 10行代码实现大模型本地部署
10行代码实现大模型本地部署





Ollama Model Zoo
https://ollama.com/search
Ollama 实践: 本地运行大模型
在本地运行开源LLM比大多数人想象的要容易得多。今天,我们就来一步一步地进行实际操作演示。最终结果如下:

我们将使用 Ollama 运行 Microsoft 的 phi-2,Ollama 是一个框架,可以直接从本地计算机运行开源 LLM(Llama2、Llama3 等)。
下载 Ollama
访问Ollama.com,下载 Ollama 并安装它。
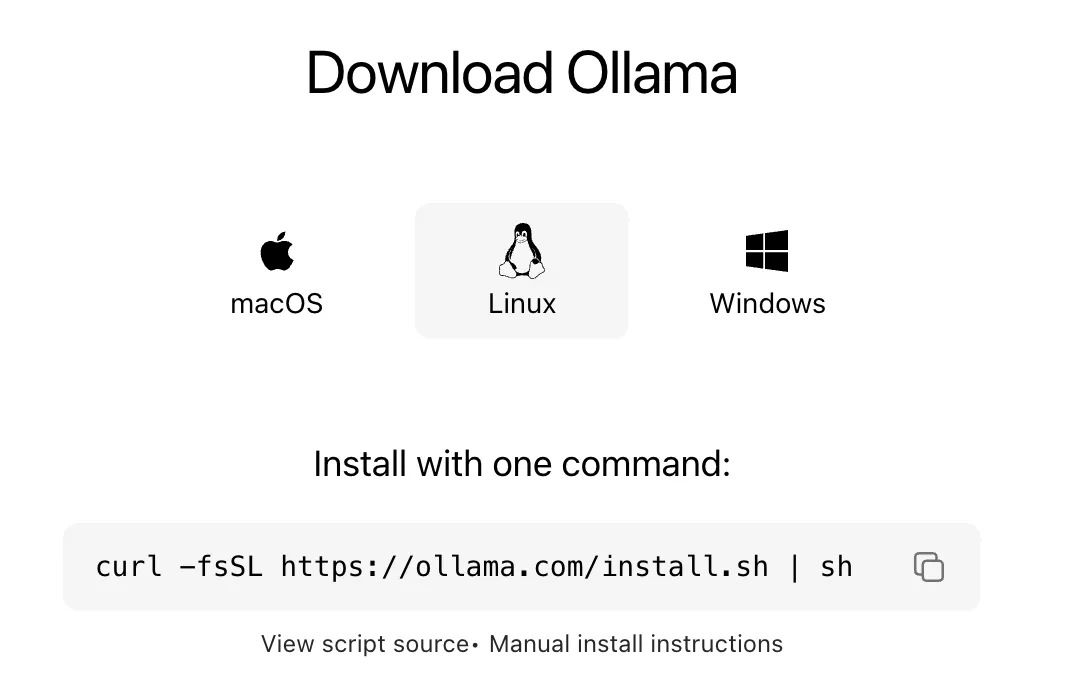
Ollama 支持多种开源模型。以下列出部分模型及其下载命令:
下载 phi-2
接下来,运行以下命令下载phi-2:

您的终端将显示以下内容:
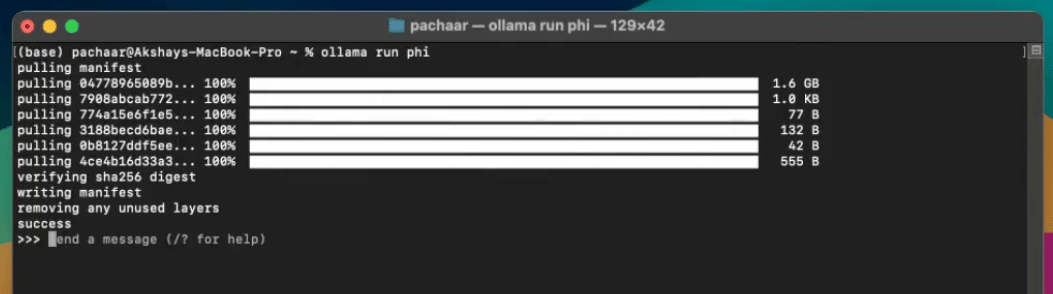
完毕!
使用本地模型
开源 LLM 现在正在您的本地计算机上运行,您可以按如下方式向其发出指令:

