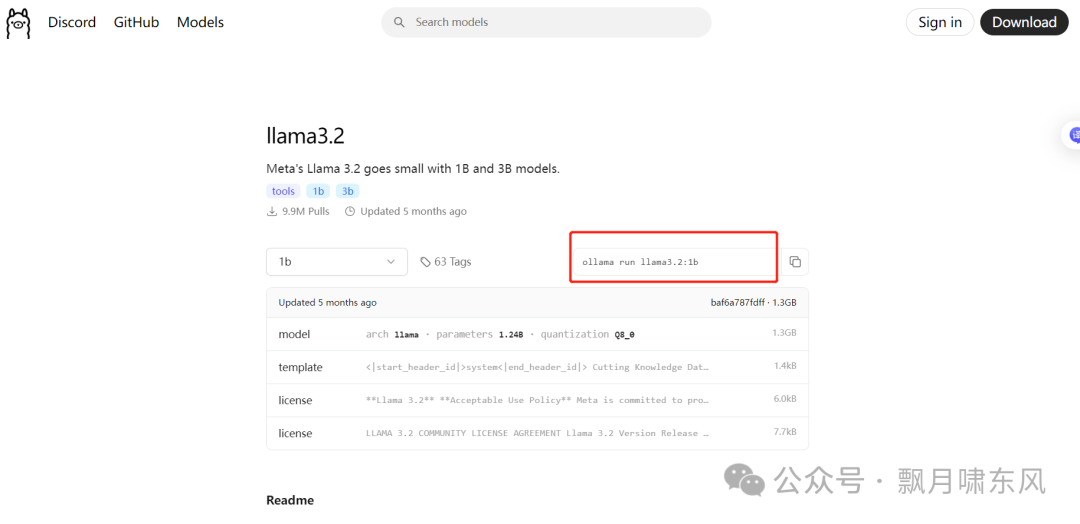
登录Ollama官网的Models页面,搜索模型,每个模型都会提供启动的命令,复制到命令行运行,等待下载完成模型就会启动。LLM模型用于文本生成和聊天,Embedding模型用于文本嵌入(知识库会用到)。
-
这里我们下载一个LLM模型llama3.2:1b和Embedding模型nomic-embed-text


4. 测试API
-
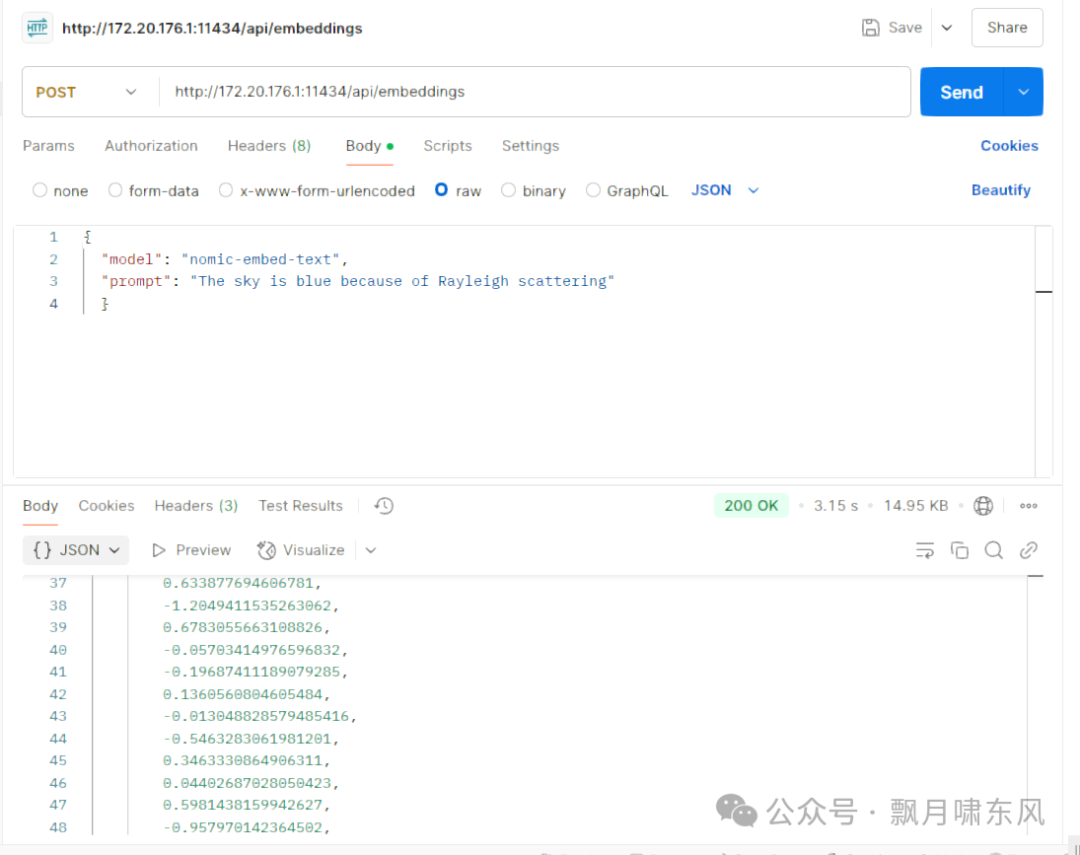
使用Postman测试API,除了提示词prompt外,还需要在JSON中写明模型名称
http://172.20.176.1:11434/api/generate
JSON复制
{ "model": "llama3.2:1b", "prompt": "hello" }
5. 使用文件创建模型
-
Ollama也可以使用下载的GGUF模型文件创建模型,对应的命令是:
