



优先级
参数优先级排序:
(1)客户端代码中设置的值
(2)ClassPath下的用户自定义的配置文件(project下的配置文件,例如/usr/local/hadoop/etc/hadoop/hdfs-site.xml)
(3)服务器的自定义配置文件(XXX-site.xml路径为/usr/local/hadoop/etc/hadoop)
(4)服务器的默认配置(XXX-default.xml)
1.测试(2)和(3)的优先级
在项目中的resource中创建hdfs-site.xml文件,将如下内容拷贝进去(表面文件存储的份数为1份,而在/usr/local/hadoop/hdfs-site.xml中表明文件存储的份数为3份)
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
执行如下代码testPut1:
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.apache.hadoop.conf.Configuration;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
public class hdfsClient{
/**
*
*/
private FileSystem fs;
@Before
public void init() throws URISyntaxException,IOException,InterruptedException{
URI uri=new URI("hdfs://172.18.0.2:9000");
Configuration configuration=new Configuration();
String user="root";
fs=FileSystem.get(uri,configuration,user);
}
@After
public void close() throws IOException{
fs.close();
}
@Test
public void testmkdir() throws URISyntaxException,IOException,InterruptedException {
fs.mkdirs(new Path("/youxiuderen1"));
}
@Test
public void testmkdir1() throws URISyntaxException,IOException,InterruptedException {
fs.mkdirs(new Path("/youxiuderen2"));
}
@Test
public void testPut() throws URISyntaxException,IOException,InterruptedException{
fs.copyFromLocalFile(false,false,new Path("/root/IdeaProjects/hdfsClient/xiongjing.txt"), new Path("/youxiuderen1"));
}
@Test
public void testPut1() throws IOException{
fs.copyFromLocalFile(false,true,new Path("/root/IdeaProjects/hdfsClient/xiongjing.txt"), new Path("/youxiuderen1"));
}
@Test
