






写在最后
可能有人会问我为什么愿意去花时间帮助大家实现求职梦想,因为我一直坚信时间是可以复制的。我牺牲了自己的大概十个小时写了这片文章,换来的是成千上万的求职者节约几天甚至几周时间浪费在无用的资源上。

上面的这些(算法与数据结构)+(Java多线程学习手册)+(计算机网络顶级教程)等学习资源
runtime.notifyNativeAllocation();
}
} else {
runtime.registerNativeAllocation(size);
}
}
1.1 Malloc内存
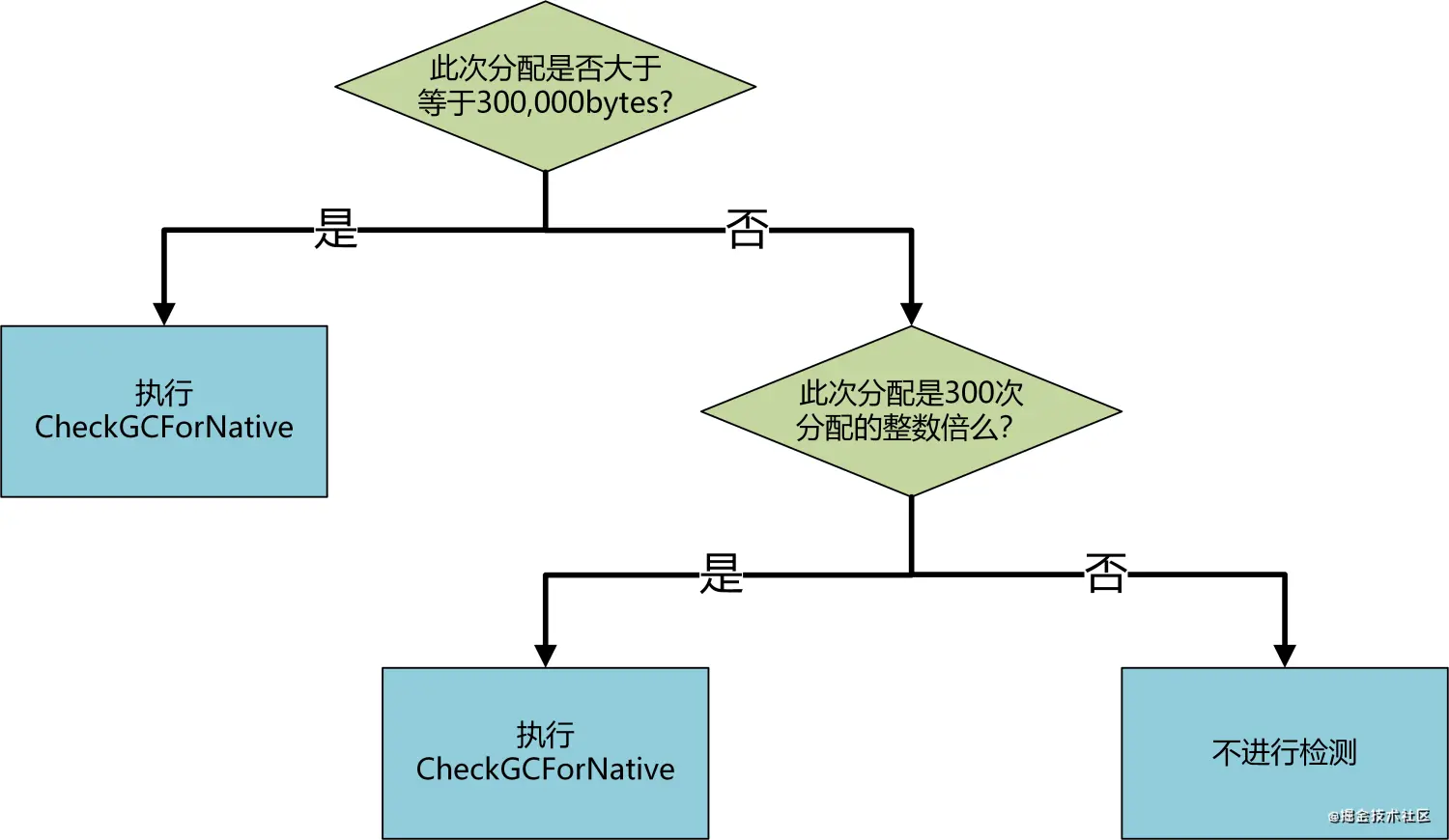
Malloc分配的内存会有两个判断条件。
- 此次分配是否大于等于300,000bytes。大于的话则走VIP通道直接执行
CheckGCForNative函数。该函数内部会统计native内存分配的总量,判断其是否达到GC触发的阈值。如果达到的话则触发一次GC。 - 此次分配是否是300次分配的整数倍。这个判定条件用于限定
CheckGCForNative的执行次数,每300次malloc才去执行一次检测。
接下来看看CheckGCForNative函数内部的逻辑。
首先计算当前native内存的总大小,然后计算当前内存大小和阈值之间的比值,如果比值≥1,则请求一次新的GC。
inline void Heap::CheckGCForNative(Thread* self) {
bool is_gc_concurrent = IsGcConcurrent();
size_t current_native_bytes = GetNativeBytes(); <================获取native内存的总大小
float gc_urgency = NativeMemoryOverTarget(current_native_bytes, is_gc_concurrent); <============计算当前内存大小和阈值之间的比值,大于等于1则表明需要一次新的GC
if (UNLIKELY(gc_urgency >= 1.0)) {
if (is_gc_concurrent) {
RequestConcurrentGC(self, kGcCauseForNativeAlloc, /force_full=/true); <=================请求一次新的GC
if (gc_urgency > kStopForNativeFactor
&& current_native_bytes > stop_for_native_allocs_) {
// We’re in danger of running out of memory due to rampant native allocation.