cmd复制
ollama create <文件名>
二、安装Dify
推荐直接看官方doc(https://docs.dify.ai/zh-hans)。
1. 下载与安装
-
Docker安装方式
访问Dify的GitHub页面(https://github.com/langgenius/dify)下载安装包,并按照页面提示进行安装。
-
如果尚未安装Docker,需要先安装Docker Desktop,再使用以下命令启动Dify:
cmd复制
docker compose up -d -
初次启动时,需要从Docker社区下载相关镜像,没有魔法的要换国内镜像,会另外写一篇讲docker的安装。
2. 访问Dify
-
安装完成后,在浏览器中打开http://localhost,即可看到Dify的注册页面。
-
输入任意邮箱地址进行注册(账号信息保存在本地)。
三、设置Dify使用的模型
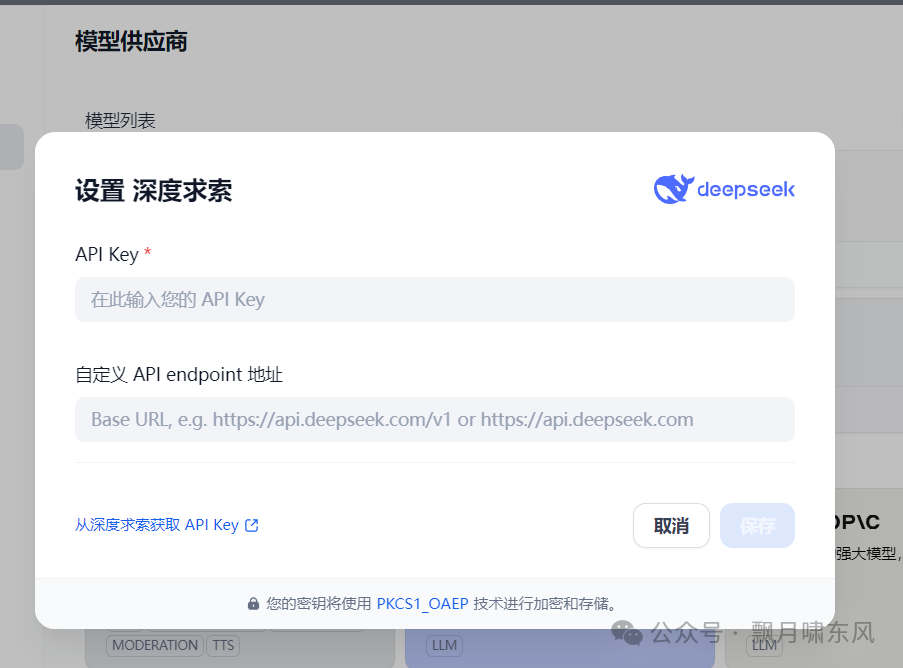
