






环境准备
1.VMware虚拟机(Linux操作系统)
2.Windows7~11
3.JDK
4.HadoopHadoop安装及集群环境配置_hadoop环境搭建与安装-优快云博客 https://blog.youkuaiyun.com/2301_81921110/article/details/139362063?spm=1001.2014.3001.55015.spark和sbt
https://blog.youkuaiyun.com/2301_81921110/article/details/139362063?spm=1001.2014.3001.55015.spark和sbt
spark安装和编程实践(Spark2.1.0)-优快云博客https://blog.youkuaiyun.com/2301_81921110/article/details/139398991?spm=1001.2014.3001.55016.Xshell 7(用于连接虚拟机与Windows)
Xshell 7与Xftp 7使用教程-优快云博客https://blog.youkuaiyun.com/2301_81921110/article/details/139377831?spm=1001.2014.3001.55017.Xftp 7(用于虚拟机与Windows之间传输文件)
一、启动虚拟机并在Windows中使用Xshell 7连接虚拟机
二、在Ubuntu本地新建一个文件,命名为:2024.txt,内容如下:
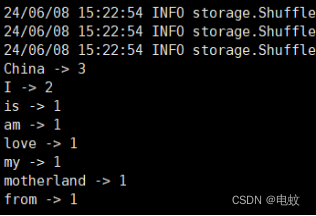
China is my motherland
I love China
I am from China
请对文件内单词进行词频统计。
1、启动hadoop
start-all.sh
2、启动spark shell
①cd /usr/local/spark
②bin/spark-shell # 启动spark shell
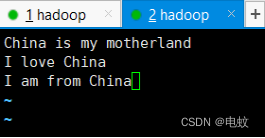
3、在Ubuntu本地新建一个文件,命名为:2024.txt,内容如下:
China is my motherland
I love China
I am from China
重新打开一个终端,在其中创建2024.txt文件;
vim 2024.txt
①spark shell运行代码:
scala> val lines = sc.textFile("file:///home/hadoop/2024.txt")
scala> val words=lines.flatMap(line => line.split(" "))
scala> var wordcount = words.map(word=>(word,1)).groupByKey()
scala> wordcount.foreach(println)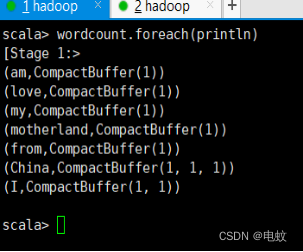
scala> var wordcount1 = words.map(word=>(word,1)).reduceByKey((a,b)=>a+b)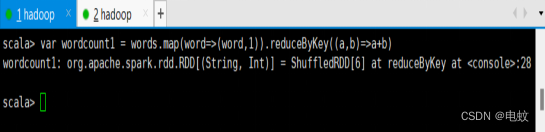
scala> wordcount1.foreach(println)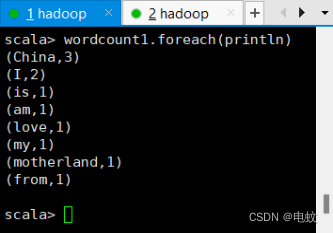
②Scala应用程序代码:
(在./sparkapp/src/main/scala下建立一个名为2024_1.scala的文件)
vim ./sparkapp/src/main/scala/2024_1.scala
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object WordCountProgram extends App {
val sparkConf = new SparkConf().setAppName("Word Count Application")
val spark = SparkSession.builder.config(sparkConf).getOrCreate()
// 读取文件
val lines = spark.sparkContext.textFile("file:///home/hadoop/2024.txt")
// 分割单词
val words = lines.flatMap(line => line.split(" "))
// 使用groupByKey进行词频统计(不推荐,因为效率较低)
val wordCountGroupByKey: RDD[(String, Iterable[Int])] = words.map(word => (word, 1)).groupByKey()
println("Using groupByKey:")
wordCountGroupByKey.foreach{case (word, counts) => println(s"$word -> ${counts.sum}")}
// 使用reduceByKey进行高效的词频统计
val wordCountReduceByKey: RDD[(String, Int)] = words.map(word => (word, 1)).reduceByKey(_ + _)
println("\nUsing reduceByKey:")
wordCountReduceByKey.foreach{case (word, count) => println(s"$word -> $count")}
spark.stop()
}cd ~/sparkapp
find .