if (VLOG_IS_ON(heap) || VLOG_IS_ON(startup)) {
LOG(INFO) << "Stopping for native allocation, urgency: " << gc_urgency;
}
WaitForGcToComplete(kGcCauseForNativeAlloc, self);
}
} else {
CollectGarbageInternal(NonStickyGcType(), kGcCauseForNativeAlloc, false);
}
}
}
获取当前native内存的总大小需要调用GetNativeBytes函数。其内部统计也分为两部分,一部分是通过mallinfo获取的当前malloc的总大小。由于系统有专门的API获取这个信息,所以在NativeAllocationRegistry.registerNativeAllocation的时候不需要专门去存储单次malloc的大小。另一部分是native_bytes_registered_字段记录的所有注册过的mmap大小。二者相加,基本上反映了当前进程native内存的整体消耗。
size_t Heap::GetNativeBytes() {
size_t malloc_bytes;
#if defined(BIONIC) || defined(GLIBC)
IF_GLIBC(size_t mmapped_bytes;)
struct mallinfo mi = mallinfo();
// In spite of the documentation, the jemalloc version of this call seems to do what we want,
// and it is thread-safe.
if (sizeof(size_t) > sizeof(mi.uordblks) && sizeof(size_t) > sizeof(mi.hblkhd)) {
// Shouldn’t happen, but glibc declares uordblks as int.
// Avoiding sign extension gets us correct behavior for another 2 GB.
malloc_bytes = (unsigned int)mi.uordblks;
IF_GLIBC(mmapped_bytes = (unsigned int)mi.hblkhd;)
} else {
malloc_bytes = mi.uordblks;
IF_GLIBC(mmapped_bytes = mi.hblkhd;)
}
// From the spec, it appeared mmapped_bytes <= malloc_bytes. Reality was sometimes
// dramatically different. (b/119580449 was an early bug.) If so, we try to fudge it.
// However, malloc implementations seem to interpret hblkhd differently, namely as
// mapped blocks backing the entire heap (e.g. jemalloc) vs. large objects directly
// allocated via mmap (e.g. glibc). Thus we now only do this for glibc, where it
// previously helped, and which appears to use a reading of the spec compatible
// with our adjustment.
#if defined(GLIBC)
if (mmapped_bytes > malloc_bytes) {
malloc_bytes = mmapped_bytes;
}
#endif // GLIBC
#else // Neither Bionic nor Glibc
// We should hit this case only in contexts in which GC triggering is not critical. Effectively
// disable GC triggering based on malloc().
malloc_bytes = 1000;
#endif
return malloc_bytes + native_bytes_registered_.load(std::memory_order_relaxed);
// An alternative would be to get RSS from /proc/self/statm. Empirically, that’s no
// more expensive, and it would allow us to count memory allocated by means other than malloc.
// However it would change as pages are unmapped and remapped due to memory pressure, among
// other things. It seems risky to trigger GCs as a result of such changes.
}
得到当前进程native内存的总大小之后,便需要抉择是否需要一次新的GC。
决策的过程如下,源码下面是详细解释。
// Return the ratio of the weighted native + java allocated bytes to its target value.
// A return value > 1.0 means we should collect. Significantly larger values mean we’re falling
// behind.
inline float Heap::NativeMemoryOverTarget(size_t current_native_bytes, bool is_gc_concurrent) {
// Collection check for native allocation. Does not enforce Java heap bounds.
// With adj_start_bytes defined below, effectively checks
// + c1* + c2*<new native allocd) >= adj_start_bytes,
// where c3 > 1, and currently c1 and c2 are 1 divided by the values defined above.
size_t old_native_bytes = old_native_bytes_allocated_.load(std::memory_order_relaxed);
if (old_native_bytes > current_native_bytes) {
// Net decrease; skip the check, but update old value.