1. 配置公网模型
-
注册后进入Dify网页,点击右上角头像设置,配置模型。
-
Docker启动时已经配置好网络,Dify可以直接访问外网,可以加入OpenAI、Qwen、DeepSeek等模型。
2. 添加本地部署模型
-
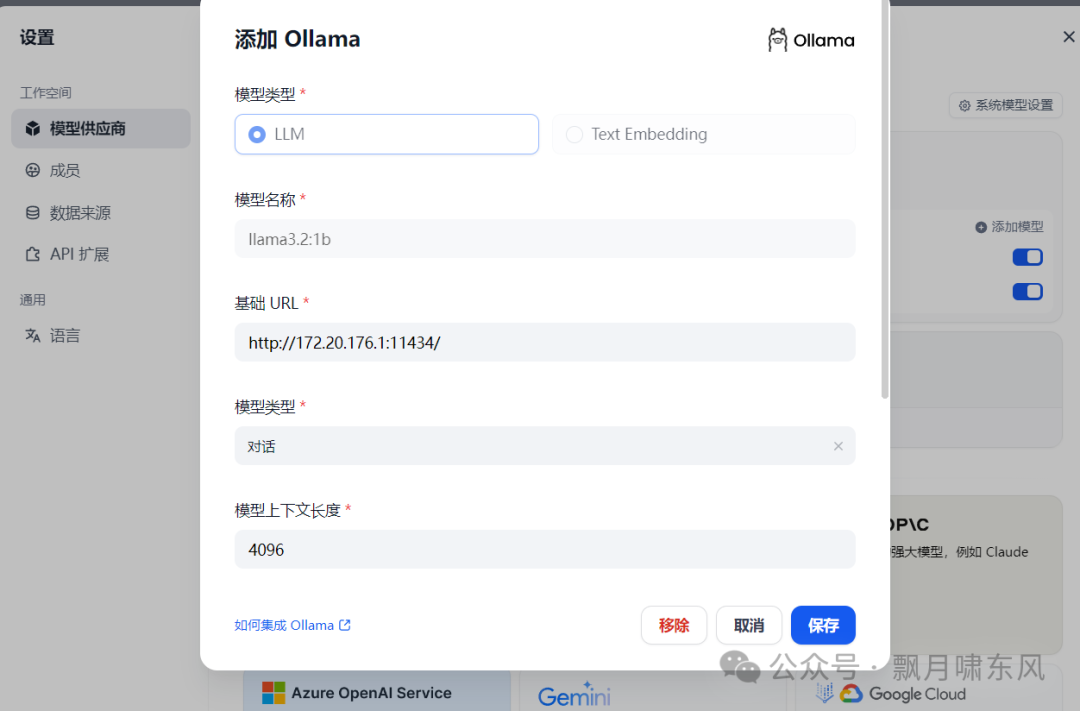
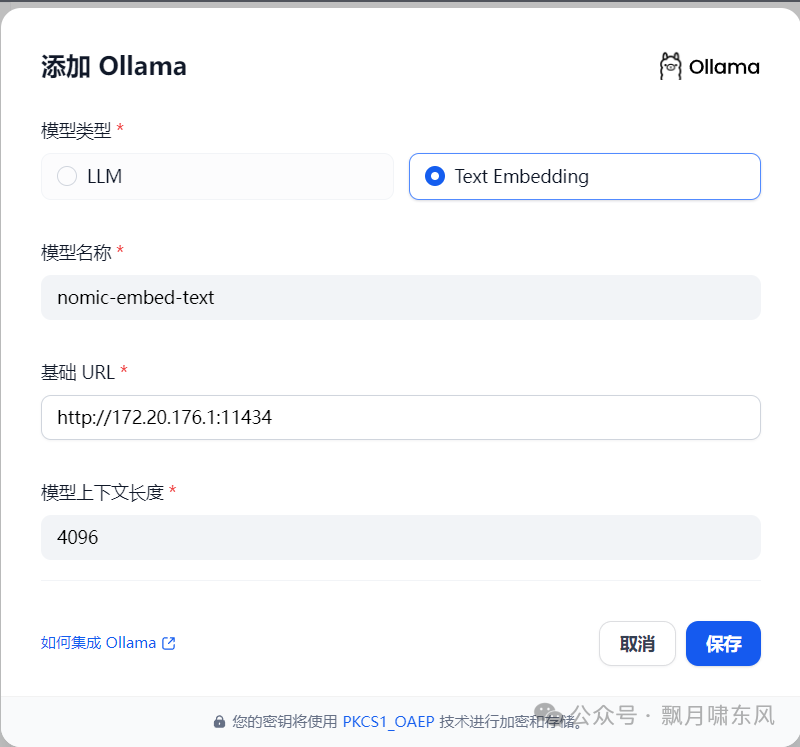
对于Ollama模型:
-
模型提供商选择ollama。
-
模型地址格式为
http://<局域网地址>:11434,例如http://172.20.176.1:11434/。 -
模型名称需要与
ollama list或ollama ps命令显示的模型名称完全一致。如果提示无法访问该地址,请检查OLLAMA_HOST是否已正确设置,并重启电脑。 -
模型类型选择LLM或Text Embedding
-
-
对于LM Studio模型:
-
