






动态内存管理
- 为什么存在动态内存分配
- 动态内存函数的介绍
- malloc
- free
- calloc
- realloc
- 常见的动态内存错误
- 几个经典的笔试题
- 柔性数组
正文开始
为什么存在动态内存分配
我们已经掌握的内存开辟方式有:
int val = 20;//在栈空间上开辟四个字节
char arr[10] = {0};//在栈空间上开辟10个字节的连续空间
但是上述的开辟空间的方式有两个特点:
- 空间开辟大小是固定的。
- 数组在申明的时候,必须指定数组的长度,它所需要的内存在编译时分配。
但是对于空间的需求,不仅仅是上述的情况。有时候我们需要的空间大小在程序运行的时候才能知道,那数组的编 译时开辟空间的方式就不能满足了。 这时候就只能试试动态存开辟了。
动态内存函数的介绍
###[malloc](malloc - C++ Reference (cplusplus.com))和[free](free - C++ Reference (cplusplus.com))
C语言提供了一个动态内存开辟的函数:
C语言提供了一个动态内存开辟的函数:
这个函数向内存申请一块连续可用的空间,并返回指向这块空间的指针。
-
如果开辟成功,则返回一个指向开辟好空间的指针。
-
如果开辟失败,则返回一个NULL指针,因此malloc的返回值一定要做检查。
-
返回值的类型是 void* ,所以malloc函数并不知道开辟空间的类型,具体在使用的时候使用者自己来决定。
-
如果参数 size 为0,malloc的行为是标准是未定义的,取决于编译器。
-
下面是补充:
-
<1>也就是说,如果malloc传入的值是0,那么这个行为可以被允许通过的。
<2>但是,这个行为最后产生的结果,是返回的一个空指针,或者是一些可能不能被访问的内存。(注意:这里是可能不能被访问,我上面运行结果显示可以被访问,并不冲突)
<3>最后,这里还表明,这个malloc返回的值,最终需要经过free()函数进行释放。
(5)那么还有一个问题,为什么我这里malloc(0)返回的是一个24字节的空间呢?这个所有人的都是24字节吗?
不是的,通过查阅网上的资料显示,不同环境下,malloc(0)返回的空间可能不同。

C语言提供了另外一个函数free,专门是用来做动态内存的释放和回收的,函数原型如下:
void free (void* ptr);
free函数用来释放动态开辟的内存。
- 如果参数ptr指向的空间不是动态开辟的,那free函数的行为是未定义的。
- 如果参数ptr是NULL指针,则函数什么事都不做。
malloc和free都声明在 stdlib.h 头文件中。 举个例子:
#include <stdio.h>
int main()
{
//代码1
int num = 0;
scanf("%d", &num);
int arr[num] = {0};
//代码2
int* ptr = NULL;
ptr = (int*)malloc(num*sizeof(int));
if(NULL != ptr)//判断ptr指针是否为空
{
int i = 0;
for(i=0; i<num; i++)
{
*(ptr+i) = 0;
}
}
free(ptr);//释放ptr所指向的动态内存
ptr = NULL;//是否有必要?
