






一、问题引入
海伦一直使用在线约会网站寻找适合自己的约会对象。她曾交往过三种类型的人:
-
不喜欢的人
-
一般喜欢的人
-
非常喜欢的人
这些人包含以下三种特征
-
每年获得的飞行常客里程数
-
玩视频游戏所耗时间百分比
-
每周消费的冰淇淋公升数
该网站现在需要尽可能向海伦推荐她喜欢的人,需要我们设计一个分类器,根据用户的以上三种特征,识别出是否该向海伦推荐。
二、需求概要分析
根据问题,我们可知,样本特征个数为3,样本标签为三类。现需要实现将一个待分类样本的三个特征值输入程序后,能够识别该样本的类别,并且将该类别输出。
三、程序结构设计说明
根据问题,可以知道程序大致流程如下。
输入数据——>分类器——>(喜欢/一般/不喜欢)
其中输入数据应包含三个值,输出应为喜欢,一般,不喜欢,三个中的一个。
四、K近邻算法的一般流程
-
数据准备:这包括收集、清洗和预处理数据。预处理可能包括归一化或标准化特征,以确保所有特征在计算距离时具有相等的权重。
数据示例:
40920 8.326976 0.953952 largeDoses
14488 7.153469 1.673904 smallDoses
26052 1.441871 0.805124 didntLike
75136 13.147394 0.428964 didntLike
38344 1.669788 0.134296 didntLike
72993 10.141740 1.032955 didntLike
35948 6.830792 1.213192 largeDoses
42666 13.276369 0.543880 largeDoses
67497 8.631577 0.749278 didntLike
35483 12.273169 1.508053 largeDoses
| 玩视频游戏所耗时间百分比 | 每年获得的飞行常客里程数 | 每周消费的冰淇淋的公升数 | 样本分类 | |
|---|---|---|---|---|
| 1 | 0.8 | 400 | 0.5 | 1 |
| 2 | 12 | 134000 | 0.9 | 3 |
| 3 | 0 | 20000 | 1.1 | 2 |
| 4 | 67 | 32000 | 0.1 | 2 |
我们很容易发现,当计算样本之间的距离时数字差值最大的属性对计算结果的影响最大,也就是说,每年获取的飞行常客里程数对于计算结果的影响将远远大于上表中其他两个特征-玩视频游戏所耗时间占比和每周消费冰淇淋公斤数的影响。而产生这种现象的唯一原因,仅仅是因为飞行常客里程数远大于其他特征值。但海伦认为这三种特征是同等重要的,因此作为三个等权重的特征之一,飞行常客里程数并不应该如此严重地影响到计算结果。
在处理这种不同取值范围的特征值时,我们通常采用的方法是将数值归一化,如将取值范围处理为0到1或者-1到1之间。下面的公式可以将任意取值范围的特征值转化为0到1区间内的值:
-
选择距离度量方法:确定用于比较样本之间相似性的度量方法,常见的如欧几里得距离、曼哈顿距离等。
-
确定K值:选择一个K值,即在分类或回归时应考虑的邻居数量。这是一个超参数,可以通过交叉验证等方法来选择最优的K值。
-
找到K个最近邻居:对于每一个需要预测的未标记的样本:
-
计算该样本与训练集中所有样本的距离。
-
根据距离对它们进行排序。
-
选择距离最近的K个样本
-
预测:
-
对于分类任务:查看K个最近邻居中最常见的类别,作为预测结果。例如,如果K=3,并且三个最近邻居的类别是[1, 2, 1],那么预测结果就是类别1。
-
对于回归任务:预测结果可以是K个最近邻居的平均值或加权平均值。
-
-
评估:使用适当的评价指标(如准确率、均方误差等)评估模型的性能。
-
优化:基于性能评估结果,可能需要返回并调整某些参数,如K值、距离度量方法等,以获得更好的性能。
五、算法实现
1. 数据加载模块
首先,我们需要加载数据集并将特征值与标签分离。以下是load_data函数的实现:
def load_data(filename):
"""加载数据集"""
features = []
labels = []
with open(filename, 'r') as f:
for line in f:
parts = line.strip().split('\t')