// It’s OK to lose an update if two stores race.
old_native_bytes_allocated_.store(current_native_bytes, std::memory_order_relaxed);
return 0.0;
} else {
size_t new_native_bytes = UnsignedDifference(current_native_bytes, old_native_bytes); <=(1)
size_t weighted_native_bytes = new_native_bytes / kNewNativeDiscountFactor <=(2)
- old_native_bytes / kOldNativeDiscountFactor;
size_t add_bytes_allowed = static_cast<size_t>( <=(3)
NativeAllocationGcWatermark() * HeapGrowthMultiplier());
size_t java_gc_start_bytes = is_gc_concurrent <=(4)
? concurrent_start_bytes_
: target_footprint_.load(std::memory_order_relaxed);
size_t adj_start_bytes = UnsignedSum(java_gc_start_bytes, <=(5)
add_bytes_allowed / kNewNativeDiscountFactor);
return static_cast(GetBytesAllocated() + weighted_native_bytes) <=(6)
/ static_cast(adj_start_bytes);
}
}
首先将本次native内存总大小和上一次GC完成后的native内存总大小进行比较。如果小于上次的总大小,则表明native内存的使用水平降低了,因此完全没有必要进行一次新的GC。
但如果这次native内存使用增长的话,则需要进一步计算当前值和阈值之间的比例关系,大于等于1的话就需要进行GC。下面详细介绍源码中的(1)~(6)。
(1)计算本次native内存和上次之间的差值,这个差值反映了native内存中新增长部分的大小。
(2)给不同部分的native内存以不同的权重,新增长部分除以2,旧的部分除以65536。之所以给旧的部分权重如此之低,是因为native堆本身是没有上限的。这套机制的初衷并不是限制native堆的大小,而只是防止两次GC间native内存垃圾积累过多。
(3)所谓的阈值并不是为native内存单独设立的,而是为(Java堆大小+native内存大小)整体设立的。add_bytes_allowed表示在原有Java堆阈值的基础上,还可以允许的native内存大小。NativeAllocationGcWatermark根据Java堆阈值计算出允许的native内存大小,Java堆阈值越大,允许的值也越大。HeapGrowthMultipiler对于前台应用是2,表明前台应用的内存管控更松,GC触发频率更低。
(4)同等条件下,同步GC的触发水位要低于非同步GC,原因是同步GC在垃圾回收时也会有新的对象分配,因此加上这些新分配的对象最好也不要超过阈值。
(5)将Java堆阈值和允许的native内存相加,作为新的阈值。
(6)将Java堆已分配的大小和调整权重后的native内存大小相加,并将相加后的结果除以阈值,得到一个比值来判定是否需要GC。
通过如下代码可知,当比值≥1时,将请求一次新的GC。
if (UNLIKELY(gc_urgency >= 1.0)) {
if (is_gc_concurrent) {
RequestConcurrentGC(self, kGcCauseForNativeAlloc, /force_full=/true); <=================请求一次新的GC
1.2 MMap内存
mmap的处理方式和malloc基本相当,大于300,000 bytes或mmap三百次都执行CheckGCForNative。唯一的区别在于mmap需要将每一次的大小都计入native_bytes_registered中,因为mallinfo中并不会记录这个信息(针对bionic库而言)。
void Heap::RegisterNativeAllocation(JNIEnv* env, size_t bytes) {
// Cautiously check for a wrapped negative bytes argument.
DCHECK(sizeof(size_t) < 8 || bytes < (std::numeric_limits<size_t>::max() / 2));
native_bytes_registered_.fetch_add(bytes, std::memory_order_relaxed);
uint32_t objects_notified =
native_objects_notified_.fetch_add(1, std::memory_order_relaxed);
if (objects_notified % kNotifyNativeInterval == kNotifyNativeInterval - 1
|| bytes > kCheckImmediatelyThreshold) {
CheckGCForNative(ThreadForEnv(env));
}
}
2. 如何在Java对象回收时触发native内存回收
NativeAllocationRegistry中主要依靠Cleaner机制完成了这个过程。关于Cleaner的细节,可以参考我的上篇博客。
3. 实际案例
Bitmap类就是通过NativeAllocationRegistry来实现native资源自动释放的。以下是Bitmap构造方法的一部分。
最后,附一张自己面试前准备的脑图:
面试前一定少不了刷题,为了方便大家复习,我分享一波个人整理的面试大全宝典
- Java核心知识整理
- Spring全家桶(实战系列)
Step3:刷题
既然是要面试,那么就少不了刷题,实际上春节回家后,哪儿也去不了,我自己是刷了不少面试题的,所以在面试过程中才能够做到心中有数,基本上会清楚面试过程中会问到哪些知识点,高频题又有哪些,所以刷题是面试前期准备过程中非常重要的一点。
以下是我私藏的面试题库:
很多人感叹“学习无用”,实际上之所以产生无用论,是因为自己想要的与自己所学的匹配不上,这也就意味着自己学得远远不够。无论是学习还是工作,都应该有主动性,所以如果拥有大厂梦,那么就要自己努力去实现它。
最后祝愿各位身体健康,顺利拿到心仪的offer!
有主动性,所以如果拥有大厂梦,那么就要自己努力去实现它。
最后祝愿各位身体健康,顺利拿到心仪的offer!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