模型提供商需选择OpenAI-API-compatible。
-
地址格式为
http://<局域网地址>:<端口号>/v1,例如http://172.22.48.1:1234/v1。 -
模型名称可以在LM Studio的开发者菜单左上角复制。
-
需要注意的是,LM Studio启动的模型默认只能通过
localhost访问。如果需要通过局域网访问,需在LM Studio的开发者菜单左上角的设置中勾选“在局域网内提供服务”。模型启动后,在底部Developer Logs窗口中看到模型地址的localhost已被替换为局域网地址。
-
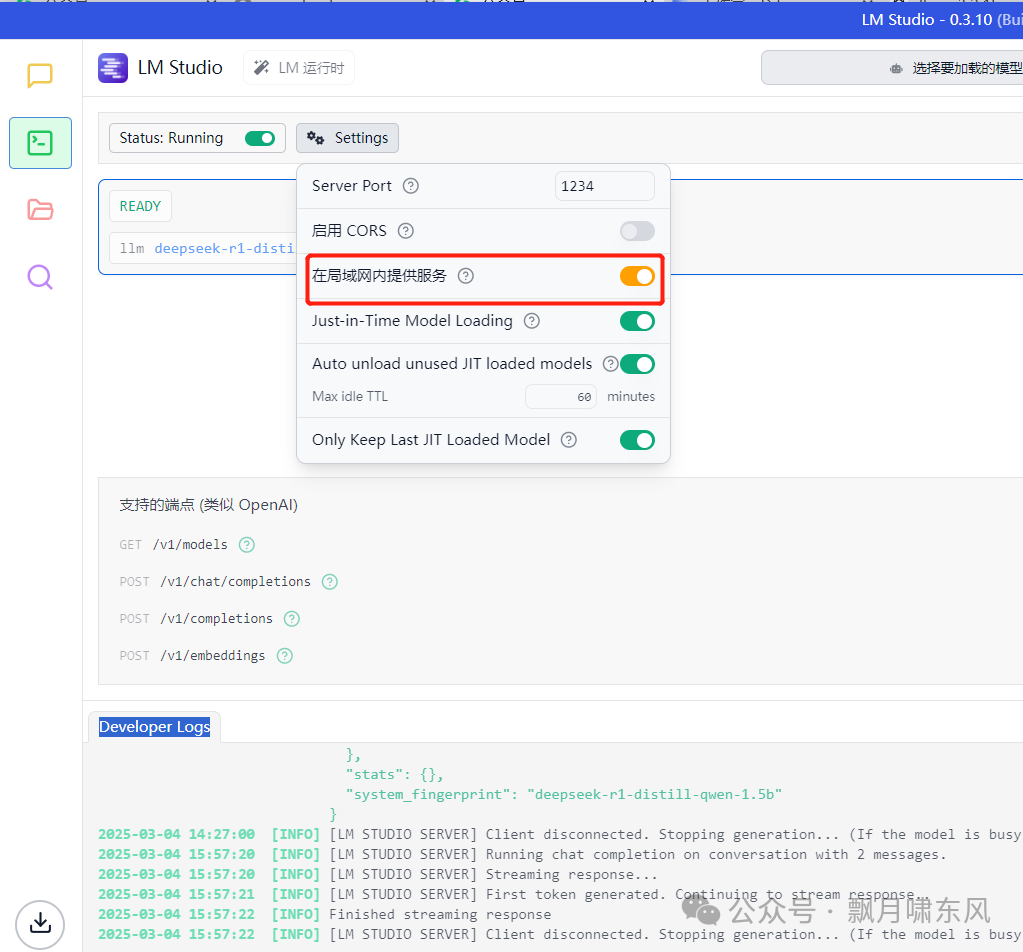
- 模型添加完成,检查蓝色按钮是打开,在系统模型设置里看到默认模型已经变为用户添加的模型了。
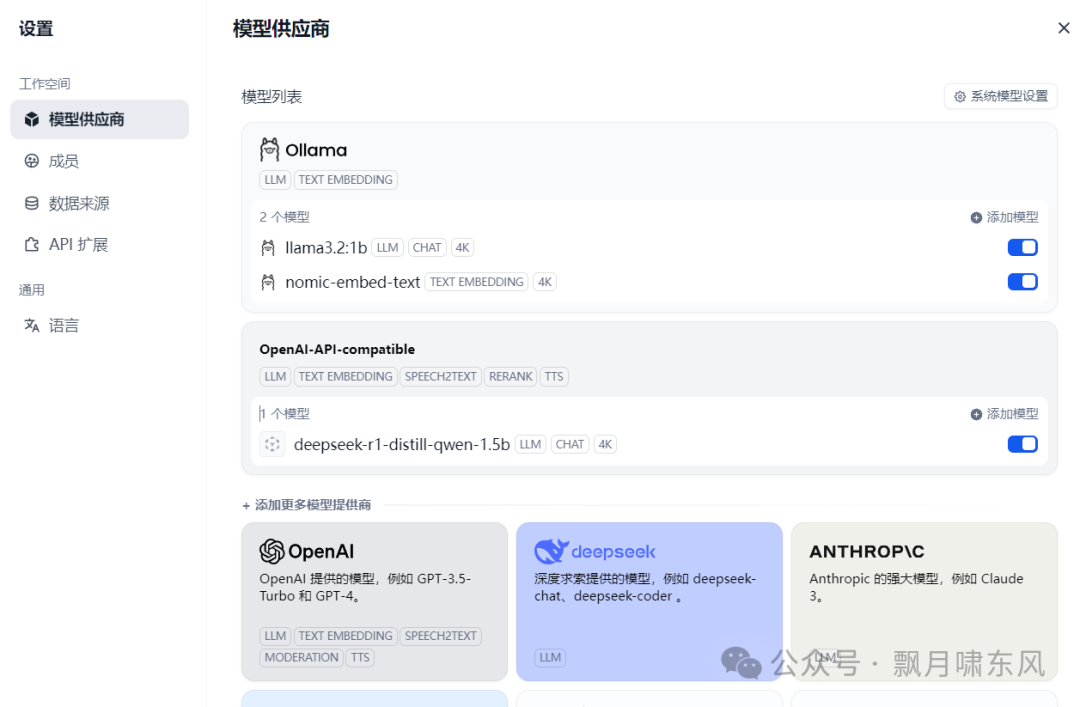
3. 其他模型
-
除了推理和嵌入模型外,还可以加入其他模型。
四、创建Dify知识库