return 0;
}
###[calloc](calloc - C++ Reference (cplusplus.com))
C语言还提供了一个函数叫 calloc , calloc 函数也用来动态内存分配。原型如下:
void* calloc (size_t num, size_t size);
- 函数的功能是为 num 个大小为 size 的元素开辟一块空间,并且把空间的每个字节初始化为0。
- 如果任意一个参数为0,返回的值不能确定
- 与函数 malloc 的区别只在于 calloc 会在返回地址之前把申请的空间的每个字节初始化为全0。 举个例子:
#include <stdio.h>
#include <stdlib.h>
int main()
{
int *p = calloc(10, sizeof(int));
if(NULL != p)
{
//使用空间
}
free(p);
p = NULL;
return 0;
}
1.calloc的用法
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<errno.h>
int main()
{
int* p = (int*)calloc(10,sizeof(int)); //动态开辟内存空间
if (p != NULL) //检验动态开辟空间是否成功
{
int i = 0;
for (i = 0; i < 10; i++) //如果成功,打印这10个整型
{
printf("%d ", *(p + i));
}
}
else
{
printf("%s\n", strerror(errno)); //如果失败,则打印失败错误信息
return 0; //失败则不需要进行下面的释放和置空操作了,可以直接退出
}
free(p); //使用完后向系统归还动态开辟的内存空间
p = NULL; //将p指针置为空,避免p成为野指针
return 0;
}
2.使用calloc()函数完成动态结构体的开辟
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<errno.h>
//人的信息-结构体
typedef struct PeoInfo
{
char name[20];
int age;
char sex[5];
char addr[20];
char tele[11];//电话11位,留一位给'\0';
}PeoInfo;
typedef struct Contact
{
PeoInfo* data; //存放人的信息
int sz; //用来记录当前已经存放的信息的个数
int capacity; //记录当前通讯录的最大容量
}Contact;
int main()
{
Contact con;
//结构体类型,为结构体开辟一块空间
PeoInfo* ptr = (PeoInfo*)calloc(3,sizeof(PeoInfo)); //动态开辟空间
if (ptr == NULL) //如果开辟失败,则打印错误原因
{
perror("InitContact::calloc");
return;
}
free(ptr); //使用完后向系统归还动态开辟的内存空间
ptr = NULL; //将p指针置为空,避免p成为野指针
return 0;
}

- 以上就是calloc空间的开辟
###realloc
- realloc函数的出现让动态内存管理更加灵活。
- 有时会我们发现过去申请的空间太小了,有时候我们又会觉得申请的空间过大了,那为了合理的时候内存, 我们一定会对内存的大小做灵活的调整。那 如下:
void* realloc (void* ptr, size_t size);
-
ptr 是要调整的内存地址
-
size 调整之后新大小
-
返回值为调整之后的内存起始位置。
-
这个函数调整原内存空间大小的基础上,还会将原来内存中的数据移动到新的空间。
-
realloc在调整内存空间的是存在两种情况:
- 情况1:原有空间之后有足够大的空间
- 情况2:原有空间之后没有足够大的空间
补充
realloc(ptr, 0) 会释放 ptr 所指向的内存空间,并返回一个空指针。
#include <stdio.h> #include <stdlib.h> int main() { int* ptr = (int*)malloc(25); ptr = realloc(ptr, 0); if (ptr == NULL) { printf("Memory allocation failed.\n"); return 1; } }在 C 语言中,如果将空指针(NULL)传递给 realloc 函数,其行为类似于 malloc 。
也就是说, realloc(NULL, size) 会分配一块新的大小为 size 的内存,并返回指向新分配内存的指针。
例如:
#include <stdio.h> #include <stdlib.h> int main() { int* ptr = NULL; ptr = realloc(ptr, 10 * sizeof(int)); if (ptr == NULL) { printf("Memory allocation failed.\n"); return 1; } // 使用分配的内存 //... int i = 0; for (i = 0; i < 10; i++) { *(ptr + i) = 1; } for (i = 0; i < 10; i++) { printf("%d", *(ptr + i)); } free(ptr); return 0; }
情况1 当是情况1 的时候,要扩展内存就直接原有内存之后直接追加空间,原来空间的数据不发生变化。 情况2 当 是情况2 的时候,原有空间之后没有足够多的空间时,扩展的方法是:在堆空间上另找一个合适大小的连续空间来 使用。这样函数返回的是一个新的内存地址。 由于上述的两种情况,realloc函数的使用就要注意一些。 举个例子:
#include <stdio.h>
int main()
{
int *ptr = malloc(100);
if(ptr != NULL)
{
//业务处理
}
else
{
exit(EXIT_FAILURE);
}
//扩展容量
//代码1
ptr = realloc(ptr, 1000);//这样可以吗?(如果申请失败会如何?)