定制模型
通过 Ollama 运行的模型可以通过提示进行自定义。假设你想自定义 phi-2,让它像马里奥一样说话。复制现有文件modelfile:

接下来,打开新文件并编辑PROMPT设置:

接下来,按如下方式创建您的自定义模型:

完毕!
现在运行mario模型:

这样就可以在本地使用LLM了。也就是说,Ollama 可以与几乎所有 LLM 编排框架(如 LlamaIndex、Langchain 等)优雅地集成,这使得在开源 LLM 上构建 LLM 应用程序变得更加容易。
Streaming & Thinking
**Streaming:**流式传输(Streaming)允许您在模型生成文本的同时渲染文本。REST API 默认启用流式传输,但 SDK 默认禁用流式传输。要在 SDK 中启用流式传输,请将stream参数设置为True。
Thinking:具有思考能力的模型会返回一个thinking字段,该字段将它们的推理过程与最终答案分开。使用此功能可以审核模型步骤、在用户界面中演示模型思考过程,或者在只需要最终响应时完全隐藏跟踪过程。
可以在https://ollama.com/search?c=thinking这里查到所有支持 Thinking 的模型。
- 聊天:流式传输部分助手消息。每个数据块都包含消息,
content以便您可以在消息到达时立即渲染它们。 - 思考:具备思考能力的模型会
thinking在每个数据块中除了常规内容外,还会输出一个字段。在流式数据块中检测此字段,即可在最终答案到达之前显示或隐藏推理过程。 - 工具调用:监视
tool_calls每个数据块中的流,执行请求的工具,并将工具输出附加回对话中。
结构化输出
参考文档:https://docs.ollama.com/capabilities/structured-outputs
from ollama import chatfrom pydantic import BaseModelclass Country(BaseModel): name: str capital: str languages: list[str]response = chat( model='gpt-oss', messages=[{'role': 'user', 'content': 'Tell me about Canada.'}], format=Country.model_json_schema(),)country = Country.model_validate_json(response.message.content)print(country)
输出示例:
name=‘Canada’ capital=‘Ottawa’ languages=[‘English’, ‘French’, ‘Official languages: English and French (French is the majority in Quebec)’]
视觉任务
- Lower the temperature (e.g., set it to
0) for more deterministic completions.
from ollama import chatfrom pydantic import BaseModelfrom typing import Literal, Optionalclass Object(BaseModel): name: str confidence: float attributes: strclass ImageDescription(BaseModel): summary: str objects: list[Object] scene: str colors: list[str] time_of_day: Literal['Morning', 'Afternoon', 'Evening', 'Night'] setting: Literal['Indoor', 'Outdoor', 'Unknown'] text_content: Optional[str] = Noneresponse = chat( model='gemma3', messages=[{ 'role': 'user', 'content': 'Describe this photo and list the objects you detect.', 'images': ['path/to/image.jpg'], }], format=ImageDescription.model_json_schema(), options={'temperature': 0},)image_description = ImageDescription.model_validate_json(response.message.content)print(image_description)
工具调用
from ollama import chatdef get_temperature(city: str) -> str: """Get the current temperature for a city Args: city: The name of the city Returns: The current temperature for the city """ temperatures = { "New York": "22°C", "London": "15°C", "Tokyo": "18°C" } return temperatures.get(city, "Unknown")def get_conditions(city: str) -> str: """Get the current weather conditions for a city Args: city: The name of the city Returns: The current weather conditions for the city """ conditions = { "New York": "Partly cloudy", "London": "Rainy", "Tokyo": "Sunny" } return conditions.get(city, "Unknown")messages = [{'role': 'user', 'content': 'What are the current weather conditions and temperature in New York and London?'}]# The python client automatically parses functions as a tool schema so we can pass them directly# Schemas can be passed directly in the tools list as well response = chat(model='qwen3', messages=messages, tools=[get_temperature, get_conditions], think=True)# add the assistant message to the messagesmessages.append(response.message)if response.message.tool_calls: # process each tool call for call in response.message.tool_calls: # execute the appropriate tool if call.function.name == 'get_temperature': result = get_temperature(**call.function.arguments) elif call.function.name == 'get_conditions': result = get_conditions(**call.function.arguments) else: result = 'Unknown tool' # add the tool result to the messages messages.append({'role': 'tool', 'tool_name': call.function.name, 'content': str(result)}) # generate the final response final_response = chat(model='qwen3', messages=messages, tools=[get_temperature, get_conditions], think=True) print(final_response.message.content)
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 22万+
22万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