1. 创建知识库
-
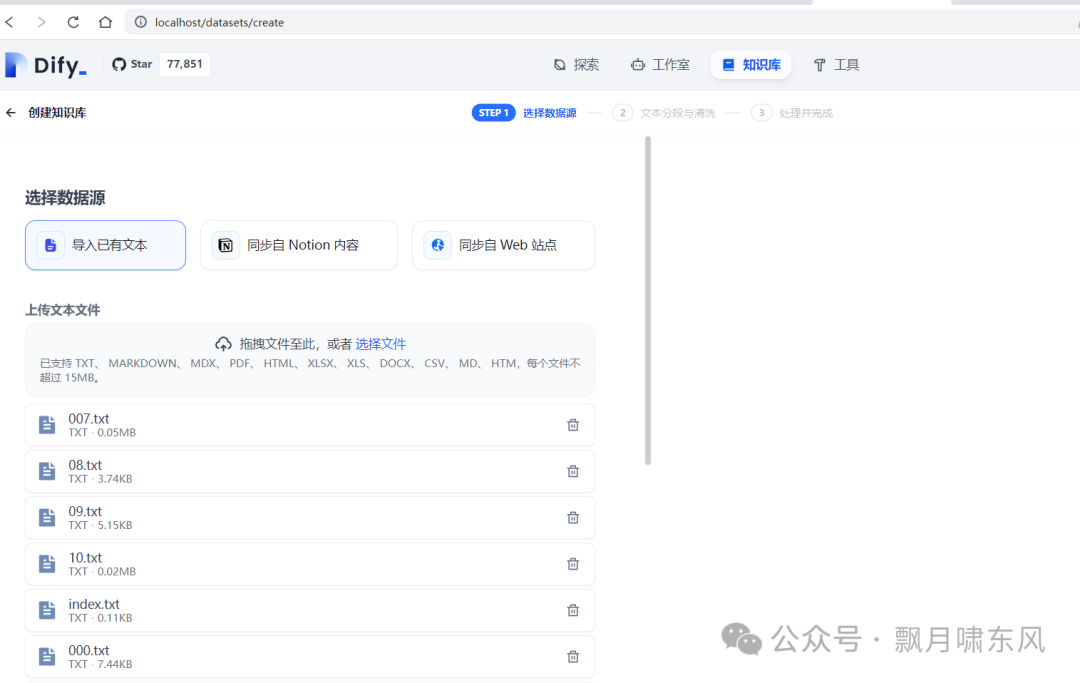
点击Dify上部的知识库菜单,选择“创建知识库”。
-
导入已有文本(可以一次拖入多个文件,但每个文件不能超过15M)。
-
设置选项包括“使用Q&A分段”(客服系统推荐选上)、索引方式、检索设置等,可以点“预览块”查看效果。
-
如果上一步没有设置嵌入模型,索引方式只能选择“经济”。
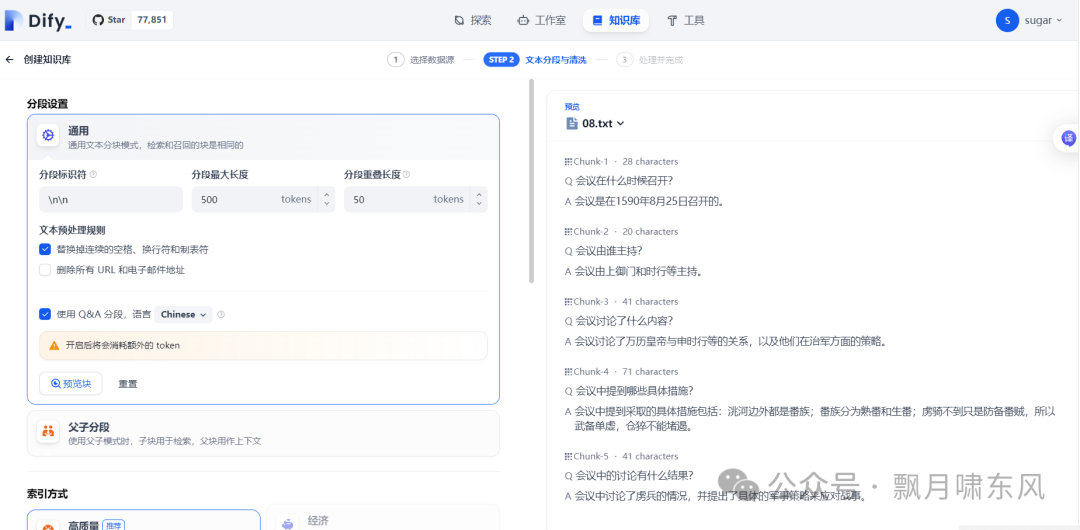
-
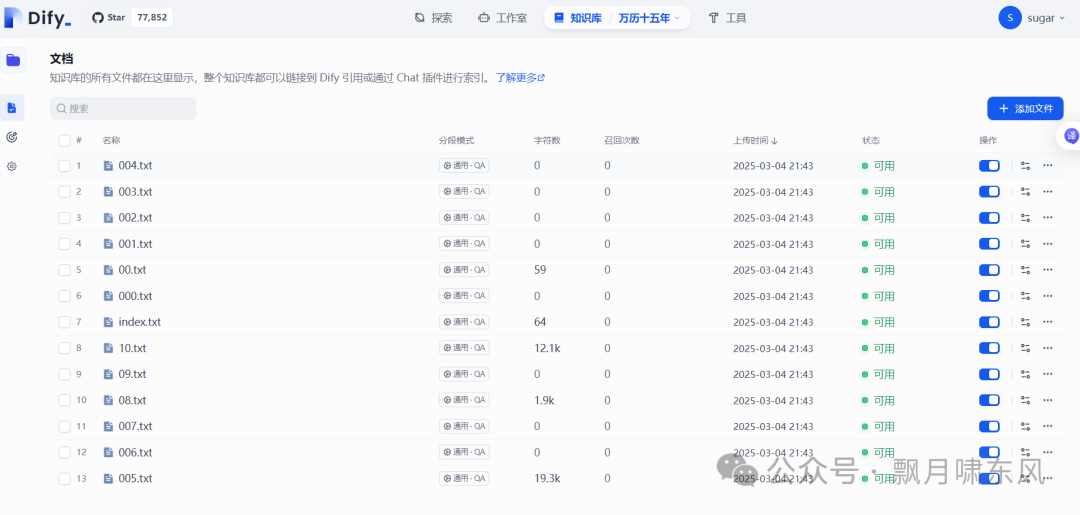
等待处理完成后进入知识库查看,可以追加文件或关闭某个文件的引用。
五、Dify工作室
1. 创建应用
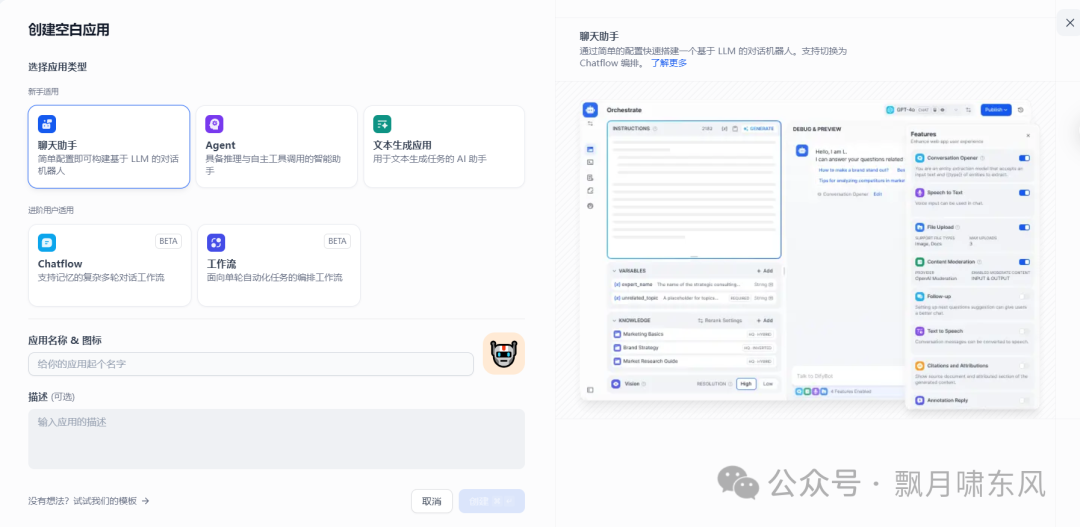
-
点击Dify上部的工作室菜单,默认可以创建聊天助手、Agent、workflow等应用。
-
这三种应用的灵活性依次增强,开发难度也相应增加。