public void testPut2() throws IOException{
fs.copyFromLocalFile(true,true,new Path("/root/IdeaProjects/hdfsClient/xiongjing.txt"), new Path("/youxiuderen1"));
}
@Test
public void testGet() throws IOException{
fs.copyToLocalFile(false,new Path("/youxiuderen1/xiongjing.txt"),new Path("/root/IdeaProjects/hdfsClient"),false);
}
@Test
public void testGet1() throws IOException{
fs.copyToLocalFile(false,new Path("/youxiuderen1/xiongjing.txt"),new Path("/root/IdeaProjects/hdfsClient/xiongjing1.txt"),true);
}
@Test
public void testGet2() throws IOException{
fs.copyToLocalFile(true,new Path("/youxiuderen1/xiongjing.txt"), new Path("/root/IdeaProjects/hdfsClient/xiongjing3.txt"),true);
}
}
结果为:复制份数为1份,所以项目中的resource中创建hdfs-site.xml文件的优先级要高于服务器的自定义配置文件(XXX-site.xml路径为/usr/local/hadoop/etc/hadoop)
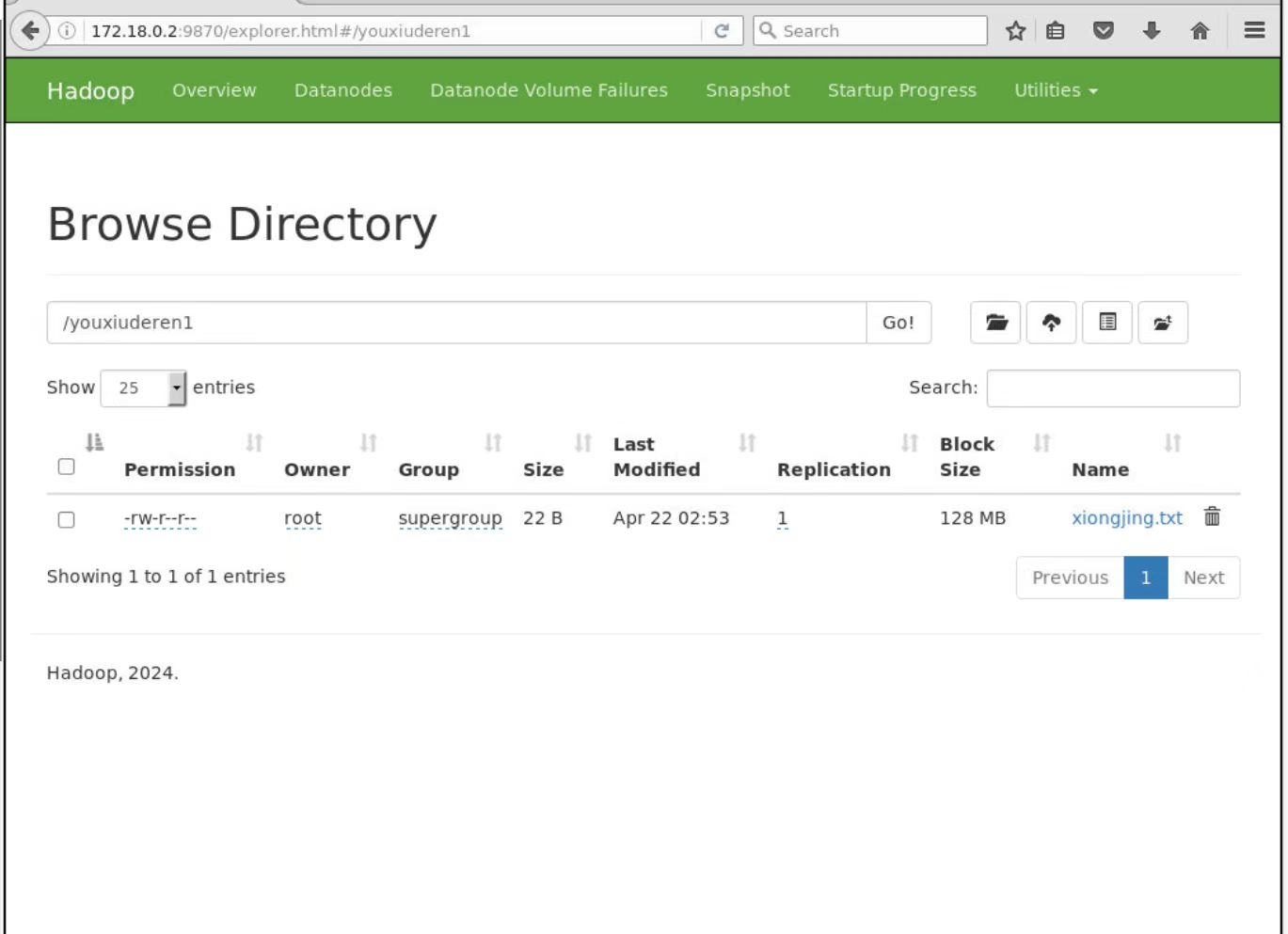
2.测试(1)和(2)(3)的优先级顺序
在代码中添加configuration.set(“dfs。replication”,“2”);设置份数为2份,在这之前设置了project下的配置文件,/root/IdeaProjects/hdfsClient/scr/main/resource/hdfs-site.xml份数为1份,服务器的自定义配置文件/usr/local/hadoop/etc/hadoop/hdfs-site.xml份数为3份
@Before
public void init() throws URISyntaxException,IOException,InterruptedException{
URI uri=new URI("hdfs://172.18.0.2:9000");
Configuration configuration=new Configuration();
configuration.set("dfs.replication","2");
System.out.println("dfs.replication:"+configuration.get("dfs.replication"));
String user="root";
fs=FileSystem.get(uri,configuration,user);
}
@After
public void close() throws IOException{
fs.close();
}
最后执行testPut1:
@Test
public void testPut1() throws IOException{