features.append([float(parts[0]), float(parts[1]), float(parts[2])])
labels.append(parts[3])
return np.array(features), np.array(labels)2. 数据可视化模块
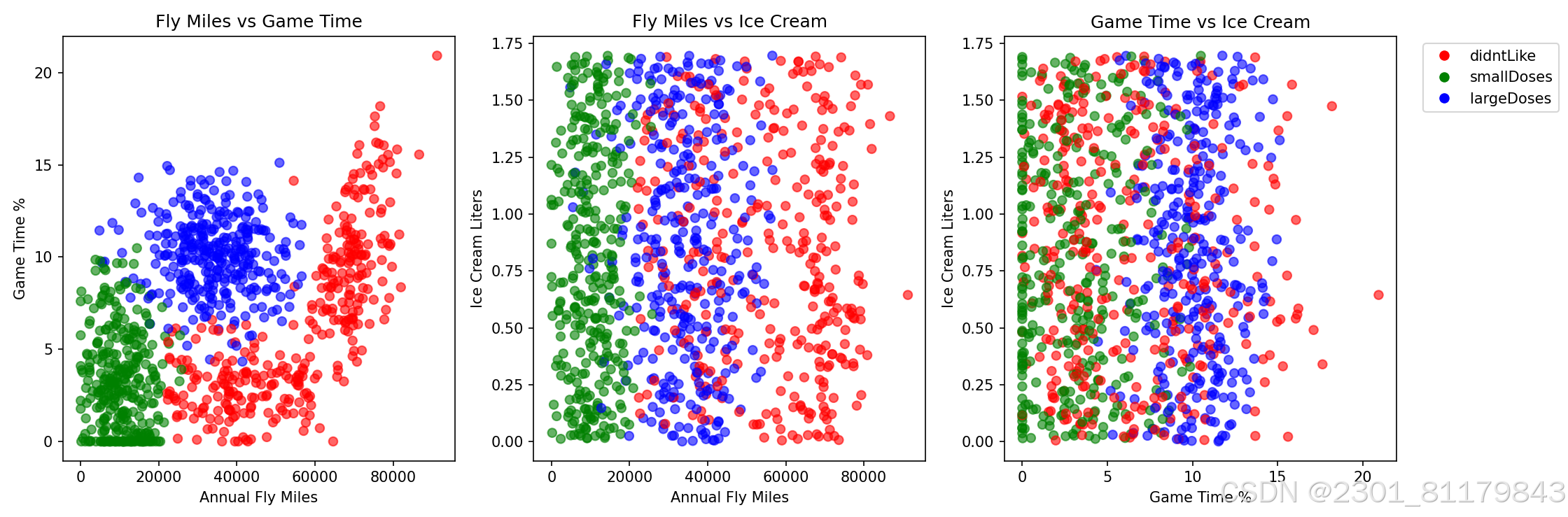
为了更好地理解数据分布,绘制了二维散点图。以下是plot_features函数的实现:
def plot_features(features, labels):
"""绘制特征二维散点图"""
# 转换为颜色映射
color_map = {
'didntLike': 'red',
'smallDoses': 'green',
'largeDoses': 'blue'
}
colors = [color_map[label] for label in labels]
plt.figure(figsize=(15, 5))
# 子图1:里程数 vs 游戏时间
plt.subplot(131)
plt.scatter(features[:, 0], features[:, 1], c=colors, alpha=0.6)
plt.xlabel('Annual Fly Miles')
plt.ylabel('Game Time %')
plt.title('Fly Miles vs Game Time')
# 子图2:里程数 vs 冰淇淋
plt.subplot(132)
plt.scatter(features[:, 0], features[:, 2], c=colors, alpha=0.6)
plt.xlabel('Annual Fly Miles')
plt.ylabel('Ice Cream Liters')
plt.title('Fly Miles vs Ice Cream')
# 子图3:游戏时间 vs 冰淇淋
plt.subplot(133)
plt.scatter(features[:, 1], features[:, 2], c=colors, alpha=0.6)
plt.xlabel('Game Time %')
plt.ylabel('Ice Cream Liters')
plt.title('Game Time vs Ice Cream')
# 添加图例
handles = [
plt.Line2D([0], [0], marker='o', color='w',
markerfacecolor=color_map['didntLike'], markersize=8),
plt.Line2D([0], [0], marker='o', color='w',
markerfacecolor=color_map['smallDoses'], markersize=8),
plt.Line2D([0], [0], marker='o', color='w',
markerfacecolor=color_map['largeDoses'], markersize=8)
]
plt.legend(handles, color_map.keys(), bbox_to_anchor=(1.05, 1), loc='upper left')
plt.tight_layout()
plt.show()3. 数据归一化模块
由于特征值的范围差异较大,我们需要对数据进行归一化处理。以下是auto_normalize函数的实现:
def auto_normalize(data):
"""数据归一化"""
min_vals = data.min(0)
max_vals = data.max(0)
ranges = max_vals - min_vals
ranges[ranges == 0] = 1 # 处理0值范围
norm_data = (data - min_vals) / ranges
return norm_data, min_vals, ranges4. 数据集分割模块
为了评估模型性能,我们需要将数据集划分为训练集和测试集。以下是split_dataset函数的实现:
def split_dataset(features, labels, test_ratio=0.2):
"""分割数据集"""
n = len(features)