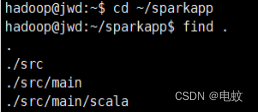
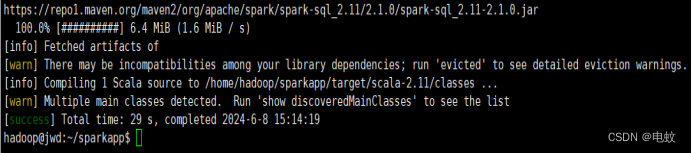
通过如下代码将整个应用程序打包成JAR:
/usr/local/sbt/sbt package
打包成功会输出如下内容:
生成的jar包的位置为 ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar。
通过spark-submit运行程序,命令如下:
/usr/local/spark/bin/spark-submit --class "WordCountProgram" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar
运行结果如下:
三、给出一组键值对数据:("c",8), ("b",25), ("c",17), ("a",42), ("b",4), ("d",9), ("e",17), ("c",2), ("f",29), ("g",21), ("b",9),请分别根据key和values的大小进行降序排列。要求有代码和执行截图。
1、spark shell运行代码:
scala>val d1 = sc.parallelize(Array(("c",8),("b",25),("c",17),("a",42),("b",4),("d",9),("e",17),("c",2),("f",29),("g",21),("b",9)))
scala>d1.reduceByKey(_+_).sortByKey(false).collect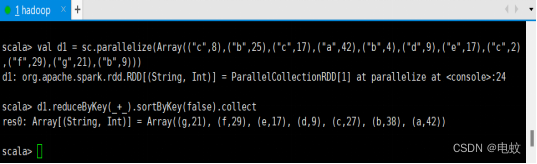
scala>val d2 = sc.parallelize(Array(("c",8),("b",25),("c",17),("a",42),("b",4),("d",9),("e",17),("c",2),("f",29),("g",21),("b",9)))
scala>d2.reduceByKey(_+_).sortBy(_._2,false).collect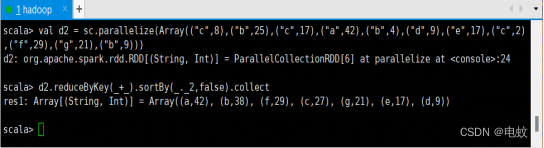
2、Scala应用程序代码:
(在./sparkapp/src/main/scala下建立一个名为2024_2.scala的文件)
①cd ~
②vim ./sparkapp/src/main/scala/2024_2.scala
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
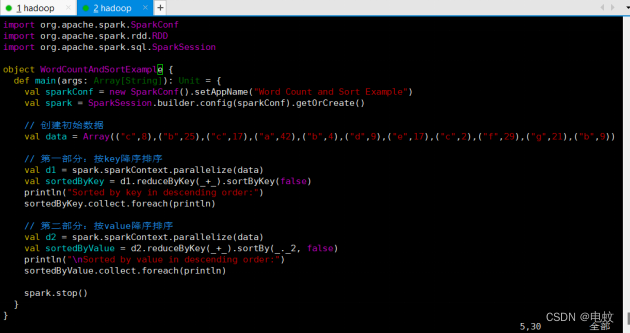
object WordCountAndSortExample {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("Word Count and Sort Example")
val spark = SparkSession.builder.config(sparkConf).getOrCreate()
// 创建初始数据
val data = Array(("c",8),("b",25),("c",17),("a",42),("b",4),("d",9),("e",17),("c",2),("f",29),("g",21),("b",9))
// 第一部分:按key降序排序
val d1 = spark.sparkContext.parallelize(data)
val sortedByKey = d1.reduceByKey(_+_).sortByKey(false)
println("Sorted by key in descending order:")
sortedByKey.collect.foreach(println)
// 第二部分:按value降序排序
val d2 = spark.sparkContext.parallelize(data)
val sortedByValue = d2.reduceByKey(_+_).sortBy(_._2, false)
println("\nSorted by value in descending order:")
sortedByValue.collect.foreach(println)
spark.stop()
}
}
③cd ~/sparkapp
通过如下代码将整个应用程序打包成JAR:
④/usr/local/sbt/sbt package