fs.copyFromLocalFile(false,true,new Path("/root/IdeaProjects/hdfsClient/xiongjing.txt"), new Path("/youxiuderen1"));
}
结果份数为2,说明客户端代码中设置的优先级高于所有的一切配置文件。
删除
@Test
public void testDelete() throws IOException{
//参数解读:参数1:源文件要删除的路径 参数2:是否递归删除(删除文件夹)
fs.delete(new Path("/jdk-8u171-linux-x64.tar.gz"),false);
}
出现报错
org.apache.hadoop.fs.PathIsNotEmptyDirectoryException:``/youxi/wangzherongyao is nonempty`:Directory is not empty
解决办法
@Test
public void testDelete2() throws IOException{
//删除非空文件夹,第二个参数选为true,会删除这个文件夹下所有的文件和这个文件夹
fs.delete(new Path("/youxi/wangzherongyao"),false);
}
文件名更改
@Test
public void testRename() throws IOException{
//修改文件的名字,第一个参数是:原本文件的路径和名字 第二个参数:被修改后的名字和路径
fs.rename(new Path("/youxi/yuanshen/shuishen.txt"),new Path("/youxi/yuanshen/huoshen.txt"));
}
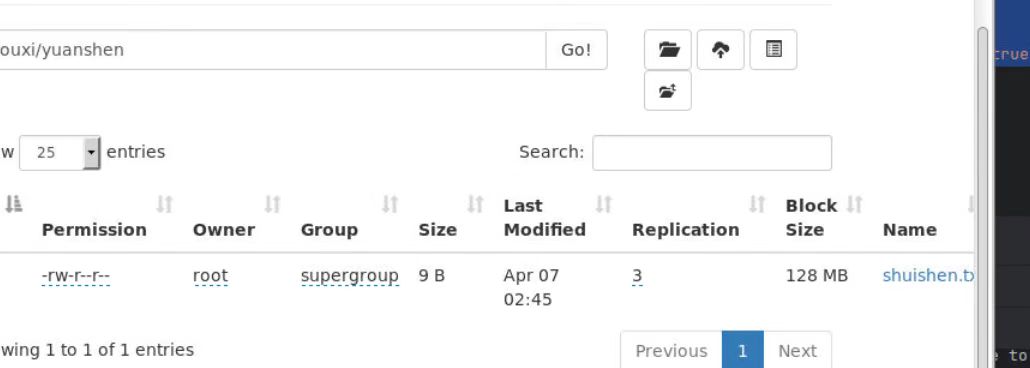
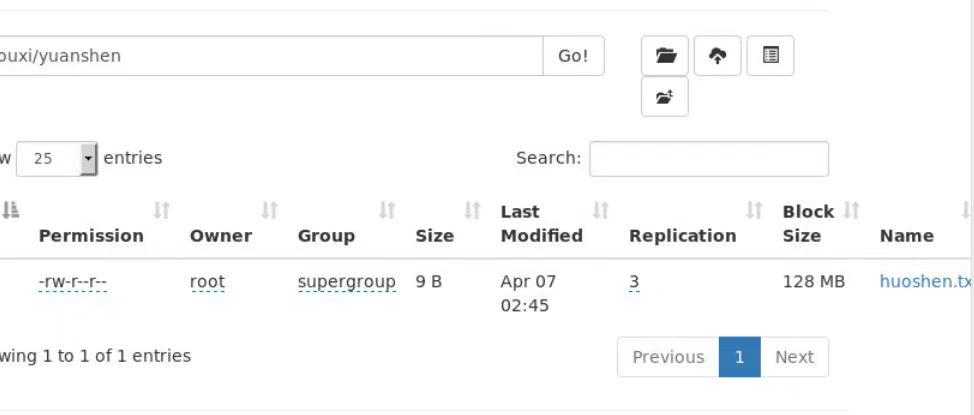
@Test
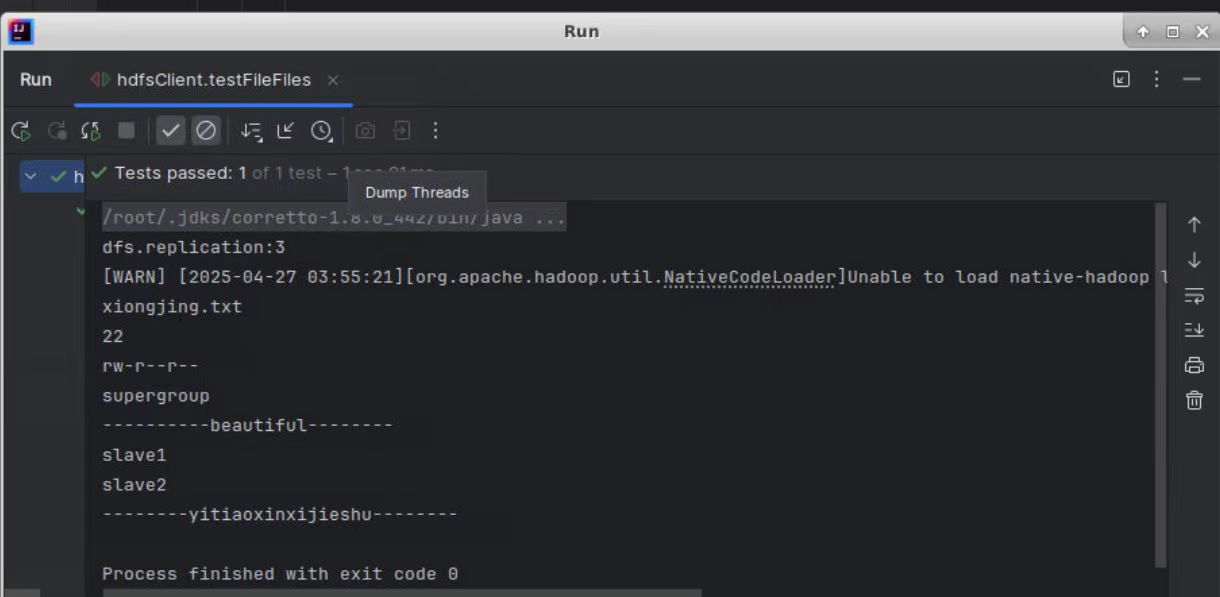
//listFiles返回该目录下所有子文件和子目录的详细信息,包括文件的长度,块大小,备份数,修改时间,所有者,权限
public void testFileFiles() throws IOException {
//RemoteIterator代表返回的对象类型,LocatedFileStatus范示,他表示的是,它的结构符合
fs.listFiles返回了所有文件的信息,返回的信息都存储在listFiles(listFiles将钱取出来,放在listFiles这个包里面)
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/youxiuderen1"), true);
//钱包里面有很多层,while循环,从第一层遍历到最后一层
while (listFiles.hasNext()) {
//打开第一层,把钱拿出来
LocatedFileStatus status = listFiles.next();
//将文件名称(钱名字例如100块)
System.out.println(status.getPath().getName());
//文件的长度
System.out.println(status.getLen());
//文件权限
System.out.println(status.getPermission());
//文件的分组
System.out.println(status.getGroup());
System.out.println("----------beautiful--------");