indices = list(range(n))
random.shuffle(indices)
test_size = int(n * test_ratio)
train_indices = indices[test_size:]
test_indices = indices[:test_size]
return features[train_indices], labels[train_indices], \
features[test_indices], labels[test_indices]5. KNN分类器实现
KNN算法的核心部分是计算距离并找到最近的K个邻居。以下是knn_classify函数的实现:
def knn_classify(train_data, train_labels, test_sample, k=3):
"""KNN分类算法"""
distances = np.sqrt(np.sum((train_data - test_sample)**2, axis=1))
nearest_indices = distances.argsort()[:k]
nearest_labels = train_labels[nearest_indices]
counter = Counter(nearest_labels)
return counter.most_common(1)[0][0]6. 性能评估模块
为了评估分类器的性能,我们计算了测试集上的准确率。以下是classifier_accuracy函数的实现:
def classifier_accuracy(test_data, test_labels, train_data, train_labels, k=3):
"""计算分类器准确率"""
correct = 0
for i in range(len(test_data)):
pred_label = knn_classify(train_data, train_labels, test_data[i], k)
if pred_label == test_labels[i]:
correct += 1
return correct / len(test_data)7. 主程序模块
以下是main函数的实现:
def main():
# 1. 加载数据
features, labels = load_data('data.txt')
# 新增可视化部分
plot_features(features, labels)
# 2. 数据预处理
train_data, train_labels, test_data, test_labels = split_dataset(features, labels)
norm_train, min_vals, ranges = auto_normalize(train_data)
print("归一化结果\n", norm_train)
norm_test = (test_data - min_vals) / ranges
# 3. 测试分类器效果
accuracy = classifier_accuracy(norm_test, test_labels, norm_train, train_labels)
print(f"分类器准确率:{accuracy:.2%}")
# 4. 使用分类器进行预测
while True:
try:
input_str = input("请输入待分类数据(格式:里程数 游戏时间% 冰淇淋升数),输入q退出:")
if input_str.lower() == 'q':
break
new_data = np.array([float(x) for x in input_str.split()])
if len(new_data) != 3:
raise ValueError
norm_new = (new_data - min_vals) / ranges
result = knn_classify(norm_train, train_labels, norm_new)
print("推荐结果:", result)
except:
print("输入格式错误,请重新输入!")运行结果截图:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