//代码2
int*p = NULL;
p = realloc(ptr, 1000);
if(p != NULL)
{
ptr = p;
}
//业务处理
free(ptr);
return 0
}
常见的动态内存错误
- 对NULL指针的解引用操作
void test()
{
int *p = (int *)malloc(INT_MAX/4);
*p = 20;//如果p的值是NULL,就会有问题
free(p);
}
- 对动态开辟空间的越界访问
void test()
{
int i = 0;
int *p = (int *)malloc(10*sizeof(int));
if(NULL == p)
{
exit(EXIT_FAILURE);
}
for(i=0; i<=10; i++)
{
*(p+i) = i;//当i是10的时候越界访问
}
free(p);
}
- 对非动态开辟内存使用free释放
void test()
{
int a = 10;
int *p = &a;
free(p);
}
- 使用free释放一块动态开辟内存的一部分
void test()
{
int *p = (int *)malloc(100);
p++;
free(p);//p不再指向动态内存的起始位置
}
- 对同一块动态内存多次释放
void test()
{
int *p = (int *)malloc(100);
free(p);
free(p);//重复释放
}
- 动态开辟内存忘记释放(内存泄漏)
void test()
{
int *p = (int *)malloc(100);
if(NULL != p)
{
*p = 20;
}
}
int main()
{
test();
while(1);
}
忘记释放不再使用的动态开辟的空间会造成内存泄漏。 切记:动态开辟的空间一定要释放,并且正确释放
几个经典的笔试题
题目1:
void GetMemory(char *p)
{
//出来局部变量的时候被销毁了
//会导致空间不一样,非法访问
p = (char *)malloc(100);
}
void Test(void)
{
char *str = NULL;
GetMemory(str);
strcpy(str, "hello world");
printf(str);
}
请问运行Test 函数会有什么样的结果?
题目2:
char *GetMemory(void)
{
//会返回不知道的空间,后面空间已经被还给操作系统
//非法访问
char p[] = "hello world";
return p;
}
void Test(void)
{
char *str = NULL;
str = GetMemory();
printf(str);
}
C/C++程序的内存开辟
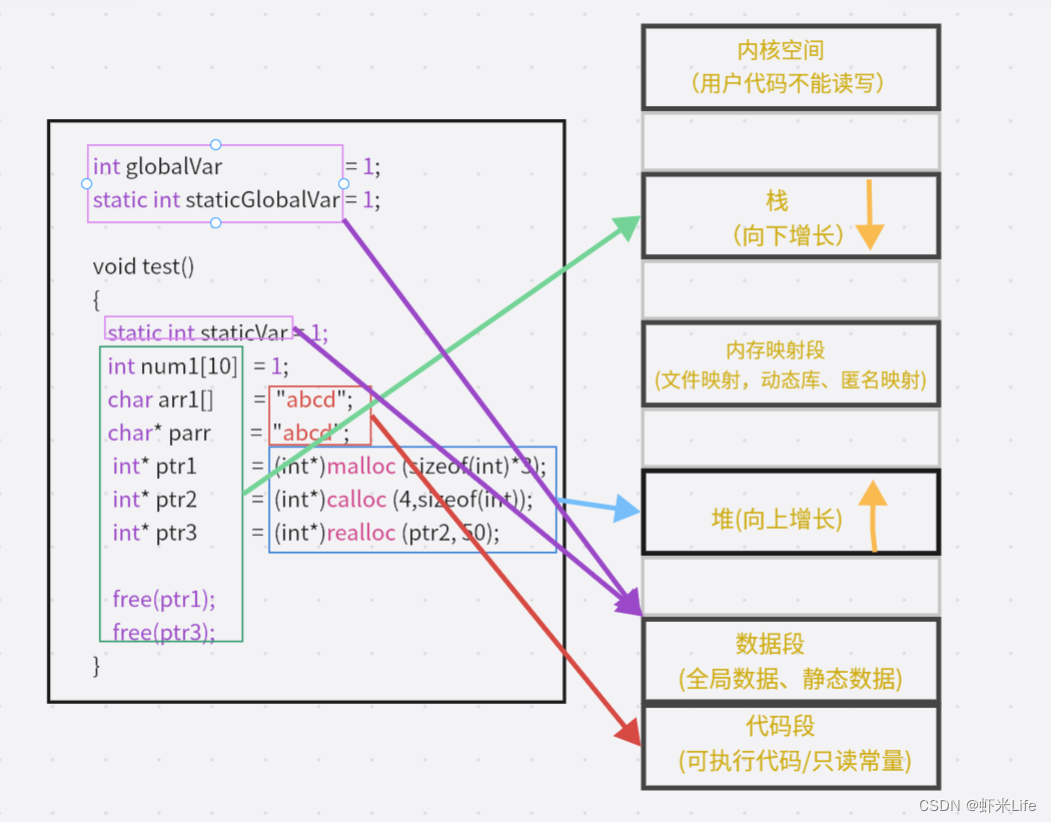
C/C++程序内存分配的几个区域:
栈区(stack):在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些 存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有 限。 栈区主要存放运行函数而分配的局部变量、函数参数、返回数据、返回地址等。
堆区(heap):一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。分配方式类似 于链表。