//获取存储的块信息,块信息在blockLocations
BlockLocation[] blockLocations=status.getBlockLocations();
//多个块,所以我们需要遍历blockLocations(把所有块信息,里面有很多小块信息,查看每个小块信息)
for(BlockLocation blockLocation:blockLocations){
//获取存储这个块的hosts(他可能包含多个节点)
String[] hosts=blockLocation.getHosts();
//遍历所有节点的host
for(String host:hosts){
System.out.println(host);
}
}
System.out.println("--------yitiaoxinxijieshu--------");
}
}
判断是文件还是文件夹
@Test
public void testListStatus() throws IOException{
//获取在hdfs系统里面此/input路径下,所有文件以及文件夹的状态
FileStatus[] listStatus=fs.listStatus(new Path("/input"));
//遍历listStatus
for(FileStatus fileStatus:listStatus){
//isFile()判断是不是文件
if(fileStatus.isFile()){
System.out.println("wenjian:"+fileStatus.getPath().getName());
}else{
System.out.println("wenjianjia:"+fileStatus.getPath().getName());
}
}
}
hdfs写数据流程
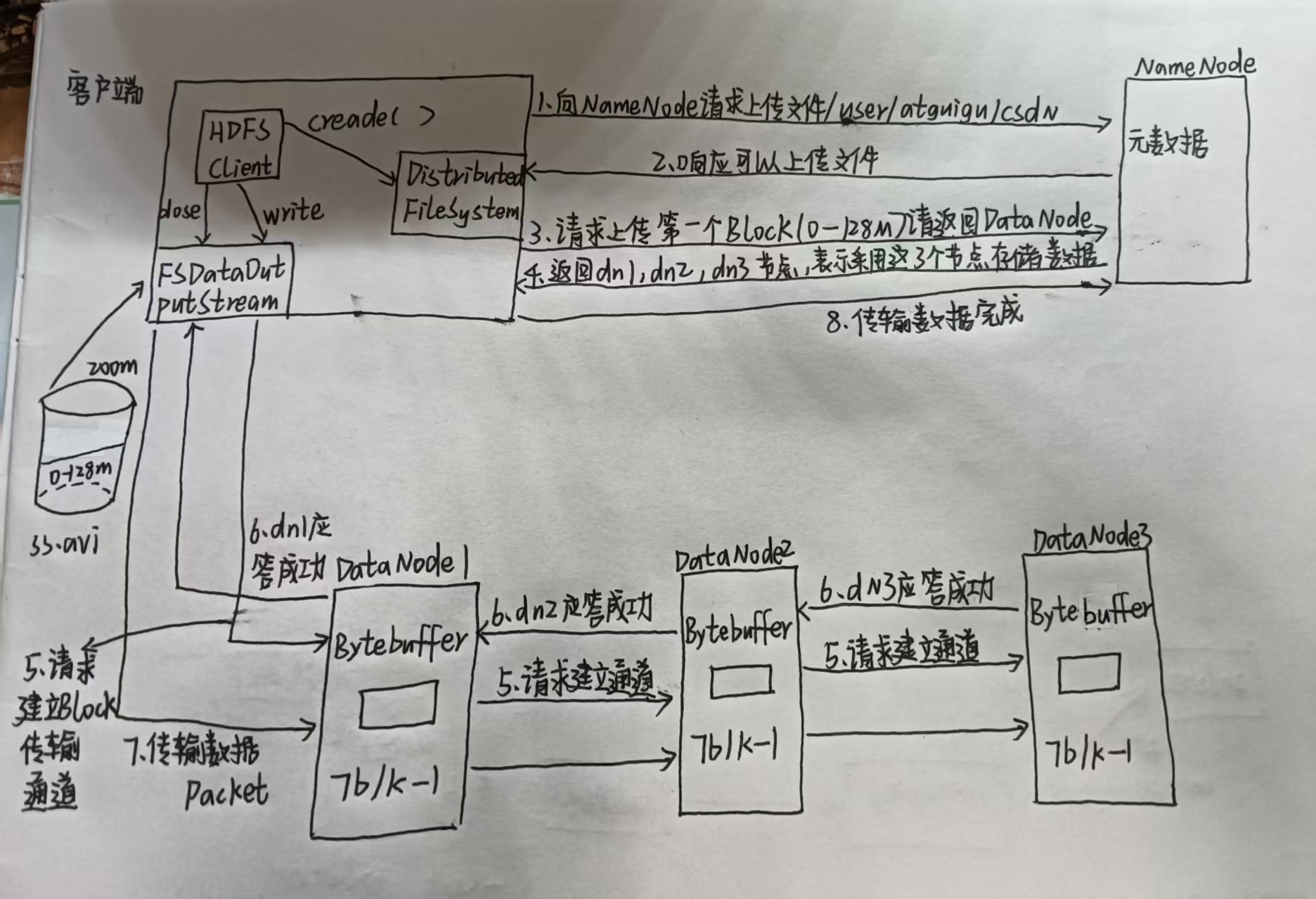
1.客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已经存在,检查目录结构和权限
2.NameNode检查后返回是否可以上传
3.客户端请求第一个Block上传到哪几个DataNode服务器上
4.NameNode返回3个(副本为多少,就返回多少个)DataNode节点,如上图返回DataNode1,DataNode2,DataNode3
5.客户端通过FSDataOutputStream模块请求DataNode1上传数据,DataNode1收到请求后会继续调用DataNode2,然后DataNode2调用DataNode3,将这个通信管道建立完成
6.DataNode3,DataNode2,DataNode1逐级应答客户端
7.客户端开始往DataNode1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,DataNode1收到Packet就会传给DataNode2,DataNode2传给DataNode3;DataNode1每传一个Packet会放入一个应答队列等待应答
8.当一个block传输完成后,客户端再次请求上传第二个block的服务器(就是第三步)
如果有多个block就会一直重复3-8步,直到所有block上传完成
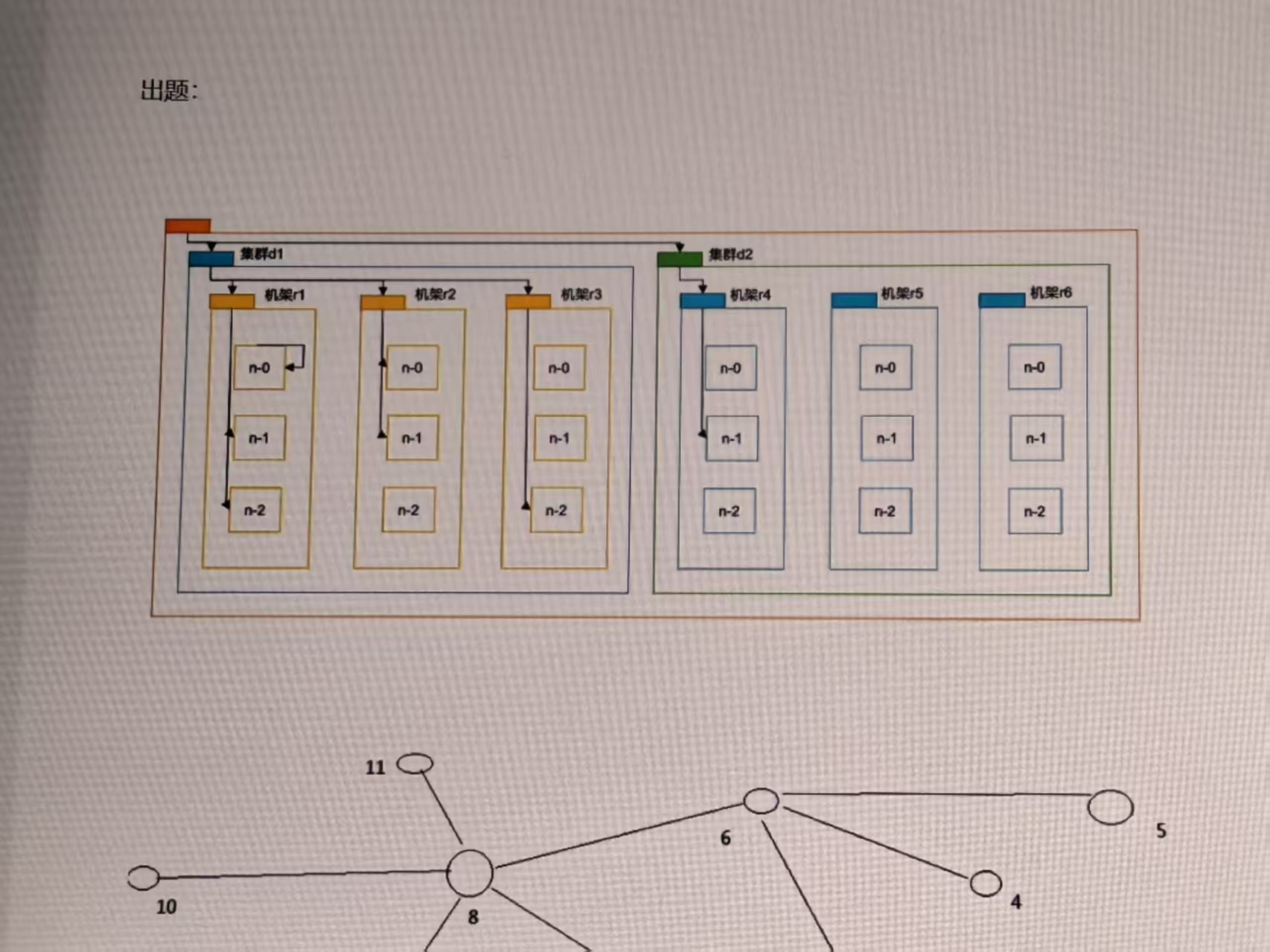
网络拓补图
hdfs写入数据的过程中,NameNode会选择距离待上传数据最近的距离的DataNoded接受数据。
距离怎么计算?怎么知道远近?