-
如果不确定如何创建应用,可以选择从模板创建,并根据需求进行修改。
2. 聊天助手
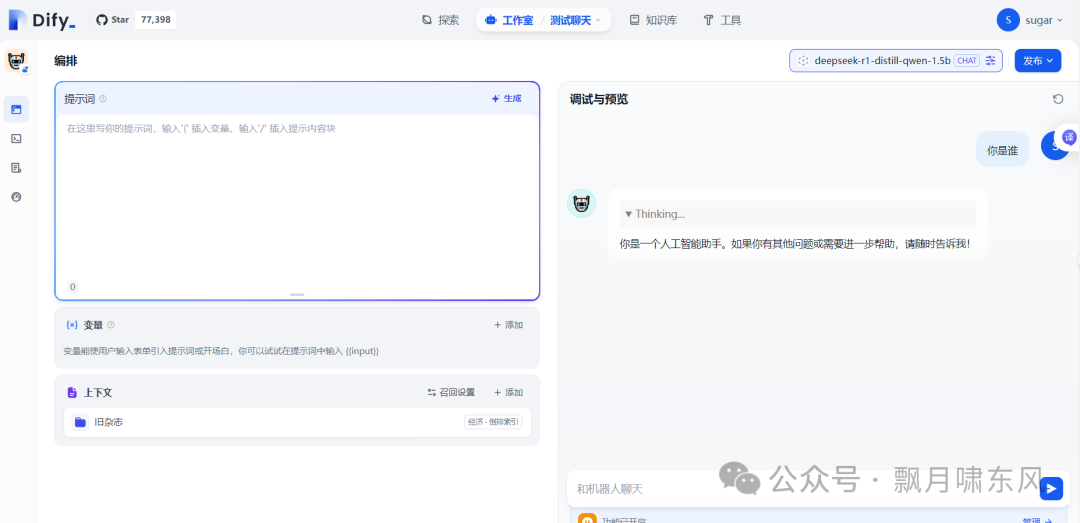
-
可以设计提示词,挂载上一步创建的知识库,选择预设的模型,还能加入开场白、调整模型参数等,主要用于客服、面试等,省去了自己开发聊天框的时间,还提供API调用和嵌入网页的选项。
-
在日志菜单中可以查看所有聊天记录,在监测菜单中可以看到应用的使用情况统计图表。
-
需要注意的是,用户使用该应用时,即使在聊天框中点击了“删除聊天记录”,聊天记录仍然会保存在服务器上。这也是我不喜欢使用第三方提供的大模型的原因。如果第三方使用本地部署的模型,聊天记录会被第三方保存和使用;如果第三方使用的是官方API,聊天记录则会被官方和第三方同时使用。模型概念火爆的当下,很多第三方公司都能靠接入别家模型引流。但我认为随着大模型厂商应用的完善,这些第三方公司会倒闭一大半,没有自主模型就不具有定价权,靠什么留住用户值得深思。