打包成功会输出如下内容:
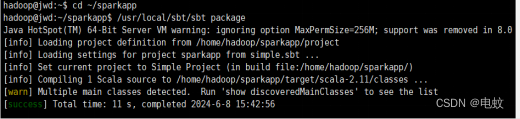
生成的jar包的位置为 ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar。
通过spark-submit运行程序,命令如下:
/usr/local/spark/bin/spark-submit --class "WordCountAndSortExample" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar
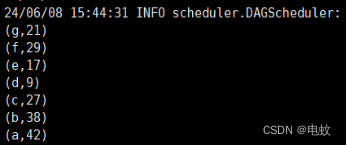
运行结果如下:
按key降序排序:
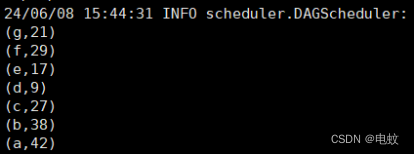
按value降序排序:
四、给出一组数据,("spark",2), ("hadoop",6), ("hadoop",4), ("spark",6), ("hadoop",5), ("spark",4),请根据数据中的key,计算values的平均值。要求有代码和执行截图。
1、spark shell运行代码:
scala>val rdd = sc.parallelize(Array(("spark",2),("hadoop",6),("hadoop",4),("spark",6)))
scala>rdd.mapValues(x => (x,1)).reduceByKey((x,y) => (x._1+y._1,x._2+y._2)).mapValues(x => (x._1/x._2)).collect().foreach(println)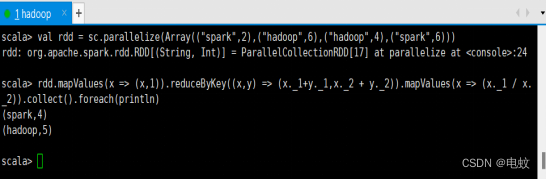
2、Scala应用程序代码:
(在./sparkapp/src/main/scala下建立一个名为2024_3.scala的文件)
①cd ~
②vim ./sparkapp/src/main/scala/2024_3.scala
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
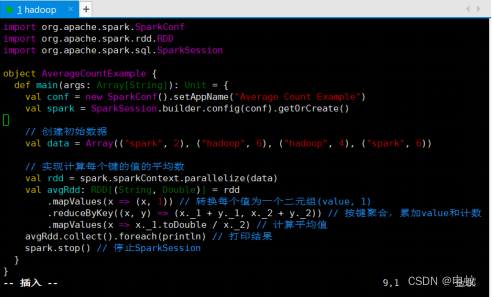
object AverageCountExample {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Average Count Example")
val spark = SparkSession.builder.config(conf).getOrCreate()
// 创建初始数据
val data = Array(("spark", 2), ("hadoop", 6), ("hadoop", 4), ("spark", 6))
// 实现计算每个键的值的平均数
val rdd = spark.sparkContext.parallelize(data)
val avgRdd: RDD[(String, Double)] = rdd
.mapValues(x => (x, 1)) // 转换每个值为一个二元组(value, 1)
.reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)) //按键聚合,累加value和计数
.mapValues(x => x._1.toDouble / x._2) // 计算平均值
avgRdd.collect().foreach(println)// 打印结果
spark.stop() // 停止SparkSession
}
}
③cd ~/sparkapp
通过如下代码将整个应用程序打包成JAR:
④/usr/local/sbt/sbt package
打包成功会输出如下内容:
生成的jar包的位置为 ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar。
通过spark-submit运行程序,命令如下:
/usr/local/spark/bin/spark-submit --class "AverageCountExample" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar
运行结果如下:
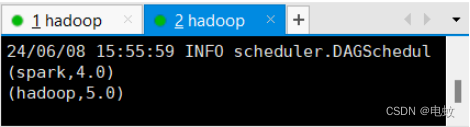


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