节点距离:两个节点到达最近的共同祖先的距离总和。
Distance(d1/r1/n0,d1/r1/n0)=0;
Distance(d1/r1/n1,d1/r1/n2)=1+1=2;
Distance(d1/r2/n1,d1/r3/n2)=2+2=4;
Distance(d1/r2/n0,d2/r4/n1)=3+3=6;
机架感知(replication副本存储节点选择)数据可靠性,传递速度快
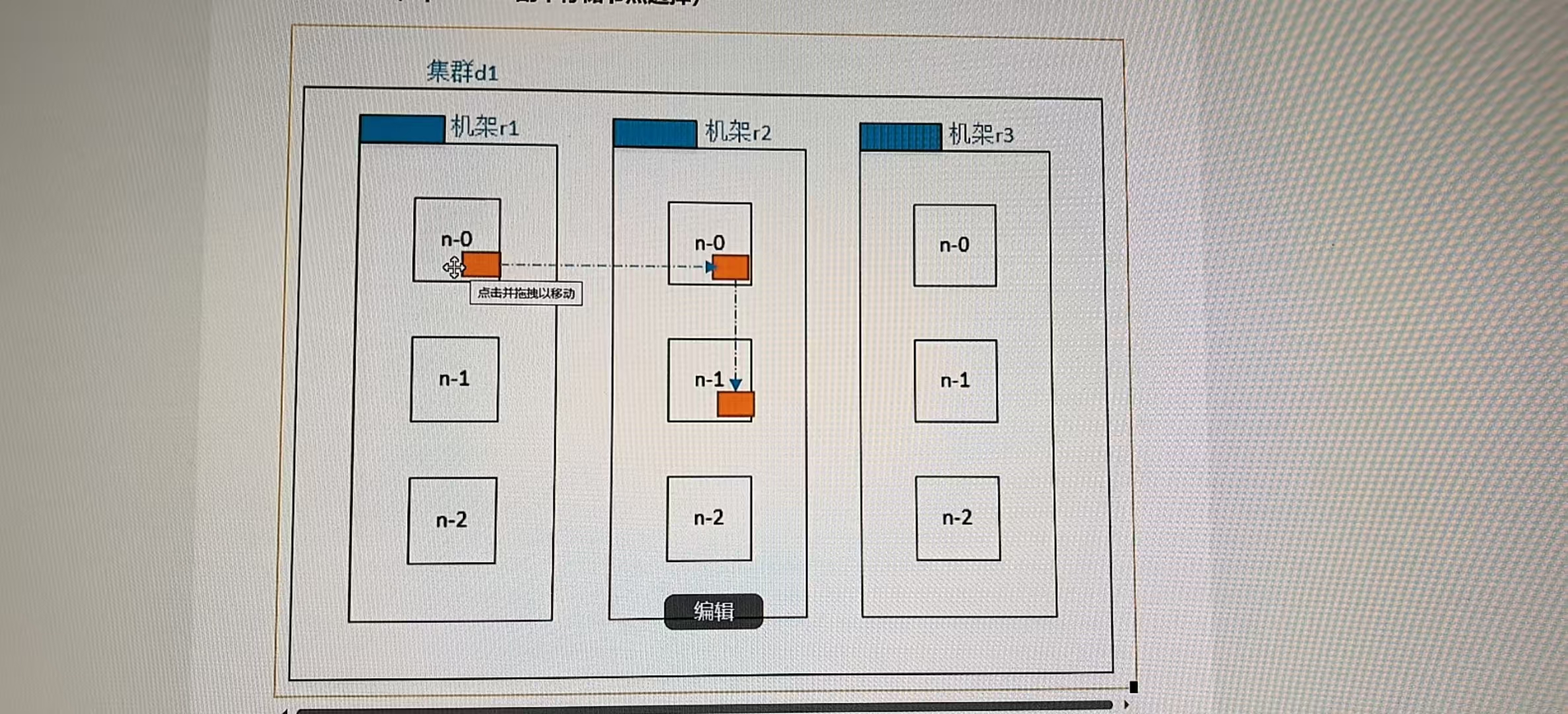
第一个副本在Client(客户端)所在的节点上。如果客户端在集群外,随机选一个。
第二个副本在另一个机架的随机一个节点。(第一个副本在r1机架上,那么第二个副本不在r1上)
数据可靠性。
第三个副本在第二个副本所在机架的随机节点。(例如:第一个副本在r1机架上,那么第二个副本在r2上,第三个副本在r2上)(速度快)
hdfs读取数据流程
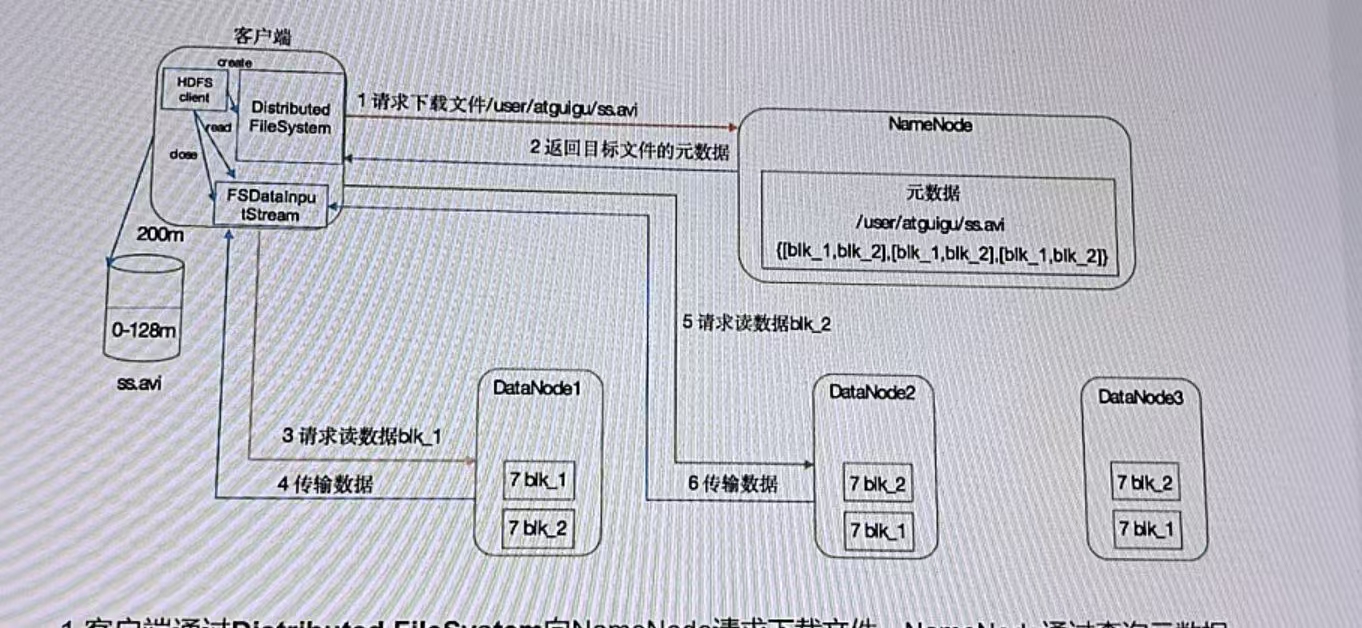
1.客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode。
(Shell脚本)查询文件位置。
hdfs fsck /input -files -blocks -location
2.挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。(负载均衡)
3.DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet数据包为单位来做校验)。(如果文件有多个block,串行读)
4.客户端以Packet为单位接受,先在本地缓存,然后写入目标文件。
namenode和secondarynamenode
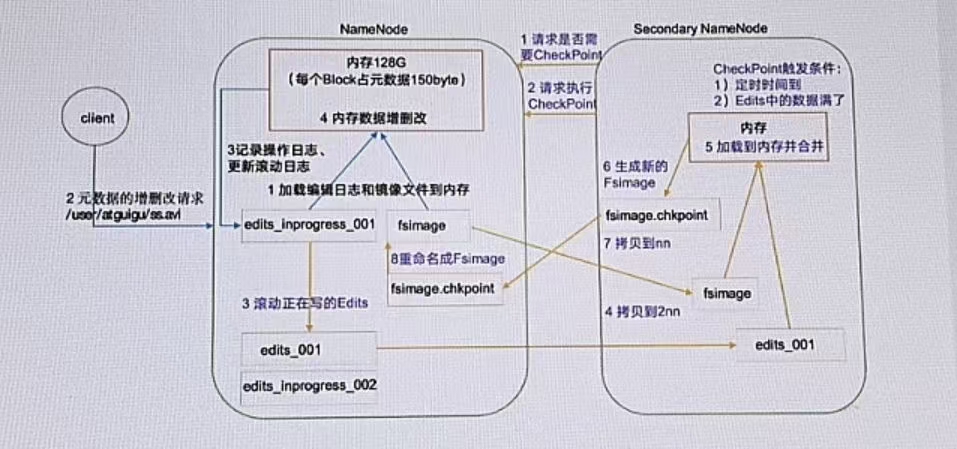
NameNode的源数据存储在哪儿?