3. Agent(智能体)
-
在聊天助手的基础上允许加入工具,包括计算、翻译、天气查询、自定义工作流等,可以理解LLM大模型是基础,智能体是应用程序。
-
有些第三方提供的工具需要输入API Key。
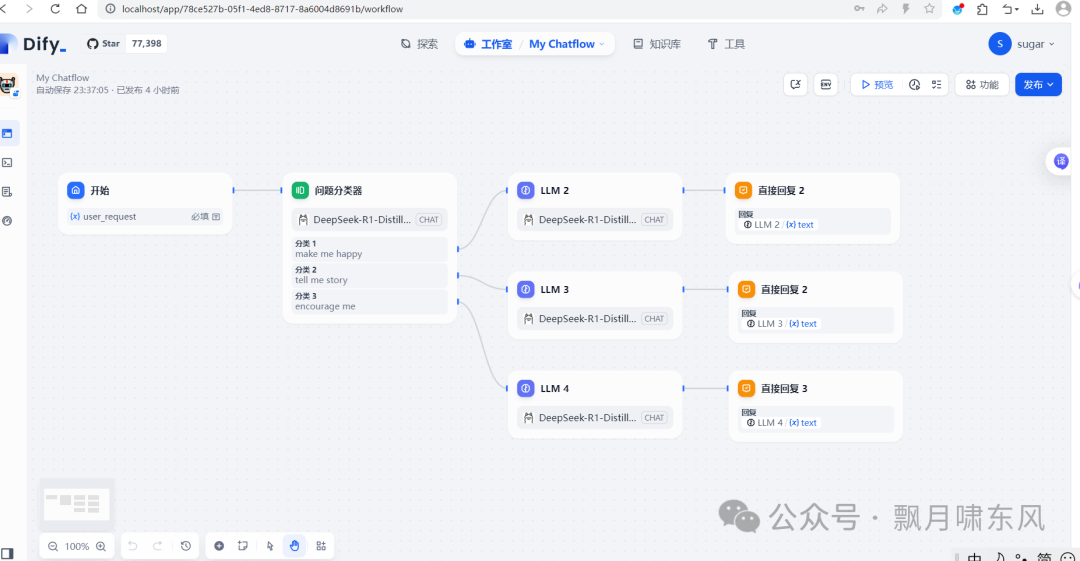
4. Workflow(工作流)
-
可以自由编排任务流,通过拖拉工具和大模型组件实现。
-
上一个任务的输出作为下一个任务的输入,除了默认参数还可以加入自定义参数。对于使用过Jenkins、Airflow、autoML等工具的同学,应该会感到熟悉。
-
可以加入代码组件,调用Python、JS程序。我尝试用Python调用一个shell命令,提示“error: operation not permitted”,可见也不能为所欲为,主要还是对参数进行处理。
总结:
Ollama+daify部署比较简单,对硬件要求也不高,主要是docker的安装(换国内镜像)和局域网设置可能会遇到问题。大模型部署跟云计算类似,可分为公有/私有/混合,公有的更新快、性能好、使用方便、不需要运维,私有的保护隐私、限制少、灵活性高,须根据实际需要进行选择。
今天的分享就到这里,有遗漏或错误的地方,欢迎指正,谢谢!
6.2 系统的持续优化
通过数据反馈、模型微调和算法优化,AI大模型问答系统能够不断进化。这使得系统不仅能够适应新兴问题,还能处理日益复杂的用户需求,为用户提供更加智能的服务。
如何学习AI大模型 ?
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
倘若大家对大模型抱有兴趣,那么这套大模型学习资料肯定会对你大有助益。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 1854
1854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