数据段(静态区)(static)存放全局变量、静态数据。程序结束后由系统释放
代码段:存放函数体(类成员函数和全局函数)的二进制代码。
有了这幅图,我们就可以更好的理解在《C语言初识》中讲的static关键字修饰局部变量的例子了。
实际上普通的局部变量是在栈区分配空间的,栈区的特点是在上面创建的变量出了作用域就销毁。
但是被static修饰的变量存放在数据段(静态区),数据段的特点是在上面创建的变量,直到程序结束才销毁 所以生命周期变长。
柔性数组
也许你从来没有听说过柔性数组(flexible array)这个概念,但是它确实是存在的。 C99 中,结构中的最 后一个元素允许是未知大小的数组,这就叫做『柔性数组』成员
例如:
typedef struct st_type
{
int i;
int a[0];//柔性数组成员
}type_a;
有些编译器会报错无法编译可以改成:
typedef struct st_type
{
int i;
int a[];//柔性数组成员
}type_a;
柔性数组的特点:
- 结构中的柔性数组成员前面必须至少一个其他成员。
- sizeof 返回的这种结构大小不包括柔性数组的内存。
- 包含柔性数组成员的结构用malloc ()函数进行内存的动态分配,并且分配的内存应该大于结构的大小,以适应 柔性数组的预期大小。
例如:
//code1
typedef struct st_type
{
int i;
int a[0];//柔性数组成员
}type_a;
printf("%d\n", sizeof(type_a));//输出的是4
柔性数组的使用
//代码1
int i = 0;
type_a *p = (type_a*)malloc(sizeof(type_a)+100*sizeof(int));
//业务处理
p->i = 100;
for(i=0; i<100; i++)
{
p->a[i] = i;
}
free(p);
这样柔性数组成员a,相当于获得了100个整型元素的连续空间。
柔性数组的优势
上述的 type_a 结构也可以设计为:
//代码2
typedef struct st_type
{
int i;
int *p_a;
}type_a;
type_a *p = malloc(sizeof(type_a));
p->i = 100;
p->p_a = (int *)malloc(p->i*sizeof(int));
//业务处理
for(i=0; i<100; i++)
{
p->p_a[i] = i;
}
//释放空间
free(p->p_a);
p->p_a = NULL;
free(p);
p = NULL
上述代码1和代码2可以完成同样的功能,但是方法1的实现有两个好处: 第一个好处是:方便内存释放
如果我们的代码是在一个给别人用的函数中,你在里面做了二次内存分配,并把整个结构体返回给用户。用 户调用free可以释放结构体,但是用户并不知道这个结构体内的成员也需要free,所以你不能指望用户来发 现这个事。所以,如果我们把结构体的内存以及其成员要的内存一次性分配好了,并返回给用户一个结构体 指针,用户做一次free就可以把所有的内存也给释放掉。
第二个好处是:这样有利于访问速度
连续的内存有益于提高访问速度,也有益于减少内存碎片。(其实,我个人觉得也没多高了,反正你跑不了 要用做偏移量的加法来寻址)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