内存:计算快,可靠性差
磁盘:计算慢,可靠性强
hdfs要求数据存储可靠性强,所以选择磁盘。但是频繁写入,磁盘太慢了,效率过低,所以要选内存。内存+磁盘的模式
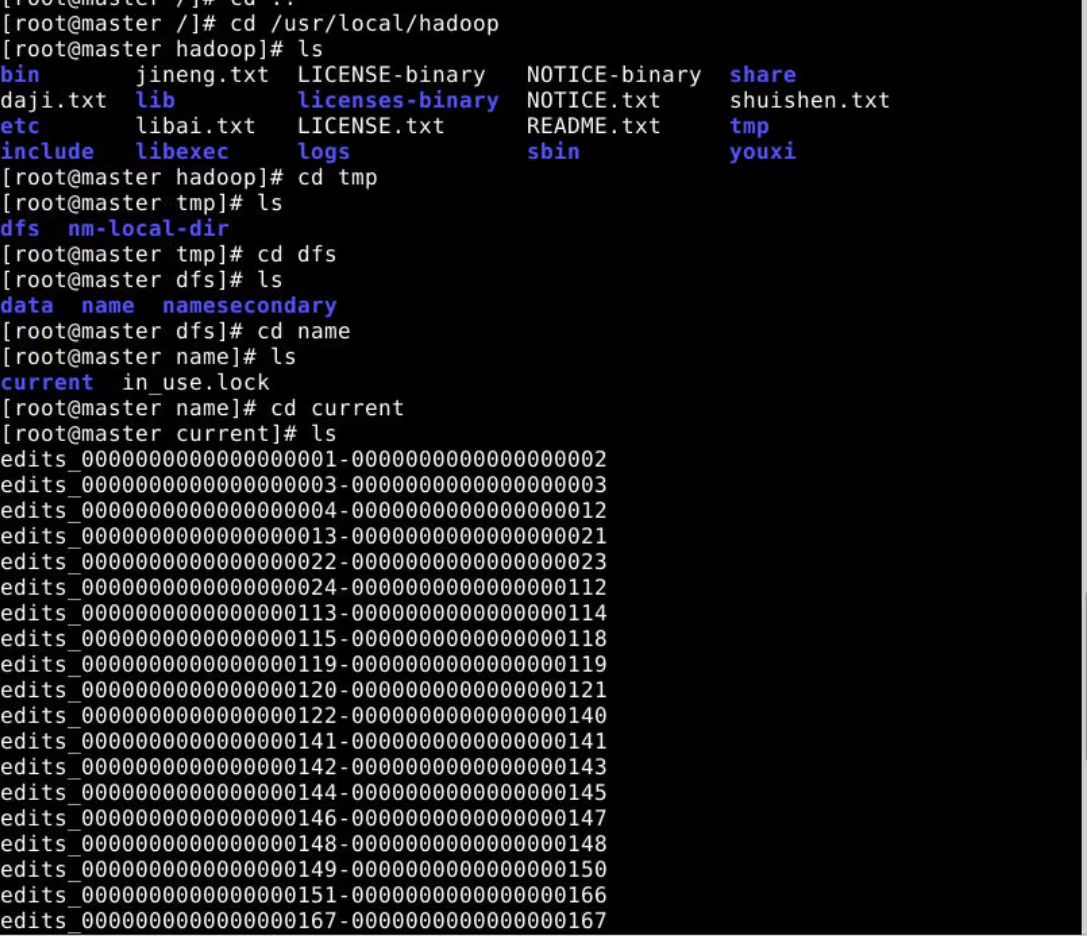
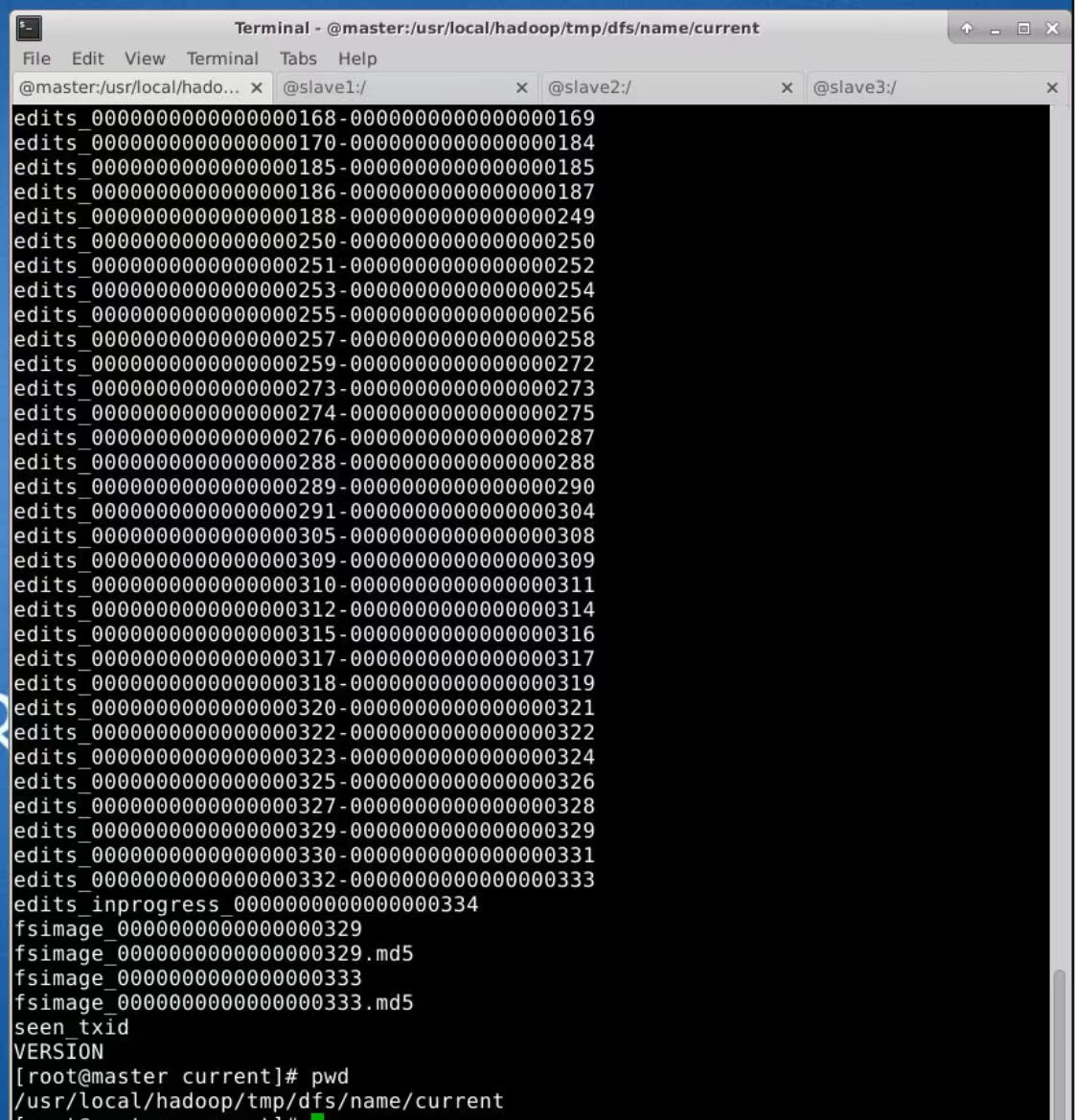
在namenode节点,执行如下命令
cd /usr/local/hadoop/tmp/dfs/name/current
下面图是namenode文件
下面图是secondary namenode的文件(没有edits_inprogress_0000000000000000334)
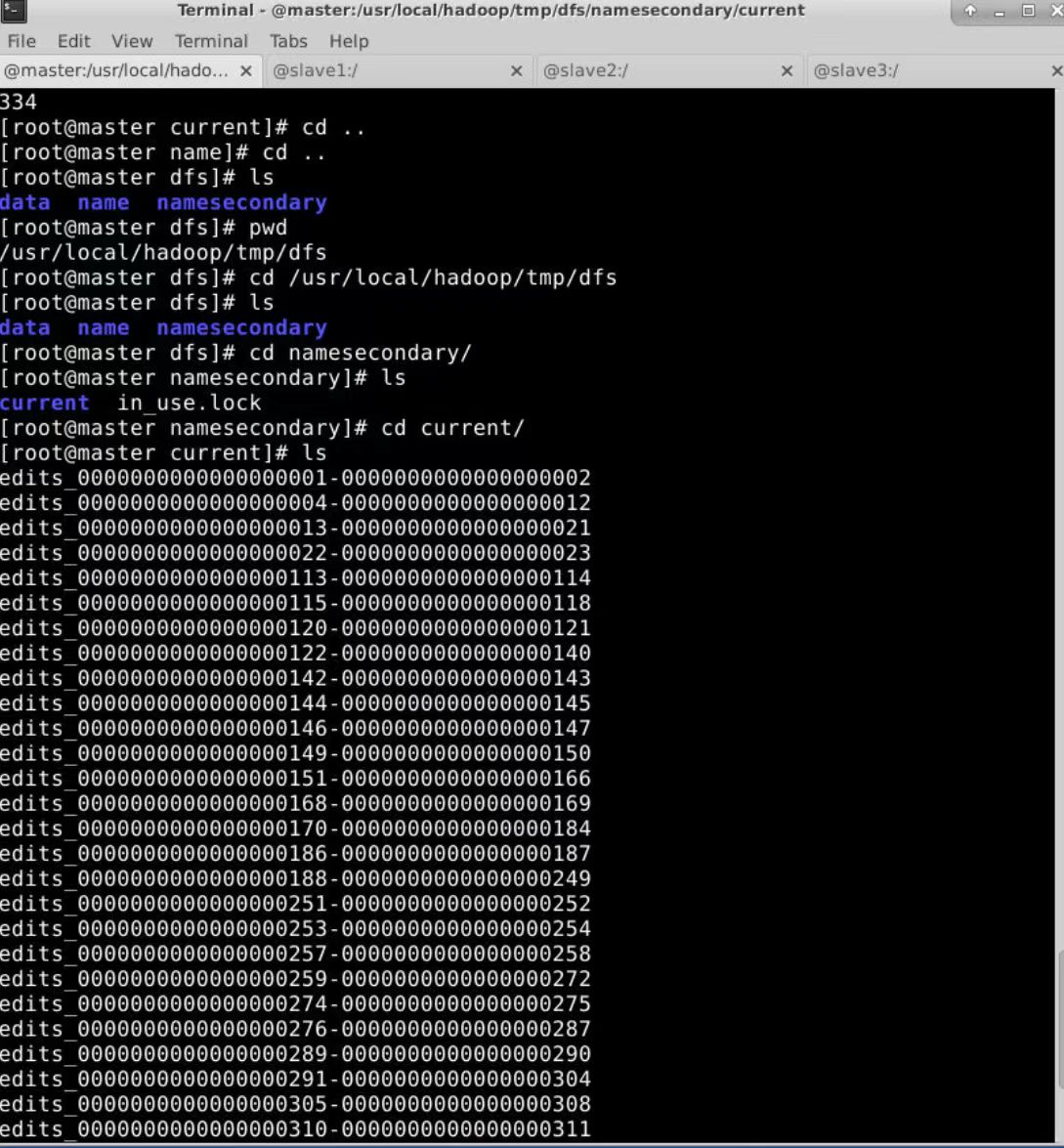
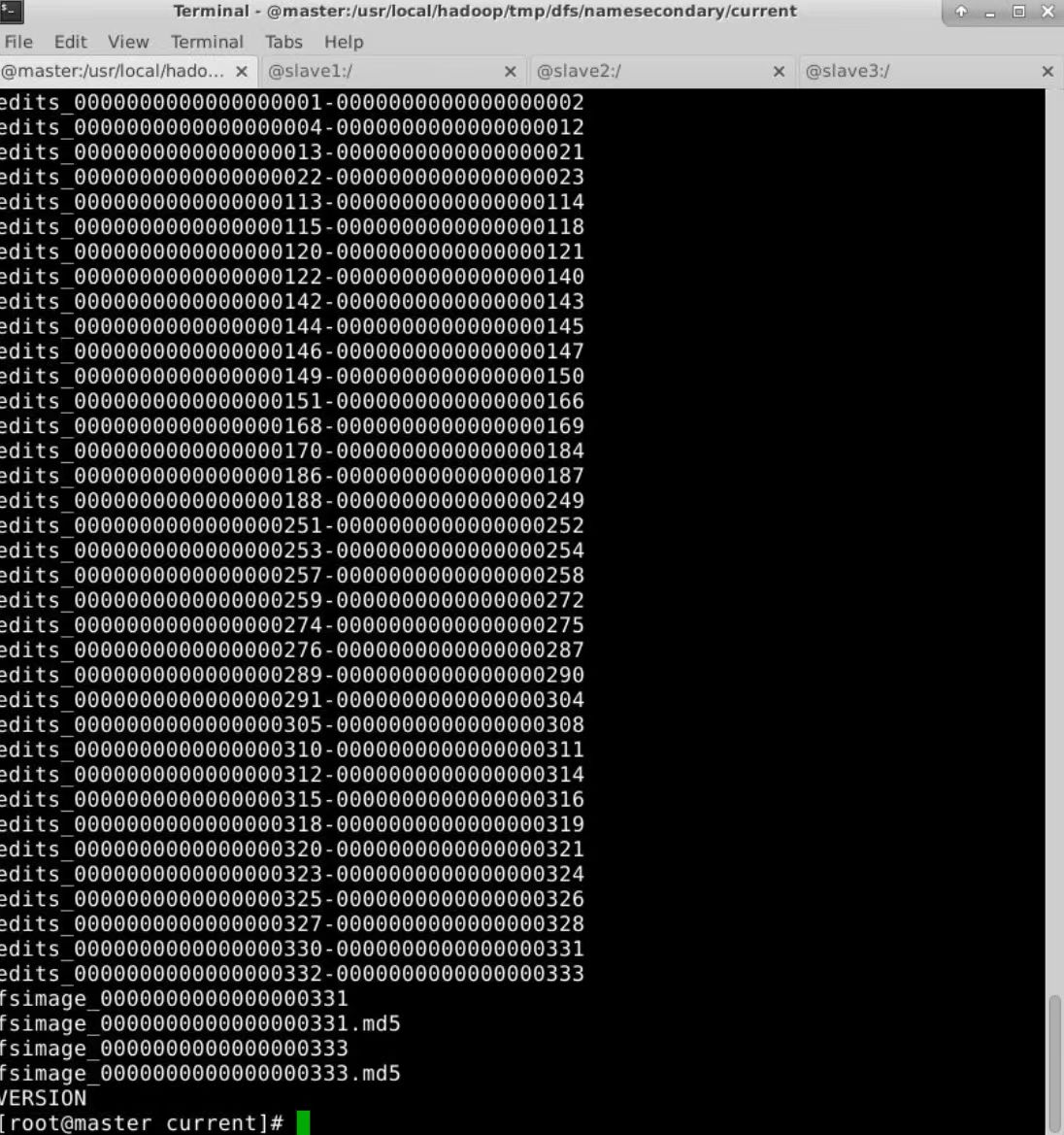
1.Fsimage:NameNode内存中元数据序列化后形成的文件。HDFS文件系统元数据的一个永久性的检查点,其中包括HDFS文件系统的所有目录和文件inode的序列化信息。
2.Edits(日志):记录客户端更新元数据信息的每一步操作。存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。
3.seen_txid文件保存的是一个数字,就是最后一个edits_的数字。
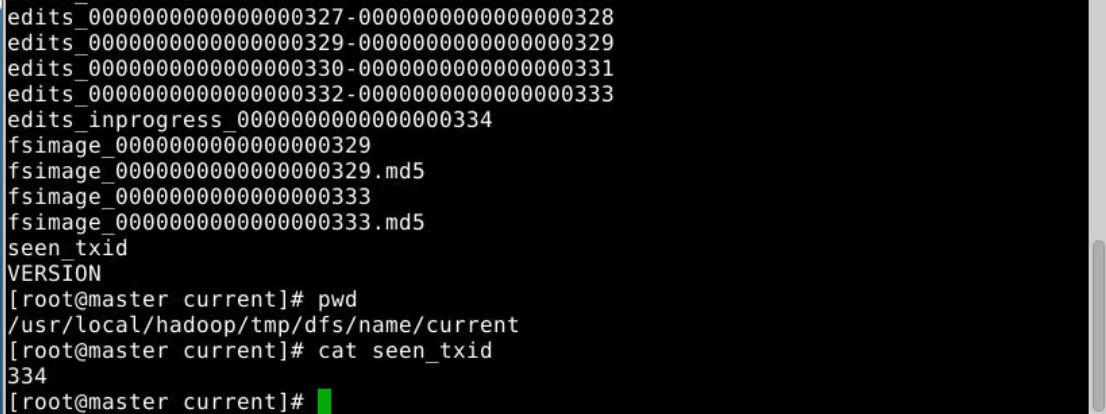
4.每次NameNode启动的时候,都会将Fsimage文件读入内存,加载Edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就会将Fsimage和Edits文件进行合并。

















 2668
2668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









